
BUZ11-NR4941与VBM1638参数对比报告
N沟道功率MOSFET参数对比分析报告 一、产品概述 BUZ11-NR4941:安森美(onsemi)N沟道增强型硅栅功率MOSFET,耐压50V,最大电流30A,导通电阻低至40 mΩ。采用TO-220AB封装。设计用于开关稳压器、开关变换器、电机驱动、继电器驱动以及需要高速和低栅极驱动功率的高功率双极开关晶体管驱动等应用。可直接由集成电路驱动。 VBM1638:VBsemi N沟道60V逻辑电平功率MOSFET,采用先进技术实现极低的导通电阻(10V驱动下典型值0.024Ω),最大连续电流50A。封装为TO-220AB。具备快速开关、动态dV/dt额定值、符合RoHS及无卤素特性。适用于高效率DC-DC转换、电机控制、功率开关等应用。 二、绝对最大额定值对比 参数 符号 BUZ11-NR4941 VBM1638 单位 漏-源电压 VDSS 50 60 V 栅-源电压 VGSS ±20 ±20 V 连续漏极电流 (Tc=25°C) ID 30 50 A 脉冲漏极电流 IDM 120 200 A 最大功率耗散 (Tc=25°C) PD 75 150 W 结温/存储温度范围 TJ, Tstg -55 ~ +150 -55 ~ +175 °C 雪崩能量(单脉冲) EAS 未提供 400 mJ 线性降额因子 —— 0.6 1.0 W/°C 分析:VBM1638 在多项绝对最大额定值上具有优势,包括更高的耐压(60V vs 50V)、显著更高的连续与脉冲电流能力(50A/200A vs 30A/120A)以及更高的功率耗散(150W vs 75W)。其最高结温也更高(175°C vs 150°C),提供了更大的工作温度裕量。此外,VBM1638 明确了雪崩能量能力,在感性负载关断时更可靠。 三、电特性参数对比 3.1 导通特性 参数 符号 BUZ11-NR4941 VBM1638 单位 漏-源击穿电压 V(BR)DSS 50 (最小) 60 (最小) V 栅极阈值电压 VGS(th) 2.1 ~ 4 (ID=1mA) 1.0 ~ 2.5 (ID=250µA) V 导通电阻 (VGS=10V) RDS(on) 0.03典型/0.04最大 @15A 0.024典型 @21A Ω 导通电阻 (VGS=4.5V) RDS(on) 未提供 0.028典型 @15A Ω 正向跨导 gfs 4 ~ 8 @15A 23典型 @21A S 分析:VBM1638 的导通电阻在相近测试条件下显著低于 BUZ11(0.024Ω vs 0.03Ω),意味着其导通损耗更低。同时,VBM1638 是逻辑电平驱动器件(VGS(th) ≤ 2.5V),而 BUZ11 需要标准驱动电压,这使得 VBM1638 在由低压逻辑电路(如MCU、DSP)直接驱动时更具优势,可简化驱动电路设计。 3.2 动态特性 参数 符号 BUZ11-NR4941 VBM1638 单位 输入电容 Ciss 1500典型 190典型 pF 输出电容 Coss 750典型 170典型 pF 反向传输电容 Crss 250典型 40典型 pF 总栅极电荷 Qg 未提供 66最大 nC 栅-源电荷 Qgs 未提供 12最大 nC 栅-漏(米勒)电荷 Qgd 未提供 43最大 nC 分析:VBM1638 的动态电容(Ciss, Coss, Crss)远低于 BUZ11,尤其是反向传输电容 Crss(40pF vs 250pF),这通常预示着其具有更低的米勒效应和更优的开关性能,有利于在高频应用中降低开关损耗和提升效率。BUZ11 的数据手册未提供具体的栅极电荷参数。 3.3 开关时间 参数 符号 BUZ11-NR4941 VBM1638 单位 开通延迟时间 td(on) 30典型 17典型 ns 上升时间 tr 70典型 230典型 ns 关断延迟时间 td(off) 180典型 2典型 ns 下降时间 tf 130典型 110典型 ns 分析:开关速度表现各有侧重。VBM1638 在开通延迟和关断延迟时间上显著更快,这对于提升占空比控制精度和减少死区时间有益。其下降时间也略快。然而,其上升时间较长,可能与测试电路条件(如驱动电阻、电流等级)不同有关。BUZ11 的开关时间参数均为最大值,而VBM1638提供的是典型值,直接对比需谨慎。 