
企业 | 长江存储加码扩产:计划再建两座武汉工厂,国产设备占比突破五成
中国存储芯片龙头企业长江存储(YMTC)正在加速扩张步伐。据多方消息证实,在完成现有三期项目建设后,该公司计划在武汉再投建两座新晶圆厂。届时,其总产能将实现翻倍增长,进一步提升中国在全球存储芯片市场的竞争力。 按照规划,三座新工厂全面投产后,每座月产能将达10万片,较现有两座工厂合计20万片的月产能大幅提升。其中,三期项目预计于今年年底率先投运,2027年产能爬坡至5万片/月。 值得关注的是,三期工厂的设备国产化率已超过50%,标志着本土半导体供应链的重要突破。 此次扩产不仅限于产能规模,更涉及产品结构的关键调整。除传统NAND闪存外,长江存储已将三期工厂约一半产能转向低功耗DRAM,并向客户送测样品。同时,公司正在研发硅通孔(TSV)封装技术,为未来布局高带宽内存(HBM)市场做准备。 当前,长江存储在全球NAND闪存市场的份额约为11.8%,与闪迪持平。分析机构预测,随着新产能陆续释放,其市占率有望在2028年提升至15%。 尽管受技术壁垒限制,其Xtacking 4.0架构约270层,仍落后于三星、SK海力士等竞争对手,但凭借自主可控的供应链优势,长江存储正在加速缩小与国际巨头的差距。 这一轮扩产计划的落地,不仅将改变全球存储芯片的供需格局,也意味着中国在半导体设备、材料等关键环节的自给能力正在经受大规模量产考验。对于正处于技术封锁压力下的中国半导体产业而言,长江存储的产能爬坡进度将成为观察国产替代成效的重要窗口。
长江存储
信创头条 . 2026-04-16 8274

市场 | 贸易投机扰乱现货市场,渠道SSD、行业及渠道内存条普遍阴跌
因前期高价囤货的部分贸易商急需转手以求回款,降价加快出货使得贸易商之间形成局部踩踏,存储现货市场整体较为混乱。尽管渠道贸易端频频出现抛售行为,较为低价的存储产品并未吸引渠道客户重拾备货动力,反而令市场更加浑浊,客户也更为谨慎。渠道市场在贸易行为持续冲击下短期处于煎熬的状态,本周渠道SSD和内存条价格普遍阴跌。 与此同时,行业市场也在一定程度上受到渠道抛货的影响,加上近半年来行业内存条涨幅过大,DDR4次级资源价格弹性较高,行业DDR4内存条价格也出现小幅下跌。尽管渠道端部分NAND资源贸易价格已连续两周下滑,但本月个别原厂512Gb/1Tb TLC官价环比上月依旧维持涨势,行业SSD价格相对更加平稳。部分存储厂商凭借较高的客户黏性,基于工控客户对于价格接受度更高,行业SATA系列SSD产品已陆续成交。 上游资源方面,今日Flash Wafer暂时持平;本周DDR5 16Gb eTT价格调降至22美元,其余DDR5、DDR4颗粒价格不变。 DDR最新报价 Flash Wafer最新报价 近半个月以来,贸易商投机动作频频,个别激进者不惜高息囤货,近日为加快资金回流而以比市场更低的价格出售,使得近两周内相关产品价格连续回调。市场混沌更加影响渠道客户采购意愿,市场整体表现较为低迷,仅部分小单成交。本周渠道SSD、内存条价格小幅下滑。 渠道市场内存条最新报价 渠道市场SSD最新报价 从近半年内来看,行业DDR4内存条累计涨幅普遍高达两到三倍,前期涨幅过大几近透支行业客户对于价格的接受度。另外,由于高等级资源价格过高且常态化缺货,行业产品方案几乎全面转向次级资源,相对来说价格弹性更高,且方案选择也较多,多因素影响下本周多数行业DDR4内存条价格小幅下跌。 行业市场内存条最新报价 行业市场SSD最新报价 尽管近期贸易端出现个别以较低价来抛售部分容量的LPDDR4X产品,但从上游供应来看资源价格变动不大,存储厂商多以维持价格稳定为主,并不愿意低价跟进。另外,由于原厂退出MLC NAND供应体系,一些客户群体转向国内存储厂商寻求供应下,令低容量嵌入式存储产品需求有撑,大容量产品则因客户库存水位偏高使得拉货需求寡淡。整体来看,嵌入式eMMC/UFS、LPDDR产品价格普遍维持高位盘整。 eMMC最新报价 eMCP最新报价 LPDDR最新报价 UFS最新报价 uMCP最新报价
SSD
闪存市场 . 2026-04-16 1981

企业 | 扩充先进封装产能,日月光32亿元取得群创南科Fab 5厂房
为应对生成式AI与高性能计算(HPC)快速发展所带动的AI芯片需求,封测龙头日月光投控正加速扩张先进封装版图。 日月光投控于4月15日代子公司日月光半导体公告称,经双方议价,以总价新台币148.5亿元(未税,约合人民币32亿元),向面板大厂群创光电取得位于台南市新市区新科段的南科Fab 5厂房及相关附属设施。 根据公告,此次交易的建物总面积达184,313.95平方公尺,折合约5万5,754.97坪。为了加速交付进度以利扩充半导体先进封装产能,双方将另签署提前使用补偿协议。而群创方面将加速进行既有制程与特定厂务设备的拆卸、搬迁与清运作业,日月光则预计补偿群创因此产生的移除成本约新台币9.82亿元。 市场解读,先进封装已成为当一半导体产业的关键瓶颈。晶圆代工龙头台积电早于2024年即向群创取得南科厂房,如今同为半导体巨头的日月光也跟进布局,晶圆制造与先进封装同步扩张,使南科园区快速崛起为先进制程与封装重镇。此外,日月光2026年在台扩产动作频频,日前已在高雄仁武产业园区启动新厂建设,法人估算其2026年整体资本支出(含设备与厂务)有望超越原订70亿美元,改写历史新高。 日前,日月光投控执行长吴田玉就表示,2026年将是日月光非常忙碌的一年,打破公司历年纪录,预计将有6座工厂同步动工。日月光与中国台湾产业链的布局版图更横跨美国达拉斯、亚利桑那、休斯敦,以及马来西亚、日本、德国等地。这不仅反映了AI浪潮下对硬件瓶颈的强烈需求,更展现了中国台湾高科技从业人员布局全球的硬实力与企图心。 而在卖方群创光电方面,此次处分南科Fab 5厂的目的是为挹注公司营运及未来发展动能,充实营运资金,预计可带来约新台币133亿元的处置利益。若加计群创2026年稍早以新台币8.8亿元出售南科模块厂予南茂(获利约新台币6.59亿元),以及以新台币63.25亿元将南科二厂售予硅品(获利约新台币58亿元),群创2026年累计的售厂获利预估可达新台币197.59亿元,将为公司贡献每股税后纯益(EPS)约新台币2.47元。
扩产
芯智讯 . 2026-04-16 1281

市场 | 钨价暴涨6倍,中国管制之下,多家日企“断粮”
2026年4月14日,日本富士精工株式会社发布公告称,受中国加强钨出口管制影响,公司已面临超硬合金主原料——钨粉的供应危机,占其合并销售额约30%的切削工具产品可能因此出现交货延迟甚至新订单受限。 日企“断粮”背后,中国出口管制加强 富士精工在公告中披露,自2026年年初以来,公司已下单的钨粉在中国海关通关受阻,至今“尚无恢复进口的时间表”。尽管公司正努力寻求替代材料,但“稳定供应所需的数量尚未得到保障”。 从财务影响来看,受影响的超硬切削工具(钻头、铰刀等)占富士精工合并销售额的约30%。日本富士精工在同日公布的截至2027年2月的业绩预测中表示,由于“难以估算影响规模”,未将此次供应链危机的影响纳入预测数据。富士精工称,一旦影响金额确定,将立即披露。 富士精工受中国出口管制影响导致“断粮”并非个案。 据韩国媒体The Elec于4月初的报道称,日本关东电化、中央硝子已向三星电子等韩国三星电子和DB HiTek等芯片制造发出六氟化钨(WF6)断供预警,5月和6月的供应仍可依靠现有库存维持,但下半年的供应存在较大不确定性。 (六氟化钨的生产流程是:钨粉→与氟气在高温下反应→蒸馏提纯→制成半导体级高纯度气体。) 数据显示,这两家日本企业合计占全球六氟化钨供应量的约25%。但是他们的六氟化钨的生产则严重依赖于从中国进口的钨粉原料。这也是导致他们对客户发出断供预警的关键原因。 这一连锁反应的共同源头,指向2026年1月6日中国商务部发布的“第1号公告”。 2026年1月6日,中国商务部发布公告,宣布加强两用物项对日本出口管制。核心内容包括:禁止所有两用物项对日本军事用户、军事用途出口;禁止对“一切有助于提升日本军事实力的其他最终用户用途”出口。任何违反上述规定的第三方转移行为,将依法追究法律责任 这一政策并非孤立行动。早在2025年,中国已陆续对钨、碲、铋、钼、铟等相关物项实施出口管制。2026年1月的公告,则是在此基础上针对日本的单列强化措施。 钨的战略价值不言而喻。作为“工业牙齿”,钨在硬质合金、穿甲弹、半导体靶材等领域具有不可替代性。中国掌握着全球约80%的钨资源与产能,而日本是中国钨制品的最大出口目的地。数据显示,2025年1-11月,中国对日本钨制品出口量占同期出口总量的29.79%,其中仲钨酸铵、未锻轧钨的对日出口占比分别高达56.79%和56.44%。 中国出口管制的直接影响,已通过价格信号快速传导至产业链各环节。 据五矿证券研究报告,截至2026年2月初,65%黑钨精矿价格已涨至63.2万元/标吨,较年初上涨37.4%;钨粉价格达1550元/公斤,较年初上涨43.5%。另据长江有色金属网数据,2026年4月初钨粉现货均价达232.25万元/吨,价格处于历史绝对高位。 如果以2025年初的价格(约300元/公斤)来对比,钨粉价格一年内暴涨了6至7倍(约2100-2300元/公斤),仲钨酸铵(APT)国际基准价自2025年2月以来上涨557%。 富士精工也在公告表示:超硬合金原料的钨粉供应不稳定,已导致“原材料成本上升不可避免”,若无法顺利转嫁价格,将对销售额和营业利润产生直接影响。 从“资源国”到“规则制定者” 从更宏观的视角来看,中国针对钨等矿产资源的出口管制及其引发的连锁反应,折射出中国关键矿产战略的根本性转变。 过去,中国长期扮演“廉价原料供应者”的角色,将稀缺的钨资源以初级产品形式出口,再以高价进口深加工制品。如今,通过“开采总量严控、出口管制收紧、环保督察常态化”的三维政策体系, 五矿证券研报指出,2025年中国钨精矿开采总量控制第一批指标同比减少6.5%,环保及安全督查严格限制表外钨矿山产出。与此同时,钨出口实行严格的国营贸易管理,审批周期显著延长。 这种转变的战略意图十分明确:将中国钨产业的强势地位从上游延伸到下游,推动产业从中低档产品向中高档升级,完成高端硬质合金刀具等产品的国产替代与出海。 正如分析人士所言,“中国从源头上卡住了钨的出口,这不是意外,而是从‘资源国’向‘规则制定者’迈进的必然结果”。 日本正积极推动供应链多元化来应对 面对中国出口管制带来的供应链冲击,日本企业和政府正在加速应对。 据中国台湾驻日经济文化代表处报告,日本经济产业省已明确表示,关键矿物资源高度依赖特定国家存在风险,将加速推动供应来源多元化。具体措施包括: 三菱商事与哈萨克斯坦政府系金属资源公司签订数年期的镓供应契约; 双日商社与JOGMEC、美国铝业合作,在澳大利亚评估镓回收生产设备; 三菱材料通过并购德国回收企业HC Starck Holding,强化钨回收能力。 然而,这些替代方案从启动到量产仍需时间。在过渡期内,日本企业不得不面对成本上升、供应不确定的现实困境。富士精工的公告正是这一困境的缩影。
半导体材料
芯智讯 . 2026-04-16 1 4942

