加载中

2026 年端侧 AI 芯片格局:手机、PC、汽车与机器人谁先跑出来?
新品推荐 | 荣湃双通道隔离驱动产品Pai8236系列

市场周讯 | 长鑫IPO过会;环球晶、联电世界先进、ST、英飞凌再涨价;太空算力关注度持续升高
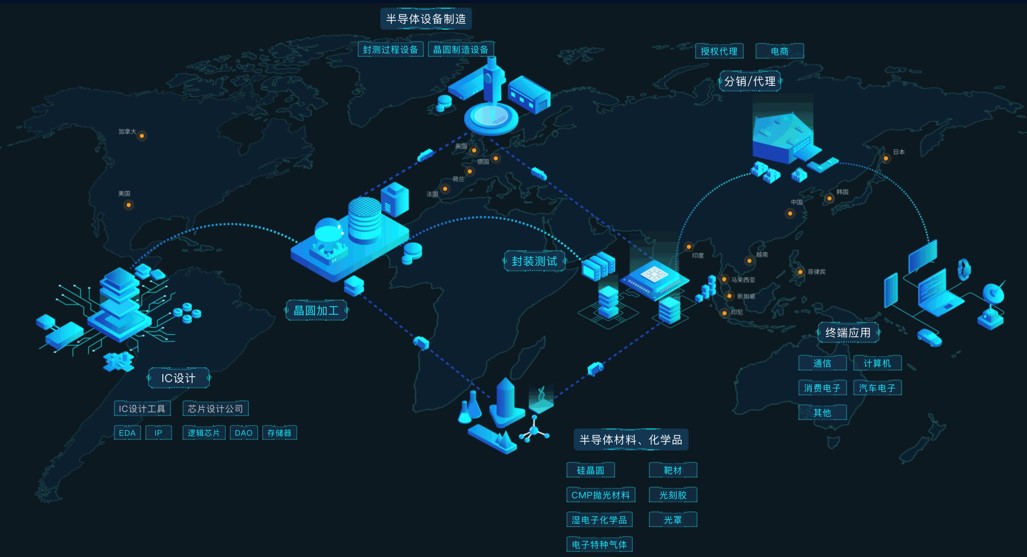
产业链 | 如何规避及减少芯片生命周期风险影响

2026高通具身智能与机器人大赛
热门推荐

我的文章

作为华大电子安全MCU三大产品线之一,超低功耗安全MCU CIU32L0产品线兼顾超低功耗与高安全特性。在智能表计、消防传感等电池供电场景中,传统方案难以兼顾高性能、低功耗与高性价比,开发者在设备续航、功能扩展和成本控制之间往往容易陷入两难。而CIU32L0产品线专为超低功耗电池供电设备而开发的产品。 超低功耗安全MCU CIU32L0产品线包括CIU32L071/61/51/30等系列产品。其中,CIU32L030系列主要面向低功耗、资源少需求场景,该系列不仅在功耗性能上进一步提升,同时提供最小3mmx3mm封装尺寸选择,搭配丰富的外设资源,全面适配 智能表计、消防安防、智能家居、新国标移动电源等消费和工业类应用场景。 CIU32L030产品框图 产品特性 1.最高频率可达48MHz,支持单周期乘法 2.内置64KB Flash,6KB SRAM,Flash全温下可支持擦写10万次 3.内部高精度48MHz时钟,全温范围误差小于±2%,无需外部高速晶振即可稳定工作 4.3通道DMA+2个高速24MHz SPI,更好的支持TFT融合显示效果,提升刷新速率性能 5.12位1Msps高精度ADC,2个低功耗比较器,温度传感器误差±2℃ 6.1.2μA@Stop+RTC模式,CPU+SRAM保持,动态功耗低至50μA/MHz@48MHz 7.支持LPUART,Stop唤醒波特率可达 9600bps@ LXTAL 32.768KHz 8.灵活的电源监测,PVD支持上电欠压复位与低电压监测,比较电压与滤波时间可配置 9.更高的可靠性,电源上下电鲁棒性高,避免欠压启动程序跑飞 10.最多28个GPIO更好的支持应用平台硬件设计扩展 CIU32L030系列上述产品优势已获得多个应用领域客户认可,如在电容笔和传感器等应用中,小封装+超低功耗有效解决体积受限且电池供电产品续航的痛点。在烟雾报警器、门磁传感器等设备中,高精度时钟和高可靠性设计保障设备长久稳定运行。在新国标移动电源中,凭借DMA+24MHz高速SPI接口优势,显著提升电量和电池状态显示效果。 CIU32L030系列向开发者提供完善的开发生态支持,可在华大电子官网下载相关产品技术文档、全例程SDK固件库及上位机软件等资源,同时可提供硬件开发板、离线编程器等硬件资源,助力开发者产品快速落地。
华大电子
华大电子 . 14小时前 357

这样的场景是不是已习以为常? 热油下锅,呲啦一声,辣椒和蒜末的香气瞬间炸开,伴随着一阵猝不及防的呛辣,直冲眼鼻,那股子“锅气”迅速弥散在整个厨房。 很多人觉得,这就是“家的味道”。但从科学角度出发,这些“温暖”的烟火气,它们的真面目究竟是什么? 揭开“烟火气”的面纱:三种不可忽视的厨房“隐形访客” 烹饪,尤其是中式爆炒、煎炸,食用油和食物在高温条件下会发生一系列复杂的化学反应,释放出大量混合污染物。中国疾控中心明确指出,当温度升至200℃以上,油脂开始剧烈氧化、裂解,形成大量有害物质。经研究表明,油烟中含有至少300种化学成分[1]: PM 做饭时厨房PM2.5和PM10浓度可达470.2μg/m³与663.0μg/m³[2]。目前国家环境空气质量标准中这两项的日均限值是60μg/m³和120μg/m³。这意味着,你家厨房做饭时的PM浓度,可能是室外重污染天气的数倍。颠勺的同时,你的气道早已默默承受了不应有的负担。 VOC “饭香”的背后,实则混着醛类、酮类、烃类以及多环芳烃等数百种物质,它们被统称为挥发性有机物(VOC),是那股“呛人”感的元凶。其中,苯并芘等部分物质被列为“可能对人类致癌”的物质。 NOx 燃气灶的火焰在燃烧时,会将空气中的氮气和氧气转化为一氧化氮和二氧化氮。当厨房通风不畅,这些有刺激性气味的气体就会悄悄累积,刺激我们的眼、鼻、喉黏膜,让嗓子发干、发紧,呼吸不畅。 不同厨房活动下的VOC指数与NOx指数波动 如果只是“偶尔呛一下”,可能很多人会觉得没什么。但这些看不见的污染,对身体的伤害是渐进性、可累积的。等你明显感觉到不适的时候,可能已经造成了不可逆的损伤[1]: 呼吸系统损害:油烟中的刺激性物质可直接损伤呼吸道黏膜,细颗粒物(PM2.5)可深入肺泡,长期暴露会导致慢性支气管炎、哮喘加重和肺癌风险。 心血管系统影响:油烟中的细颗粒物可穿透肺泡进入血液循环,引发全身性炎症反应和氧化应激,使血液粘稠度增加从而加速动脉粥样硬化进程。 致癌风险:油烟中的苯并芘和丙烯酰胺是明确致癌物。每天暴露于高浓度油烟环境1小时,相当于每日吸食10-20支香烟的致癌负荷。 其他健康影响:如皮肤老化和眼部刺激等,油烟中的自由基加速皮肤胶原蛋白降解,导致皱纹、色斑提前出现;而醛类物质则会引发结膜炎、干眼症。 让厨房空气被看见,让每一次呼吸都“心中有数” 过去,我们会依赖“鼻子闻”和“眼睛辣”来判断厨房空气的好坏;现在,一个灵敏的传感器已经能够比你更早地监测到骤升的空气污染物浓度。这份极致的安心感,正是Sensirion环境传感器想要带给你的。 传感 · 知源 | MOX电阻信号反应气体变化 我们专为空气质量监测设计的SGP4x系列气体传感器,基于金属氧化物(MOX),并在单个芯片上集成了CMOSens®传感器系统,能对空气中的VOC和NOx做出灵敏和精准的响应。无需凭感觉去“猜”,而是以可量化的数据,告诉你厨房间每一次呼吸的真实情况。 更进一步,SEN6x系列多合一环境传感器模组将这一守护做到了更为简约与强大。它将PM1, PM2.5, PM4, PM10, T, RH, VOC指数, NOx指数, CO₂九类关键参数的测量,精巧地集于一体。对于追求生活品质的用户而言,这意味着无需繁琐的选型和调试,一个模组就能轻松赋予你的智能油烟机、新风空调、空气净化器等终端设备全方位感知厨房空气质量的能力。 “人间烟火气,最抚凡人心。”那些每天在灶台前忙碌、把爱和营养装进每一道菜里的人,更值得被温柔地守护。依托Sensirion针对厨房场景的空气质量解决方案,用精密的感知技术 ,重新定义厨房的空气微环境,让每一次的共餐,都只有爱与美味弥漫。
盛思锐
盛思锐传感器 . 14小时前 315
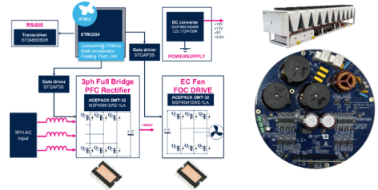
随着人工智能技术的飞速迭代,AI服务器朝着超高算力、高密度集成的方向快速发展,单台服务器的功耗持续攀升,随之而来的散热难题令传统散热方案已难以满足AI服务器高功率密度的散热需求,高效、节能、可靠的散热技术成为行业研发的重点。意法半导体(ST)推出的SiC(碳化硅)驱动7kW EC(电子换向)风扇解决方案,依托宽禁带半导体技术的优势,实现了散热效率与能源利用效率的双重突破,为AI服务器及各类高功率设备的散热提供了全新的技术路径。本文将全面解析SiC驱动7kW EC风扇的技术架构、核心器件特性、实验性能表现,并探讨其在AI服务器、数据中心等领域的应用价值与行业发展前景。 行业背景:高功率散热需求催生技术革新 在数字化转型与人工智能普及的双重驱动下,数据中心、HVAC(采暖、通风与空调)、BESS(电池储能系统)等领域迎来爆发式增长,高功率设备的广泛应用使得散热系统的重要性日益凸显。尤其是AI服务器,随着GPU等算力芯片的功耗突破千瓦级,单台AI服务器的散热需求已达到传统服务器的数倍,传统散热方案的局限性愈发明显,推动散热技术向高效化、节能化、集成化方向升级。 高功率散热市场规模与发展趋势 根据市场研究数据显示,高功率散热相关市场呈现高速增长态势,其中三大核心领域的市场规模与增长潜力尤为突出: 数据中心散热领域,2022年全球市场规模已达31.4亿美元,预计到2032年将增长至311亿美元,2022-2032年期间的复合增长率高达25.8%。其中,液冷技术作为高效散热的重要方向,2032年市场规模将达到171亿美元,成为数据中心散热市场的核心增长极。这一增长主要得益于AI服务器、通信基站等业务的快速扩张,数据中心的功率密度持续提升,传统风冷已难以满足散热需求,液冷与高效风冷技术的融合应用成为必然趋势。 随着全球对节能减排的重视,家用空调、热泵、屋顶机组等设备对散热效率与节能性能的要求不断提高,高效EC风扇凭借低功耗、高可靠性的优势,逐步替代传统交流风扇。HVAC领域,2023年全球市场规模为2940亿美元,预计到2032年将达到4810亿美元,复合增长率为5.6%。 BESS领域,2023年全球市场规模为54亿美元,预计到2030年将增长至269亿美元,复合增长率达25.8%。电网级电池储能系统的热管理需求日益迫切,直接液冷技术与高效风冷技术的结合,能够有效控制电池温度,提升储能系统的安全性与使用寿命。 上述三大领域的市场增长,直接推动了高功率散热技术的创新,尤其是SiC等宽禁带半导体技术的应用,为散热系统的性能升级提供了核心支撑。 AI服务器散热的核心痛点 AI服务器的核心需求是实现超高算力的稳定输出,而算力的提升必然伴随着功耗的激增。以7MW数据中心为例,其IT负载达到7MW,对应的散热容量需求高达12MW,散热系统的电力消耗达到3.7MW,占总功耗的34.5%,散热成本与能源消耗成为数据中心运营的重要负担。 传统散热方案的核心痛点主要体现在三个方面:一是能效比低,传统交流风扇的转换效率较低,大量电能被浪费在机械损耗与热损耗上;二是可靠性不足,高功率运行下,风扇的振动、磨损问题突出,使用寿命较短,增加了设备维护成本;三是控制精度低,难以根据服务器的实时功耗动态调整散热能力,导致散热不足或过度散热,影响服务器性能与能源利用效率。 在此背景下,SiC驱动的EC风扇凭借高效节能、高可靠性、精准控制的优势,成为解决AI服务器散热痛点的理想方案。 技术架构:SiC驱动7kW PMSM逆变器+三相全桥PFC”的核心架构 意法半导体推出的SiC驱动7kW EC风扇解决方案,采用7kW PMSM逆变器+三相全桥PFC的核心架构,以STM32G4微控制器为控制核心,借助这款高性能微控制器(MCU),可同时实现功率因数校正(PFC)环节与电机控制的管理。在功率级方面,我们采用两块SiC ACEPACK DMT-32功率模块,得益于这款碳化硅(SiC)模块,它实现了低导通损耗与高开关性能,我们得以打造出高效且可靠的电机控制方案。 另一个关键点是,这款PCB布局极为紧凑,直径仅24厘米。这非常适用于AI散热风扇等空间受限的应用场景。 你可能会好奇,为什么需要功率因数校正(PFC)?PFC在现代电力电子系统中起着至关重要的作用。它有助于提升效率,并满足电网规范要求。 如果不增加功率因数校正(PFC)环节,正如图中所示,电流波形会发生畸变,与电压不同步。这会显著增加变压器的功率损耗,同时加剧其他设备的损耗与老化。 我们的方案集成了三相全桥PFC,能够主动对电流波形进行整形,使其紧密跟随电压波形。这就是核心优势所在。如果每台风扇都配备独立的PFC级,就无需额外安装昂贵的外置有源电力滤波器(APF),同时还可以使用体积更小、成本更低的变压器,从而显著节约成本。 接下来我们看一下这款SiC ACEPACK DMT-32模块的PFC性能。 如下图左侧所示,当功率超过2kW时,这款SiC模块可实现97.5%以上的超高效率。右侧曲线则表明,在各种功率区间内,电流总谐波失真(THDi)表现都十分优异。 即使在轻载工况下,THDi也能保持在极低水平,不超过7%。 现在我们来看如下图左侧的电机控制级。效率曲线显示,系统在4A电流时达到峰值效率;右侧曲线则表明,功率损耗会随电机电流的增大而上升。当电机电流达到16A时,功率损耗仅约105W。相较于高散热工况下的整机功耗,这一损耗非常小。 除此之外,在前面提到的优势基础上,我们还引入了AI技术来分析振动问题,从而延长风扇使用寿命。机械振动主要来源于三大因素:转子不平衡、共振现象以及轴承老化。这些因素会产生不同类型的振动特征。通过AI,我们可以对这些振动模式进行精准分类。 当检测到转子不平衡或轴承问题时,AI会输出维护预警信号,避免风扇系统出现意外停机或故障。针对共振现象,一旦AI检测到共振,可自动调节转速指令,使设备避开共振频率运行,从而改善振动问题。AI还会综合监测电机转矩、转速信息以及振动传感器的反馈数据,让整个系统更加智能、可靠。 现在我们来看一下该方案中采用的核心器件。 首先是SiC ACEPACK功率模块DMT32,它具备出色的耐压能力和极低的导通电阻Rds(on)。此外,模块还集成了NTC热敏电阻,可实时监测温度,保障运行安全。 与该模块配套使用的是STGAP3S栅极驱动器,它是一款增强型电气隔离单通道栅极驱动器,具备9.6kV隔离耐压与优异的抗瞬态干扰能力。得益于仅75ns的极低传输延迟,可实现更高的开关频率。同时内置退饱和保护、过热关断等多重保护功能,进一步提升风扇系统可靠性。 当然,我们还采用了经典的STM32G4微控制器。它拥有170MHz的高性能主频,集成了丰富的模拟前端外设以及高精度定时器,能够实现紧凑高效的风扇控制方案。 除了这款7kW EC风扇方案,我们还提供一系列成熟的散热解决方案,覆盖不同功率等级、多种PFC拓扑结构,并支持多路电机控制。在PFC拓扑方面,我们提供单相单通道、交错并联拓扑;三相PFC则支持维也纳拓扑与全桥拓扑。在受控电机数量上,最多可同时支持3台电机。 在此我还要重点介绍我们的10kW方案,它专为压缩机等高功率散热场景设计。 结合以上全套电机控制方案,我们为AI散热领域构建了一套完整的电机控制生态系统。 行业应用前景 随着AI服务器、数据中心、HVAC、BESS等领域的持续发展,高功率散热需求将不断增加,SiC驱动7kW EC风扇作为高效、节能、可靠的散热解决方案,具有广阔的行业应用前景。
ST
意法半导体工业电子 . 14小时前 392