四、体二极管特性 参数 符号 BUZ11-NR4941 VBM1638 单位 二极管正向压降 VSD 1.7典型 @60A 未提供 @51A V 反向恢复时间 trr 200典型 130典型 ns 反向恢复电荷 Qrr 0.25典型 0.84典型 μC 连续二极管电流 IS 30 50 A 分析:两款器件都集成了体二极管。VBM1638 的体二极管反向恢复时间更短(130ns vs 200ns),有利于降低在同步整流等应用中的反向恢复损耗。但其典型反向恢复电荷值较高。VBM1638 体二极管的连续电流额定值与漏极电流相同,均为50A,而BUZ11为30A。 五、热特性 参数 符号 BUZ11-NR4941 VBM1638 单位 结-壳热阻 RθJC ≤1.67 ≤1.0 °C/W 结-环境热阻 RθJA ≤75 ≤62 °C/W 分析:VBM1638 的热阻性能更优,尤其是结-壳热阻(≤1.0°C/W vs ≤1.67°C/W)。这意味着在相同的功耗和散热条件下,VBM1638 的结温升会更低,有利于提高可靠性或允许通过更大电流。其结-环境热阻也更低,在无额外散热器或有限散热条件下表现可能更好。 六、总结与选型建议 BUZ11-NR4941 优势 VBM1638 优势 ◆ 栅极阈值电压范围更宽,线性转移特性可能更易控制(如线性区应用) ◆ 反向传输电容Crss的典型值有具体数据 ◆ 产品历史久远,应用案例丰富 ◆ 更高的电压与电流等级(60V/50A vs 50V/30A) ◆ 显著更低的导通电阻,导通损耗更小 ◆ 逻辑电平驱动,可与低压控制器直接连接 ◆ 更优的动态电容,开关性能潜力大 ◆ 更低的热阻,热管理能力更强 ◆ 更高的最大结温(175°C) ◆ 明确的雪崩能量评级,鲁棒性更佳 ◆ 符合现代环保法规(无卤素,RoHS) 选型建议 选择 BUZ11-NR4941:当应用于传统的、对成本敏感的中低功率开关场景,且驱动电压为标准10-15V,对逻辑电平驱动无特殊要求时。其经久考验的可靠性也是一个考虑因素。 选择 VBM1638:当设计追求高效率、高功率密度时,其低RDS(on)可减少导通损耗。当系统由3.3V或5V逻辑电路直接驱动时,其逻辑电平特性是关键优势。在高频开关应用(如DC-DC转换器)中,其低电容特性有助于提升效率。此外,对于需要更高电流能力、更强散热性能或更优瞬态耐受能力(雪崩)的新设计,VBM1638是性能更全面的选择。 备注:本报告基于 BUZ11-NR4941(onsemi)和 VBM1638(VBsemi)官方数据手册生成。所有参数值均来源于原厂数据手册,设计选型请以官方最新文档为准。请注意,部分参数的测试条件可能存在差异,进行精确对比时需仔细核对。
微碧
微碧半导体 . 2026-06-02 735

东芝开始提供面向电机驱动、内置MOSFET的新款SmartMCD™系列IC样品
-集成3相直流无刷电机驱动电路与微控制器,实现小型车载电机的直接驱动- 东芝电子元件及存储装置株式会社(“东芝”)今日宣布,已开始提供“TB9M040FTG”的工程样品。TB9M040FTG是一款内置功率MOSFET,用于3相直流无刷电机驱动的电机控制器件。作为东芝“SmartMCD™”[1]电机控制器件系列的最新成员,TB9M040FTG集成了微控制器(MCU)与电机驱动电路,可直接驱动3相直流无刷电机,适用于控制车载设备中使用的小型电机。 随着车辆可动部件电动化持续推进,用于电动阀门、暖通空调(HVAC)系统中的风门/挡板/翻板,以及进气格栅百叶(grille shutter)[2](图1)等应用的小型3相直流无刷电机需求不断增长。这也带动了对更少器件与更小型电子控制单元(ECU)的需求,以及对磁场定向控制(FOC)[3]支持功能与无感控制能力的需求,这些功能可实现更高级的电机控制并降低CPU负载。 图1. 小型车载3相直流无刷电机的主要应用位置 TB9M040FTG集成了MCU(Arm® Cortex® M23内核)、闪存、可直接驱动3相直流无刷电机的电机驱动电路、可用于电源的高边驱动电路、本地互连网络(LIN)[4]收发器,以及可在车载电池电压等级下工作的电源系统,并全部封装于小型VQFN36封装(6mm×6mm(典型值))中(图2)。该器件还集成了采用东芝专有硬件的矢量引擎(VE),可在采用FOC控制的电机应用中降低CPU负载,并有助于缩小软件程序体积。 图2. 基于TB9M040FTG的电机控制系统 此外,TB9M040FTG还具备反电动势(BEMF)[5]检测功能,可实现无感的方波控制。 