Vishay推出适用于GaN和SiC开关应用EMI滤波的新型航天级共模扼流圈
日前,威世科技Vishay Intertechnology, Inc.(NYSE 股市代号:VSH)宣布,推出一款新型航天级表面贴装共模扼流圈---SGCM05339,适用于严苛航空航天应用电磁干扰(EMI)滤波和噪声抑制。 Vishay定制磁芯SGCM05339是GaN和SiC开关应用的理想选择,这类应用的波形会出现锐边,导致电磁辐射干扰。共模扼流圈还可用于低电流立式电源、分布式电源系统DC/DC转换器,以及太阳能电池板功率转换器。 为应对应用环境的恶劣条件,这款自屏蔽器件采用紧凑坚固的纳米晶磁芯和过模塑成型加固结构。SGCM05339提供扩频高阻抗,支持的温升电流高达14.43 A,连续工作温度-55 C至+130 C。 日前发布的器件符合ASTM-E595标准多项筛查,包括MIL-PRF-27、Grade 5、Product Level T、Temperature Class S、MIL-STD-981 Family-4、Class S以及EEE-INST-002。SGCM05339耐压1000 VRMS,绝缘电阻为500 VDC,可根据匝数、线规等进行定制,满足特定应用的要求。 器件规格表: (1) ΔT上升约30°C时的串联绕组直流电流(A) 新型航天级共模扼流圈现可提供样品并已实现量产,供货周期为8至12周。
vishay . 2026-04-16 1260

兆易创新与吉利汽车共建联合创新实验室,携手迈进汽车发展新时代
业界领先的半导体器件供应商兆易创新GigaDevice宣布,于4月7日与国内先进汽车制造商吉利汽车共建联合创新实验室。双方将建立长期稳固的战略合作伙伴关系,聚焦座舱、车身、智驾等高性能的MCU应用,为中国汽车产业的智能化发展注入技术源动能。 (左)李传海 吉利汽车集团副总裁、吉利汽车研究院院长 (右)胡洪 兆易创新CEO 联合创新实验室将整合吉利汽车与兆易创新的优势资源,聚焦车身、座舱、智驾、动力、底盘等关键领域,开展全方位的协同创新。兆易创新将依托在车规级存储和MCU等产品线的深厚技术积淀,围绕客户需求,通过精准的产品定义与解决方案的落地,为吉利汽车整车平台提供高性能、高可靠、高品质的底层硬件保障。 (从左至右) 果鹏 吉利汽车智能硬件中心产品管理和架构主任工程师 蔡卫龙 吉利汽车智能硬件中心产品管理和架构负责人 李传海 吉利汽车集团副总裁、吉利汽车研究院院长 韦浩 吉利汽车智能硬件中心主任 李文雄 兆易创新副总裁、汽车事业部总经理 胡洪 兆易创新CEO 马思博 兆易创新副总裁、DRAM事业部总经理 王海洋 兆易创新中国销售部总经理 在车规芯片领域,兆易创新已构建起多元化的产品布局,其车规级存储与MCU均已实现规模化市场应用。截至目前,车规级Flash累计出货量超3亿颗,广泛应用于智能座舱、辅助驾驶等核心场景。在高算力微控制器方面,GD32A全系车规MCU累计出货量超800万颗,其中,GD32A7系列车规MCU已获得多个车型定点,覆盖多层级汽车应用。与此同时,兆易创新也在加速布局更高算力的下一代车规MCU产品,为中央计算等前沿架构提供可靠的算力保障。 吉利汽车集团副总裁、吉利汽车研究院院长李传海表示:“当前,芯片技术已成为驱动汽车产业迭代升级的核心力量。吉利期待依托双方优势深化汽车产业协同。此次联合实验室的成立,将有助于双方打通前瞻技术研究、产品选型与产业化落地链路,助力车规芯片技术在汽车场景的创新应用。我们愿与兆易创新务实推进各项合作落地,共同助力国产芯片与智能汽车产业深度融合、迈向全球化发展。” 兆易创新CEO胡洪表示:“汽车产业的技术迭代与国产芯片的发展相辅相成、相互成就。兆易创新高度重视与吉利汽车的合作,并将持续加码在车规级芯片领域的研发投入。本次联合创新实验室的成立是见证双方长期合作、携手前行的重要里程碑,我们期待与吉利汽车在车规存储和MCU芯片等方向展开深度课题研究,以技术协同为纽带,赋能吉利汽车供应链体系的完善,共同探索汽车智能化发展的无限可能。” 面向汽车AI融合发展的新时代,兆易创新与吉利汽车将依托联合创新实验室平台,持续深化从芯片定义到整车应用的紧密联动,聚焦技术创新与产业融合,推动中国智能汽车产业链迈向更高水平。
兆易创新 . 2026-04-16 1288
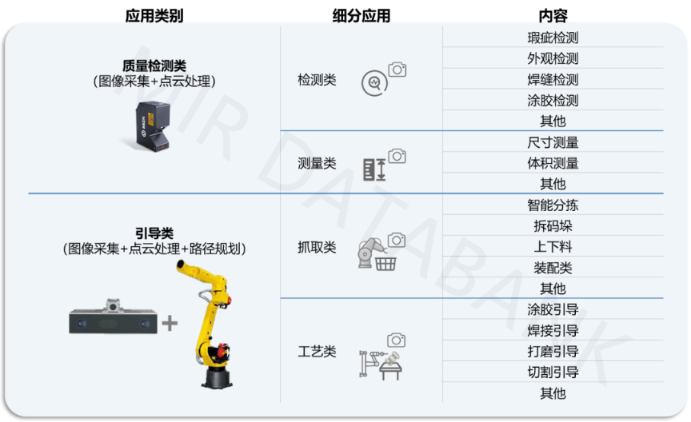
市场 | 《2026年中国工业3D视觉市场年度报告》发布,深度解析中国工业3D视觉市场 | MIR DATABANK
工业3D视觉,是指通过成像装置获取物体X、Y、Z三维坐标信息,并对相关信息进行处理的视觉系统,通常由工业3D相机、相机控制器等部分组成。根据应用场景不同,可划分为引导类与质量检测类两大方向:前者侧重于为机器人或自动化设备提供图像采集与路径规划支持如智能分拣、拆码垛、涂胶引导等,后者则聚焦于瑕疵检测、尺寸检测、外观检测等质量控制环节。 数据来源:《2026年中国工业3D视觉市场年度报告》 作为关键的感知与决策技术,工业3D视觉在人工智能、仿真及离线编程等技术体系持续演进的驱动下,近年来实现了快速的发展。自2020年起,中国已成为驱动全球工业3D视觉市场增长的核心动力。 2019-2028年中国工业3D视觉整体市场规模及增长预测 数据来源:《2026年中国工业3D视觉市场年度报告》 根据MIR DATABANK数据统计,2025年中国工业3D视觉市场实现高速增长,整体市场同比增长超20%,预计未来三年,中国工业3D视觉市场将继续保持高速增长。 工业3D视觉质量检测类产品市场分析 2025年中国用于检测测量场景的3D视觉产品市场销量超6万,延续稳健增长态势。其核心下游应用行业主要包括电子制造、汽车整车和锂电池、半导体等行业。当前,质量检测类市场增长由消费电子与半导体复苏主导。 2025年中国工业3D视觉质量检测类分行业市场规模(按销量) 数据来源:《2026年中国工业3D视觉市场年度报告》 电子行业的检测需求从传统3C产品拓展至柔性屏等高精密部件检测;半导体领域受AI芯片、智能汽车等产业投资拉动,线光谱共焦产品在封装测试环节的应用需求显著增长;人形机器人关节模组等高复杂精密部件的量产,带来了新的高精度3D检测需求;新能源汽车关键部件如轮胎、轮毂及控制器对质量的要求不断提高等,在多行业精密化升级与高端制造投资加速的背景下,上述因素叠加发力,共同推动了3D视觉质量检测类产品需求的快速增长。 2025年中国工业3D视觉质量检测类市场竞争格局对比情况(按销量) 数据来源:《2026年中国工业3D视觉市场年度报告》 从MIR DATABANK统计的数据看,目前外资厂商在质量检测市场中仍占据主导地位,尤其在电子、汽车、半导体等高端应用场景的头部客户中保持较高份额,2025年在高精尖场景出货量持续增加。其中,基恩士以24%的市场占有率位列中国工业3D视觉质量检测类市场第一,其与乐姆迈、康耐视等凭借高精度、高稳定性线扫相机产品,在电子行业柔性屏检测、汽车轮毂检测等细分行业取得持续订单。 近年来,随着国产厂商持续加大技术攻关与产品创新力度,并依托本土化生产和服务优势,国产替代进程明显提速,在锂电池、电子及一般工业等领域实现了规模化导入,市场渗透率不断提升。例如,深视智能在2025年工业3D视觉质量检测类市场的市占率提升至23%,位居国产第一,且公司已量产产品均已成功打破国外垄断。近年来,深视智能在锂电池、电子行业等高精密检测领域持续突破,市场份额持续扩大,进一步显示出本土品牌在中高端应用场景中的竞争力正逐步增强。预计未来,国产品牌在质量检测市场的整体市占率将进一步提升。 工业3D视觉引导类市场分析 2025年中国工业3D视觉引导类市场销量超1.8万台,同比增长达28%。引导类产品的核心下游应用行业主要包括汽车、金属制品、物流仓储等行业。其中,汽车产业是2025年工业3D视觉引导类市场的核心增长引擎。 2025年中国工业3D视觉引导类产品分行业市场规模(按销量) 数据来源:《2026年中国工业3D视觉市场年度报告》 在汽车整车与零部件领域,3D视觉系统不仅在国内终端工厂的导入增长,同时,随着终端车企出海步伐加快,国内系统集成商与设备商在海外项目中的参与度不断提升,带动3D视觉方案在海外用户端的导入也取得较大进展。 在锂电池环节,随着产品稳定性与测量精度获得市场验证,3D视觉开始批量化进入电芯搬运、模组组装等高精度工序环节,成为提升良率与自动化水平的重要技术支撑。 除汽车领域外,传统行业、具身智能等产业对3D视觉的需求也有同步增长。 从供应商竞争格局来看,当前引导类3D视觉市场呈现“一超多强”的格局,其中梅卡曼德以明显领先的市场占比位列第一,头部优势较为突出。随着头部供应商梅卡曼德、海康机器人等在日本、东南亚、美洲等地区持续开拓,已在汽车、物流等行业取得较大进展。预计未来中国厂商在全球工业3D视觉引导类市场的份额将持续增长。 2025年中国工业3D视觉-引导类市场竞争格局对比情况(按销量) 数据来源:《2026年中国工业3D视觉市场年度报告》 经过近几年的市场导入,各行业终端用户对引导类3D视觉的技术成熟度与应用价值已形成较为充分的认知,并逐步建立起相对稳定的供应商合作体系。在此过程中,内资厂商依托对垂直行业工艺的深度理解、解决方案整合能力以及本地化服务响应优势,逐步在各行业获取头部客户的广泛认可。预计未来较长周期内,内资企业仍将是中国引导类3D视觉市场的主要供给力量。 与此同时,国内市场逐步成熟也促使中国厂商加快全球化步伐。以梅卡曼德、海康机器人等为代表的头部企业,正持续在日本、东南亚及美洲等地区拓展业务版图,在汽车制造与物流自动化领域取得阶段性进展。随着产品稳定性与交付能力提升,中国厂商在全球工业3D视觉引导类市场的份额将持续提升。 3D视觉市场未来发展趋势 目前,随着3D视觉技术在各类应用中的成熟度持续提升,其应用范围已从传统优势领域延伸到锂电池等新兴行业当中。作为自动化系统的“眼睛”,3D视觉正成为越来越多场景的核心需求。预计未来三年,该市场将保持10%以上的快速增长,未来成长空间广阔。 2020-2028年中国工业3D视觉市场增长及预测情况(%) 数据来源:《2026年中国工业3D视觉市场年度报告》 从应用端来看,未来传统工业领域的需求预计整体将较为平稳。与此同时,新能源与电子等行业中对柔性化的应用场景的需求持续提升,将进一步推动3D视觉技术的应用。此外,随着具身智能与人形机器人等新兴产业的发展,3D视觉也将迎来一些新的应用机会。
3D视觉
MIR睿工业 . 2026-04-16 1 3297