TJA1421单通道LIN收发器和TJA1425高集成度四通道LIN主控收发器,进一步丰富了恩智浦的LIN产品系列。这两款收发器具备更强的电磁兼容性 (EMC) / 静电放电 (ESD) 耐受能力,兼容1.8V MCU,并支持超低功耗运行,适用于速率高达20kBd的汽车子网络。 TJA1421是TJA1021的升级产品,能够支持更多的LIN节点,提升可靠性,同时无缝适配现代低电压MCU。 TJA1425集成四个LIN主通道并内置终端电阻,大幅节省物料清单 (BOM) 成本和PCB占用面积,适合打造更具成本效益和空间效率的多通道LIN设计。同时,TJA1425在TJA1124的基础上实现升级,进一步提升了性能和灵活性。 该系列收发器面向车身电子、网关以及汽车ECU设计,能够提供可靠、可扩展的LIN连接能力。 为何选择TJA1421和TJA1425? 完全符合LIN 2.x、SAE J2602及ISO 17987 4 (12V) 标准 增强的EMC/ESD耐受能力,满足严苛的汽车环境要求 兼容1.8V、3.3V和5V MCU 可从单通道扩展至多通道LIN架构 针对低功耗和现代 ECU 设计进行了专门优化 TJA1421和TJA1425主要特性 主要用于使用高达20kBd波特率的车载子网络 符合LIN 2.x、美国汽车工程师协会 (SAE) J2602以及国际标准化组织 (ISO) 17987-4:2016 (12V) 标准 LIN和VBAT引脚具备高ESD耐受能力 总线、WAKE_N和电池引脚均受保护,可抵御汽车环境的瞬态干扰 总线端子具备对电池和对地短路保护 热保护 TXD显性超时功能 LIN显性超时功能 (TJA1425) MCU超时功能 TJA1421和TJA1021引脚兼容,提供SO8和HVSON8封装: SO8封装:塑料小封装,8引脚,1.27mm间距,本体尺寸为4.9mm × 3.9mm × 1.75mm HVSON8封装:塑料散热增强型超薄小型无引脚封装,8端子,0.65mm间距,本体尺寸为3mm × 3mm × 0.85mm TJA1425和TJA1124引脚兼容,仅提供 DHVQFN24封装: DHVQFN24封装:塑料双列直插兼容型、增强散热超薄四方扁平封装,24端子,0.5mm 间距,本体尺寸为3.5mm × 5.5mm × 0.85mm TJA1421和TJA1425的优势 优化的LIN IP EMC/ESD性能 完全符合最新全球标准 (IEC 62228-2:2016和SAE J2962-1:2024) LIN引脚具备8kV ESD防护能力 (符合IEC 61000-4-2标准) TJA1421的特点: 内置范围更严格的从节点终端电阻 ([27.66,48kΩ],一般为[20,60kΩ]),从而支持在同一网络容纳更多LIN从节点 (从15个增至22个),进而减少区域MCU的LIN端口数量,例如用于车内照明、风扇等应用 在LIN从节点数量相同的情况下,可支持更复杂网络和更长线缆 TJA1425的特点: 同时提供SLP和SLP_N引脚,适应客户的不同需求 SLP_N:推荐使用,由于内置上拉电阻,可避免电流泄漏至MCU SLP:用于与TJA1124引脚兼容的场景 将主机兼容性扩展至1.8V MCU,覆盖各类应用 高端区域控制ECU和中央计算ECU,用于娱乐中控和座舱应用 MCU超时故障安全功能:可最大限度降低功耗 TJA1421框图 TJA1425框图
NXP
NXP客栈 . 14小时前 364
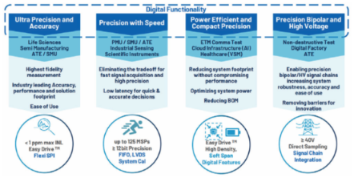
从半导体测试到生命科学,如何破解精密仪器设计中的“性能平衡难题”? 在精密测量仪器的设计逻辑中,“精度”、“速度”与“尺寸”往往被视为难以兼得的“不可能三角”。当应用场景从静态的直流校准演进到动态的流式细胞分析,或从低检测跃升至±40V的高压逆变器环境时,工程师面临的挑战已不再是如何选择一颗高性能的数据转换器 (ADC/DAC),而是如何在受限的板级空间、功耗预算以及严苛的噪声环境下,构建一套具备高度鲁棒性的精密信号链。 而 ADI 的精密转换器组合(如图1所示),清晰地展示了其在这一领域的四维布局:超高精度(Ultra-Precision)、精密高速(Fast Precision)、紧凑精密(Compact Precision)以及精密高压 (High Voltage Precision)。作为精密模拟技术的长期主义者,ADI不仅是在推陈出新硬件型号,更是在试图通过底层架构的创新——如EasyDrive技术、SoftSpan功能以及高集成度的系统模块(ADMX系列)——重新定义精密信号链的设计范式。 图1:精密转换器在关键应用中的创新 PART.01 保障直流精度的“定海神针”:1ppm下的可重复性 在超高精度领域,直流精度(DC Accuracy)是衡量信号链性能的核心标尺。对于半导体测试设备中的源表(SMU)或电池测试系统而言(如图2所示),1ppm(百万分之一)级别的积分非线性 (INL) 是区分顶级仪器与常规设备的“分水岭”。 图2:源测量单元(SMU)系统架构 ADI在这一维度的标杆产品是AD5791数模转换器与AD4630-24模数转换器。AD5791作为一款20位DAC,其提供的1ppm INL和小于0.5 ppm/°C 的温度漂移,确保了信号源在极宽的时间跨度和环境波动下依然能保持高度的稳定性。在实际应用中,这种稳定性直接转化为测试设备的可重复性和可再现性,这对于晶圆测试等需要长时间连续作业的场景至关重要。 与此同时,AD4630-24是当前性能表现十分优异的SAR ADC产品。在 2 MSPS的采样速率下,它实现了±0.9ppm的INL最大值和105.7 dB的信噪比(SNR)。这种“既要又要”的性能表现,打破了传统高分辨率ADC在速度与噪声之间的权衡。 PART.02 打破速度与精度的边界:低延迟的动态响应 当应用场景切换到流式细胞仪(Flow Cytometry)或扫描电子显微镜 (SEM)时,信号链的需求重心从单纯的直流精度转向了动态性能与低延迟。在这些控制闭环系统中,每一纳秒的延迟都可能导致反馈补偿的失效或图像采集的模糊(如图3所示)。 图3:Flow Cytometry(流式细胞术)的工作原理和对应的模拟信号链 ADI的快速精密系列(Fast Precision)正是为此而生。以AD4080为例,这款20位ADC提供了40 MSPS的采样速率,同时保持了小于10 nV/√Hz 的噪声谱密度。这种高的采集能力,能够捕捉极细微的瞬态信号。而在输出端,AD3552R则以33 MSPS的速率和100ns的建立时间,确保了电子束定位等精密驱动应用的高速动态响应。 这种代际跃迁的背后,是对“低延迟”这一核心指标的极致追求。在高速闭环控制中,AD4080通过创新的架构实现了首次 测量的准确性,避免了传统高阶Delta-Sigma ADC常见的群延迟问题。这种特性对于硬件在环(HIL)仿真和宽带信号生成具有决定性意义。 PART.03 EasyDrive架构:从“元器件思维”到“系统思维”的转变 在传统的精密ADC设计中,驱动级的设计往往是工程师的噩梦。深入到物理底层,精密SAR ADC采样过程中的核心痛点在于采样保持电容(CSH)切换时引起的电荷注入,即“反冲毛刺(Kickback)”。为了应对这种瞬态冲击,传统方案不得不依赖于高带宽、高压摆率的驱动放大器强行“压制”毛刺,这不仅推高了系统功耗,更引入了额外的噪声。 ADI推出的EasyDrive技术,本质上是从底层架构上消除了这一痛点 (如图4所示),信号链的“去冗余化”在EasyDrive架构中得到了物理层面的验证。通过引入内部预充电(Pre-Charge)电路,ADC 在采样周期开始前,通过时序同步将内部CSH充电至接近前一采样值的水平,从而将进入输入端的电荷总量降低了几个数量级。与此同时,诸如AD469x等器件提供的高阻抗(High-Z)模式,实质上是通过内部缓冲将驱动级与采样电容物理隔离,使得模拟前端即便面对高阻抗信号源(如无缓冲的电阻分压器或精密滤波器),也能在不加缓冲器的情况下保持极高的采集精度。 图4:EasyDrive™技术通过集成化设计,显著优化传统信号链架构 在紧凑精密(Compact Precision)产品线中,这种技术的价值被成倍放大。例如,AD4696系列16通道ADC通过集成EasyDrive,能够让整体解决方案尺寸减少75%,功耗降低60%。对于便携式生命体征监测(VSM)或无线环境监测系统而言,这种集成度提升不仅是数字上的减少,更意味着更长的电池寿命和更小的物理轮廓。 PART.04 高压信号链的集成进化:化繁为简的工程美学 传统的精密高压监测方案(如逆变器测试或负载端电流监测) 通常是一场“补丁设计”。工程师必须在VCC>20V的高共模环境下,通过由仪表放大器、精密分压电阻和外部缓冲器组成的离散信号链,来提取检测电阻上微弱的电压降。这种方案的物理局限在于:离散电阻网络随温度漂移的不一致性会直接破坏系统的共模抑制比(CMRR),且复杂的布局增加了寄生参数影响信号完整性的风险。 譬如工业逆变器测试或LED老化测试中,系统往往需要处理±15V、 ±20V乃至±40V的高压双极性信号。传统的做法是利用仪表放大器进行衰减,辅以分压电阻网络,最后送入低压ADC。这种离散方案不仅导致电路板布局极其复杂,更由于匹配电阻的漂移引入了不可控的系统误差。 ADI在高压精密(High Voltage Precision)领域的突破,集中体现在 AD4858这类高度集成的信号采集系统上(如图5所示),传统离散信号链方案的复杂性困局得以终结。通过在单芯片上集成高密度的数据采集路径,AD4858提供了高达120 dB的共模抑制比,能够直接耐受高达±40V的信号波动。 图5:AD4858高/低侧电压与电流检测简化方案 其核心优势在于每通道可独立配置的SoftSpan范围,配合片内的数字增益、偏置及相位调整功能,在数字域内即可消除前端模拟元件引入的温漂误差。这种“端到端”的集成不仅将外部组件数量降至最低,更通过消除中间环节,确保了信号链在宽动态范围下的线性一致性。 PART.05 行业洞察:精密模拟的“数字化”与“模块化”趋势 纵观ADI最新的精密转换器布局,我们可以清晰地观察到两个深刻的行业趋势: 首先是精密模拟功能的数字化增强。无论是ADMX系列模块中内置的专利数字预失真(DPD)算法,还是ADC片内的平均滤波和自主监控功能,都表明数据转换器不再仅仅扮演“翻译”的角色,而是开始承担起部分信号处理的任务。这种趋势减少了对后端处理器(FPGA/MCU)计算资源的依赖,同时也降低了系统级固件开发的复杂度。 其次是从单一器件向信号链模块(Module)的跃迁。ADMX1002等模块的推出,标志着ADI正在将复杂的电路设计(如超低失调、低毛刺的正弦波发生电路)进行“黑盒化”。对于仪器厂商而言,这意味着可以将研发精力从底层的模拟调优中解脱出来,转而投入到更具差异化的应用算法和用户体验上。 在半导体行业追求极致效能的今天,ADI对精密信号链的整合与优化,实际上是在解决一个普适的工程矛盾:如何用更简单的设计实现更严苛的指标。 图6:精密DAC产品选型决策树 通过超高精度、快速、紧凑、高压四个维度的精准切入,配合 EasyDrive、SoftSpan等底层架构创新,ADI不仅巩固了其在精密转换器领域的护城河,更通过减少系统级BOM、降低功耗和面积,赋予了下游工程师更高的设计自由度。 在未来,随着AI医疗、自动测试设备以及工业物联网的持续深 化,现代精密仪器的设计正在步入一个全新的阶段:芯片本身即是子系统。从选型决策树(如图6所示)中可以看到,无论是从基础的AD4052起步,还是向追求24位极致分辨率的AD4630-24跨越,其背后都遵循着一套“按需匹配”的模块化逻辑。广大工程师可以根据电压范围、通道数、性能冗余及采样速度,在决策树中找到最优解,而这俨然已成为这一代精密设计的新起点。未来的仪器设计将不再是繁琐的底层元件调优,而是基于高集成度、数字化增强型硬件的系统级定义。工程师可以利用这种更成熟的选型起点,在更短的周期内实现从实验室原型到工业级产品的工程落地。
ADI
ADI智库 . 14小时前 378

Melexis推出MLX92344,这是一款极具灵活性的无PCB解决方案,可实现多达四个位置的非接触式检测,无需使用体积庞大的微动开关。该器件在确保通过两线实现向下兼容的同时,引入了完全可编程的电流输出和磁阈值。这一创新将推动下一代汽车车身电子技术的发展,应用涵盖座椅轨道定位、车门关闭的流畅性以及多位置前备箱锁的小型化等领域。 汽车车身电子产品对位置传感可靠性要求日益增高,尤其是在座椅滑轨位置监测、电子前备箱锁、人机界面(HMI)控制按钮、充电端口等安全关键功能中。传统的机械微动开关方案通常需要多个开关来检测中间位置,这增加了系统复杂性、布线要求以及潜在的可靠性隐患。与此同时,不断演进的安全标准和日益提高的车辆自动化程度,正推动设计人员转向更集成、更稳健的传感解决方案,同时还要保持与现有ECU的兼容。 ▲ MLX92344产品图 MLX92344的核心优势 MLX92344凭借业内首创的双可编程架构化解了这一难题。工程师可根据需求,将输出电流直接分配给器件的磁工作点(BOP1, BOP2)和释放点(BRP1, BRP2)阈值,并针对钕磁铁或铁氧体磁铁提供温度补偿。设计人员可在3mA至28mA范围内配置多达四个不同的电流(通常为5mA、10mA、15mA和20mA),使器件能够模拟标准微动开关接口,同时保持与现有硬件和ECU的兼容性。该器件可通过标准的I/O触发器或ADC进行读取,设计人员只需调整软件读数即可完成适配。 MLX92344的工作电压范围为2.7V至28V(支持32V卡车应用的最大额定值),工作温度范围为-40℃至+150℃,满足汽车级温度要求。该器件符合ASIL B SEooC标准,并通过AEC-Q100认证,提供TSOT23-3L表面贴装和TO92-3L(UA)两种封装。它还具备出色的静电释放(ESD)鲁棒性,支持8kV人体模型(HBM)和15kV系统级ESD,确保在严苛的汽车环境中能可靠运行。 ▲ 无PCB设计图 器件参数(包括开关阈值、电流输出、诊断行为及输出状态数量)均通过片上非易失性存储器进行配置,使MLX92344能够针对不同的磁铁几何形状、机械公差和系统架构进行优化。终端产线编程(EoL)允许工程师消除组装中的机械公差,从而实现极高的检测精度。MLX92344的部分料号还提供IMC技术,能够检测侧向磁场分量,在磁铁布置和机械设计方面提供更大的灵活性。 •• 应对新的安全要求 •• 座椅滑轨位置传感是一个关键应用,准确的座椅位置检测对于乘员安全系统至关重要。更新的安全标准要求车辆检测三个座椅位置而非两个,以确保安全气囊根据驾驶员与方向盘的距离进行适当部署MLX92344而无需增加额外的机械微动开关,仅凭单个器件和两线接口即可检测三个位置,从而降低座椅系统的布线复杂性——在此类系统中,线束的长度和尺寸往往十分可观。 随着汽车行业向更高级别的自动驾驶迈进(乘员可能采用不同的座椅配置),座椅位置监测将变得更加重要。在检测转向柱相对于驾驶员和座椅的伸缩位置时,也存在同样的需求。 除座椅系统外,MLX92344还可通过用单个非接触式器件替换多个机械微动开关,简化车门、引擎盖和后备箱的电子锁(e-latch)机构的设计。在软关闭机构中,检测四个机械状态尤为重要——车门或后备箱在达到中间半锁位置后会被自动拉闭。此外,该器件还可以检测完全打开、半锁、全锁和过推状态,完整映射整个运动过程。 该器件还支持电动汽车充电端口监控,检测充电端口盖或连接器机构的位置,不仅为高压充电带来安全性保障,还可增加推开式开启等舒适功能。其他应用包括自动变速杆、驻车锁、断开装置和安全带扣。 Melexis 产品线总监 Minko Daskalov 表示: 凭借这种可编程架构,我们为汽车工程师提供了一种更智能的方案来替代多个机械微动开关,同时满足日益严格的安全要求。通过将可配置的电流输出与磁开关阈值相结合,MLX92344助力工程师能够设计出更小巧、更安全、更灵活的车身电子系统。
迈来芯
迈来芯Melexis . 14小时前 343

Wi-Fi 7(IEEE 802.11be)于2024年正式推出,带来了320 MHz超宽信道、4096-QAM高阶调制、8×8 MIMO等炫目规格——这些特性对路由器、网关和高吞吐客户端意义重大。 但对智能门锁、温控器、安防摄像头、工业传感器这类物联网设备而言呢? 它们要的不是“跑得最快”,而是: 连得上——在拥塞的频谱环境中保持稳定 用得久——严格的功耗预算,电池能撑更长 响应快——控制指令、状态数据,低时延可靠送达 好消息是:Wi-Fi 7的MAC层智能机制,正是为这些场景而生。 2026年1月,Wi-Fi Alliance正式推出了面向20 MHz信道设备的Wi-Fi 7认证,让成本与功耗经过优化的物联网设备,无需宽带设计的复杂度,即可享受Wi-Fi 7的核心红利。 三大关键技术,重新定义物联网连接体验 1.多链路操作(MLO)—拥塞?直接绕开 传统Wi-Fi设备一次只能关联一个频段,遇到干扰只能“硬扛”或断线重连。Wi-Fi 7的MLO让设备同时逻辑关联2.4 GHz、5 GHz和6 GHz三个频段,实时感知网络状况,自适应切换、动态避开拥塞路径,连接稳定性大幅提升。 2.多资源单元(MRU)—小包数据,也能高效传 物联网设备的数据包往往很小(传感器数据、状态上报),Wi-Fi 6的单RU限制让频谱利用率捉襟见肘。Wi-Fi 7的MRU允许分配多个非连续资源单元,减少信道占用浪费、降低时延、提升拥塞场景下的可靠性。 3.受限目标唤醒时间(R-TWT)——省电,省到极致 设备不再各自“随机醒来”争抢信道,而是由接入点统一调度,将具有相似时延和流量需求的设备组织到协调的唤醒窗口中。空闲监听减少、不必要唤醒减少,电池寿命显著延长——这对门锁、可穿戴、烟感等电池设备意义重大。 技术落地:英飞凌AIROC™ ACW741x,业界首款面向物联网的20 MHz Wi-Fi 7芯片 理解了Wi-Fi 7对物联网的价值,再来看英飞凌给出的硬件答案——AIROC™ ACW741x,这款芯片有几个关键标签值得记住: 业界首款面向物联网的20 MHz Wi-Fi 7器件 业界最低Wi-Fi连接待机功耗:仅70 µW(DTIM10) 三合一集成:Wi-Fi 7 + Bluetooth® LE + IEEE 802.15.4,单芯片搞定 核心亮点一览: Wi-Fi规格 1x1,20 MHz,支持双频(2.4/5 GHz)或三频(2.4/5/6 GHz) PHY数据速率 最高可达86 Mbps(MCS7) MLO支持 多链路单射频(MLSR),支持多链路操作(MLO),自适应频段切换 省电机制 受限目标唤醒时间(r-TWT),Wi-Fi连接待机仅70 µW(DTIM10) 发射功率 最高+23 dBm 接收灵敏度 低至-100 dBm Wi-Fi感知 802.11bf,基于信道状态信息(CSI)的Wi-Fi感知,支持运动检测与存在感知 安全性 WPA2/WPA3个人/企业版 Bluetooth® Bluetooth Core 6.0,支持信道探测,实现高精度距离测量;LE LR灵敏度:-109 dBm 802.15.4 支持Thread / Matter生态系统,含Thread边界路由器应用;发射功率+18 dBm 主机接口 Wi-Fi:SDIO 3.0 / gSPI;Bluetooth®:共享SDIO/gSPI或UART;802.15.4:共享SDIO/gSPI或SPI 封装 QFN60,7×7 mm,0.4 mm引脚间距,支持低成本双层PCB 超低功耗+超远覆盖+三频自适应,让ACW741x成为安防摄像头、智能门锁、可视门铃、温控器、HVAC控制、医疗保健设备等应用的理想之选。 更值得一提的是,ACW741x还支持IEEE 802.11bf Wi-Fi感知(基于信道状态信息CSI),可实现运动检测与存在感知,支持同一网络内设备之间的协同智能,为智能家居带来真正的“情境感知”体验。 想看更深度的技术解析? 英飞凌最新发布的白皮书《面向物联网的Wi-Fi 7:可靠且超低功耗的20 MHz Wi-Fi性能表现》,从物联网挑战出发,系统梳理了: Wi-Fi 7核心技术机制(MLO / MRU / R-TWT)的原理与物联网价值 20 MHz信道认证路径的技术逻辑 物联网Wi-Fi 7生态的发展趋势与市场预判
英飞凌
英飞凌官微 . 昨天 644