这些特性结合在一起,可在实现高级且复杂的电机控制的同时,帮助车载设备实现小型化并减少元器件数量;TB9M040FTG可支持广泛的小型车载电机应用,并通过与ECU的LIN通信,实现车载系统内小型电机的控制。 东芝将持续扩充配备车载系统电机驱动所需功能的SmartMCD™系列产品线,并为车载系统的小型化与降低元器件数量做出贡献。 Ø 应用: 车载设备 - 小型直流无刷电机应用,例如电动阀门、HVAC风门/挡板/翻板,以及进气格栅百叶 Ø 特性: - 集成面向3相直流无刷电机的电机驱动电路,可直接驱动3相直流无刷电机(内置电机驱动MOSFET) - 32位MCU(Arm® Cortex® M23),工作频率:40MHz(内置低速与高速振荡器) - 内置带ECC的存储器(SEC/DED[6]) 代码闪存:80KB,SRAM:4KB - 内置用于FOC控制的矢量引擎(VE)以及可编程电机驱动器(PMD)[7] - 内置1分流电阻电流检测放大器[8],与12位A/D转换器 - 单通道高边驱动电路,可为霍尔效应传感器IC等器件供电 - 通信接口:LIN、UART(与LIN复用)和SPI - 符合AEC Q100[9] 0级 - 符合ASIL B[10] Ø 主要规格: 注: [1]SmartMCD™:东芝电子元件与存储装置株式会社开发的车载电机控制驱动IC(MCD)系列,将电机驱动电路与微控制器集成在单一器件中。 [2]进气格栅百叶:安装在车辆前部格栅后方的百叶/风门机构,可根据行驶状态自动开闭。 [3]磁场定向控制(FOC):一种典型的矢量控制方法(将电机转矩与磁通作为正交分量分别独立控制的控制方法)。该方法使用电机旋转参考系(dq坐标系)分别独立控制磁通分量(d轴)与转矩分量(q轴)。 [4]本地互连网络(LIN):一种串行通信协议,主要用于车辆中电子控制单元(ECU)之间的通信。 [5]反电动势(BEMF):电机转动时在绕组中感应产生的电压,由转子磁场切割绕组而形成,其方向与外加电压相反。 [6]内置ECC(纠错码)功能支持1位纠错(SEC)与2位错误检测(DED)。 [7]可编程电机驱动器(PMD):面向电机控制的硬件模块,可在硬件中执行PWM(脉宽调制)生成、电流导通控制以及故障检测,从而降低电机控制所需的处理负载。 [8]1分流电阻电流检测放大器:通过电流检测分流电阻与电流检测放大器间接估算电机电流。 [9]AEC Q100:由汽车电子委员会(AEC)制定的汽车电子器件认证标准,涵盖汽车电子部件(尤其是集成电路IC)的可靠性与质量要求。 [10]ASIL(汽车安全完整性等级):基于ISO 26262功能安全标准,用于表示汽车功能安全等级的指标。ASIL-B代表中等安全要求等级,高于ASIL-A,适用于功能故障可能对人身安全或车辆造成一定程度影响的情况。 [11]编码器输入电路(ENC):接收编码器信号以检测电机运行状态(包括位置、转速与旋转方向)的电路。 如需了解有关新产品的更多信息,请访问以下网址: TB9M040FTG https://toshiba-semicon-storage.com/cn/semiconductor/product/automotive-devices/detail.TB9M040FTG.html 如需了解有关东芝车载电机驱动IC的更多信息,请访问以下网址: 模拟器件 https://toshiba-semicon-storage.com/cn/semiconductor/product/automotive-devices.html#Analog-Devices *Arm和Cortex是Arm Limited(或其子公司)在美国和/或其他国家或地区的注册商标。 *SmartMCD™是东芝电子元件及存储株式会社的商标。 *本文提及的公司名称、产品名称和服务名称可能是其各自公司的商标。 *此样品仅用于功能评估。规格可能与量产产品有所不同。 *本文档中的产品价格和规格、服务内容和联系方式等信息,在公告之日仍为最新信息,但如有变更,恕不另行通知。
东芝 . 2026-06-02 812

告别频闪与过热关断:TP8005 让低压 LED 照明更稳、更顺、更省心