企业 | 超30亿!中国迄今最大具身智能融资诞生
智东西4月16日报道,今天,上海具身智能创企它石智航宣布完成超4.5亿美元(约合人民币30.69亿元)Pre-A轮融资,创下中国具身智能有史以来最高单轮融资纪录。本轮融资的投资机构涵盖了四大维度: 财务投资者:高瓴创投、红杉中国联合领投,美团龙珠、中金资本、凯联资本、东方富海、钧山投资等知名财务基金跟投; 战略投资者:美团战投作为该公司重要的基石战略股东重额加注并继续联合领投,同时启明创投、线性资本、蓝驰创投、襄禾资本、洪泰基金等老股东也进行了战略投资加注; 产业投资者:TCL产投、孚腾资本、首程控股(0697.HK)、建发新兴投资、恒旭资本、国汽投资参投; 国有资本:北京机器人产业发展投资基金、上海国投先导首次联合投资具身智能公司。 它石智航成立于2025年2月,在成立不到半年的时间里,该公司就完成了累计2.42亿美元(约合人民币16.5亿元)的融资,创下中国具身智能有史以来最大天使轮融资记录: 2025年3月,该公司完成天使轮1.2亿美元(约合人民币8.18亿元)融资,由蓝驰创投、启明创投共同领投; 2025年7月,该公司完成1.22亿美元(约合8.37亿人民币)天使+轮融资,由美团战投领投,钧山投资、碧鸿投资、国汽投资、临港科创投等跟投。 硬件方面,它石智航已推出了轮式工业机器人A系列和双足通用机器人T系列。其中,A系列机器人可实现亚毫米级精度的装配操作。以线束装配为例,这是工业场景中典型的高难度精密操作任务,广泛应用于汽车制造、3C电子等领域。因为自动化难度极高,线束装配还被称作是工业自动化界的“哥德巴赫猜想”。 今年3月,A1机器人在1小时内完成亚毫米级柔性线束完整装配任务百余次,创下全新吉尼斯世界纪录,这也是中国具身智能企业在工业精密操作领域的首个吉尼斯世界纪录。 软件层面,它石智航设计研发了通用具身大模型AWE3.0。它石智航称,AWE3.0是全球首个“能干活”的通用具身大模型,具备物理世界精准感知、理解与规划能力,支持亚毫米级操作与长程稳定执行。 AWE3.0不仅可以让机器人在从未见过的新视角下,实现稳定可靠作业,还能大幅消除卡顿,让任务执行更为稳定丝滑、连续自然,使得机器人能够胜任精密装配、柔性制造等复杂场景。数据采集上,它石智航推出了SenseHub穿戴式具身数据采集系统。 SenseHub坚持以人为中心,打造了一套从感知、计算到传输的全链路融合解决方案,能够精准捕捉人类全身动作数据、触觉数据、多视角相机数据。 它石智航董事长李震宇,曾任百度智能驾驶事业群总裁,牵头打造了阿波罗自动驾驶开放平台和当前全球最大的无人驾驶出行服务平台“萝卜快跑”。 它石智航CEO陈亦伦,曾先后任职大疆机器视觉总工程师、华为自动驾驶CTO、清华大学智能产业研究院智能机器人方向首席科学家,是中国自动驾驶领域的产业领军人物。在华为期间,陈亦伦曾主导设计智能辅助驾驶系统ADS 1.0算法全栈、组建核心技术团队,推动产品商业化应用。 首席科学家丁文超,原华为“天才少年”,是具身智能领域青年科学家、复旦大学机器人研究院研究员,曾从0到1主导华为智驾端到端决策网络,打造复旦大学首个人形机器人。李震宇称,本轮融资将用于加速打造通用具身大模型AWE和持续吸引行业顶尖人才,下一轮融资将重点用于打造真干活、真量产的机器人。
智能眼镜
智东西 . 2026-04-16 1 2485