新闻亮点 ● 英特尔推出英特尔至强6+能效核处理器,为各类数据中心工作负载提供业界领先的机架密度。 ● 英特尔扩展以太网800系列产品组合,推出英特尔以太网E835控制器及网络适配器,扩展至200GbE吞吐量,缓解现代AI、云和边缘基础设施的网络瓶颈。 ● 英特尔扩展面向中小企业的至强产品组合,推出全新12核英特尔至强6300系列处理器,为入门级服务器带来更高性能。 ● 英特尔披露下一代数据中心GPU(代号“Crescent Island”)的更多技术细节,该产品专为智能体系统打造,解决客户面临的功耗与内存瓶颈。 今日,英特尔宣布数据中心领域最新进展,推出全新英特尔至强6+处理器,发布以太网800系列新成员——英特尔以太网E835控制器及网络适配器,以及AI加速器路线图的最新进展,包括Crescent Island的更多信息。这些进展共同凸显了一个清晰的行业趋势:当AI迈向智能体时代,CPU正重返现代AI基础设施的中心。英特尔以至强作为控制平面,采取系统级方法,实现大规模部署的高性能与高能效,交付为日益普及的智能体AI工作负载而设计的平台。而在这些工作负载中,无论是在数据中心还是在网络环境,编排、数据流动以及持续推理都至关重要。 Kevork Kechichian 英特尔公司执行副总裁 兼数据中心事业部总经理 AI的扩展之道,不在于各部件的叠加,而在于系统的协同运作。随着AI走向智能体时代,编排、并发与数据流动成为了新的限制因素。这再次强化了一个核心事实:CPU依然是现代AI基础设施的控制平面。通过至强6+和以太网E835,我们正紧密耦合计算与网络,以减少现实世界中的智能体工作流瓶颈,并助力其实现高效、安全的扩展。 英特尔至强6+处理器重磅登场 英特尔至强6+处理器扩展了至强6家族,专为云原生、智能体AI以及网络密集型工作负载提供卓越的性能密度、能效与运营扩展。作为采用Intel 18A制程打造的首款数据中心CPU,至强6+在现实世界的功耗限制下,依然能提供强劲且持续的性能,这精准解决了新兴智能体AI对编排、并发与数据流动的严苛需求。 针对对单机架功耗、单核吞吐量以及延迟可预测性要求极高的业务环境,至强6+进行了优化。它聚焦于横向扩展性能,让企业无需对数据中心进行颠覆性重构,即可承载全新的AI工作负载。 产品亮点包括 ● 多达288颗能效核(E-core):与上一代产品相比,性能提升高达2.5倍1;与同类产品相比,每线程每瓦性能提升高达45%2,可为云原生、电信和智能体AI驱动的工作负载提供高并发和快速响应能力。 ● 12通道DDR5内存:具有可扩展带宽,适用于高密度系统。 ● 96通道PCIe Gen 5和CXL支持:加速跨异构基础设施的数据流动。 ● 英特尔应用能源遥测技术(AET):实现实时、工作负载级的CPU能源和活动遥测。从英特尔至强6+处理器开始,该技术可提高工作负载级能耗的可见性。 ● 高达9:1的服务器整合率3:与第二代英特尔至强处理器相比,可大幅减少占地面积,降低TCO。 ● 内置于芯片的可靠性机制:包括英特尔SGX和英特尔TDX,以支持机密和多租户部署。 英特尔至强6+处理器已在电信网络基础设施中进行测试,并开始配置到数据中心系统中,整个生态系统均有可用平台。其中包括来自华硕、戴尔科技、爱立信、技嘉、慧与(HPE)、联想、超微等厂商所提供,或在其方案中采用的服务器、网络和集成解决方案。 这一不断壮大的产品组合,诠释了英特尔“系统优先”的理念,即易于部署、交付即刻可用的基础设施,从而在x86架构上运行、扩展和编排爆发式增长的智能体AI工作负载。通过将针对高密度吞吐量和单线程性能优化的至强平台进行互补,英特尔的客户和合作伙伴可以在成熟、广泛的硬件和软件生态系统中调度工作负载,从而在出色效率和敏捷响应之间获得平衡。 英特尔公司执行副总裁兼数据中心事业部总经理Kevork Kechichian展示英特尔至强6+处理器(图片来源:英特尔公司) 英特尔至强6+处理器晶圆(图片来源:英特尔公司) 英特尔至强6+处理器晶圆(图片来源:英特尔公司) 英特尔以太网E835:适用于下一代基础设施的高效网络 AI、云和分布式工作负载持续扩展,网络成为决定整体基础设施性能和效率的关键因素。英特尔以太网E835控制器和网络适配器将为现代数据中心、企业、边缘和AI环境提供高性能、高能效的连接。 英特尔以太网E835在保持行业领先的每瓦性能的同时,还提供了下一代基础设施所需的扩展性和效率。E835专为高密度、虚拟化部署而设计,能够在不牺牲吞吐量或可靠性的前提下,降低能耗和运营成本。 产品亮点包括 ● 灵活的连接性:通过多种控制器和网络适配器配置,提供200 GbE的吞吐量,支持10GbE到200GbE的数据速率。E835支持广泛的端口配置,包括2x25GbE、4x25GbE、2x100GbE和1x200GbE,并可通过英特尔以太网端口配置工具(EPCT)启用更多配置。 ● 行业领先的能效:专为更高每瓦性能而设计。英特尔E835-CQDA2网络适配器的每瓦性能比同类产品高出多达1.4-1.9倍,从而降低了现代分布式环境的能耗和运营成本。* ● 网络优化:采用RDMA (RoCEv2/iWARP),降低CPU占用率并最大化效率,支持动态设备个性化(DDP)以简化数据包处理流程,并提升应用性能。 ● 可靠性与可管理性:集成硬件信任根(Root of Trust)和带签名的SPDM,支持基于DMTF的可管理性,实现可靠、稳定的运营。 ● 广泛的兼容性:支持包括Linux、ESXi和Windows在内的多种操作系统。 ● 10年以上生命周期:为长期可靠性而设计,提供持久的技术支持。 凭借思科、戴尔、慧与(HPE)、联想和超微等行业领军企业的广泛支持,英特尔以太网E835构建了高效、易管理的网络架构。无论是AI训练,还是企业云服务,E835都能提供下一代网络所需的卓越扩展性、出色可靠性与高能效表现。 英特尔以太网E835控制器及网络适配器(插拔式)(图片来源:英特尔公司) 提升中小企业入门级服务器性能 英特尔同时宣布,面向入门级服务器的英特尔至强6300处理器系列全新12核版本正式上市。该版本首次将该平台的内核上限提升至8核以上。新增的内核数量可在不改变既有平台的前提下,为中小企业日益增长的工作负载提供更强大的算力支撑与灵活性。 即日起,搭载12核的至强6300处理器将通过各大主流OEM厂商正式发售。该处理器与现有的入门级服务器设计无缝兼容,可助力客户实现快速且具成本效益的系统升级。 Crescent Island:构筑AI推理新势能 为了满足对智能体AI日益增长的需求,除了计算性能之外,内存容量、带宽与能效成为了衡量芯片竞争力的差异化指标。英特尔新一代数据中心 GPU,代号Crescent Island,正是为此量身定制。它基于Xe 3P架构,不仅继承了已被验证的Xe架构优势,还在提供更强效率与能效比的同时,确保了对现代AI负载的软件兼容。 得益于LPDDR5x显存的加持,Crescent Island可提供高达480 GB的超大容量,在大幅降低TCO的同时,高效应对海量、词元密集型的工作负载。它采用的高能效350W风冷PCIe设计,能够以卓越的能效比实现智能体AI的高效扩展。此外,该GPU支持广泛数据类型,涵盖从原生FP4到FP64,为运行各种应用提供了不做妥协的灵活性。 英特尔Crescent Island依托历代Xe架构庞大的装机量积累,专为下一代AI工作负载设计。它支持从原生FP4/MXFP4到FP64的广泛数据类型和微缩放格式,包括对先进AI运营的扩展支持,并提升了内存性能与可扩展性。 同时,英特尔开放式可编程AI软件栈支持异构计算平台,该平台通过“上游优先”策略,带来开箱即用的模型体验,从而减少迁移阻力并加速AI规模化落地。基于相同的Xe架构基础,英特尔锐炫Pro系列提供了一个理想的开发平台,使开发者能在熟悉的硬件上构建、验证和优化工作负载,并通过向前和向后兼容性在Crescent Island上进行无缝部署。 补充说明: 实际性能因使用情况、配置和其他因素而异。详情请参阅 www.intel.com/PerformanceIndex。 1.请参阅 intel.com/processorclaims 上的 [9D23]:英特尔® 至强® 6+。结果可能有所差异。 2.请参阅 intel.com/processorclaims 上的 [W223]:英特尔® 至强® 6+。结果可能有所差异。 3.请参阅 intel.com/processorclaims 上的 [9W020]:英特尔® 至强® 6+。结果可能有所差异。 *关于工作负载和配置信息,请访问 www.intel.com/PerformanceIndex 的以太网(Ethernet)部分。结果可能有所差异。 通知与免责声明: 性能结果基于配置说明中注明的测试日期,未必涵盖所有公开的后续更新。详细配置请参阅备份文档。任何产品或组件都无法绝对保障可靠性。您的成本及结果可能有所差异。英特尔技术可能需要启用特定的硬件、软件或激活服务。
英特尔
英特尔中国 . 昨天 693

现阶段空调风机、水泵、洗护家电及各类小家电领域的电机驱动方案,普遍存在外围器件繁多、布线空间受限、开发周期长、可靠性与成本难以兼顾等困境。 相较于单纯的性能升级,精简硬件架构、降低系统复杂度才是当下研发的核心诉求。 JWP79336DM67高压集成IPM应运而生,芯片整合32位控制内核、高压MOSFET、三相预驱和5V稳压模块,搭载电机控制专用ADC、OPA、ACMP、DAC以及Timer等外设资源,大幅减少外围元器件、简化硬件设计,为高压三相电机应用提供更紧凑的实现路径。 单芯片集成方案,重塑驱动系统架构 JWP79336DM67通过更高集成度的系统设计思路,将控制、驱动、功率和供电能力集中于单芯片之中,有助于降低BOM复杂度,缩小PCB占用面积,让整体设计更加清晰高效,从根源上简化硬件开发流程。 深度适配电机控制,支持多类控制算法 JWP79336DM67集成32位控制内核,CPU 频率最高可达108MHz,搭配片上 Flash/SRAM存储资源,同时产品适配无感/有感、单电阻/双电阻等多种FOC控制方式,为不同产品平台和控制策略提供了更灵活的实现空间。 高压强悍性能,多重防护筑牢系统稳定性 针对高压驱动能力方面,JWP79336DM67推荐VDC工作范围60V~600V,集成600V耐压N-MOS,连续漏极电流最高可达 4A(TC=25°C)。 在防护层面,芯片三相预驱模块自带死区控制与延时匹配功能,并提供欠压锁定、过流保护、过温保护等全套保护机制,全方位规避高压工况下的运行风险,大幅提升系统运行的稳定性与安全性。 集成辅助供电,进一步简化外围设计 JWP79336DM67内嵌5V LDO电源模块。在标准热设计环境下,最大输出电流可达 100mA,可进一步减轻外围电源设计压力,简化电路架构,助力产品小型化升级。 双芯赋能,打造一站式高压电机控制方案 配合用于辅助供电的 JW15325,可构建覆盖前端供电、主控驱动、功率执行与系统保护的一站式高压电机控制解决方案。通过提供参考硬件、控制算法与调试支持,帮助客户缩短开发周期、降低导入风险,加速从设计验证到量产落地。 当下家电电机行业正朝着小型化、高集成、高性价比方向快速迭代,JWP79336DM67以单芯片一体化解决方案,帮助研发团队简化设计、缩短开发周期、严控整机成本,为高压三相小家电电机驱动提供更高效、更优质的全新选型。
领芯微
领芯微电子 . 昨天 3 644
在十五五新基建与双碳政策驱动下,智算中心加速扩容,服务器电源正朝着高效率、高功率密度、高可靠性、智能化方向快速迭代。上海贝岭深耕模拟IC与功率半导体领域多年,打造从功率器件、栅极驱动、电源管理、隔离器、接口芯片、线性电路产品、存储器、控制芯片到计量芯片的全品类配套方案,为服务器电源提供一站式国产化解决方案,助力客户抢占算力时代先机! 图1:上海贝岭服务器电源产品配套框图 功率器件产品矩阵:四大MOSFET器件平台强势覆盖 功率器件是服务器电源高效运行的核心,上海贝岭构建高压 SJ MOSFET、SiC MOSFET、中低压 SGT MOSFET、高压平面MOSFET四大产品平台,覆盖服务器电源全功率段选型需求。 超结MOSFET方面,上海贝岭已经形成多次外延与深沟槽双技术路线并行迭代的格局。其中,G3代深沟槽技术实现cell pitch 7μm、RSP低至1.0Ω·mm²的关键指标;同时兼具超低的栅极电荷Qg与输出电容Coss,有效降低导通损耗与开关损耗,在提升转换效率的同时降低系统温升,延长电源使用寿命。 表1:上海贝岭SJ MOSFET产品选型表 SiC MOSFET方面,基于第五代平面栅技术平台,通过对沟道区进行精细化设计与周期性势场调控,实现了导通电阻、开关损耗与栅极阈值电压漂移的协同优化,确保器件在高温、高频工况下具备优异的稳定性。通过优化栅源电容与栅漏电容比值Cgs/Cgd,增强了栅极抗串扰能力,有效抑制桥式拓扑中的直通风险。结合HU3PAK、QDPAK等高功率密度封装,可进一步优化散热路径与寄生参数,提升器件在高结温、高功率密度工况下的应用能力与系统可靠性。 表2:上海贝岭SiC MOS产品选型表 SGT MOSFET方面,上海贝岭产品覆盖30V至200V全系列。以40V系列产品为例,采用红磷衬底及HDP工艺,可以显著降低衬底电阻及沟道电阻。同时,得益于精心调试的工艺,高密度元胞并没有额外增加应力,wafer仍然可以减薄至100um(非taiko),这也显著降低了衬底电阻。同时支持多管并联应用场景下的栅极阈值电压Vth档位定制筛选,满足模块化服务器电源对多路并联均流的需求。 表3:上海贝岭SGT MOS产品选型表 辅助电源的高压平面MOSFET方面,上海贝岭高压平面MOSFET产品线覆盖100V~1700V宽电压范围,拥有领先的EAS抗冲击能力和短路耐量,为反激式辅助电源提供高可靠性方案。 表4:上海贝岭高压平面MOSFET产品选型表 计量明星产品:高性价比与高集成度的双重选择 在服务器电源领域,能效管理日益精细化,精准的功率监测与电能计量已是刚需。计量产品是上海贝岭的传统优势领域,本次重磅带来从独立计量IC到电能采集专用SoC的完整产品组合: · BL0942:内置时钟免校准,支持电流、电压有效值、有功功率、有功电能量等参数测量,SSOP10/TSSOP14 封装,适配智能计量模块; · BL0971:单相交/直流计量,支持电流、电压有效值、有功功率、无功功率、有功电能、无功电能等参数的测量,QFN20封装,适配交直流能耗监控; · BL6552:7通道三相计量,支持3路电压采集+4路电流采集,适配三相电源监控、电能质量分析; · BL66A02XX:电能采集专用SoC芯片,内嵌 ARM Cortex-M0 内核,256KB Flash+32KB SRAM,集成独立硬件计量单元(EMU),支持全波 / 基波 / 谐波计量、波形重构,丰富通信接口,适配高端服务器电源智能监测与数据交互。 从单独的计量芯片到高度集成的SoC方案,上海贝岭计量产品形成了完善的梯队布局,能够灵活匹配不同服务器电源产品对能效监测的精简与复杂需求,是名副其实的“明星产品”。 上海贝岭服务器电源选型指南 围绕服务器电源供电、控制、监测与通信等需求,贝岭提供电源管理、信号链、计量、存储及隔离等全系列 IC 器件,性能可靠、兼容性强,可灵活匹配不同拓扑与功率等级,助力实现高效、智能的电源设计。 表5:上海贝岭IC产品选型表
上海贝岭
上海贝岭 . 昨天 686