自动温度补偿· 双模调光 · 宽压输入 · 原厂全程支持 在日常技术支持中,我们常听到客户反馈:低压LED 灯具(如车灯、射灯、机床灯、灯带)容易出现高温频闪、调光不灵活、不同电压需要换方案等烦恼。今天,我们就结合TP8005降压型 LED 恒流驱动芯片,和大家聊聊如何用一颗芯片,同时解决这些问题。文中有车灯、射灯、工业灯、灯带四个典型应用方案,可直接参考设计。 一、为什么 TP8005 能做到“不频闪”? 传统驱动 IC 的过温保护(OTP)通常是“硬开关”:温度超标 → 直接关断 → 冷却后重启 → 再次关断……这就造成了人眼可见的低频闪烁。 TP8005 内部集成了自动温度补偿控制电路(自主设计): 当芯片结温超过130℃时,输出电流平滑下降,LED 亮度逐渐变暗,但不会闪烁; 温度达到150℃时,输出电流降至零,确保安全。 ✅ 特别适合密闭灯具、高温环境、长时间工作场景(如车灯、工矿灯),彻底解决“灯闪得眼疼”的问题。 二、调光方式任意选:模拟 / PWM 都支持 很多驱动只能接受一种调光信号,TP8005 的DIM 引脚则非常“通吃”: 小技巧:在DIM 脚对地加一个电容,还能实现软启动(约150μs/nF),抑制上电浪涌。 三、宽电压输入,一颗芯片通吃 12V / 24V / 36V TP8005 支持5V ~ 36V输入,覆盖绝大多数低压照明电源: 12V 系统(汽车、射灯、灯带) 24V 系统(卡车、工业机床、检修灯) 36V 系统(低压户外照明) 搭配高端电流采样结构,只需一个1% 精度电阻设定输出电流,输出电流误差≤ ±3%,最大输出1.2A。根据输入电压与LED 串联数量,可驱动 3~10 颗 LED。 四、四个落地案例:照着做,直接量产 方案一:12V / 24V 车载 LED 灯(日行灯、雾灯、阅读灯) 输入:12V 或 24V 汽车电瓶(发电机工作状态下实际电压 14V/28V 左右,均在 36V 范围内) ⚠️ 温馨提示: 汽车电瓶存在抛负载等瞬态高压尖峰,在24V或者以上的应用时,建议增加瞬态抑制器件(如TVS管)、电解电容做滤波,来吸收浪涌,进一步提升可靠性。 输出: SOT23-5封装:3 颗(12V 系统)或 6 颗(24V 系统)串联 LED,电流 350mA ~ 700mA;SOT89封装:电流最高可达1.2A。 关键元件:L=68μH(12V)或 100μH(24V),Rcs 按 Vcs / Iout 选择,肖特基二极管 SS14 或 SS24。 优势: 自动温度补偿 → 车灯密闭环境不频闪 支持 PWM 调光 → 可实现日行灯亮度分级或转向灯动态效果 宽压输入 → 耐受汽车电瓶电压波动 开路保护 → 灯珠损坏后自动切断,安全可靠 方案二:MR16 / GU10 射灯(替代卤素灯) 输入:12V AC(经整流桥)或 12V DC 输出:3 颗串联 LED,电流 350mA 关键元件:L=68μH,Rcs=0.28Ω(98mV / 0.35A),D=SS14 优势:无频闪,支持模拟或PWM 调光,灯杯温度升高时自动降流,不会烧坏。 方案三、24V 工业机床检修灯 输入:24V 输出:6 颗串联 LED,电流 500mA 关键元件:L=100μH,Rcs=0.2Ω(100mV / 0.5A,B 档芯片),DIM 脚对地加 1μF 电容(软启动时间约 150ms) 优势:LED 开路自动保护,金属灯壳不发烫,适合长时间工作。 方案四、可调光装饰灯带(展厅/酒店/家居) 输入:12V 输出:每路≤1A,多路可用多片 TP8005 调光:主控输出1kHz PWM 信号同时控制多颗芯片的 DIM 脚 优势:PWM 调光不改变色温,拍摄无频闪,色温一致性极佳。 五、原厂硬实力:为什么可以放心用 TP8005? TP8005 的背后是我们完整的设计、测试、应用支持体系: 严格的参数测试每一颗芯片都经过严格测试,保证批量一致性。 详细的应用文档提供: 完整的电感/二极管选型指南 PCB 布局要点(SW 走线、采样电阻 layout、散热铜皮) 快速的技术支持从选型评估、原理图review 到量产问题,FAE 团队可以直接对接,帮客户缩短开发周期。 稳定供货与合理定价作为国产原厂,备货充足,价格透明。 六、封装与效率 TP8005 提供SOT89-5L和SOT23-5L两种封装,效率最高95%,助力更易过认证。 一颗好的驱动芯片,不仅要参数漂亮,更要让工程师用得顺手、让终端产品可靠。 TP8005 正是基于多年 LED 驱动经验,为低压照明市场(尤其是 车灯、射灯、工业灯、装饰灯)打造的一款“无频闪、调光自由、耐高温、易设计”的恒流驱动 IC。 如果您正在开发: LED 车灯(日行灯、雾灯、阅读灯、氛围灯);LED 射灯 / 筒灯、工业检修灯 / 机床灯;装饰灯带 / 橱柜灯;低压户外照明等产品,欢迎联系我们,立即获取开发资料!