市场 | 洛图科技发布《中国智能眼镜行业发展现状及展望报告》
日前,“2026 AI眼镜中国行”论坛在深圳电子信息博览会期间召开。洛图科技(RUNTO)COO王育红女士受邀出席论坛,并发布了主题为《中国智能眼镜行业发展现状及展望报告》的主题分享。 2025年,全球智能眼镜市场迎来全面爆发,中国市场更是实现远超全球水平的高速增长。这一年,行业正式从概念普及迈向规模化落地,由小众尝鲜逐步走向大众消费。 在爆发式增长的同时,行业也暴露出电子产业发展进程中普遍存在的共性问题。站在2026年的新起点,洛图科技(RUNTO)以过往市场的表现为趋势研判依据,复盘行业发展脉络,试图预测中国智能眼镜市场的未来发展方向。 2025市场全面爆发,消费级时代正式开启 根据产品形态和产品功能,洛图科技(RUNTO)将智能眼镜划分为AR眼镜(有显示+有音频)、音频眼镜(无显示+有音频)和拍摄眼镜(无显示+有摄像头)。 根据洛图科技(RUNTO)数据显示,2025年,中国智能眼镜市场的销售量达145万台,同比增长211%。得益于Vlog创作、户外运动记录等场景的兴起,拍摄眼镜、AR眼镜、音频眼镜均收获了不同程度的关注度和销量增长,呈现三品类齐头并进的增长格局。 其中,拍摄眼镜表现尤为突出,大量跨界品牌的进入和华强北白牌的模仿,推动市场规模几乎实现了从零到51.7万台的突破。音频眼镜的销售量为44.8万台,同比增幅为134.6%。AR眼镜为48.9万台,同比增幅达83.2%,近乎翻倍。可见,各细分品类均形成了稳定的用户群。 2023-2025年 中国智能眼镜市场细分产品销量变化 数据来源:洛图科技(RUNTO),单位:万台 2025年,智能眼镜赛道大获资本芳心,投融资覆盖了上游核心供应链至终端品牌全链条。雷鸟创新、影目 INMO、XREAL 等头部终端品牌集中获投,等完成大额融资;上游微显示、光学方案厂商获数亿元级别注资;中国移动、中国联通等运营商资本战略入局,加速渠道渗透与规模化落地。文后附从2025年到2026年1月的中国融资事件统计表。 繁荣之下的隐忧,分析高速增长中的行业痛点 首先,行业高速增长的同时,高退货率与高MCN依赖两大泡沫问题突出。智能眼镜的退货率高达20%-50%,远超手机、智能平板等成熟的3C产品。用户退机的核心原因是功能鸡肋、佩戴不适。到2026年,市场逐渐传开“去魅时刻”的论调。 与此同时,智能眼镜的销售过度依赖达人带货,逐渐形成了营销层面的功能优点放大与真实体验之间的强烈落差,自然流量转化偏低,因而粘性用户不足。 第二,入局品牌良莠不齐,产品同质化加剧,整体产品力薄弱。2025年,中国智能眼镜市场持续升温,吸引了大量品牌涌入,不乏一些品牌采取快打快消策略,缺乏技术沉淀与产品打磨,以低价肉搏的方式推出大量低质产品,进一步加剧行业内卷。根据洛图科技(RUNTO)数据显示,2025年,非AR类的智能眼镜在线上市场的在售机型数量从第一季度的72款增至第四季度的353款,其中,拍摄眼镜的品牌数量已超过了100个。“百镜大战”不是虚指。 第三,产品、技术、生态亟待破局。当前,行业陷入了功能堆砌与实用缺失的矛盾,洛图科技(RUNTO)调研数据显示,功能实用性不足是AI眼镜市场占比最高的退货原因,刚需场景缺失,难以形成高频使用习惯。同时,产品存在时尚与科技割裂的问题,多数机型重硬件能力,轻时尚设计,无法适配日常的全场景佩戴需求。更重要的是,行业仍面临性能、轻量、续航难以兼顾的“不可能三角”。加之尚未形成独立完善的应用软件生态,共同制约着用户体验的进一步升级。 政策技术场景三重驱动,智能眼镜仍处黄金增长期 进入2026年,洛图科技(RUNTO)展望,尽管不少问题尚存在,智能眼镜行业在多重利好的推动下将继续稳健前行。 在政策层面,智能眼镜被首次纳入国补目录,并成为唯一新增品类,补贴比例为15%,最高500元。当从业者们还存在是否虚火的自我疑问的同时,智能眼镜已经成为了官方认证的下一代智能显示硬件终端。 其次,技术层面,成本与体验双向优化。随着国产光波导方案量产成熟、成本显著下降,双目全彩AR眼镜的价格门槛持续下探。端侧低功耗技术与结构设计同步突破,整机重量进一步收敛,行业轻量化竞争已深入克级比拼阶段。此外,独立终端化提速,智能眼镜正陆续实现去手机化,具备独立通信与多模态交互。 最后,在场景层面,行业正在进入垂直场景的深耕阶段。“AI+音频眼镜”实现智能降噪,音感补偿;“AI+拍摄眼镜”实现智能构图、剪辑,从记录走向创作;“AI+AR眼镜”有效平衡算力与续航,落地导航、场景识别等刚需应用。 基于此,智能眼镜正快速向影音、电竞、运动、办公、健康等细分场景,甚至专业行业领域渗透,为生态平台建设打开黄金窗口期,以真实好用的生态能力维护用户粘性。 洛图科技(RUNTO)预测,2026年,中国市场的整体销量将达320万台,同比大幅增长120%。更详细的数据,请关注洛图科技(RUNTO)即将发布的《2026年第一季度中国智能眼镜市场总结报告》。 附:中国智能眼镜行业融资事件不完全统计表 (2025年-2026年1月)
智能眼镜
Runto洛图科技观研 . 2026-04-16 2338
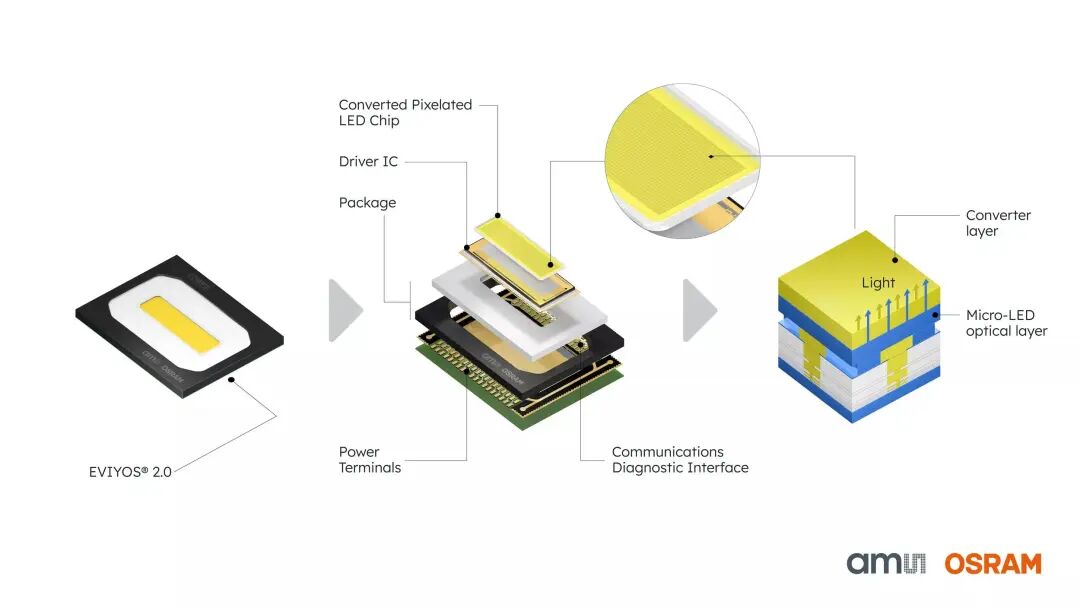
应用 | 车灯技术“杀入”数据中心!
全新光学互连技术助力数据中心提升带宽、能效与系统可靠性 microLED技术:从汽车前照灯到数据中心 谈及人工智能技术的演进,机器学习、大语言模型的发展成果自然浮现脑海,新一代图形处理单元(GPU)、高带宽内存(HBM)以及芯粒、异质集成等尖端半导体技术同样引人瞩目。 那么汽车前照灯领域又如何呢? 汽车照明技术虽非人工智能创新突破的典型代表,但“自适应远光”前照灯技术已证实:其光学连接方案在可靠性和扩展性方面的优异表现,恰好能够帮助数据中心运营商解决当前面临的网络带宽扩容、能效提升及可靠性增强等核心挑战。 让我们深入解析汽车前照灯与AI数据中心技术的内在关联。 数据传输瓶颈 急剧增长的AI训练与推理需求,正迫使设备制造商大幅提升系统算力。如今,得益于GPU、神经处理单元(NPU)等加速器(统称‘xPU’器件)能高速处理AI数据,计算功能本身不再是瓶颈。xPU设备间、xPU与内存间、乃至机架内服务器间的数据传输速率才是制约因素。 传统铜互连虽具成本优势且易于集成,却存在显著扩展瓶颈:在AI算力系统所需的传输距离(可达30米)下,铜互连需更高传输能耗、更强信号均衡及更复杂的信号调理,部分用于克服电磁干扰(EMI)。这导致铜链路功耗攀升、发热加剧,严重制约设备制造商提升带宽密度(Gbit/s/mm)、系统能效及可靠性的技术攻关。 因此,为提升网络带宽,数据中心转而采用光学互连技术。其技术原型源自互联网骨干网。那些通过数量有限的海底光缆(其铺设维护成本极高且难度巨大)承载洲际流量的企业,已掌握单缆吞吐量最大化技术。当今洲际光传输网络的单通道速率高达1.6Tbit/s。 这种“高速窄带”带宽提升方案追求在每条光通道内极限传输数据。但高频系统存在结构复杂、功耗高、成本昂贵等缺陷。更重要的是,每条链路都是影响全局的单点故障源,严重威胁系统可用性。随着单通道速率与吞吐量的每次提升,实施难度和成本呈指数级增长,“高速窄带”架构的扩展空间已日趋有限。 互联网基础设施因线缆成本高昂,运营商不得不追求单缆数据吞吐最大化。但数据中心不受此限制。 从单通道到数千通道的演进 数据中心领域因此日益关注新方案:与其追求“高速窄带”,不如采用“低速宽带”策略,即用数百乃至数千条低速并行光通道替代单一超高速链路,在采用更简单、廉价、低速组件的同时实现更高总带宽。 此类系统中,数据发射端可采用数百个microLED,替代互联网基础设施中的单一高功率激光源。由于数据通信设备制造商此前从未构建过由数百/数千个microLED发射器组成的并行光通道,“低速宽带”方案在数据中心领域尚属未经验证的技术路径。 “低速宽带”架构的核心能力,在于将数百个光发射器集成至服务器数据处理器与存储组件近端。鉴于AI需求永不停歇,数据中心运营商要求这些微型发射支持全年无休的可靠运行。而数千个microLED组成的芯片级阵列,已在严苛的汽车市场得到验证,这正是汽车前照灯为数据中心设备制造商带来的启示。 图1:EVIYOS产品将microLED阵列与驱动电路集成于紧凑封装 01 艾迈斯欧司朗EVIYOS™自适应远光源中的microLED技术,正是这些能力的集中体现。 02 单颗EVIYOS芯片集成25,600个microLED阵列单元,每个单元的尺寸仅为发丝直径的一半,通过CMOS驱动芯片以22.0mm×17.5mm微型封装实现系统集成。 03 25,600个“像素单元”均可独立控制,使前照灯能在路面投射复杂光型。此项microLED与CMOS驱动器的独特集成技术荣膺“数字光”德国未来奖,基于该技术的产品已在量产车型中验证其卓越可靠性与鲁棒性。 04 如今,相同技术正被改造应用于AI数据中心的超高带宽光学互连系统。 久经验证的微发射器技术 光学互连应用采用与前照灯相同的制造工艺,但存在关键差异:车灯中的microLED采用高密度单片式阵列结构,而数据连接需将microLED进行解键合处理,从制造晶圆上切割分离后贴装至基板,使每个发射器能独立连接光纤或光波导。该基板可后续集成至目标CMOS晶圆。 图2:高速光链路microLED可制造性实现路径 得益于microLED的微型化特性,采用该技术的数通收发器可实现超高带宽密度。艾迈斯欧司朗内部研究证实:在10米全链路中,microLED发射器可实现3.0Gbit/s的单通道速率,且单位比特能耗低于2pJ(皮焦耳),同时满足行业标准规定的低于10⁻¹⁵误码率(BER)要求。 通过以数百条并行连接替代单一超高速链路,AI设备制造商还可获得对数据中心应用极具价值的优势: 可靠性 - microLED可在系统中配置多重冗余通道。这意味着单个故障发射器可实现无感失效,并由备用通道自动接替。 能效性 – 在“低速宽带”架构中,每个发射器处于相对较低的开关频率(典型值约1GHz),较互联网基础设施的超高频激光发射器显著降低功耗。能耗降低同时减少废热产生,为设备运营商提供更充裕的热预算空间。 架构精简性 – “高速窄带”架构要求AI加速器中的并行数据流进行串行化传输与接收后解串行化处理。搭载艾迈斯欧司朗microLED的“低速宽带”架构具有原生并行特性,无需复杂且高成本的串行化解串方案。 携手数据通信产业 艾迈斯欧司朗作为欧洲唯一实现microLED规模化量产的制造商,其生产能力已获市场验证,自2023年起持续向汽车行业批量交付EVIYOS产品。 目前,艾迈斯欧司朗正与数据中心设备制造商展开深度合作,推动该技术在光学互连领域的应用转型,具体包括集成适配高频数据发射器的驱动电路,优化微型封装设计方案以及确保与商用光连接器、线缆及光纤的互操作性。 在此技术开发进程中,制造商可充分借助艾迈斯欧司朗全面的光学系统能力。公司同时具备microLED与光电二极管(光接收器)的量产能力,能够在全集成光学数据传输系统的开发中发挥核心作用。 图3:面向AI数据中心的超高带宽传输方案——集成microLED阵列与光电二极管接收器 基于microLED的光学互连集成概念设计现已完成。如需获取技术细节或探讨与艾迈斯欧司朗的联合开发机遇,欢迎随时与我们联系。
ams OSRAM
感光现象 . 2026-04-16 1 1582