株式会社村田制作所开始提供面向车载UWB(Ultra Wide Band)用途的组合方案与电路设计支持。该方案在分立构成中将晶体谐振器「XRCGE55M200MZF1BR0」与热敏电阻「NCU03XH103F6SRL」组合使用,并提供相应编号建议及电路设计支持。本提案及支持主要面向利用UWB的车载应用,如数字钥匙、CPD(Child Presence Detection)、传感器以及Wireless BMS等。 近年来,在车载UWB应用中,随着数字钥匙和安全功能的不断升级,对宽带通信中的高准确度定时控制需求不断增加。然而在高温环境下,仅依靠晶体谐振器本体较难满足所需精度,因此通常需要利用晶体谐振器内置的温度传感器进行补偿。 另一方面,为了优化成本结构,部分客户希望采用晶体谐振器与外置热敏电阻的分立构成方式,但在电路设计及温度补偿方面存在一定难度。 为此,村田开始提供晶体谐振器「XRCGE55M200MZF1BR0」与热敏电阻「NCU03XH103F6SRL」在分立构成中的组合方案,并提供用于温度特性补偿的电路设计支持。 在本支持服务中,客户可通过支持链接进行咨询。村田可借用客户的安装基板,对安装本产品后的温度特性参数进行测量,并提供相关数据。 通过上述支持,即使在分立构成条件下,也可以使用针对安装基板优化后的补偿参数,从而有助于实现客户的性能目标,并提高设计流程效率。 此外,本组合方案中的晶体谐振器「XRCGE55M200MZF1BR0」为新产品,已于2026年3月开始量产。该产品实现了2016的小型尺寸、高可靠性以及低故障率,有助于车载应用设备的小型化以及安全功能的升级。 主要特点: 晶体谐振器XRCGE55M200MZF1BR0 支持高准确度温度补偿:通过专有切割技术,对高温环境下的温度特性曲线进行优化 面向车载应用的高可靠性: 确保工作温度115℃,低故障率(无微粒) 设计支持:通过温度补偿电路的技术支持,使分立构成的设计更加容易实现 稳定供应 无铅 规格 产品 XRCGE55M200MZF1BR0 尺寸 2.0 x 1.6 mm 振荡频率 55.2MHz 频率偏差(25℃) ±10ppm 频率温度特性 ±10ppm(※补偿后特性、-40~115℃) 主要特点: 热敏电阻NCU03XH103F6SRL 适用于汽车等需要高可靠性部件的设备 采用铜电极实现小型化:0.02 × 0.01英寸(0.6 × 0.3 mm) 由于体积较小,可实现迅速响应 规格 产品 NCU03XH103F6SRL 尺寸 0.6 x 0.3 mm 电阻值(25℃) 10 kΩ±1.0% B常数(25/50℃) 3380 K±1.0% 工作温度范围 -55~+125℃
村田
Murata村田中国 . 昨天 616

随着人工智能基础设施算力规模持续高速扩张,行业对高压配电与高集成密度的需求愈发迫切。当下快速普及的800V直流数据中心架构,不仅能实现更高能效、减少功率损耗,还可为超大规模云服务商及AI算力业务,搭建具备更强可扩展性、更高计算密度的基础设施底座。 与此同时,服务器行业正朝着多元化架构演进。GPU代际、服务器高度、机柜外形尺寸和热设计边界的差异,致使大规模训练集群、推理中心和高密度 AI基础设施需要不同的供电拓扑。50V、12V和6V中间直流母线将在未来的智算数据中心中共存,具体取决于机柜密度、GPU配置及散热方案。 针对以上发展趋势,意法半导体联合英伟达,拓展了旗下800V直流电源转换产品阵容,推出全新12V、6V供电架构,与现有的50V方案形成互补,方案全面适配各种高功率密度AI平台,包括基于英伟达MGXᵀᴹ的系统。 依托自身在功率半导体(硅基、碳化硅SiC、氮化镓GaN)、模拟芯片、混合信号芯片、微控制器等领域的技术积淀与整合能力,意法半导体打造出适配多规格AI服务器的完整800V直流产业生态,为千兆瓦级AI算力基础设施规模化部署提供坚实支撑。 ▲图片来源:ST领英
ST
意法半导体中国 . 昨天 441
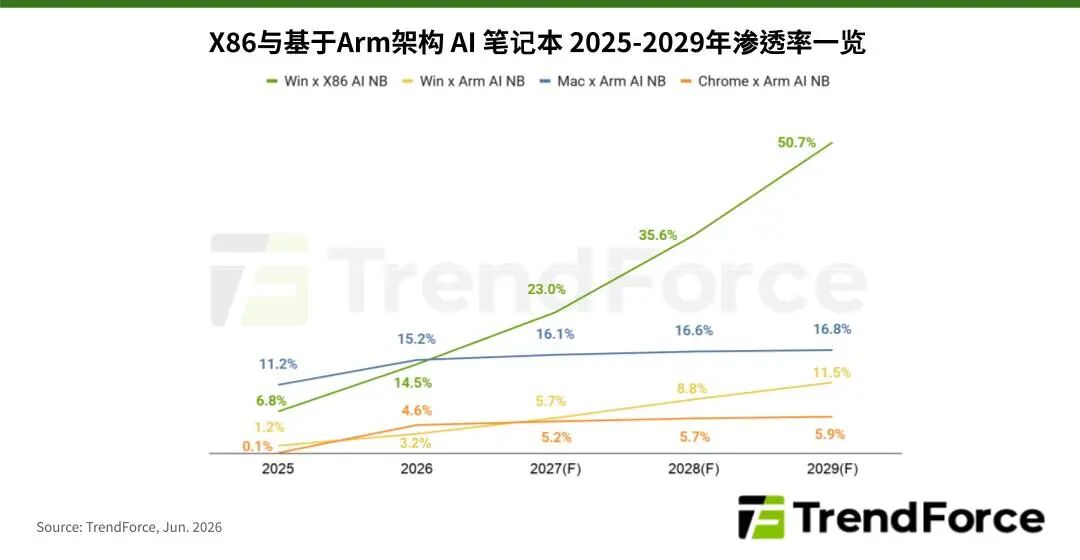
TrendForce集邦咨询最新研究指出,目前AI笔记本主要由Intel(英特尔)、AMD(超威)、Apple(苹果)与Qualcomm(高通)推动,但市场仍缺乏能够大规模展现装置端AI运算价值,并形成明确使用者换机动力的产品。随着Nvidia(英伟达)于Computex正式发表RTX Spark平台搭配N1与N1X处理器,AI笔记本市场有望从目前以NPU功能展示为主的阶段,进一步迈向以Agent与本地端模型运算为核心的新发展阶段。 TrendForce集邦咨询表示,RTX Spark平台的意义不仅在于新增Windows on Arm阵营的重要成员,更首次将CUDA生态系延伸至Windows笔记本市场,预估将快速提升AI笔记本渗透率,由2025年的19.3%与2026年的37.5%提升至2029年的84.9%。 N1/N1X处理器由Nvidia与联发科(MTK)合作推出,扮演开拓高端市场的关键。此架构整合了高性能Arm架构CPU、Blackwell架构GPU、CUDA生态系,并支持最高128GB Unified Memory配置,让硬件性能与作业系统、专业软件层面达到深度整合。 受惠于装置端算力提升,文件搜寻、简报制作、知识库查询、工作排程及部分AI Coding等应用,未来皆有机会直接在本地端完成,降低对云端算力与Token消耗的依赖。随着AI Agent逐步普及,PC角色也将由被动工具转变为主动助理,带动换机需求由硬件规格升级转向应用价值升级,成为2027年后推动笔记本市场成长的重要动能。 Windows on Arm、Apple M与Chromebook共同推升,Arm架构笔记本迎新局 从AI笔记本市场结构来看,目前AI笔记本仍以Windows x86平台为主,其渗透率由2025年的6.8%提升至2026年的14.5%,预估2029年将占整体市场约50.7%。相较之下,Windows on Arm AI笔记本虽然目前基期较低,但成长速度在Qualcomm与Nvidia陆续加入此阵营后将明显加速,渗透率将由2025年的1.2%提升至2026年的3.2%,预期将于2029年进一步成长至11.5%,显示Arm架构正逐步扩大在Windows笔记本市场的影响力。 除了Windows on Arm的发展外,Apple M系列预计维持约17%的笔记本市场占比,持续扮演Arm架构笔记本的重要组成。另一方面,随着Intel与AMD近年将资源逐步转向AI笔记本与高端商务机型,在Chromebook市场投入相对保守,这也让联发科(MTK)在今年有机会通过AI Chromebook进一步扩大在Chromebook平台的渗透率。在Windows on Arm、Apple M与Chromebook系列共同带动下,预估2029年Arm架构笔记本渗透率将达34.2%。 TrendForce集邦咨询指出,在Nvidia RTX Spark平台(N1/N1X)、Qualcomm Snapdragon X以及未来更多Arm架构芯片陆续进入市场后,Windows笔记本市场将由过去以Intel与AMD竞争,逐步转向多架构、多平台并存的新局面。
英伟达
TrendForce集邦 . 昨天 1 427
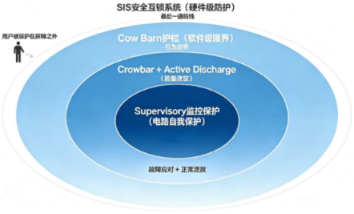
最近看到一个有趣的视频:一个人形机器人在自主整理客厅,但它不是机械地执行程序,而是学会了像人一样“偷懒”走捷径。毛巾用完直接甩肩上,箱子太大随手夹腋下。这画面让人莞尔,却又细思极妙:机器,开始有“思考”了!当机器人不再盲目遵循指令,而是自主选择路径时,我们该如何确保它选择的“捷径”不会伤到人、不会撞坏东西?这就引出了一系列保障安全的系统设计,它们像一道道看不见的护栏,守护着机器人与人类共处的日常。 图1 安全防护分层结构图 先说SIS(Safety Interlocking System),安全互锁系统,这是工业安全领域的基础概念。所谓互锁,是指在两个或多个可能产生冲突的动作之间建立制约关系。在机器人系统里,SIS通常以硬件逻辑实现,独立于主控程序之外。例如,当机器人伺服驱动器检测到外部信号异常时,会通过安全继电器直接切断动力回路,而不是等待软件响应。这是一种物理层面的互锁机制,即使主控程序崩溃、通信中断,SIS依然能确保机器人不会做出危险动作。比如在有人靠近时禁止高速运动,或在双臂交汇时防止碰撞。 再来看Cow Barn,护栏,直译是“拦牛梁”,即牧场里防止牛发疯乱撞的那根横木。牛受惊时横冲直撞,这根梁就拦住它,不让它冲出围栏伤到人。在机器人系统里,Cow Barn是同样的角色:它在软件层面设定了不可逾越的边界。比如在伺服驱动系统中,我们会为每个运动轴设定位置极限、速度极限、力矩极限。当机器人的“自主决策”试图超出这些阈值时,Cow Barn机制会强制介入,或减速,或停机,或反向回退。 安全互锁系统(SIS)和护栏(Cow Barn),都是从保护用户出发的设计,守护着人与机器的边界。但我们还需要另一层保护——对电路本身的保护,即Supervisory(监控保护)。在电力电子系统中,这通常包括过压保护、过流保护、过温保护等。它由专门的监控芯片或比较器电路实现,持续检测关键参数,一旦发现异常,会切断电源或降低功率,防止电路烧毁。这层保护不直接与人相关,却是系统能长期稳定运行的基础。 说到这里,不能不提一个容易混淆的概念Crowbar。这个词直译是“撬棍”,名字非常形象。想象一下失控的马车,车夫情急之下将一根撬棍插进车轮辐条,让车轮卡死、马车骤停。这很粗暴,但很有效。在电源系统中,Crowbar电路用来实现:当检测到电压过高或故障时,它会故意把电路短路,让电压瞬间跌落,迫使系统停机。Crowbar是强制放电,是一道物理防线。有意思的是,早年间治安员曾用过类似的办法,手持长棍,不是打人,而是朝飞车抢劫的摩托车轮辐里一杵,逼停摩托。这撬棍就是现实版的Crowbar,粗暴直接,但有效。 而另一个与Crowbar电路形似而神不似的概念叫Active Discharge,主动放电。在电机驱动或开关电源中,母线电容在系统停机后往往残留高压电荷,这对设备以及维修人员构成安全隐患。主动泄放电路的作用,就是在系统断电后,通过受控的开关器件和泄放电阻,将残余能量以可控的速率释放掉。它与Crowbar的本质区别在于:Crowbar是故障触发的、不可恢复的、破坏性的;而Active Discharge是计划内的、可控的、无损的。 回过头看那个学会“偷懒”的机器人,它的聪明让人欣喜,但真正让它能安全地走进家庭、走进工厂的,正是这些看不见的“护栏”层层设防:最底层是电路级的监控保护(Supervisory),守护着系统自身的稳定运行;向上是能量级的主动泄放(Active Discharge)和撬棍电路(Crowbar),一个负责正常停机,一个应对极端故障;再往上是行为级的安全限界(Cow Barn),在软件层面框定机器人的活动范围;最外层是系统级的安全互锁(SIS),用硬件硬线守住最后的底线。当然,这些都离不开底层硬件的支撑。圣邦微电子提供的Supervisory系列产品(详见表1),不仅实现了电路级的监控保护,更为能量级泄放、行为级限界、系统级互锁等上层安全护栏的设计提供了坚实的支撑,让层层设防可真正落地为可靠的安全保障。 表 1 圣邦微电子 Supervisory 系列产品 以上所列仅为部分具有代表性的产品型号,如需了解更多详细信息,欢迎登录圣邦微电子官方网站 www.sg-micro.com 。
圣邦微
圣邦微电子 . 昨天 462
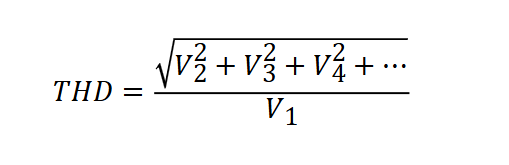
引言 总计谐波失真 (THD) 是信号中存在的谐波失真,定义为一组较高谐波频率的均方根 (RMS) 振幅与一次谐波或基频的 RMS 振幅之比。公式 1 将 THD 表示为: 公式 1 其中 Vn 是 n 次谐波的 RMS 值,V1 是基波分量的 RMS 值。 在电力系统中,这些谐波会导致从电话传输干扰到导体性能下降等各种问题;因此,控制总 THD 非常重要。THD 越低,电机中的峰值电流越低、发热越少、电磁辐射越低、磁芯损耗越小。 降低 THD 需要功率因数校正 (PFC),这是输入功率大于 75W 的交流/直流电源所必需的。PFC 会强制输入电流跟随输入电压,以便电子负载生成包含超小谐波的正弦电流波形。 THD 要求越来越严格,在服务器应用中尤其如此。模块化硬件系统通用冗余电源 (M-CRPS) 规范在整个负载范围内定义了非常严格的 THD 要求,如 表 1 中所示。这比之前的 CRPS THD 规范更为严格。 表 1 M-CRPS THD 规范 图 1 该电路通常在隔离式电源中生成反馈信号。在传统的环路调优可能无法满足要求的 PFC 设计中,满足此类严格的 THD 规范是一项巨大的挑战。本文将提供几种额外的方法来帮助降低 THD。 确保检测到的信号干净 PFC 控制器可检测交流输入电压、电感器电流和 PFC 输出电压。这些检测到的信号必须干净,否则会影响 THD。例如,由于交流输入电压信号生成正弦电流基准,因此检测到的信号上的任何尖峰都会导致电流基准失真并影响 THD。 尽管输出电压 (VOUT) 信号不用于生成电流基准,但它也可能会影响 THD,因为 VOUT 上的尖峰会在电压环路输出上产生纹波,这会影响电流环路基准并最终影响 THD。如果尖峰的幅度足够大,则可能会触发电压环路非线性增益,从而显著提高 THD。 一种常见的做法是将去耦电容器放置在靠近控制器检测引脚的位置。您必须仔细选择电容,以便有效降低噪声,但不引起过多延迟。使用一个数字无限脉冲响应滤波器来处理检测到的 VOUT 信号可进一步减少噪声;由于 PFC 电压环路比较慢,由该数字滤波器导致的额外延迟是可以接受的。 不过,对于交流电压检测,不建议添加数字滤波器,因为它会导致电流基准出现延迟。在这种情况下,您可以使用固件锁相环 (PLL) 来生成与交流电压同相的内部正弦波信号,然后使用生成的正弦波信号来调制电流基准。由于 PLL 生成的正弦波是干净的,即使检测到的交流电压上有一些噪声,电流环路基准也是干净的。 降低交流过零点处的电流尖峰 交流过零点处的电流尖峰是图腾柱无桥 PFC 的固有问题。这些尖峰可能会非常大,以至于无法符合 M-CRPS THD 规范要求。通过分析这些尖峰的根本原因,发现脉宽调制 (PWM) 软启动算法(如 图 1 中所示)可有效地减少尖峰。 图 1 交流过零点处的栅极信号时序 在此解决方案中,当 VAC 在交流过零点后从负周期变为正周期时,有源开关 Q4 首先以非常小的脉冲宽度导通,然后逐渐增加到由控制环路生成的占空比 (D)。Q4 上的软启动会逐渐将开关节点漏源电压 (VDS) 放电至零。一旦 Q4 的软启动完成,同步晶体管 Q3 开始导通。它从很小的脉冲宽度开始,然后逐渐增加,直到脉冲宽度达到 1-D。当 Q4 的软启动完成且 Q3 的软启动开始时,低频开关 Q2 导通。 过零检测可能会被噪声错误地触发。出于安全考虑,在半个交流周期结束时,关断所有开关。这样会形成一个较小的死区,从而防止输入交流短路。从交流正周期到负周期的转换是相同的。图 2 展示了测试结果。 图 2 不使用和使用 PWM 软启动功能时的电流波形:传统控制方法 (a) 和 PWM 软启动 (b) 降低电压环路影响 电压环路输出上的双倍工频纹波会影响电流基准,从而影响 THD。为尽可能减少这种频率纹波的影响,同时又不影响负载瞬态响应,您可以在 VOUT 检测信号和电压环路之间添加一个数字陷波(带阻)滤波器。该陷波滤波器可以有效地衰减双倍工频纹波,同时仍能传递所有其他频率信号,包括负载瞬态导致的 VOUT 突变。负载瞬态不会受到影响。 另一种方法是在交流过零实例处检测 VOUT。由于交流过零实例 Vout_zc(t) 处的 VOUT 的值等于其平均值,并且在稳态下是一个“常量”,因此它是用于电压环路控制的理想反馈信号。若要处理负载瞬态,请使用以下电压环路控制律: 电压环路控制律 如果瞬时 VOUT 误差很小,请使用交流过零实例 Vout_zc (t) 处的 VOUT 值和小比例积分 (PI) 环路增益 Kp、Ki 计算电压环路补偿器 Gv。当发生导致瞬时 VOUT 误差大于阈值的负载瞬态时,为 Gv 使用瞬时 Vout(t) 值和 PI 环路增益 Kp_nl、Ki_nl 可将 VOUT 迅速恢复至其标称值。 过采样 PFC 电感器电流是在每个开关周期中具有直流偏移的锯齿波;该电流随后进入运算放大器等信号调节电路,使信号适合 PFC 控制电路。不过,该信号调节电路无法充分衰减输入电流纹波。电流纹波仍出现在放大器的输出端。如果该信号在每个开关周期内仅采样一次,则不存在该信号始终代表平均电流的理想固定位置。因此,使用单个样本时,很难实现良好的 THD。 为了获得更准确的反馈信号,建议使用过采样机制。图 3 展示了可在每个开关周期内对电流反馈信号进行八次平均采样,对结果求平均值,然后将其发送至控制环路。过采样有效地计算电流纹波平均值,以便测量的电流信号更接近平均电流值。此外,控制器对噪声(包括信号噪声和测量噪声)的敏感度会降低。过采样是减少电流波形失真的有效方法之一。 图 3 在每个开关周期中进行八次过采样 占空比前馈 占空比前馈控制的基本原理是预先计算占空比,然后将此占空比添加到反馈控制器中。对于在连续导通模式下运行的升压拓扑,公式 2 可用于计算占空比 (dFF): 公式 2 该占空比形式可在开关上有效地生成一个电压,此电压在一个开关周期内的平均值等于整流输入电压。常规电流环路补偿器会根据计算出的该占空比来更改占空比。 图 4 展示了最终形成的控制方案。使用公式 2 计算 dFF 后,将其与传统的平均电流模式控制输出 (dI) 相加。然后,可以使用最终得到的占空比 (d) 生成 PWM 波形以控制 PFC。 图 4 平均电流模式控制和 dFF 鉴于占空比的大部分是由占空比前馈生成的,控制环路仅对计算出的占空比进行略微调整。这项技术可以帮助改善控制器环路带宽受限型应用中的 THD。 交流周期跳跃 通常,满足轻负载 THD 要求比满足重负载 THD 要求更困难;特别是在满足 M-CRPS 规范中的 5% 负载 THD 要求时,尤其如此。如果 PFC 满足除 5% 负载时以外的所有其他 THD 要求,那么即使您已尝试到目前为止提到的所有方法,交流周期跳跃方法也会有所帮助。 将交流周期跳跃想象成一个特殊的突发模式:当负载小于预定义阈值时,PFC 进入此模式,并根据负载跳过一个或多个交流周期。换句话说,PFC 在一个或多个交流周期内关断,然后在下一个交流周期重新导通。导通和关断发生在交流过零点处,以便跳过整个交流周期。由于 PFC 在电流为零时导通和关断,因此应力和电磁干扰较小。交流周期跳跃与传统的 PWM 脉冲跳跃突发模式(随机跳过 PWM 脉冲)不同。 要跳过的交流周期数与负载成反比;负载越小,跳过的交流周期就越多。图 5 展示了跳过一个交流周期。通道 1 是交流电压,通道 4 是交流电流。 图 5 轻负载下的交流周期跳跃 当 PFC 由于电流为零而关断时,THD 为零。由于 PFC 需要补偿关断周期,因此它在导通时会提供大于平均值的大功率。实际上,这会在中等负载下运行 PFC,或者完全关断。鉴于中等负载时的 THD 远低于轻负载时的 THD,轻负载 THD 有所降低。 测试结果 本文作者在通过德州仪器 (TI) C2000™ 微控制器控制的 3kW 图腾柱无桥 PFC 上实施了本文所述的方法。图 6 展示了 240VAC 时的 THD 测试结果。 图 6 THD 测试结果 THD 不仅符合最新的 M-CRPS THD 规范,而且还具有足够的裕量,可确保 PFC 即使在具有硬件容差的情况下也能在大规模生产期间满足规范要求。
德州仪器
德州仪器 . 昨天 469

新唐旗下晶圆代工业务宣布,自7月1日起再度调涨价格,涨幅最高达30%以上,反映AI浪潮正全面推升公司运营动能。 新唐晶圆代工部门近日向客户发出通知,宣布自2026年7月1日起再度调涨代工价格,整体调幅介于20%至30%之间,部分热门产品甚至超过30%。 新 唐指出,自4月1日完成上一轮价格调整后,AI加速器、HBM封装、硅光子、边缘计算及工业控制等需求同步爆发,产能在短短一个季度内迅速被客户预订一空,部分热门工艺新增需求已排至下一季度。 新唐表示,目前各工艺产能配额已全数由现有客户包下。在供给极度吃紧的情况下,通过更合理的价格机制,才能确保长期客户获得稳定且可预测的产能供应,同时反映成本与市场供需变化。 此外,新唐在AI布局方面也传出捷报。市场消息指出,新唐已成功打入微软(Microsoft)新一代AI ASIC服务器供应链,旗下BMC产品获采用于微软AI ASIC平台,并可同时支持英特尔与AMD架构,成为切入北美云服务商(CSP)市场的重要里程碑。 过去全球BMC市场长期由少数供应商主导,但随着AI服务器需求快速增长,加上客户为降低供应链风险,近年来积极寻找第二供应来源,新唐因此获得切入机会。 据了解,微软AI ASIC服务器平台已开始导入新唐BMC方案,并由联想(Lenovo)负责部分系统制造,订单规模达数十万颗级别,单颗平均售价(ASP)约15美元,预计今年下半年开始放量,并延续至2027年。 机构指出,除微软之外,Google相关项目已开始采用新唐方案,Amazon也正在进行产品验证与测试。 新唐新一代12纳米工艺、支持DDR5的新款BMC产品预计于2026年底推出,并持续拓展北美大型CSP客户。机构预计,新唐AI ASIC相关客户需求今年有望较去年倍增,2027年至2028年进入更大规模增长阶段。 除BMC之外,AI数据中心备援电池(BBU)需求同步攀升,也带动电池管理芯片(BMIC)市场快速增长。新唐凭借多年车规级BMIC技术基础,积极切入服务器储能领域,有望成为未来另一项重要增长引擎。
晶圆
芯查查资讯 . 2026-06-03 679

电动自行车正在迅速重塑城市出行方式。作为汽车之外更可持续、更灵活的选择,电动自行车不仅有助于缓解交通拥堵,也符合绿色低碳的发展趋势。随着电动自行车技术的不断进步和普及,用户对安全性、可靠性和智能辅助功能的期待也在持续提升。 然而,无论是传统机械自行车还是电动自行车,当前仍高度依赖骑手的主动感知以及按计划进行的维护保养。许多机械问题往往是逐步演变的,在性能明显下降或故障真正发生之前,几乎没有预警信号。这种被动式维护方式容易导致意外故障、更高的维修成本,甚至带来潜在的安全隐患。 瑞萨通过AI赋能的智能电动自行车概念方案应对这些挑战。该方案基于嵌入式边缘人工智能(AI),在自行车本体上即可实现预测性维护、智能骑行辅助、环境感知以及电池管理优化,无需依赖云端连接。 嵌入式边缘AI实现预测性与智能骑行 智能电动自行车的核心由Renesas AIK-RA8D1 AI开发套件驱动。该套件基于RA8D1微控制器(MCU)),这是一款面向实时嵌入式AI应用设计的高性能Arm® Cortex-M85® MCU。借助Renesas Reality AI Tools®,开发者可以部署高度优化的AI模型,使其完全运行于MCU本地,无需云端计算支持。 这种系统架构在实现更安全、更高效骑行体验的同时,也有效控制了功耗和系统成本,非常适合大规模部署于智能出行设备中。 AI赋能的智能电动自行车围绕以下两大核心能力,全面提升骑行体验: AI驱动的状态监测:更顺畅、更安全的骑行体验,全面提升用户感受 瑞萨电动自行车概念 链衰减检测 齿轮异常检测 轴承失效检测 损坏发生 帧结构监控 负载分配检测 表面探测 安全骑行的物体检测 用声音空间感知看 AI驱动的状态监测 无论是传统自行车、电动自行车,还是共享出行车队中的自行车,本质上都是精密的机械系统。其性能高度依赖于关键部件的健康状况,包括链条、齿轮、轴承以及车架连接部位。随着时间推移,这些部件会因机械应力、环境影响以及骑行工况而逐渐磨损和劣化。 传统的维护方式通常依赖定期人工检查或基于里程的保养周期。这些方法往往不够精准且偏被动,容易导致突发故障,增加维护成本和运营风险。 通过将AIK‑RA8D1与加速度传感器直接集成到自行车中,实时AI驱动的状态监测成为可能。系统可持续分析振动特征和运动模式,及早发现机械性能退化的迹象。 关键预测性维护功能包括: 链条劣化检测(Chain Deterioration Detection)——系统监测传动系统的振动模式。当振动特征偏离正常状态时,可在性能明显下降之前识别出链条过度磨损或润滑异常问题。 齿轮异常检测(Gear Anomaly Detection)——AI模型可识别由齿轮齿面磨损、损坏或变速器对位异常引起的异常振动模式,实现早期干预。 轴承失效检测(Bearing Failure Detection)——轴承在劣化过程中会产生特定的高频振动特征。系统可在出现可听噪声或严重机械损伤之前就检测到这些异常。 车架结构监测(Frame Structure Monitoring)——通过振动分析,还可识别车架的松动或结构性变化,从而提升骑行安全性并延长整车使用寿命 瑞萨如何实现智能自行车监测 要构建高精度的状态监测AI模型,必须采集涵盖正常运行状态和多种机械故障状态的数据集。 为此,系统采用AIK-RA8D1 AI开发套件,并通过Pmod™模块连接外部加速度传感器。开发套件和传感器均直接安装在自行车上,在真实骑行场景中采集振动和运动数据。 数据集采集通过Data Storage Tools完成。该工具可作为插件集成在Renesas e² studio中,也可作为独立应用供第三方IDE用户使用工具可实时采集加速度传感器的原始数据,并进行存储,用于后续的数据标注和AI模型训练。 Figure1.Training Set-up AI模型开发与部署 在完成数据标注并上传至Renesas Reality AI Tools后,可利用云端AutoML功能训练和评估多个AI模型,并针对RA8D1 MCU进行部署优化。 最终选定的模型能够识别七种系统状态: 电动自行车状态:识别空闲与静止状态 链条运行状态:识别正常的正向与反向链条运动 齿轮异常:基于变速器位置检测两种故障状态 后轮结构状态:识别潜在的后轮松动问题 该优化模型在仅占用5KB内存的情况下,实现了99.63%的识别准确率,可高效运行于RA8D1 MCU上。 Figure2.Model Development to Deployment Flow 部署完成后,推理结果可通过集成在e² studio开发环境中的AI Live Monitor工具进行实时监控。 AI增强型骑行智能 除状态监测外,AIK RA8D1还可作为智能电动自行车计算核心,充当中央处理节点,分析来自电机、电池及各类传感器的数据——支持在有或无额外传感硬件的情况下运行。 AI赋能的骑行功能示例包括: 载荷分布检测——通过分析振动与运动信号,系统可估算骑手及货物的重量分布。据此推荐或自动调整坐垫位置,以提升舒适性和踩踏效率。 路面类型识别(Surface Detection)——AI模型可识别沥青路、碎石路或不平整地形。并根据路况动态调整电机扭矩和功率输出,从而提升稳定性与能效。 目标检测,实现更安全骑行(Object Detection for Safer Riding)——结合视觉传感器时,AI模型可识别周围车辆与障碍物,在盲区来车时触发预警。 “See with Sound”的空间感知能力——通过麦克风阵列,系统可估算周围车辆的来向,并向骑手提供空间方位提示,而无需持续视觉关注。 推动下一代智能出行 AI驱动的智能电动自行车方案充分展示了嵌入式边缘AI对个人出行和共享交通的变革潜力。通过将预测性维护与环境感知能力直接集成到自行车中,制造商能够打造更安全、更可靠、更高效的出行解决方案。 瑞萨AI技术致力于帮助客户基于可扩展的边缘AI平台,构建适用于实时嵌入式部署的智能出行系统。 告别突发故障,从瑞萨开始打造更智能、更安全的自行车。 准备好将AI驱动的状态监测引入骑行领域了吗?
瑞萨电子
Renesas瑞萨电子 . 2026-06-03 637

6月1日,高通技术公司正式发布面向机器人的全栈参考设计高通跃龙™ IQ10机器人参考设计(RRD),凭借高达700 TOPS的强劲AI算力与全栈集成架构,为工业、AMR及人形机器人平台树立了全新性能标杆。 就在行业各界聚焦这款全新产品的战略价值、观望赛道风口之时,阿加犀早已率先卡位、躬身深耕,实现技术与场景的双重落地,领跑行业一步。 别人在“等发布”,阿加犀已在“落地跑” 今年1月,在2026年国际消费电子展(CES 2026)上,阿加犀推出全球首个基于高通跃龙™ IQ10系列的遥操、数采和VLA具身大模型端侧解决方案。该方案充分利用高通跃龙平台的边缘异构计算性能,实现了敏捷的遥操动作同步及高效的数据采集、数据回放、数据标注和数据导出功能。同时,高通跃龙™ IQ10带来卓越的AI算力,让VLA具身大模型在端侧更快速地运行,带来了更加流畅的视觉感知、动作规划、操作执行的端到端性能。 通过结合APLUX先进的具身机器人全栈工具链与高通跃龙™ IQ10,该方案释放性能,为具身机器人的超高算力需求提供卓越支持,让机器人更加智能,并提升端侧处理的时效性,实现出色的动作执行。 高通技术公司副总裁兼ADAS和机器人业务总经理Anshuman Saxena对双方合作高度认可:“高通与阿加犀长期在智能计算领域保持深度协同,持续推进机器人行业软硬件一体化创新。此次我们将合作版图拓展至全新的高通跃龙™ IQ10系列处理器,依托高通在边缘计算、AI处理领域的技术积淀,搭配阿加犀在具身智能赛道的深耕经验,双方将持续赋能端侧AI与机器人技术的深度融合,打造更高效、更智能的行业解决方案,充分释放下一代机器人的商业化应用潜力。” 绝非孤例:从“通天晓”到“数采平台”的全栈先发优势 阿加犀在IQ10上的先手棋,是其深耕端侧AI、与高通技术深度绑定的缩影。事实上,阿加犀的端侧技术能力并非仅停留在单一芯片上。公司旗舰人形机器人“通天晓”便是最佳佐证。 作为全球首款完全依托端侧AI技术打造的人形机器人,“通天晓”秉持“一芯多用”的核心技术路线,全程基于高通算力平台研发落地,目前已成功落地成都春熙路交通劝导、世运会警务巡逻等多个真实场景,充分验证了高通端侧算力+阿加犀全栈方案落地真实应用场景的可行性与稳定性。 相较于行业多数产品的硬件原型定位,阿加犀基于高通跃龙™ IQ10打造的全套解决方案,是一套成熟可落地、可快速复用的商业化具身智能方案,核心覆盖遥操控制、全流程数采、VLA(视觉-语言-动作)大模型三大核心能力,全方位补齐机器人端侧智能化短板。 “当行业还在解读、观望IQ10的硬件参数时,我们的工程师已经基于该平台,在真实场景中完整跑通VLA大模型全流程落地,实现了技术的商用化验证。”公司相关技术人员表示。 目前,这套端侧具身智能解决方案已亮相CES 2026、FAIR plus 2026 等多项全球顶级机器人与智能科技展会,收获了行业广泛关注。 硬件产品层面,阿加犀基于高通 IQ10 平台打造的具身智能硬件,目前研发设计工作已进入收尾阶段,预计将于今年下半年重磅发布。 生态适配层面,团队已规划在端侧AI 生态门户模型广场适配多款基于 IQ10 的具身智能模型,后续将陆续上线,敬请期待。 不止于硬件:构建可复用的端侧AI具身生态 阿加犀的先发优势,不仅体现在硬件方案上,更构建了一个完整的、可复用的软件与生态闭环。公司自研的融合架构操作系统与全栈AI工具链,能帮助开发者将大模型从云端快速迁移至端侧。阿加犀正将基于高通平台的强大算力,转化为每一个开发者和企业都能“开箱即用”的生产力。 随着高通跃龙™ IQ10 RDD的正式发布,端侧机器人的算力底座将更加坚实。阿加犀作为首批生态合作伙伴,已在该平台上积累了从数采、训练到部署的全链路实战经验。随着高通IQ10平台的生态进一步扩展,阿加犀有信心携手更多产业链伙伴,将端侧AI的优势从标杆案例复制到千行百业,加速具身智能的规模化爆发。 我们始终相信,真正的技术领先,不是等待风口,而是提前预判并躬身入局。如今端侧算力全面升级,端侧机器人新时代已至,而阿加犀,早已在路上。 由高通技术公司主办,阿加犀承办,Arduino、瑞莎作为赛事合作伙伴共同参与的“2026高通具身智能与机器人开发者大赛”正在火热报名中! 算控交互一体开发板「犀牛派X1」为机器人开发者提供高效生产力引擎!强大的核心主控支持,为机器人带来前所未有的智能体验和自主能力,实时、高效地运行复杂的人工智能算法及流畅运行多种大模型。
阿加犀
阿加犀智能科技 . 2026-06-03 518