产品 | 小体积・大驱动・更可靠,中微爱芯H桥直流双向马达驱动芯片——AiP6208C全新上市
【简介】 AiP6208C是无锡中微爱芯推出的单通道、低导通电阻H桥直流双向马达驱动电路,可实现电机待机、正转、反转、刹车四种控制功能,集成欠压与过温双重保护,具备宽电压、低功耗、小体积、外围极简等特点,广泛用于IR‑CUT、智能锁、消费电子等小型有刷直流电机驱动场景,是高性价比的微型运动控制解决方案。 【关键参数】 项目 规格 电源电压 2.8~15V 峰值输出电流 1A 持续输出电流 典型 0.6A 导通电阻 典型 3Ω 待机电流 典型 1μA 工作电流 典型 180μA 输入电平 0~5V 保护功能 欠压保护、过温保护(185℃) 封装形式 SOP8 工作温度 -40℃~+85℃ 【产品优势】 宽电压适配:兼容 3.7V/5V/12V 等主流供电,直接对接 3.3V/5V MCU,无需电平转换; 驱动能力强:1A峰值电流、低导通内阻,发热小、效率高; 超低功耗:μA 级待机电流,大幅提升电池供电设备续航; 可靠性高:过温/欠压自动保护,输入内置下拉电阻,抗干扰更强、运行更稳; 控制简单:两路 IO 即可实现正转/反转/刹车/待机,支持PWM调速,程序简化易编写,开发难度低; 小型封装:SOP8小型封装,外围电路极简,PCB布局紧凑,量产成本低。 【应用领域】 安防摄像:IR‑CUT 双滤光片切换驱动 智能家居:智能锁、智能窗帘、小型执行器 消费电子:电动玩具、美容个护、小型电动工具 IoT 终端:智能水表 / 气表阀门、传感器执行机构 创客与教学:小型机器人、DIY 电机驱动模块 【推荐外围】 【结语】 AiP6208C以其稳定可靠、低功耗、小体积、易开发的核心优势,成为微型直流电机驱动的优选芯片,助力消费电子、安防、智能家居等产品快速落地与升级,为设备运动控制提供高效、安全、高性价比的有力支撑。 中微爱芯H桥马达驱动系列产品如下: 型号 Part Number 名称及主要特点 Function 工作电压 Voltage Range 封装 Package L9110S 300mA直流电机H桥驱动电路 2.0~4.5V SOP8/TSSOP8/DFN8 L9110HS 300mA直流电机H桥驱动电路 2.0~6.5V SOP8/TSSOP8/DFN8 AiP6110* 300mA直流电机H桥驱动电路 3~12V SOP8/TSSOP8/DFN8 AiP6150 0.7A直流电机H桥驱动电路 VDD:3.0~5.5V VM:8.0~20V SOP8 AiP6150H 0.7A直流电机H桥驱动电路 VDD:3.0~5.5V VM:8.0~24V SOP8 AiP6151 1.0A直流电机H桥驱动电路 VDD:3.0~5.5V VM:8.0~20V ESOP8 AiP6151H 1.0A直流电机H桥驱动电路 VDD:3.0~5.5V VM:8.0~24V ESOP8 AiP6152H 1.0A集成5V LDO直流电机H桥驱动电路 8.0~24V SOP8/ESOP8 AiP6189 3A单通道直流马达驱动 3~13V SOP8 AiP6208 100mA直流电机H桥驱动电路 4.5~12V SOP8 AiP6208C 600mA直流电机H桥驱动电路 2.8~15V SOP8 AiP6133 双通道H桥电机驱动 2.7~10.8V TSSOP16/QFN16/ETSSOP16 AiP6137 PWM接口低压H桥电机驱动 1.8~11V DFN8/SOP8 AiP6138 PH/EN接口低压H桥电机驱动 1.8~11V DFN8/SOP8 AiP6142* 5A直流电机H桥驱动电路 8.2~45V HTSSOP28 AiP6143* 2.5A直流电机H桥驱动电路 8.2~45V HTSSOP28 AiP6146* 双路H桥步进电机驱动器 VM:4~18V QFN24 AiP6147* 双路H桥电机驱动器 VM:2.7~18V ETSSOP16/TSSOP16/QFN16 AiP6170* 3.6A直流电机H桥驱动电路 6.5~45V ESOP8 AiP3637 PWM控制型直流马达驱动 ±2.5~±20V DIP18/SOP20 注:产品名称带*表示为研发中 刘敏
马达驱动
中微爱芯官网 . 2026-04-16 735

方案 | 无刷强动力,锯切更给力——基于中微爱芯AiP8M7008的低成本电链锯解决方案
【行业介绍】 电链锯控制器专为直流无刷电机驱动的链锯类电动工具设计。用户仅需控制把手开关,即可开始切割工作,使用场景主要集中在林业采伐、木材加工处理、家庭与园艺DIY等场景。本方案支持上位机调试,借助上位机的参数实时显示功能,可高效辅助开发者完成产品开发,大幅提升方案开发效率。 【电链锯控制器整体解决方案】 该方案采用中微爱芯AiP8M7008芯片,AiP8M7008是一款电机专用8051内核MCU,内置256B的XRAM,256B的IRAM,8K的MTP ROM,并且内部集成了多种电机专用外设:多功能定时器模块,1路运算放大器,2路比较器,15通道12-bit高速ADC,支持UART通信。MCU外围电路简单,布板方便,能够快速二次开发并投入量产。 该款电链锯控制器搭载自研电机控制算法,能根据切割工况,实时匹配最佳工作逻辑,使切割效率达到最佳,让用户在日常使用中游刃有余。此外,该款控制器支持上位机调试,用户可对电机的启动状态进行调整,查看每次启动的参数信息;控制器调试运行过程中,还能实时监控运行参数变化,便于快速问题定位和优化。 【方案特点】 工作电压:DC14-24V 最大允许电流:40A(可根据需求进行调整) 使用温度:-20℃-120℃ 控制方式:把手开关启动、上位机调试 电机控制方式:无位置传感器方波控制 最大支持转速:0~50000eRPM/min 保护功能:过压保护、欠压保护、堵转保护、过流保护 本款电链锯控制器方案,具备工况自适应匹配算法,可根据实际工况自动调节转速和扭矩,使电链锯始终保持最佳切割状态。并且控制器具备多种保护功能,让每一次切割都稳定可靠,使用无忧。对比常见220V电链锯,其优势主要体现在其强大的扭矩、便携性以及工况时的稳定性能。 【方案实物/PCB/上位机/运行波形】 图(1)整机面貌 图(2)电链锯PCB正面 图(3)上位机调试界面 图(4)电机启动波形图 图(5)电机全占空比(100%)时波形图 【芯片资源】 适用电链锯的高性价比MCU: 主要参数 AiP8M7008 AiP8F7232S AiP8F7232 AiP8F7364 AiP32F7532 内核 1T 8051 1T 8051 1T 8051 1T 8051 M0 主频 16M 16M 64M 88M 60M IRAM 256B 256B 256B 256B 4K SRAM XRAM 256B 1K 1K 2K / ROM 8K MTP ROM 32K 32K 64K 32K+3K Timer 16bit×2 16bit×2 16bit×2 16bit×2 16bit×2 16bit×3 16bit×2 16bit×3 32bit×1 16bit×3 16bit×1 高速ADC 1Msps ADC 15×12bit 双ADC 9×12bit 双ADC 9×12bit 1Msps ADC (15+1) ×12bit 11×12bit OP 1ch 1ch 1ch 4ch 2ch轨到轨 运算模块 / / MDU MDU+Cordic 除法器 DMA / / / / 支持Timer/ADC/USART COMP 2ch 2ch 2ch 2ch 2ch 通信接口 1ch Uart 1ch Uart 1ch Uart 2ch Uart/1ch I2C 1ch SPI 1ch,支持UART和SPI 自带预驱 否 否 否 否 否 封装 SSOP28/QFN28 SSOP28 LQFP44/ LQFP48/SSOP28 SSOP28/LQFP48 TSSOP28/TSSOP20 SSOP28/SSOP20 QFN28/QFN20 适用电链锯的高集成带预驱MCU: 主要参数 AiP8F7201 AiP8F7201S 内核 1T 8051 1T 8051 主频 64M 16M RAM 256B 256B XRAM 1K 1K ROM 32K 32K Timer 16bit×2 16bit×3 16bit×2 16bit×2 高速ADC 双ADC 9×12bit 双ADC 9×12bit OP 1ch 1ch 运算模块 MDU / DMA / / COMP 1ch 2ch 通信接口 1ch Uart 1ch Uart 自带预驱 是 是 封装 QFN40 SSOP28 LDO 主要参数 AiP78L05 AiP78L12 输出电压 5V 12V 输入电压 7-36V 12-36V 最大输出电流 100mA 100mA 封装 TO92/SOT23-3/SOT89 TO92/SOT23-3/SOT89 MOS预驱 主要参数 AiP2164 AiP2163 AiP2119 支持电路 单相高低侧 单相高低侧 三相高低侧 芯片供电电压 10-20V 10-20V 10-20V 最高工作电压 225V 90V 90V 封装 SOP8 SOP8 TSSOP24/TSSOP20 电机可选用外置运放 主要参数 AiP358LV AiP324LV AiP8052 AiP8054 工作电压 2.5~5.5V 2.5~5.5V 2.5~5.5V 2.5~5.5V 是否轨道轨 是 是 是 是 通道数量 2 4 2 4 单位增益带宽 1M 1M 250M 250M 封装 SOP8/MSOP8 TSSOP8 SOP14 TSSOP14 SOP8 MSOP8 SOP14 TSSOP14 【结语】 中微爱芯电链锯控制器解决方案,以其高性能的MCU为核心,借助上位机平台的有效辅助开发,结合先进的电子控制技术和丰富的物料资源,为用户提供了稳定、可靠、智能化的电链锯控制方案。该方案在可靠性、工况稳定性以及切割平稳性上优势突出,是无刷电链锯方案中的理想选择。 如需了解更多产品资讯,请联系我司授权代理商或销售工程师。 马文博、杨杰、邓婷玉
MCU
中微爱芯官网 . 2026-04-16 728

企业 | 权威认证 以质致远,中微爱芯检测与实验中心正式通过CNAS国家实验室认可
【芯动态】权威认证 以质致远,中微爱芯检测与实验中心正式通过CNAS国家实验室认可 3月30日,中国合格评定国家认可委员会(CNAS)正式向无锡中微爱芯电子有限公司(以下简称“中微爱芯”)检测与实验中心颁发CNAS实验室认可证书(注册号:CNAS L25597)。CNAS作为国际实验室认可合作组织(ILAC)、亚太认可合作组织(APAC)的互认协议成员,其颁发的认可证书是实验室技术能力与管理水平的“国际通行证”。 CNAS认可检测实验室 中微爱芯检测与实验中心严格按照JEDEC和AEC相关标准要求建设检测能力,深耕车规级、工业级等领域芯片的可靠性测试技术;整合中微爱芯多产品线共性需求,逐步建立起自主可控的集成电路设计验证、全生命周期检测及失效分析能力。本次获得认可,标志着本中心的检测能力、管理水平已满足ISO/IEC17025标准及CNAS-CL01准则要求,检测结果将获得全球百余个经济体互认。 目前,检测与实验中心已具备AEC-Q100全项环境试验能力,同时拥有X-RAY、声学扫描分析等分析手段。未来,本中心将严格遵循ISO/IEC17025:2017《检测和校准实验室能力的通用要求》及CNAS-CL01《检测和校准实验室能力认可准则》的要求,持续强化检测能力和管理水平建设,不断提升检测服务的专业性、公正性和权威性,满足公司商业航天、汽车电子、低空经济、人工智能、新能源、服务器等不同市场的多样化检测需求,助力公司高端芯片市场的持续突破,为打造公司第二增长曲线提供强有力的品质保证。 CNAS实验室认可证书
CNAS实验室
中微爱芯官网 . 2026-04-16 644