在 COMPUTEX 期间举办的 NVIDIA GTC 台北大会上,全球开发者、研究人员和行业领导者齐聚一堂,深入探讨正在影响各行各业的全新突破,涵盖 AI 工厂以及将基础设施扩展到代理式 AI 和物理 AI 等主题。 NVIDIA 创始人兼 CEO 黄仁勋抵达台北后,行程便一刻未停。 本周黄仁勋所到之处,都能看到生态系统的身影。今天,他们齐聚台北流行音乐中心共同迎来这场主题演讲。黄仁勋向在场的每一位致谢,从各公司 CEO,到他在夜市偶遇的水果摊主。 黄仁勋向现场及线上的观众表示:“如今,AI 已成为利润引擎,也是 GDP 引擎。” “实用 AI 已经到来。”2026 年前几个月里,GitHub 等平台上的开发者提交量已接近此前的三倍。 黄仁勋说,这也让身处这股浪潮中心的人们比以往任何时候都更具价值。 AI 工厂成为新型基础设施 黄仁勋表示,Token 如今已成为可创造利润的营收单元,AI 企业正争相建设更多 AI 工厂,将地区对计算能力的需求推向新高。 黄仁勋强调,在 AI 工厂时代,计算能力就是营收,每生成一个 Token 都能创造利润。这让每瓦性能、可靠性以及系统的长生命周期,成为关键的财务杠杆,而不仅仅是技术指标:“如果你拥有十亿瓦级的电力,那么每瓦吞吐量就是你的收入。仅因为芯片更便宜就选择错误的架构,是没有意义的,因为计算能力就是营收。买得越多,赚得越多。” NVIDIA Vera Rubin 进入全面量产 随后,黄仁勋宣布 NVIDIA Vera Rubin 正在加速进入全面量产阶段。 他表示:“我们为 Vera Rubin 打造的供应链规模是 Grace Blackwell 的两倍。我们需要所有产能来支撑当前的需求。” 智能体迎来专属运行时 黄仁勋将智能体视为下一个重大的计算机遇。 他指出,这一转变将催生一个“前所未有”的全新 CPU 市场,背后驱动力是持续运行、并不断调度工具与数据的自主智能体。 黄仁勋表示:“这种应用模式,将成为每家公司未来十年采用的计算模式。”而智能体将成为它们基础设施中的基础层。 重塑计算机 个人计算经过四十年发展走到了今天。NVIDIA 与微软正在为个人智能体时代重塑 PC——从数据中心一路延伸到桌面端。 黄仁勋发布了 NVIDIA RTX Spark,让轻薄 Windows 笔记本与紧凑型桌面主机都能具备 1 Petaflop 的 AI 性能。 由 MediaTek 联合打造,运行微软 Windows 系统,NVIDIA RTX Spark 将为首个专为个人智能体打造的 PC 提供动力——始终在线、始终本地运行。 黄仁勋说:“这是这段旅程的开端。一条全新的产品线、一个全新的开始。”他指出,未来每一代 NVIDIA 架构都将包含台式机、笔记本与工作站三类产品,并强调“全球 PC 产业已全部加入我们,共同重塑 PC”。 AI 走入物理世界 AI 正在进入工厂、车辆、医院以及支撑这个世界运转的各类物理系统。黄仁勋将其描述为物理 AI 的前沿——在这里,智能体不再只是阅读和书写文本,而是真正在现实世界中感知、推理和行动。 NVIDIA Cosmos 3 全模态模型,Alpamayo 2 Super 自动驾驶推理模型以及 NVIDIA Isaac GR00T 参考人形机器人等解决方案更新,帮助企业和开发者加速部署物理 AI 应用。 全栈产品已正式交付 黄仁勋称,Vera Rubin 目前已进入全面量产阶段。它不只是一款 GPU,而是一套完整的分布式智能体处理系统。Grace Blackwell 主要用于 AI 计算,尤其是推理任务,而 Vera Rubin 则专门适配智能体的运行需求。 他表示,NVIDIA 如今已转型为基础设施企业,它不再只是单纯的显卡厂商、系统厂商,而是致力于帮助客户尽快实现收益与利润最大化的基础设施服务商。 “我要感谢与各位的合作和深厚情谊。若没有我们共同付出的努力,就不可能有今天的成就。”
NVIDIA
NVIDIA英伟达网络 . 2026-06-03 1799

随着 AI 从云端逐步走向边缘侧(Edge),多目标检测(Multi-Object Detection,MOD)正在被越来越多地应用于工业视觉、智能交通、机器人、智慧零售与边缘安防等场景。 相比云端部署,Far Edge 场景对于系统实时性、功耗、带宽与热设计提出了更高要求。设备往往需要在本地完成目标识别、分析与决策,同时还需要满足低延迟、长期稳定运行以及有限功耗预算等条件。 在这一背景下,传统 CPU 或 GPU 架构在部分边缘场景中开始面临新的挑战。 Far Edge AI 对多目标检测提出了哪些新要求? 在 Far Edge 环境中,设备通常无法依赖持续稳定的云端连接,越来越多 AI 推理任务需要直接在本地完成。 这意味着系统不仅需要具备目标检测能力,还需要在有限资源下实现: 更低延迟(Low Latency) 更低功耗(Low Power) 更高实时性(Deterministic Performance) 更小体积与热设计压力 更高系统稳定性 与此同时,多目标检测本身也正在变得更加复杂。 相比单目标识别,MOD 需要同时处理多个目标的位置、分类与跟踪信息。当场景中目标数量增加、运动状态变化或环境复杂度提升时,系统对于并行计算与实时处理能力的要求也会进一步提高。 对于工业自动化、智能摄像头与嵌入式视觉系统而言,这种需求尤为明显。 为什么 FPGA 更适合 Far Edge 多目标检测? 在边缘 AI 场景中,FPGA 的价值不仅仅在于“可编程”,更重要的是其能够在性能、功耗与实时性之间实现更好的平衡。 白皮书指出,相比传统处理器架构,FPGA 可以通过高度并行化的数据处理方式,在保持较低功耗的同时,实现更稳定的实时推理能力。 对于 Far Edge 场景而言,这意味着系统能够: 在有限功耗预算下运行 AI 推理 降低系统热设计复杂度 实现更确定性的延迟表现 根据不同应用需求进行灵活配置 支持长期生命周期部署 这也是 FPGA 在工业视觉、边缘 AI 与嵌入式智能系统中持续受到关注的重要原因之一。 面向边缘视觉,Lattice sensAI™ 8.0 提供了哪些能力? 在白皮书中,莱迪思进一步介绍了基于 Lattice sensAI™ 8.0 的多目标检测实现方案。 该方案支持 Generic MOD 与 Automotive MOD 等不同模型类型,并结合量化工具链与 FPGA 推理架构,实现面向边缘侧部署的 AI 推理能力。 白皮书中还进一步探讨了: YOLO-like anchor-free 架构 fixed-point FPGA deployment 模型量化与优化 边缘 AI 推理效率 不同 MOD 架构之间的设计权衡 通过软硬件协同优化,开发者能够更高效地将 AI 视觉能力部署到资源受限的边缘设备中。 从云端走向 Far Edge,边缘 AI 架构正在变化 随着 AI 应用持续向边缘扩展,系统设计重点也正在从“单纯提升算力”,逐步转向: 功耗效率 实时响应 系统稳定性 长生命周期部署 可扩展与可配置能力 对于工业视觉与边缘智能设备而言,低功耗 FPGA 正在成为越来越重要的计算平台之一。
Latticesemi
Latticesemi . 2026-06-03 490

由电动汽车产业技术创新战略联盟提出,苏州国芯科技股份有限公司、北京开源芯片研究院、中国汽车工程研究院股份有限公司、普华基础软件股份有限公司联合牵头研制的《基于RISC-V架构的汽车控制芯片技术规范》团体标准已按《中国汽车工程学会标准(CSAE)制修订管理办法》有关规定通过立项审查,现正式列入中国汽车工程学会“团体标准提升引领计划”,并申报引领性团体标准,起草任务书编号为2026-058。 标准研制背景 汽车控制芯片是整车动力、底盘、智能驾驶核心域控的硬件中枢,直接决定行车实时控制能力与整车安全底线,是汽车架构向中央计算、跨域融合升级的核心底座。当前RISC-V开源架构已成为车载芯片升级主流方向,但行业缺乏统一车规级技术规范,芯片设计、软件适配、测试验证标准不一,生态碎片化严重。同时,我国高端车载主控芯片对外依存度高,传统封闭架构存在授权受限、供应链承压等现实隐患,产业自主可控攻坚迫在眉睫。 立足车载高可靠、高安全硬性车规要求,本标准旨在统一全链设计规范,依托RISC-V开源架构补齐国产芯片技术短板,筑牢自主可控汽车芯片供应链。标准围绕实时性与确定性、可靠性与耐久性、可扩展性与兼容性、功能安全、信息安全五大核心维度提出全流程设计要求,覆盖芯片架构研发、底层软件适配、合规测试核验全链路,精准补齐产业短板,护航国产高等级车规控制芯片规模化量产上车,夯实智能汽车产业安全发展根基。 国芯科技基于RISC-V架构,完成开源架构汽车控制芯片样件开发,验证了多核RISC-V在车规场景的可行性。该样件面向高可靠、高安全需求,形成多核RISC-V抗量子高性能AI MCU方案,可支撑智驾主控、跨域控制、底盘域控、动力域控、电池管理等车载应用技术验证。 CCRC4086开源架构芯片 芯片研发场景 标准研制主要内容 本标准提出基于RISC-V 架构的汽车控制芯片基础设计原则,规定 RISC-V 内核技术要求、芯片技术要求、基础软件技术要求及对应测试验证方法,覆盖芯片设计与架构、软件开发、测试与验证全流程。 标准框架标准主要内容分为以下几个部分: 1.RISC-V内核技术要求 规范基础指令集、扩展指令集选用,明确处理器核功能特性; 覆盖锁步机制、权限控制、预取与分支预测、核内紧耦合存储器(TCM)、Cache 管理、调试接口、地址转换保护及虚拟化支持等关键功能要求。 2.芯片技术要求从功能、性能、电气特性、可靠性、电磁兼容性、功能安全、信息安全七个维度提出综合设计要求;明确处理器子系统、存储架构、总线互连、中断系统、外设接口、调试跟踪、电源管理、硬件虚拟化等关键模块设计规范,确保芯片设计符合基础原则。 3.基础软件技术要求明确硬件抽象层(MCAL)、虚拟化管理(Hypervisor)、操作系统(OS)、中间件及工具链技术要求;覆盖驱动模块设计、实时性保障、虚拟机资源隔离与生命周期管理、操作系统任务调度与内存保护,以及编译器、调试器、软件验证工具合规性要求。 4.试验方法针对上述技术要求制定配套验证流程,包括RISC-V 内核指令集与核心功能试验、芯片全维度性能与安全试验、基础软件全栈合规性试验,为芯片测试与上车验证提供依据。 芯片测试场景本标准贯通IP集成、芯片设计、软件开发、测试,在规范传统控制芯片基础上,前瞻布局多核异构、虚拟化前沿技术;深度融合功能安全与信息安全,纳入国密及抗量子密码算法,可保障车辆生命周期内抵御量子攻击,技术达国际先进水平,赋能智能网联汽车长效发展。 征集参与单位 《基于RISC-V架构的汽车控制芯片技术规范》标准项目已启动参编申报,计划近期召开标准启动会,诚邀行业内相关企业、研究机构和专家学者参与标准的制定工作,共同推动中国汽车安全领域的发展。
国芯科技
苏州国芯科技 . 2026-06-03 560

格罗方德(GlobalFoundries,纳斯达克代码:GFS)今日正式宣布,已完成对新思科技(Synopsys)ARC 处理器 IP 解决方案业务的收购。结合格罗方德旗下 MIPS 公司,此次收购标志着格罗方德成为专为物理 AI 量身打造、提供从软件到芯片全流程服务的技术合作伙伴。 MIPS 公司业务与 ARC 两大业务整合后,将 RISC-V 处理器 IP、软件工具、定制设计及先进制造结合形成一体化解决方案;同时,通过引入业界一流的处理器和 AI 人才,此次收购进一步加深了格罗方德的工程实力,以加速技术创新。 格罗方德旗下公司 MIPS首席执行官Sameer Wasson表示:“物理 AI 正推动计算、软件与工艺技术的深度融合,客户亟需具备这三大能力的合作伙伴。随着 MIPS 与 ARC 两大业务整合落地,格罗方德已形成涵盖软件、IP及定制化芯片的服务能力,赋能客户在汽车、工业机器人、嵌入式系统等领域,构建差异化、面向特定应用的解决方案。MIPS将作为全栈技术合作伙伴,深度参与产品设计周期。” 代理式AI(Agentic AI)正加速从数据中心走向物理世界,催生出全新的物理 AI 与自主平台,广泛应用于汽车雷达、高级驾驶辅助系统(ADAS)、工业机器人、智能工厂及新一代物联网设备。这些系统必须在严苛的功耗和延迟限制下完成实时感知、推理、执行和通信,因此,融合通用计算、AI加速、传感与互联能力的定制芯片,成为保障产品性能、加速市场普及的关键。 英飞凌科技汽车软件与生态系统副总裁 Thomas Schneid 表示:“汽车与工业系统正日益向实时化和 AI 驱动化方向发展,我们亟需能够大规模提供标准IP 和优化硅设计,并且具备行业现在所需的供应链弹性的技术合作伙伴。格罗方德通过整合 MIPS 与 ARC 处理器 IP 业务,并结合其制造规模,为助力企业打造面向新一代智能系统的差异化、低功耗解决方案,奠定了端到端技术底座。” 交易完成后,ARC 处理器 IP 业务正式并入格罗方德旗下 MIPS 公司,成为其不断拓展的物理 AI 产品组合之一。MIPS 与 ARC 业务结合,共同构建了业界领先的 RISC-V 处理器 IP 产品组合,覆盖高性能、中阶及超低功耗计算与 AI 内核,拥有 150 余项专利,并形成涵盖全球超过 300 家 IP 客户的生态体系。本次收购的资产还包括专用指令集(ASIP)处理器工具 ——ASIP Designer 与 ASIP Programmer,助力客户设计并编程适配自身特定工作负载的定制化处理器。依托格罗方德的设计支持、定制芯片能力、先进的软件工具以及全球制造布局,客户将能够通过单一合作伙伴获得从架构到芯片的一站式支持,实现早期介入、打造差异化产品并加速其上市进程。 格罗方德正与新思科技紧密合作,确保员工、客户及合作伙伴的平稳过渡。新思科技将保留并持续拓展其接口 IP与基础 IP产品组合,格罗方德则全面接管 ARC 处理器 IP 业务的所有权及管理权。
格罗方德
格罗方德 . 2026-06-03 560
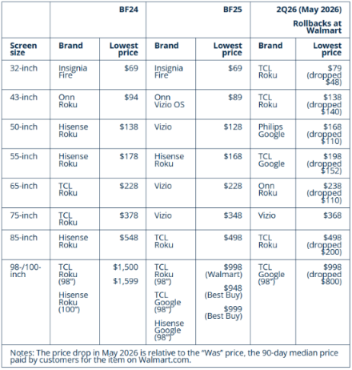
要点 沃尔玛(Walmart)2026年5月的 Rollbacks(降价)活动,对目前提供的电视产品进行了折扣达30–50%的促销。 亚马逊(Amazon)正式宣布,其2026年的Prime Day(会员日)促销活动已从往年的7月提前至6月举行。 大型与超大型电视的降价幅度更为显著,这表明市场正转向大尺寸及高阶产品,以管理电视物料清单(BOM)中的记忆体成本占比。 零售商与电视厂商之间的竞争,似乎抵消了大幅上涨的供应链成本,使得低价电视在市场上依然普遍可见。这些价格促销可能会让电视品牌和OEM感到不满,他们将渴望把上涨的供应链成本转嫁给零售商。 如果零售巨头在五月和六月的促销活动能带动流量并符合预期,第三季需求大幅调整的风险将得以消除,尽管仍预期会有一定程度的调整。 电视显示器产业面临的风险在于考虑到2026年下半年的部分电视购买需求已提前至上半年释放,2026年下半年的消费者需求可能会弱于预期。此外,还需要考虑下半年电视平均售价(ASP)可能会提高,这将影响市场需求。再者,持续的地缘政治动荡和顽固的通膨,将威胁并抑制2026年下半年的消费者支出。 2026年第一季度,显示面板需求表现强劲,这一趋势部分得益于2025年第四季度电视面板价格降至两年低点所带来的需求释放。然而,由于2月中国春节假期、FIFA世界杯筹备需求,以及围绕《美墨加协定》(USMCA)可能调整带来的关税不确定性,2026年第一季度,面板价格再次出现回升。 在这一强劲需求的带动下,面板厂商持续维持较高稼动率,预计这一趋势将在2026年第二季度延续。然而,行业仍面临潜在需求回调风险,主要来自不利的外部环境因素,包括伊朗冲突引发的地缘政治不稳定及其带来的通胀压力,这可能对电视市场需求形成负面影响。 与此同时,AI生态系统的繁荣推动内存及关键组件价格快速上涨,促使电视厂商上调产品平均售价(ASP)。虽然价格提升有助于缓解成本压力,但也可能对市场需求造成抑制。如果电视厂商无法将不断上升的供应链成本顺利转嫁给零售商及消费者,其在2026年第二季度可能面临更大盈利压力。 行业参与者目前正重点关注6–7月世界杯期间的终端销售表现,该节点被视为评估并调整电视面板采购计划的重要依据。然而,电视厂商可能难以匹配大型零售商在5–6月推出的促销力度,例如沃尔玛的“Rollback”及亚马逊Prime Day活动。 近年来,美国零售巨头(如沃尔玛、亚马逊、百思买Best Buy、好市多Costco)以及欧洲分销渠道之间的竞争持续加剧,同时电视品牌与OEM厂商之间的价格竞争依然激烈。这种双向价格竞争在一定程度上抵消了内存价格飙升带来的供应链成本上涨,使得低价电视产品仍广泛存在于市场中。 例如,沃尔玛在2026年5月的Rollback促销活动中,对电视产品提供30%–50%的价格优惠。这类大幅折扣可能令电视品牌与OEM厂商承压,因为它们希望通过提高价格来转移供应链成本压力,但零售商往往将价格压力继续传导至消费者。 当前,零售巨头与头部电视厂商未必能从电视硬件业务中获得可观利润,部分企业甚至可能因与中国电视品牌/OEM的激烈竞争而在硬件业务上承受亏损。然而,一些具备自有电视平台或能够获得平台补贴的企业,仍可通过平台业务盈利来弥补硬件端损失,从而维持低价促销策略以争夺市场份额与流量。然而,在当前不确定的外部环境与行业竞争格局下,低端零售商及电视厂商的生存空间正面临持续挤压与挑战。 2026年下半年电视需求展望情景分析:有何预期? 在2026年第二季度或第三季度初,随着库存去化及前述促销活动结束,显示供应链参与者将在2026年第三季度与2026年第三季度面临更直接的挑战。2024年第二季度,促销周期中的电视终端销售表现,以及电视厂商能否在不损害需求的情况下成功将部分上升的供应链成本传导出去,将成为2026年下半年关键的观察指标。 如果零售巨头在5月、6月和7月的促销活动能够有效带动流量并达到预期目标,那么2026年第三季度电视面板需求出现大幅下滑的风险将被消除,尽管仍可能出现一定程度的结构性调整。在该情景下,电视厂商将在2026年第三季度补充更多面板库存,以备2026年第四季度季节性促销需求增长。但该情景的风险在于,2026年下半年消费者需求可能弱于预期。这是因为部分原本计划在2H26发生的电视购买需求,可能已在2026年上半年提前释放。此外,由于供应链成本持续上升,电视平均售价可能维持在相对高位甚至进一步上涨,从而对市场需求造成抑制。与此同时,持续的地缘政治冲突推动能源价格上升,以及顽固的通胀压力,也将对2026年下半年消费者支出形成明显制约。 如果零售巨头在5月、6月和7月的促销活动无法有效带动流量,或电视厂商未能按计划完成库存清理,那么电视厂商将被迫在6月末或2026年第三季度初期削减面板需求,否则将面临销售不及预期与财务亏损加剧的“双重损失”风险。在这种情况下,电视厂商在2026年第三季度与2026年第四季度的补库行为将更为保守。 值得注意的是,尽管电视品牌与OEM厂商正在向零售商报出更高价格,且部分头部品牌已在全球市场上上调2026年新品的标价,但零售商与消费者的关注重点仍集中在促销产品上,而这些主要是2025年的旧机型。这意味着,即使整体ASP有所提升(如有),对终端设备厂商的实际意义有限,因为低价旧机型仍在主导市场流量。因此,2026年新款电视在下半年很可能面临进一步的价格下行压力。 沃尔玛Rollbacks促销将电视价格下调30%–50%,亚马逊Prime Day在2026年由7月提前至6月 沃尔玛并未设定固定的Rollback促销日期,因此相关活动可能全年分散进行。典型的Rollback周期约为90天,但根据库存情况或供应商协议不同,部分促销周期可能更短。 沃尔玛的Rollback是针对特定商品的限时降价活动,其降幅通常高于门店常规低价策略。这些促销商品通常会以“Was/Now”价格标签标示,清晰展示原价与折后价之间的对比。Rollback商品多为日常消费或核心品类,促销结束后通常会恢复原价。沃尔玛通过Rollback促销实现多重目标,包括应对通胀、提升销量、增加门店客流,并强化其“最低价零售商”的市场定位。 如表1所示,沃尔玛在5月开展的Rollback促销活动中已涵盖多款电视产品,且价格显著低于原价。目前部分65英寸及75英寸电视的Rollback价格已接近去年黑色星期五的最低水平,而85英寸及98英寸等大尺寸与超大尺寸电视,不仅具备较大幅度折扣,甚至已与去年黑五的最低价格持平。这些价格策略与电视品牌及OEM厂商的预期相悖,因为电视厂商正迫切希望将持续上升的供应链成本转嫁至全球市场,以减轻财务压力。然而,他们也早已预见到,在激烈市场竞争下,这一目标难以实现。以下为近期电视厂商与零售商之间的商业谈判情况: 2026年3月,美国零售巨头同意电视厂商提出的涨价要求,以反映因内存价格前所未有上涨所带来的供应链成本激增。 电视厂商需提前60至90天向零售商发送涨价通知,随后双方将就涨幅进行进一步谈判。 零售巨头计划在2026年继续维持自有品牌电视的低价策略。 在内存芯片价格上涨的背景下,预计单台电视成本已上涨30%–50%,甚至可能更高。2026年4月,电视厂商正在与零售商协商共同分担内存成本上涨的一半压力。但市场竞争将迫使电视品牌及OEM厂商吸收大部分新增成本,而零售商则可能承担部分成本压力,并将其转嫁给市场,从而推动电视ASP上升。 尽管电视品牌和OEM厂商已向零售商报出更高价格,且部分头部品牌已在全球市场上上调2026年新品的标价,但零售商和消费者的关注重点仍集中在促销机型上,而这些主要是2025年旧款产品。这意味着ASP提升在实际市场层面的作用有限,因为低价旧机型仍在主导市场流量。 表1:沃尔玛2024与2025年黑色星期五最低价格与2026年5月最低价格对比 来源:Walmart.com与BestBuy.com;由Omdia整理。 大屏电视降价幅度更深 在沃尔玛Rollback促销期间,大尺寸及超大尺寸电视的降价幅度更为明显。从电视整机制造成本管理的角度来看,这一现象是可以理解的。内存价格前所未有的上涨,正在对整个供应链形成持续压力。 根据Omdia《Display Dynamics – 2026年2月:电视厂商将如何应对内存价格飙升?》的分析,电视厂商需要通过向更大尺寸和更高端产品结构转移,以更好地管理内存在电视BOM(物料清单)中的成本占比。如图1所示,55英寸UHD谷歌智能电视的主板成本在2Q26将占整机BOM的31%,而去年同期仅为12%。75英寸UHD智能电视的音视频处理主板成本占比将在2Q26提升至20%,较一年前的8%显著上升。对于32英寸HD智能电视,该成本占比将在2026年第二季度升至37%,而2025年同期仅为13%。 就在沃尔玛5月开启Rollback促销之后,亚马逊正式宣布其Prime Day活动将覆盖26个国家,并在2026年6月回归,相较以往传统7月举办时间有所提前。2026年Amazon Prime Day对于电视显示供应链参与者而言至关重要,因为众多全球电视品牌都将参与这一大型促销活动。2025年Prime Day在整体线上销售额方面已显著超过黑色星期五,主要原因在于亚马逊将夏季大促从两天延长至四天(7月8日至11日)。尽管2026年具体日期尚未公布,但预计将落在6月下旬。 图1:电视音视频处理板在BOM中的成本占比(60Hz,Google/Android智能电视,2GB DDR/NAND eMMC 16GB配置,2026年4月更新)
电视
Omdia . 2026-06-03 2 756

Hydrostasis, Inc. 是以人为本的医疗科技可穿戴设备公司,总部位于美国加利福尼亚州,其核心理念就是 “养成良好的水分摄取习惯” ,这对保持健康至关重要。该公司的无线Geca Watch 2.0智能手表提供可操作、可定制的水分摄取信息,从而帮助用户改善安全性、提升运动表现和活得更健康。 Hydrostasis 创始人兼首席执行官Debbie Chen 博士: 我们认为水分摄取是至关重要的生命体征,无论在诊所、药房以及您的智能设备中,都应该像心率和脉搏血氧饱和度监测仪一样普及。我们的目标是为人们提供这些缺失的信息,以便他们保持充足水分,从而延长寿命并活得安康。 她进一步解释说:“老年人是我们特别关注的对象,因为美国每年有1000万老年人因可预防的脱水而住院。由于口渴感会随着年龄增长而减退,因此脱水的风险也会增加,其影响也更加明显,例如跌倒风险增加、肾脏健康受损和脑退化加速。” Chen补充说,虽然他们的主要客户群体是40岁以上有特殊补水需求的成年人,但Hydrostasis的产品和服务也获得了精英运动员、忙碌专业人士、旅行爱好者、建筑工人和残疾人士的青睐。 Geca Watch (2.0) 面世 Chen解释道:“我们虽然拥有丰富的营养知识,却不知道应该喝多少水,以及何时喝水。” Chen和她的团队投入了七年时间研发GECA Watch,并于 2024 年推出。第二年推出了 GECA Watch 2.0,该手表采用了 Nordic nRF5340一体化双核低功耗蓝牙系统级芯片 (SoC)。 GECA Watch是一款实时、个性化的可穿戴水分摄取监测器。它是率先采用光学传感器检测皮肤水分含量的腕戴式设备,能够在出现头痛、疲劳或思维迟钝等脱水症状之前发出饮水提醒,也是巿场上独一无二的同类型商业产品。完成用户校准后,它可提供实时提醒和移动端进度追踪功能。 为什么选择Nordic Chen解释道:“Nordic是我们的首选。” 第一代 GECA Watch采用了 Nordic 公司的 nRF52832 系统级芯片,这是一款支持低功耗蓝牙的通用多协议 SoC。 据她所说,当时该公司需要一个具有充足内存、强大处理能力和硬件级安全性的组件来保护其知识产权。 GECA Watch 2.0在这方面的要求并没有改变。Chen表示该产品需要升级的微控制器单元 (MCU) ,具体需要的功能包括大容量内存、强大的计算能力,以及通过硬件安全功能隔离和保护知识产权的能力。 为此,他们选择了 Nordic 的 nRF5340。这款芯片被誉为“全球首款搭载两个 Arm® Cortex®-M33 处理器的无线 SoC”,它提供了 GECA Watch 2.0 所需的庞大内存容量、强大计算性能和硬件级安全性。此外,它还支持包括低功耗蓝牙在内的多种无线协议。 nRF5340是一款双核 SoC,它配备了一个采用 128/64 MHz Arm Cortex-M33 应用处理器的应用核心,具有 1 MB 闪存和 512 KB RAM;它还有一个网络核心,采用 64 MHz Arm Cortex-M33 网络处理器,具有 256 KB 闪存和 64 KB RAM。 得益于双核规格,网络核心可以独立处理无线协议,而应用核心则负责管理用户逻辑。这种分离设计有助于保持SoC的超低功耗和高效的协议处理能力,因此成为了GECA Watch 2.0的理想之选。 nRF5340 SoC 还通过硬件强制执行的安全功能提供高级安全性,包括用于安全/非安全执行分离的 Arm TrustZone、通过 AP-Protect 实现的读取保护,以及用于安全密钥存储和加密保护的 CryptoCell 312 子系统。这些功能确保敏感代码和专有模型可以在受保护的内存区域中运行,从而显着降低代码被提取或逆向工程的风险。 这些特性使得 nRF5340 不仅具有充足性能以满足可穿戴设备的实时水份摄取监测需求,而且还为保护 Hydrostasis 的核心知识产权提供了安全基础。 另一个卖点是易于升级。Chen指出,“我们熟悉了其生态系统,以及出色的代码重用性,因此顺理成章地以nRF5340替代nRF52832。” 展望未来 Hydrostasis在质量保证和精简迭代方面不断进步,它将继续采用Nordic的SoC芯片并受益于其强大优势。 Chen兴奋地说:“我们与 Nordic 合作愉快。我们一开始只是Nordic的支持者和客户,但到了如今,我们的产品在2026年展会的Nordic展位上获得重点展示;我们很高兴继续与 Nordic 团队合作,日后共同开发新功能和产品。”
Nordic
Nordic半导体 . 2026-06-03 497

北京时间2026年6月1日16时40分,由中国航天科技集团商业火箭有限公司抓总研制的首型火箭——长征十二号乙运载火箭遥一箭,在东风商业航天创新试验区中国商火研试发射工位点火升空,首飞任务取得圆满成功。作为运载火箭的“中枢大脑”,本箭核心控制系统搭载的龙芯高可靠处理器,凭借优异的产品性能与极强的严苛环境适应性,稳稳扛起火箭智能控制核心重任,在复杂飞行工况下稳定输出算力,为构建自主可控的商业航天产业生态注入硬核动能。这也是龙芯处理器首次应用在长征系列运载火箭核心控制系统。 运载火箭核心控制系统贯穿火箭起飞、爬升、轨道修正、精准入轨的全飞行周期,是保障任务全程精准可控的核心枢纽。火箭在轨高速飞行过程中,需持续面临高空温差剧变、复杂气流扰动、强电磁干扰等极端环境,对控制系统的实时运算速度、运行稳定性和抗干扰能力提出了极高要求。而处理器作为控制系统的核心算力载体,更是决定发射任务成败的关键部件。此次长征十二号乙采用龙芯处理器,自主重构核心交互逻辑与调度算法,成功打通底层协议栈与上层应用间的“任督二脉”,充分验证了龙芯处理器领先的技术架构、卓越的环境适应能力和运行高可靠性,切实证明其完全满足商业运载火箭常态化组网发射的严苛标准,彰显国产航天核心算力硬件的硬核实力。 不止于核心硬件的技术突破,长征十二号乙的问世,更是中国商业航天产业迭代升级的标志性飞跃。20吨级超大运力、全液氧煤油低成本方案、可重复使用预留设计、21个月极速研制……作为我国运力最大的单芯级火箭,长征十二号乙从诞生起就为“大运力、低成本、高密度”商业需求量身定制,每一项参数都直击行业痛点,从资源、产业、技术、竞争四大维度,定义商业火箭价值新坐标,为千帆星座等万颗级组网按下“加速键”,更让中国商业航天从“追赶者”一跃成为“规则制定者”,标志着中国商火的火箭经济性设计理念正式迈入工程实践的新阶段。 当前,长征十二号乙运载火箭聚焦以高密度发射快速提升我国进入空间能力,支撑大规模互联网星座组网。未来,随着该型号规模化量产,发射服务将更高效、更经济、更灵活,更多卫星将以更快速度、更低成本进入轨道。立足全新起点,龙芯中科将不断突破关键技术,持续夯实国产商业航天自主可控技术根基,为我国商业航天产业化、规模化发展提供坚实技术支撑。
龙芯中科
龙芯中科 . 2026-06-03 581

2026年6月2日至5日,江波龙携全栈端侧AI存储新品及综合应用方案,亮相台北国际电脑展(COMPUTEX 2026)。本次展会以“AI Together”为主题,聚焦AI与计算、下一代技术等核心方向,江波龙围绕“端侧AI存储·综合应用”,集中展示AI内存新品、全链路技术方案及多场景组合应用,依托旗下Lexar雷克沙全球化品牌优势,全方位呈现端侧AI存储领域的创新成果,助力端侧AI本地模型体验优化,推动行业生态协同发展。 AIDIMM™&AILPBGA™两大AI内存新品首发,精准适配端侧AI推理应用 此次展会,江波龙重点推出两款为端侧AI推理打造的专用内存产品,精准匹配AI模型在各类场景下的部署需求。 AIDIMM™:单条稳定承载70B+端侧AI大模型 AIDIMM™作为针对AI计算深度优化的内存,凭借最高128GB容量、256bit位宽、307.2GB/s单通道超高带宽及紧凑体积,有效解决当前智能体主机普遍存在的内存容量不足、算力任务卡顿、散热困难、升级不便等核心难题。该产品采用4颗LPDDR5x同面布局设计,布线简洁,搭载的高速率、高密度、高针脚数连接器可适配主流智能体主机的主板架构,无需对现有硬件进行大幅改造,从而降低客户硬件升级成本。 在AI智能体高频运算、大模型实时推理、多场景同步交互的高强度工况下,AIDIMM™的高速带宽能够快速响应算力调度需求,大幅降低数据传输延迟,有助于缓解算力空转、任务卡顿、模型响应滞后等问题,单条即可稳定支撑70B+级端侧大模型流畅运行。 同时,AIDIMM™搭配高效散热结构,在智能体主机高密度部署场景下可精准控温、避免性能降频,兼具高性能与运行稳定性。产品支持0.9V-1.05V动态调压,搭载FDVFS智能能效优化机制,可针对端侧AI推理、大模型运行等不同负载场景,智能调节电压与运行状态,实现AI负载下精细化动态功耗管理,有效提升端侧AI整体场景能效比,大幅降低整机运行发热,AI PC、智能体主机提供高性能、低功耗、易升级的AI内存解决方案,充分释放终端AI算力,让设备长期批量部署更省电、更稳定。 AILPBGA™:兼容LPDDR接口的高带宽内存芯片 AILPBGA™则聚焦对紧凑体积有要求的嵌入式AI推理场景,同时具备“高效益、高适配、低功耗”的核心优势。产品采用自研技术标准与创新架构,单颗原生256bit位宽设计,带宽可达307GB/s,容量覆盖24GB~64GB,全面适配 LPDDR 标准接口;同时采用22×22mm的BGA1764紧凑封装设计,体积小巧、集成度高,可灵活适配AI推理、中轻量模型部署等紧凑型终端。 对比云端AI高带宽内存,AILPBGA™优先平衡成本与功耗表现,能以更高的效益比满足端侧AI推理需求,助力客户降本增效;对比标准LPDDR5x,其位宽、性能、容量均高出数倍,且兼容现有LPDDR平台,布线简单便捷,无需重构SoC和系统架构,大幅缩短终端研发与落地周期,有助于降低适配成本。 AILPBGA™采用低功耗设计,不仅可大幅削减设备能耗,有效延长AI推理终端、边缘大模型设备续航时长;还能显著降低整机发热量,精简散热结构设计,贴合紧凑型设备空间布局需求,同时提升设备长期运行稳定性,规避高温引发的运行故障。随着AI应用全面普及,其低功耗特性能实现高效节能,从而帮助用户有效缩减整体用电运维成本。 软硬件存储技术布局,构筑端侧AI存算综合应用 在技术应用层面,江波龙展示了从芯片硬件到软件智能的存储方案,全方位优化端侧AI本地模型运行体验。 SPU™ + iSA™存储智能体应用 在智能体端侧AI应用场景,HLCache™技术深度集成于SPU™存储处理单元之中,可有效降低终端DRAM占用与硬件成本。而作为SPU™大脑的iSA™存储智能体,用于端侧AI推理的专业调度引擎,针对MoE大模型参数量大、KV Cache膨胀快、I/O延迟影响推理效率等痛点,利用专家卸载、缓存智能管理及智能预取算法,高效解决端侧大模型运行的存储调度难题,全面提升本地AI推理流畅度。依托这套优化方案,现场基于AMD锐龙AI Max+ 395处理器的智能体主机完成实机演示:128GB内存可实现397B超大参数AI模型本地部署,64GB内存便能流畅运行122B及80B等中大型模型,同时优化长上下文使用体验,有效缓解端侧AI高内存使用问题,大幅提升端侧AI运行效率与使用经济性。 UFS + HLCache™技术应用 在移动端侧AI应用领域,江波龙推出搭载HLCache™技术的UFS产品,可大幅提升DRAM调度效率,结合不同DRAM容量手机的对比演示,清晰验证其对移动端侧AI交互效率的提升效果,让移动终端也能流畅运行13B、20B轻量级AI模型。该方案以更低规格内存即可实现大内存级别的流畅运行体验,有效缩减终端对DRAM的使用。在保障设备流畅运行、延长硬件使用寿命的同时,有效优化终端整机BOM综合成本。 未来,智能体端侧AI存储 SPU™+iSA™+AIDIMM™、移动端侧AI存储 UFS+HLCache™+AILPBGA™ 两大组合,有望实现“存 - 算 - 加速” 一体化协同,更好地适配端侧复杂本地大模型的加载、推理与运行需求。 mSSD高速存储介质,散热集成存储应用 本次展会现场展出Gen4、Gen5全系列mSSD高速存储介质并开展实机性能实测。全系mSSD采用晶圆级SiP系统级封装,将主控、NAND、电源管理芯片高度集成一体,具备芯片级可靠品质,体积紧凑且形态拓展性灵活,可衍生M.2 SSD、PSSD、AI存储卡等多款产品,适配多元终端设计需求。 其中PCIe Gen5 mSSD的20×30mm小尺寸,原生兼容 M.2 2230 规格,现场同步展示了M.2 2280散热拓展卡与整体散热结构。产品搭载高性能主控,顺序读写峰值达 11GB/s、10GB/s,4K 随机读写最高 2200K、1800K IOPS,单盘最大支持 8TB 大容量,精准匹配AI PC高速吞吐与大模型存储需求。散热材料工程方面,产品配备专属VC相变液冷散热方案,搭配多层导热结构,大幅延长峰值性能持续输出时长,充分适配AI PC KV Cache高负载运行场景,在极致高速读写的同时,兼顾设备轻薄化设计,实现高性能、低温升、高稳定表现。 在Gen5迭代的同时,江波龙成熟的PCIe Gen4 mSSD已实现商用落地。目前产品已与多个PC主机厂商达成合作,广泛搭载于多款AI PC、轻薄本设备,凭借稳定的性能与可靠性,获得市场与行业的广泛认可。 全球化布局赋能,品牌助力应用普及 基于mSSD高速存储介质衍生的AI Storage Core技术架构,Lexar雷克沙在此次展会上重点推出了新一代AI-Grade Gen5专业存储产品,通过搭载Lexar AI Storage Solution,显著提升端侧AI应用的运行效率,并有效降低终端对DRAM容量的需求,广泛适配AI PC、智能影像及智能机器人等前沿应用场景。 正值雷克沙品牌30周年之际,世界杯开幕在即,阿根廷国家队联名产品也备受关注,品牌携手阿根廷国家队推出联名系列PSSD和USB,并带来大容量SSD、PSSD、存储卡等全产品线,进一步丰富消费存储布局。 在全球化布局方面,江波龙依托旗下国际高端消费存储品牌Lexar雷克沙,持续扩大端侧AI存储技术的全球影响力。作为诞生于1996年的国际知名品牌,雷克沙具备全品类产品布局与遍布六大洲的全球化渠道,已进驻Costco、BestBuy等全球头部零售渠道及主流电商平台。此次展会推出的部分端侧AI存储核心技术与产品,未来将通过雷克沙的全球化渠道优势同步辐射全球市场,为全球AI内容创作、边缘推理、移动计算等场景提供高性能、高可靠性的存储解决方案。 江波龙将持续深耕端侧AI存储领域,凭借全链路存储Foundry能力持续迭代产品与解决方案,优化本地大模型运行体验,以多元化场景落地实践,打造兼具实用性与行业参考性的成熟端侧AI存储应用方案。 *上述产品数据均来源于江波龙内部测试 实际性能因设备差异,可能有所不同
江波龙
江波龙 . 2026-06-03 567