产品 | 思特威全新推出搭载Lofic HDR® 3.0技术的50MP 1.0μm像素尺寸超高动态范围手机应用CMOS图像传感器
近日,技术先进的CMOS图像传感器供应商思特威(SmartSens,股票代码688213),全新推出5000万像素1.0μm像素尺寸超高动态范围手机应用CMOS图像传感器——SC575XS。 SC575XS基于思特威SmartClarity®-XL Pro技术平台打造,采用22nm Stack先进工艺制程,搭载思特威全新升级Lofic HDR® 3.0、SFCPixel®-2及AllPix ADAF®等多项先进技术,具备超高动态范围、低噪声、100%全像素对焦、低功耗等多项性能优势。作为1/1.56英寸1.0μm像素尺寸图像传感器,SC575XS凭借思特威全新Lofic HDR® 3.0技术,实现了白天夜晚皆出色的全场景超高动态范围拍摄效果,能够显著提升中高端智能手机主摄视频拍摄质感。 全新Lofic HDR® 3.0技术,超高动态昼夜皆精彩 基于思特威全新升级的Lofic HDR® 3.0技术,SC575XS实现了像素性能的全面优化,能够在傍晚、夜间等低光照场景下,为手机摄像头带来更出色的高动态范围效果,显著提升中高端智能手机主摄的照片及视频拍摄质感。 超高动态范围高帧率视频 作为1/1.56英寸1.0μm像素尺寸图像传感器,SC575XS在思特威全新Lofic HDR® 3.0技术加持之下,最高动态范围可达110dB*,较前代双帧HDR技术产品动态范围提升约25dB,大幅领先于行业同规格竞品。因此,即使在明暗对比强烈的拍摄环境中,SC575XS也能够帮助手机摄像头捕捉到光影生动、明暗有致的高动态范围影像。并且,思特威Lofic HDR® 3.0技术由单次曝光下的三帧融合实现,能够有效抑制运动伪影的产生,可帮助智能手机摄像头轻松应对运动场景下超高动态范围视频的拍摄,保障视频清晰无拖影。 此外,SC575XS可支持4K 120fps 100% PDAF 超高帧率视频及HDR模式下4K 60fps高帧率高动态范围视频拍摄。超高帧率能够显著提升智能手机摄像头的视频拍摄质感,灵活满足多样化影像功能模式开发与专业化创作需求。 像素性能优化,超高动态昼夜皆精彩 思特威全新Lofic HDR® 3.0技术针对LOFIC帧进行了像素性能的全面优化。与前代技术相比,Lofic HDR® 3.0具备更好的夜间成像表现,可支持LOFIC帧高增益,显著提升Lofic HDR®模式下手机摄像头在夜间的高动态范围视频拍摄效果,并且有效优化多帧融合中画面明暗区域的过度效果,让光影质感更自然生动。得益于此,SC575XS在傍晚、夜间等低光照场景下有着卓越的超高动态范围成像质量,无论白天黑夜,都能帮助手机摄像头捕捉到明暗有致、光影分明的高清高动态范围视频。 专利SFCPixel®-2技术,出色噪声抑制性能 作为5000万像素1.0μm像素尺寸图像传感器,SC575XS创新搭载思特威专利SFCPixel®-2技术,在实现更高的灵敏度的同时有着出色的噪声抑制性能,其读取噪声低至0.85e-,能够在阴天、傍晚、夜间等光线不充足环境中,有效提升成像质量,帮助手机摄像头捕捉到细节清晰、画面细腻的高清影像。 双模式快速对焦,清晰高速闪拍 SC575XS搭载思特威AllPix ADAF®与Sparse PDAF™技术,可支持100%全像素对焦与6%部分像素相位检测对焦两种快速对焦模式。在光线较差的低光照环境下,SC575XS可使用AllPix ADAF®模式,通过100%全像素对焦,实现高速稳定对焦,帮助手机摄像头解决暗光对焦难题。在光线充足的日常环境下,则可切换至Sparse PDAF™技术,通过6%部分像素相位检测对焦,在保障准确对焦效果的同时节约功耗。 更低功耗,整机续航无忧 基于思特威先进的SmartClarity®-XL Pro技术平台,SC575XS采用全新超低功耗技术方案,实现了功耗的显著优化。在4K Lofic HDR® 3.0高清视频模式下,SC575XS功耗仅约430mW,有利于减少高清超高动态范围视频拍摄中的手机发热,延长最大视频拍摄时长,提升Lofic HDR® 3.0模式的场景利用率,为智能手机影像策略配置提供更高灵活性,保障整机续航。 目前SC575XS已接受送样,预计将于2026年Q2实现量产。想了解更多有关SC575XS的产品信息,请与思特威销售人员联系。 *在20bit位宽(HG帧和LOFIC帧1024:1的ratio)条件下,SC575XS动态范围最高可达110dB。
思特威
思特威 SmartSens . 2026-04-16 1827

应用 | “看听说动”全融合,移远Q-Robotbox让机器人开发“一步觉醒”!
4月15日,GEIA Asia 2026亚太具身智能与人形机器人创新周在上海拉开序幕,移远通信携多模态智能机器人平台Q-Robotbox精彩亮相,凭借创新的交互设计与开箱即用体验,吸引现场广泛关注。 作为一款专为机器人打造的一体化平台,其深度融合“视觉、听觉、动觉”的多模态交互架构,采用开箱即用的集成化设计,可为AMR(自主移动机器人)、智能割草机器人、助力外骨骼、辅助驾驶轮椅、商用清洁机器人与陪伴机器人等提供高集成度、低部署门槛的算法验证与快速开发底座,有效助力机器人从“机械执行”向“智能互动”实现关键跨越。 当前,伴随具身智能与人形机器人产业化浪潮加速涌来,行业开发者普遍面临多模态感知集成复杂、边缘侧AI算力资源紧张、算法从仿真到实机迁移成本高昂等核心挑战。 为破解这些难题,Q-Robotbox依托地瓜X5高性能芯片平台,搭载SH602HA-AP智能模组,将双目相机、环形灯带、麦克风阵列、高保真扬声器与多功能可动摇臂深度集成,实现了“看、听、说、动”四位一体的自然交互闭环。 移远通信产品总监史德锋表示:“机器人行业正从‘功能执行’向‘智能交互’加速演进。Q-Robotbox首次将10 TOPS NPU算力与‘看、听、说、动’全模态交互能力集成于一个紧凑、开箱即用的平台中,专注于解决原型验证阶段的效率问题,大幅降低多模态算法部署门槛,帮助开发者快速验证各类核心场景的算法效果。它将成为高校教学、创意开发与产业预研的高效能加速器。” 从“单点感知”到“多维协同”:为机器人装上“灵动感官” Q-Robotbox不是冰冷的机器人开发平台,而是一套软硬件深度协同的多模态交互系统。 1.看 搭载双目相机,支持高精度深度感知与复杂环境理解,高效适配SLAM、目标识别等视觉算法。 2.听 内置高性能麦克风列阵,实现语音唤醒、精准声源定位与清晰指令采集。 3.说 配备高保真扬声器,支持自然流畅的语音合成与主动播报。 4.动 独创的多功能可动摇臂,可完成细腻的动作反馈与拟人化姿态表达。 此外,平台创新的环形灯带设计进一步增强了状态可视化与交互友好性,让机器人的每一次“表达”都更自然直观。 算力精准匹配,为原型验证按下“加速键” 凭借10 TOPS NPU 的实用边缘算力配置, Q-Robotbox 在功耗与性能之间取得了黄金平衡,能够高效运行主流轻量级深度学习模型,并实时处理多传感器融合数据,显著降低算法从仿真环境迁移至真实场景的验证成本与门槛。 平台已精准适配各类机器人细分领域的核心算法验证与开发,无论是企业产品原型预研、高校教学实验,还是创意开发与智能交互展示,Q-Robotbox均可帮助用户快速搭建多模态AI项目,大幅缩短从概念到原型的迭代周期。 开放灵活:让机器人开发像搭积木一样自由 Q-Robotbox在设计之初便将“开放”作为核心设计理念,提供标准化硬件接口与软件适配能力,支持用户灵活定义算法模型并进行二次开发。其高度集成形态不仅降低了硬件搭建与系统联调成本,更为教学演示、创意验证及产业预研场景提供了稳定一致的参考平台。 在应用落地方面,该平台模组已在智能割草机器人、助力外骨骼、智能驾驶轮椅等多个场景完成算法验证与实机适配,效果均达预期。目前,Q-Robotbox正持续拓展部署范围,加速多模态智能机器人从研发到量产的进程。 作为具身智能生态的“核心构筑者”,移远已构建起从核心模组、开发平台到多元解决方案的全链路服务能力。 未来,移远通信将持续深耕多模态机器人开发平台,围绕感知精度、运动控制、语音交互等差异化需求,规划推出多款定制化Q-Robotbox系列产品,致力于打造从算法开发到量产落地的全链路加速平台,携手产业伙伴共同迎接多模态智能机器人时代的全面到来。
移远通信
移远通信 . 2026-04-16 1218
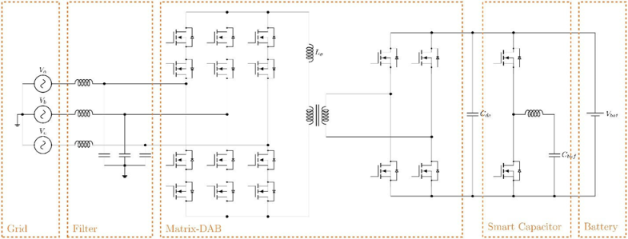
技术 | 功率密度升至2.4kW/L:拆解11kW矩阵式OBC的实现路径
随着全球电动汽车市场对充电效率与架构灵活性的要求不断提升,OBC技术正迎来从繁至简的变革。为了深度拆解这一前沿趋势,我们将通过两篇系列文章介绍11 kW矩阵式OBC创新方案。本文将聚焦安森美(onsemi)11kW 矩阵式 OBC 核心技术详解与器件应用解析。 11kW矩阵式车载充电机-硬件设计师访谈 Daniel Goldmann拥有电气工程与信息技术专业的工学学士(B.Eng.)和理学硕士(M.Sc.)学位,目前正在攻读博士学位。他曾担任大学研究员,自2023年起加入安森美,在分析未来系统应用趋势的同时,致力于开发下一代半导体技术。其主要研究方向包括电力电子系统多域仿真,以及面向各类汽车与工业应用的交流/直流转换器控制技术。 1. 安森美针对该设计和拓扑提供了哪些产品? 我们提供符合车规认证的栅极驱动器和辅助电源解决方案,用于驱动碳化硅(SiC)功率器件,并同步供应此类功率器件本身。该单级矩阵式OBC在所有工况下均可实现全软开关,这意味着功率器件的开通损耗可以忽略不计。因此,理想的器件应具备快速、低损耗的关断特性以及低导通电阻(RDS(ON))。安森美的EliteSiC MOSFET正是理想之选,例如顶部散热封装的23 mΩ、650V M3S系列器件NVT2023N065M3S。M3S技术采用平面半导体结构,确保器件在整个寿命周期内RDS(ON)、阈值电压VGS(TH)和体二极管压降稳定无漂移,同时保证负栅极驱动电压下的可靠工作。 2. 该演示设计包含哪些主要电子元器件和电路? 该设计可分为两部分:第一部分是矩阵式OBC,它将电网侧交流电转换为直流电,同时控制功率流实现电气隔离。所有这些功能集成于单一转换级,从而带来前述优势。然而,在单相供电时,矩阵OBC输出端会出现100/120 Hz的功率脉动。若电动汽车电池可接受该纹波,则无需额外处理;若要求输出纹波较低,则需有源滤波。这就引出了演示设计的第二部分,即“智能电容”,它是一种有源滤波元件,在单相电网输入时用于平滑输出功率,直至达到规定的纹波要求。 图1. 单级矩阵式DAB转换器与智能电容滤波示意图 3. 您的设计如何同时兼容北美和欧洲充电标准,从而避免为同一款车型开发两种不同的OBC? 本演示设计可在额定功率下兼容三相(欧洲标准)或单相(北美标准)电网供电。在单相运行模式下,A相和B相连接至电网一侧,C相连接至另一侧。C相所用的半导体器件的导通电阻RDS(ON)仅为A相和B相的一半,从而即使在单相电网供电下,也能实现高效功率转换。A相与B相之间的电流则通过电网侧滤波器实现平衡。 4. 针对电动汽车电池,OBC在应对转换器输出电流纹波方面的主要设计要求是什么? 目前市场上对OBC的要求各不相同:有些要求输出纹波非常低,而另一些则相对宽松。然而,大量研究表明,在电池充电过程中,100/120 Hz的脉动功率流可能对电池造成损害。我们预计未来会有更多整车厂(OEM)接受较为宽松的纹波要求,这将使矩阵式OBC无需使用有源滤波器,进一步凸显其相比传统拓扑,在减少元器件数量方面所带来的优势。 5. 矩阵式双有源桥(Matrix-DAB)后端采用智能电容替代传统无源输出滤波器。这种新型电容为何被称为"智能"解决方案? 这是因为Bulk电容通过半桥转换器连接。该设计使得电容电压能够在较大范围内波动,同时保持输出电压稳定,能够更充分地利用电容器存储的能量。虽然这种方案需要为物料清单增加额外的半导体器件和磁性元件,但减少了Bulk电容后,在重量、体积和成本方面的优势远超这些新增元件。 6. 目前正在测试的演示设计改进版(第2版)功率密度高达2.4 kW/L。实现功率密度提升一倍以上的关键设计改进是什么? 实现功率密度倍增的关键设计改进在于元件布局的优化。散热器被设计为多面散热:顶面用于交流侧开关矩阵散热,底面用于直流侧整流开关和智能电容散热,正面则用于集成电感的变压器散热。结合变压器结构的进一步改进,最终实现了更高的功率密度。 图2:11 kW 矩阵式OBC设计演进:演示设计的新旧版本对比 7. 您能解释一下在此演示设计中所采用的开环控制概念吗? 这一开环控制概念是我在攻读博士学位期间研发的。它仅需检测交流侧电压和直流侧电压,无需检测流经变压器的高频电流,从而显著降低了对检测的需求。此外,该方法为单级矩阵式双有源桥(Matrix DAB)设计了多种调制策略,确保在所有工作条件下都能实现软开关——即使在需要与电网交换无功功率的情况下也不例外。 8. 能否简要介绍一下您所开发控制算法的核心组成部分? 控制算法在一个包含处理器和FPGA的系统芯片(SoC)上运行。处理器负责完成电网同步和DQ坐标变换,并执行开环控制——包括矩阵式双有源桥(Matrix DAB)的调制计算,以及与FPGA的接口通信。FPGA 负责换相控制,根据开环算法计算出的开关时序对 DAB 进行调制,并管理交流侧开关矩阵(采用多步换流,为原边电流提供续流路径)。 9. 由于该演示设计本质上是一种隔离式AC-DC功率拓扑,除电动汽车之外,在其他应用领域是否有潜力? 是的。任何需要隔离式AC-DC变换的场合都可以使用这种拓扑。例如,服务器电源、固态变压器等众多应用。 顶部散热封装如何革新EliteSiC MOSFET的热性能 为满足OBC应用日益严苛的需求——包括更高的功率密度、更低的损耗以及显著提升可靠性——安森美推出了采用顶部散热 T2PAK 封装的全新 EliteSiC MOSFET。 本演示设计在其功率级中采用了 650V T2PAK MOSFET,显著提升了热性能、增加了功率密度,并优化了开关特性。T2PAK 是一种专为满足汽车和工业高压(HV)应用严苛标准而设计的顶部散热封装。可实现与外部散热器或金属外壳的直接热接触,将热量高效导离主印刷电路板(PCB),从而大幅改善整体散热性能。 低寄生电感的紧凑型设计 T2PAK 封装通过取消长引脚,相比 D2PAK 或 TO-247-4L 封装实现更紧凑的电流回路,显著降低了寄生电感。这带来了更优的开关性能:电压过冲更低,电磁兼容性(EMC)更好,使其成为OBC等紧凑型高性能电源应用的理想选择。 此外,T2PAK 的爬电距离超过 5.6 mm,确保符合 IEC 60664-1 标准。 图注:EliteSiC MOSFET T2PAK 引脚定义 安森美推出首批四款采用 T2PAK 封装的 EliteSiC MOSFET,依托先进的 M3S SiC 技术实现车规级性能。 安森美推出首批四款采用 T2PAK 封装的 EliteSiC MOSFET,依托先进的 M3S SiC 技术实现车规级性能。下方表格汇总了这些器件的关键特性。 表: 采用T2PAK 封装 EliteSiC MOSFET 的关键特性(符合 AEC-Q101 认证) 优化的散热与电气设计 要实现系统峰值性能,需要在外露的漏极焊盘与散热器之间建立稳固的热界面。除了结到外壳的热阻(RθJC)之外,整体热性能还高度依赖于合理的导热叠层以及高导热性热界面材料(TIM)的选用。精确地应用热界面材料能确保一致的散热性能和长期可靠性。 与底部散热封装相比,顶部散热器件在降低换流回路中的寄生电感方面也具有显著优势。这种设计使得PCB上的电气布线更加灵活,并能实现更紧凑、更优化的换流回路,从而直接降低开关损耗,提升系统整体性能。
安森美
安森美 . 2026-04-16 1547

产品 | Microchip扩展dsPIC33A DSC产品系列,专为高密度AI数据中心电源、复杂电机控制及智能传感应用而设计
随着AI服务器、数据中心、汽车及工业系统对更高效率设计、确定性实时控制以及抗量子加密技术的需求不断增长,Microchip Technology Inc.(微芯科技公司)在dsPIC33A DSC产品系列中新增dsPIC33AK256MPS306数字信号控制器(DSC)。该系列器件将高分辨率控制、高速模拟性能与安全性相结合,并支持后量子加密技术。这些器件结构紧凑且具成本效益,旨在降低物料清单(BOM)成本、简化电路板布局,并缩短电源转换、电机控制和智能传感应用的开发周期。 dsPIC33AK256MPS306系列基于200 MHz 32位内核,配备双精度浮点运算单元(FPU),集成高分辨率78 ps脉宽调制器(PWM)、多个40 MSPS 12位模数转换器(ADC)、5 ns高速比较器以及带斜率补偿的数模转换器(DAC)。这些特性有助于实现快速、确定性的控制环路,适用于高效率DC/DC转换器、辅助电源轨和智能传感设计,包括基于碳化硅(SiC)和氮化镓(GaN)功率半导体的高频开关系统。 Microchip负责数字信号控制器业务部的公司副总裁Joe Thomsen表示:“我们发现客户不再局限于关注单个组件,而是更看重将系统快速、可靠落地的能力。这些数字信号控制器(DSC)通过在单一器件中集成广泛的控制、模拟及安全功能,满足了客户需求。这种集成特性,结合完善的开发生态系统,帮助团队从早期设计到最终部署,全流程有效应对系统复杂性,并满足不断演变的性能及网络安全要求。” 为应对日益增长的网络安全需求,dsPIC33AK256MPS306系列集成了硬件安全特性,可实现安全启动、安全固件更新及安全调试。该器件支持商业国家安全算法(CNSA)2.0套件推荐的后量子加密(PQC)算法库,并具备开放计算项目(OCP)电源及其他联网实时控制设计所需的硬件加速加密功能。实时更新支持可实现不中断的全流程固件更新,满足现代服务器设计的需求。 该系列器件具备I3C连接功能,可支持现代服务器及工业机架中可扩展、低延迟的遥测与传感器网络,同时配备CANFD、LIN、SPI、I2C及SENT等其他通信接口。 凭借20 ns的三角函数(正弦和余弦)快速执行能力,dsPIC33A内核架构助力设计人员实现响应迅速的位置控制及高效的磁场定向控制(FOC)算法。dsPIC33AK256MPS306系列包含机械电机反馈接口,支持双向串行同步(BiSS-C)、EnDat、正交/光学编码器及旋转变压器。结合高度的模拟集成,该器件可实现高分辨率、高精度的实时控制闭环,有助于提升电机控制算法的整体性能。 集成式触摸控制器(ITC)及具备内置过采样功能、分辨率高达 16 位的40 MSPS ADC旨在简化复杂传感及人机交互应用。这种高度的集成能力可减少对外部组件的需求,让设计人员无需额外硬件即可实现增强功能。此外,紧凑的封装选项也为空间受限的设计提供了有力支持。 该系列器件遵循汽车(ISO 26262)及工业(IEC 61508)功能安全流程开发,包含硬件安全特性,助力简化安全关键型应用的认证流程。dsPIC33AK256MPS306 DSC 将通过车规认证,支持高达 150°C的工作温度。 开发生态系统 该系列器件由Microchip完善的开发生态系统提供支持,包括MPLAB® X集成开发环境(IDE)、MPLAB代码配置器和MPLAB机器学习开发套件。dsPIC33AK256MPS306器件现已支持Zephyr®实时操作系统(RTOS),为设计人员提供开源生态系统的访问权限和构建可扩展嵌入式应用的统一平台。 此外,dsPIC33A DSC兼容FreeRTOS™、SafeRTOS®(已通过认证)和wolfCrypt®库(包括对后量子加密的支持)、Vector的MICROSAR IO,并支持Lauterbach的TRACE32®调试和追踪工具。 为便于评估和快速原型开发,Microchip提供dsPIC33AK256MPS306电机控制双列直插模块(DIM),可与MCS MCLV-48V-300W开发板和MCHV-230VAC-1.5kW电机控制高压开发板配合使用,支持可扩展的低压和高压电机控制开发。dsPIC33AK512MPS506数字电源插接模块(PIM)兼容数字电源开发板,适用于电源转换应用场景。此外,通用型dsPIC33AK256MPS306 DIM可用于dsPIC33 Curiosity平台开发板,为通用控制、传感和系统评估提供灵活平台。更多信息请访问www.microchip.com。 通过MATLAB®支持基于模型的设计,以及Microchip日益丰富的电源和电机控制参考设计库,进一步加速开发和系统集成。 供货与定价 dsPIC33AK128MPS103-I/M7现可批量采购,单价为1.20美元。客户可直接向Microchip采购https://www.microchipdirect.com,或联系Microchip销售代表或全球授权分销商https://www.microchip.com/en-us/about/global-sales-and-distribution。
Microchip
Microchip微芯 . 2026-04-16 1050