中国台北,6 月 2 日,2026 – 全球边缘计算与边缘AI平台厂商研华科技昨(1)日于华南银行国际会议中心举办“Edge AI Conference”国际论坛,汇聚产业领袖、技术专家及生态合作伙伴,并通过全球同步直播,吸引超过3000名行业人士线上线下参与。研华刘克振董事长亲临论坛并号召包括 NVIDIA、高通技术公司(Qualcomm Technologies, Inc.)、Intel 等全球 AI 生态伙伴,聚焦边缘计算与 Physical AI 的最新发展,揭示边缘 AI 规模化应用的时代正式来临。 研华董事长刘克振于「Edge Computing & AI-Powered WISE Solutions」主题演说中表示:「 AI正从云端走向边缘,并逐步从技术热点演变为企业运营核心,成为推动千行百业数字转型的重要关键。」刘董事长进一步指出,研华也从硬件和技术供应商转型为产业赋能者,并透过WEDA(WISE-Edge Developer Architecture)平台化架构、生态系整合与软硬件协同能力,协助企业将AI升级为驱动运营与决策的核心。 Physical AI崛起 以WEDA打造边缘AI关键架构 随着边缘 AI 日趋成熟, AI已从以云端模型训练和生成式AI为主的发展阶段,进一步演进至具备感知、推理与行动能力的物理 AI(Physical AI),让 AI 真正能实时参与产业决策与自主运作。研华嵌入式事业群总经理张家豪表示,“研华目前已积极布局智能制造、医疗、零售、能源、半导体、AMR、自主机器人及人形机器人等应用领域,并进一步推出面向物理 AI机器人的核心架构与关键模块,整合边缘计算、多感测融合 (Multi-sensor fusion) 到机器人软件开发工具包 Robotic Suite,加速跨产业机器人应用的快速部署。此外亦携手 NVIDIA、Qualcomm、Intel、AMD、NXP 等伙伴共同推出新一代平台方案,并透过研华 WEDA 开发者架构,提供兼具跨平台兼容性与 AI Agent 加速开发能力的整合解决方案,加速推动各产业场域的实际落地与规模化发展。” 全球科技巨擘云集 共探Physical AI与边缘计算未来潜能 本次论坛包括 NVIDIA、高通技术公司、Intel 等全球AI生态伙伴高层皆亲临现场。 NVIDIA 机器人与边缘计算副总裁 Deepu Talla 于演说中指出, NVIDIA 以三计算机框架为技术底座,结合 NVIDIA Omniverse、 Isaac Sim、Metropolis与 NemoClaw,构建从训练、仿真到部署的完整闭环。以「AI Factory Brain」为主题,Talla进一步说明管理型 AI Agent 如何于视觉检测、SOP 管理及工厂运营等场景中,提供更高层次的智慧决策与协同管理能力,全面提升工厂运营效率。同时以研华工厂转型蓝图作范例,为 Physical AI 的未来提供有力验证。 高通技术公司执行副总裁暨汽车、产业、嵌入式物联网与机器人事业群总经理Nakul Duggal表示,边缘计算与无线技术将驱动工业与Physical AI大规模发展,透过 Qualcomm Dragonwing™高效能工业处理器、5G与Wi-Fi 8等联网技术,可将智慧方案直接部署于边缘端,支持低延迟、实时决策与自主运作。高通技术公司与研华将持续深化合作关系,推动机器人创新发展,进一步释放Physical AI的产业价值。 Intel 边缘计算事业群企业副总裁暨总经理 Dan Rodriguez 则分享 Intel 与研华如何通过开放式生态系、原生边缘 AI 架构,以及机器人 AI 平台,推动可复制、可规模化的AI创新,加速 AI 技术于各产业中的实际落地应用。 深化产业应用 聚焦Physical AI工业落地的四大核心 研华智能系统事业群总经理暨运营长蔡淑妍携手 NVIDIA 与 Omron 于论坛中,聚焦 Physical AI 工业落地的四大核心议题,指出 AI平台能力实现跨越式提升已让 Physical AI 从概念走向现实,然而 OT融合与规模化部署仍是产业落地的关键挑战;研华进一步以 NVIDIA 三计算机框架,建立涵盖AI训练、仿真与部署的完整闭环工作流,大幅提升部署效率。而面对工业现场高度碎片化所带来的规模化难题,研华则推出“AI Foundry”七大标准化模块,协助企业快速从 POC 迈向量产部署。展望未来,“AI Factory Brain”将通过 AI Agent 驱动工厂从传统自动化,演进为具备持续学习能力的自适应智能系统。运营长蔡淑妍特别强调,“Physical AI不再只是能否实现的问题,而是我们能以多快的速度规模化。” 论坛最后还深入探讨制造业与智慧城市的边缘 AI 演进,通过实际AI应用案例分享、数字孪生与边缘计算如何协助企业提升生产效率、质量稳定性与运营韧性,加速迈向开放、智慧且可扩展的自主智能制造;同时亦从智慧医院与连锁零售等应用场景切入,解析 AI 于不同产业中的关键落地模式。 欢迎莅临参观研华位于COMPUTEX 2026南港展览馆一馆(K0603a)展位。
研华
研华 . 2026-06-03 504

全球边缘计算与边缘AI平台厂商研华科技宣布深化与 NVIDIA 的合作,正式推出 AI 原生工厂架构(AI-Native Factory Architecture)迎向 Agentic AI 与 Physical AI 时代的来临。 AI 原生工厂架构结合 NVIDIA NemoClaw、NVIDIA Factory Operations Blueprint、NVIDIA RTX PRO、NVIDIA Jetson Thor,以及研华 WISE-Edge Developer Architecture(WEDA),协助制造业者将人工智能深度导入实时工厂运营流程,以适应柔性生产、人力优化与能源效率等关键需求。 研华嵌入式事业群总经理张家豪(左) 与NVIDIA 机器人与边缘计算副总裁 Deepu Talla (右)于研华Edge AI论坛中宣布,双方将深化合作推出「AI Factory Brain」 研华嵌入式事业群总经理张家豪表示:“研华与 NVIDIA 此次的进一步合作,是AI驱动智慧工厂发展的重要里程碑。通过整合NVIDIA AI工厂大脑,以及研华基于NVIDIA NemoClaw 与全栈式边缘 AI 计算平台所打造的Edge AI与WEDA生态系,我们正以智能体驱动AI(Agent-driven AI)、软件定义编排(Software-defined Orchestration)与自主化运营(Autonomous Operations),实现全厂级智慧化,并为新一代 Physical AI 智能制造建立可复制、可验证的最佳实践蓝图。” 结合 NVIDIA Factory Operations Blueprint (FOX) 打造 AI Factory Brain多智能体系统 研华此次推出的 AI Factory Brain,是一套以工厂管理为核心的多智能体系统,并基于 NVIDIA Factory Operations Blueprint(FOX)打造,可作为工厂运营的中央智能决策中枢,主动监测异常事件、分析潜在根因,并调度各类 AI Agent 与现场人员协同处理问题。该架构建构于 NVIDIA 加速计算平台之上,结合研华基于 NVIDIA MGX 架构打造的 SKYRack AI 系统,搭载 NVIDIA RTX PRO 6000 Blackwell 服务器显卡 与 Spectrum-X 网络技术,并串联采用 NVIDIA IGX Thor、NVIDIA Jetson Thor 与 NVIDIA Jetson Orin 的 MIC 与 ICAM 边缘计算设备,打造从云端到边缘的全方位 AI Factory Brain。 通过实时整合企业 SAP、MES、WMS 等系统数据与边缘感测数据,Factory Manager Agent 可统筹工厂内各领域 AI Agent 协同运作,并结合 NVIDIA NemoClaw、NVIDIA Omniverse、NVIDIA Metropolis 与 NVIDIA Isaac Sim,可实现流程自动化、能源精细化管控,进一步提升设备综合效率(OEE)、产品良率及平均修复时间(MTTR)等关键运营指标。 Edge Agentic AI 实现实时推论 强化瑕疵检测与制程优化 研华 ICAM-540 工业相机与 MIC-743-AT 平台,分别搭载 NVIDIA Jetson Orin NX 与 NVIDIA Jetson Thor,可支持 AI 驱动的自动光学检测(Automated Optical Inspection),以及地端 LLM/VLM Chatbot 部署,提升瑕疵检测能力、生产效率与工厂智能运营,并通过自然语言互动强化操作体验。 Physical AI 串联双轨应用 推动智能物流与仓储自动化 研华 AIR-427A 平台(搭载 NVIDIA IGX Thor)与 AFE-A702 平台(搭载 NVIDIA Jetson Thor),可为叉车、人形机器人、AMR 与 MMR 提供高效能 AI 算力,支持自主导航、机器人作业、智能搬运与动态产线调度等应用。通过 AI Agent 理解工作流程情境,系统可实时调整生产优先级,并协助现场操作人员进行决策与作业优化。 提供企业级治理与功能安全机制 确保系统稳定可靠 透过 NVIDIA NemoClaw(包括 NVIDIA OpenShell 安全执行环境与 Policy Frameworks),该架构可提供企业级资安防护、权限管理与运营治理能力。此外,搭载 NVIDIA IGX Thor 的 MIC-735-IT 与 AIR-427A 平台,亦支持符合 Functional Safety(FuSa)需求的 AI 计算架构,可应用于人形机器人与自主工业系统,协助提升运营稳定性与作业安全。 研华自有工厂验证 AI Agent 应用成效 目前研华已于自身制造场域中,完成两项基于 NVIDIA NemoClaw 的 AI Agent 验证项目。其中,能效管理智能体(iEnergy Agent) 可通过交叉比对生产排程、实时 Vision AI 画面与 SCADA 系统数据,自主调控暖通、照明设备,全面部署后预计厂区整体能耗可降低10%。另一项 产线效率智能体(Production Line Efficiency Agent),则透过 Vision AI 实时搜集产线数据,分析生产效率、侦测异常与瓶颈,并自动生成改善建议与班次报告。自导入六个月以来,已成功提升产线生产效率达 12%。 展望未来,研华将持续深化与NVIDIA的长期战略合作,扩展 Edge AI 与加速计算产品布局,协助企业加速导入智能制造、AOI检测、工业机器人、智慧仓储、自主物流与数字孪生等 AI 应用,推动全球制造产业迈向高效、智慧且永续的新一代工厂模式。
研华
研华 . 2026-06-03 448

在人工智能的大力推动下,MLCC似乎也进入了涨价轨道。 近日,被动元件大厂华新科向代理商发出涨价通知,自6月1日开始调涨芯片电阻及部分MLCC产品价格,主要因多项原物料价格持续上涨, 华新科在涨价通知中表示,国际局势不稳与市场波动,使金属、石化及多项原物料成本持续上涨,内部承受成本压力,随着新应用市场持续发展,产能需求提升,经审慎评估,针对电阻及部分MLCC进行价格调整。 由于村田、三星电机在高容MLCC供需缺口扩大下,平均稼动率奔满载,均已达90%以上,业界认为,国巨、华新科是产能排挤、外溢订单受惠第一排,继国巨大中华区产能重镇-苏州厂满载之下,华新科MLCC稼动率也直奔90%。华新科MLCC产能排名约当全球第五,此次作为中国台湾MLCC首个涨价的厂商,后续或有其他企业跟进。 华新科曾在股东会强调,AI用的特殊品毛利高,产值倍数型跳升,电阻、电容因应AI需求,走向耐高温、耐高压,市调机构预测AI服务器在2026年可望大幅成长36.9%,被动元件厂(MLCC厂)的切入契机主要在运算、通讯与电源三方面,随着GPU/CPU指令周期、功耗提升,AI用电容与电阻需求提升二倍。 华新科指出,在运算、通讯及电源模块规格升级,带动被动元件用量大幅增加,使AI服务器所需被动元件颗数增加约2倍,不仅在用量上增加,也因产品规格较大颗,故相对消耗产能。而因需求增长,公司持续推动扩产计划,每年资本支出约5亿至10亿元新台币,今年底产能较去年底预计增加约10%,以支持AI、车用及通讯等高阶应用市场成长。 有机构表示,MLCC在服务器、光模块有广泛应用,受益服务器功率提升、垂直供电、800V等升级有望迎量价齐升机遇。当前受益AI需求景气,MLCC行业正进入新一轮涨价、景气上行周期,我们看好本土厂商乘风发展并顺势加速服务器、车规等高规格产品突破。 高盛分析师认为,多层陶瓷电容器(MLCC)或将是AI产业链的“下一个供给瓶颈”,正如2025年底当市场关注点集中在AI超级周期部署中的特定瓶颈时,内存价格出现暴涨一样;如今,受AI服务器带来的巨大需求机遇推动——高盛预计其需求量将从2025财年至2030财年增长约4.3倍,整个MLCC行业正日益感受到供需紧张的态势。 值得注意的是,智能手机和PC等传统消费电子客户在传统终端出货承压、供应短缺的背景下,传言近期也开始反常地积极寻求签订MLCC“长协合同”。其深层逻辑在于,随着MLCC全行业的核心产能被优先倾斜和挪调至利润率更高的AI服务器供应链,那些缺乏高优先级溢价能力的传统长尾客户,对于未来自身元器件的备货采购已产生强烈的断供焦虑。 免责声明:文 章综合网络,仅供参考交流,封面图片/配图来源网络,不构成任何投资/采购等建议,投资者据此操作风险自担。
MLCC
半导体前线 . 2026-06-03 1 833

EliteSiC技术赋能蔚来最新电动车平台更快充电、更长续航与更强整车性能 摘要 安森美(onsemi)进一步深化与蔚来(NIO)的长期战略合作,助力蔚来加速向下一代900V高压电动汽车平台转型。双方的合作基于安森美EliteSiC技术,以提升蔚来最新电动汽车系列的能效、性能与可扩展性,其中部分车型于2026年北京国际车展首次亮相。 新闻要点 EliteSiC技术已应用于蔚来900V高压平台车型,包括旗舰车型 双方在多年合作基础上,进一步深化工程与系统级协同 蔚来多款搭载安森美技术的车型亮相2026北京国际车展 安森美宣布,与蔚来汽车进一步扩大战略合作,共同推进下一代电动汽车(EV)平台发展。基于多年合作,双方将更紧密协同,安森美提供最新的EliteSiC M3e技术,加速蔚来从400V向900V架构的演进。 带来续航、充电与性能方面的实质提升 安森美EliteSiC增强型M3e技术通过优化体二极管特性,显著提升开关性能,在降低损耗(Eon)的同时,保持出色的短路鲁棒性。这些技术进步带来了更高的系统输出能力、更佳的热管理表现以及整车电驱系统能效的全面提升,对于驾驶者而言,这意味着: 更长续航里程,这得益于动力系统中热损耗的降低 加速更强劲、更平顺,即使在高速及高负载工况下依然保持稳定加速性能 更短充电时间,由高电压快充系统提供支持 长期可靠性:面向严苛工况设计的电源系统 合作持续深化,从400V迈向下一代平台 此次合作的进一步拓展,建立在双方多年的合作基础之上。双方的合作始于安森美EliteSiC技术应用于蔚来400V平台,如今已升级为系统级战略协同。安森美EliteSiC技术正成为蔚来向900V高压平台转型的关键支撑,其中包括在2026北京国际车展亮相的最新旗舰SUV ES9以及其他多款新车型。 高管观点:战略合作与行业风向 安森美总裁兼首席执行官Hassane El‑Khoury表示:“电气化正步入一个全新阶段,在这个阶段,系统能效和可扩展性至关重要。我们与蔚来不断深化的合作,充分体现了深度的工程协同与一致的技术路线如何加速向高压架构转型。凭借EliteSiC技术,我们正助力下一代电动汽车平台实现更高性能和能效,并加快产品落地进程。” 蔚来驱动科技XPT首席执行官曾澍湘(Alan Zeng)表示:“蔚来始终致力于拓展智能电动出行的边界。我们与安森美的合作,伴随技术路线不断演进——从早期的400V系统到如今的900V平台。安森美EliteSiC技术在性能与可靠性上的优势,加之双方紧密的技术协同,正助力我们向全球用户提供更高效、更高性能的电动车。” 规模化部署下一代电动汽车技术 双方的合作也反映了汽车产业的重要趋势:随着电动汽车系统功率水平持续提升,汽车制造商与半导体企业正在形成更加紧密的协同关系。通过支持系统级集成,安森美正助力客户更快速、更高效地将高性能、可扩展的电动汽车平台推向市场,同时降低开发复杂度并加速落地执行。随着汽车制造商向更高电压架构与先进电驱系统转型,这种合作模式正变得愈发重要。
安森美 . 2026-06-03 546