应用 | 东风天元智舱Plus平台搭载黑芝麻智能武当C1296芯片,打造首个本土舱驾一体量产化平台
4月15日,黑芝麻智能宣布,东风天元智舱Plus舱驾一体量产化平台搭载其武当C1296芯片,双方达成平台级合作。作为首个本土舱驾一体量产化平台,天元智舱Plus以单芯片同时支持智能座舱、L2+行车辅助及FAPA泊车功能,将率先搭载于东风集团旗下标杆车型东风奕派007,计划2026年内至2027年陆续实现多款车型规模化量产。 天元智舱Plus平台 作为天元智舱系列的主力平台,天元智舱Plus为用户带来的体验升级贯穿智能座舱与智能驾驶两大场景。在座舱内,用户可享受3D沉浸式车控与智驾SR渲染带来的直观交互,增强现实车道级导航将感知信息叠加于实景路面,而AI大语言模型个人助手则能理解自然对话,一步完成媒体搜索、车辆控制、生活服务等复杂指令。同时,平台支持手机、平板、穿戴设备的多端无缝互联,让数字生活从车外自然延伸到车内。智驾层面,天元智舱Plus依托多模态感知融合能力,从容应对L2+级全场景行车需求,配合FAPA融合自动泊车与PDC停车距离控制,行车与泊车的核心安全场景全部覆盖。从座舱到智驾的无缝体验,源于硬件级的深度融合与统一调度,这正是行业从“功能堆砌”向“体验融合”转型的方向。 这些卓越体验的背后,是黑芝麻智能武当C1296芯片提供的核心算力支撑。作为首个本土舱驾一体量产芯片,C1296采用7nm车规级工艺,单芯片实现座舱、智驾、网关、MCU车控四大域的硬件级融合,打破传统功能域边界,实现资源统一调度。性能层面,通过算力跨域动态调度与片内通讯、内存共享,显著降低延迟的同时提升资源利用率,在保障极致体验的前提下实现成本最优。得益于C1296硬件级低功耗优化,天元智舱Plus无需液冷即可稳定运行。 武当C1296芯片 安全层面,C1296已通过汽车功能安全的最高等级标准——ISO 26262 ASIL-D产品认证,为整车稳定运行提供了坚实保障。此外, C1296支持多路高清显示、Unity 3D渲染引擎,并兼容12路摄像头、5颗毫米波雷达及12路超声波雷达的接入,为丰富的外设扩展提供了充分空间。 从多芯片到单芯片,从高端专属到主流标配,舱驾一体技术正在加速普及,并逐步成为入门级车型的智能化标配。随着天元智舱Plus平台的量产落地,武当C1296芯片将赋能东风更多车型,让舱驾一体方案走向平台化规模应用。黑芝麻智能将继续携手东风等合作伙伴,让安全、智能、沉浸的出行体验真正走进千家万户。
黑芝麻智能
黑芝麻智能 . 2026-04-16 882

产品 | 纳芯微推出新一代隔离式CAN收发器NSI1150,支持±70V总线保护耐压和更高的通信速率
纳芯微今日宣布推出全新工规级隔离式CAN收发器NSI1150,新器件基于纳芯微第三代隔离技术,提供±70V的总线保护耐压和高达±150kV/μs(典型值)的CMTI,可靠性和抗扰性相比前代产品(NSI1050)实现了全面提升,NSI1150亦集成了纳芯微自研的CAN FD收发器,可提供高达5Mbps的通信速率。 NSI1150支持SOW16,SOW8,SOP8,SOWW8,DUB8等多种封装,满足用户的多样化设计需要,可广泛适用于工业自动化与控制、能源电力、通信与服务器等高电压、强干扰、多节点的应用场景。 可靠性全面升级,应对严苛应用需求 NSI1150在可靠性与抗扰性上实现了业内领先的水平,以±150kV/μs(典型值)的高CMTI与±70V的总线保护耐压,轻松应对严苛场景中的强电磁干扰与地电位差挑战。 此外,NSI1150全引脚支持±6kV HBM ESD防护与10kV隔离栅浪涌耐受,确保极端环境下的稳定通信;隔离耐压覆盖3kVRMS,5kVRMS,7.5kVRMS多档选择,满足各类应用的严苛安规需求,为工业自动化、能源电力等关键场景筑牢安全屏障。 多种封装可选,支持多样化设计需要 NSI1150提供SOW16,SOW8,SOP8,SOWW8,DUB8五大主流封装选择,适配不同设计的空间与安规需求。其中新推出的SOWW8超宽体封装凭借高达15mm的爬电距离优势,可从容应对光伏、充电桩、工业电源等领域对爬电距离的强制要求,简化安规认证流程,为高功率密度系统设计提供更灵活的布局空间。多封装的矩阵化产品族,进一步支持了用户多样化的设计需要,提高系统落地效率。 NSI1150系列选型表 丰富的“隔离+”产品,引领隔离芯片标杆 凭借在隔离技术方面的积累和领先优势,纳芯微提供涵盖数字隔离器、隔离采样、隔离接口、隔离电源、隔离驱动等一系列“隔离+”产品。纳芯微正以全生态“隔离+”产品矩阵,为高压系统筑造安全可靠的防线: “+”代表增强安全:纳芯微“隔离+”产品提供超越基本隔离标准的安全等级,为客户系统构筑更坚固的高低压安全边界。 “+”代表全产品生态:纳芯微以成熟的电容隔离技术IP为核心,拓展出包括数字隔离器、隔离采样、隔离接口、隔离电源、隔离驱动等完整产品组合,为客户提供隔离器件的一站式解决方案。 “+”代表深度赋能应用:纳芯微“隔离+”产品可满足电动汽车高压平台、大功率光储充系统,以及高集成、高效率AI服务器电源等场景的核心需求,实现系统级安全、可靠与高效。 纳芯微全面的“隔离+”产品布局,以核心技术IP和全产品生态,引领隔离芯片标杆,为不同客户提供一站式的隔离芯片解决方案。
纳芯微
纳芯微电子 . 2026-04-16 1008
企业 | 算力筑基,算法赋能,登临科技与光束慧联协同创新,共筑国产AI新基石
近日,苏州登临科技股份有限公司与成都光束慧联科技有限公司达成深度合作,依托登临科技自主研发的GPU+架构,共同打造国产化AI智能平台。该平台深度融合国产算力芯片与行业AI算法,为矿山、能源及工业领域的智能化升级注入全新动能,实现从底层硬件到上层应用的全链路国产化。目前,双方合作成果已延伸至1000余座矿山,持续拓展能源行业智能化边界。 GPU+技术凭借其强大的算力、高效的能效比和灵活的部署能力,正在成为推动矿山、能源及工业领域发展的关键引擎。矿山 AI 智能化平台以登临科技创新 GPU + 架构为算力核心,全面赋能矿山日常作业、远程巡检、远程协助、应急救援等多元场景,助力矿山实现安全生产、高效运营与可持续发展。 GPU+架构的核心优势 登临科技的 GPU+架构兼具 GPU 的通用性与 ASIC 的高效率,提供从算力到能效的全面解决方案。 卓越的能效比:通过创新的可扩展、软件定义的片内异构体系结构,实现了能效比的大幅提升。其代表产品如 KS38,在典型 AI 场景的性能超过国际主流旗舰产品 1.5-4.5 倍,而能效比达到竞品的 3-5 倍。 高度的生态兼容性:硬件兼容 CUDA/OpenCL 等现有软件生态,算法模型可平滑迁移,极大节约了企业的移植成本和开发周期。 强大的算力与内存支持:登临纳适™II 系列工业加速卡提供了从 70 TOPS 到 560 TOPS 的有效 AI 算力,以及 8GB 至 128GB 的大显存配置,为处理高分辨率图像、复杂缺陷分类等计算密集型任务提供了坚实基础。 全栈国产化与自主可控:坚持自主创新,核心 IP 全自研,已申请国内外各类知识产权 200 余项。产品支持 Windows10、Linux、麒麟等系统,并兼容各类国产 CPU,确保了从硬件到软件的全国产化能力。 产品矩阵与应用场景 登临科技构建了完整的 GPU+产品线,涵盖边缘计算、数据中心、高性能计算和图形加速等领域,提供全方位的算力支持。 边缘计算:纳适™系列产品,如 KS20,典型功耗仅 25W,支持 60 路 1080P@30FPS 视频解码,适用于边缘侧的实时监测和分析。 数据中心:纳适™系列产品,如 KS38,提供强大的算力支持,适用于大数据分析和大模型复检等场景。 登临科技与光束慧联以GPU+架构为核心,AI算法为支撑,共同打造全链路国产化AI智能平台,已成功赋能千座矿山,用国产核心技术守护矿山安全、激活能源效能。未来,双方将持续以中国造芯片为底座,以中国造算法为引擎,合力推动国产化AI平台走向全球,为工业制造数字化转型提供坚实支撑。
登临科技
登临科技 DenglinAI . 2026-04-15 2401
- 1
- 34
- 35
- 36
- 37
- 38
- 500