高端采样车灯芯片
天源中芯官网 . 2026-06-02 1120

智能显示屏时钟方案推荐:YXC多路时钟发生器确保画面同步进行
从医疗影像诊断到工业人机界面(HMI),再到高端电子竞技屏,显示屏技术正全面向4K/8K超高清及120Hz/144Hz高刷新率普及。高清高刷场景下图像数据吞吐量大幅提升,想要实现数据实时稳定传输,像素时钟、链路符号时钟等显示接口时钟的时序性能至关重要。 随着LVDS、HDMI、DP等主流显示接口传输速率不断提高,时钟信号抖动在高速串行链路中可能会被显著放大,导致显示画面撕裂/错位、信号失锁、EMI辐射超标等故障。基于行业痛点,显示屏厂商亟需一款支持高频频点灵活定制、兼具超低抖动特性的集成时钟方案。 一、智能显示系统时钟设计四大难点 显示屏系统通常包含FPGA、主控SoC、显示驱动IC及接口转换电路,内部电路复杂、时序链路多,时钟设计面临多重核心痛点,主要挑战有: 1、非标准高频点的精准输出 不同分辨率、刷新率的显示面板,需要特定的像素时钟频率,例如常见的135MHz及以上非标准高频点。传统的晶体振荡器往往只能提供标准固定频点,灵活性不足。 2、严格控制相位抖动 PCIe、HDMI、DP等高速串行传输链路对时钟抖动极其敏感。若相位噪声积分得到的RMS抖动较大,会削弱接收端的时钟恢复(CDR)性能,从而大幅增加系统误码率,影响画面稳定传输。 3、狭小空间的集成与散热 高端屏要求窄边框、轻薄化设计,留给PCB的面积非常有限。采用多颗独立晶振搭建时钟电路,不仅挤占布局空间,还会增加功耗、加剧整机内部散热压力。 4、电磁兼容性(EMC)合规 高频时钟产生的谐波干扰是电磁辐射超标、无法通过行业认证的主要诱因,智能显示屏行业亟需可靠方案抑制EMI干扰,满足EMC合规标准。 二、YXC高速显示系统时钟优选方案:可编程时钟发生器SYKG1042E/Q5系列 针对高速显示系统各类时序设计难题,YXC扬兴科技推出SYKG1042E、SYKG1042Q5系列可编程时钟发生器,为智能显示屏行业提供高性能一体化时钟替代选择。 两个产品系列核心电气性能一致,主要区别在于:SYKG1042E系列需外接基准时钟源,方案设计更灵活;SYKG1042Q5系列内置了一颗50MHz的晶体,硬件设计更简洁。 产品核心优势: ① 灵活定制:支持1MHz~333MHz任意频点输出 SYKG1042E/Q5系列内置分数反馈分频器(FFB)与输出分频器(FOD),支持在1MHz至333.33MHz范围内进行高分辨率频率合成。无论是显示屏领域常见的135MHz还是其他特殊频点,均可通过I2C接口动态配置,或通过OTP预设频点,无需客户定制昂贵的非标晶体。 ② 卓越性能:245fs低抖动(12kHz~20MHz)提升显示同步质量 SYKG1042E/Q5系列芯片具备卓越的抖动表现,135MHz时的典型相位抖动仅为245fs RMS(12kHz-20MHz),在PCIe Gen6模式下抖动典型值甚至能达到19fs RMS。这种工业级的稳定性能够显著提升显示总线的信号完整性,确保在高刷场景下图像传输无掉帧、无延迟。 ③ 高集成度与低功耗:释放空间压力 芯片采用4.0mm x 4.0mm紧凑封装,一颗芯片可同时提供4路差分输出与2路LVCMOS时钟输出,在1.8 V供电下功耗<150mW,相较于传统的晶振方案,可以显著降低PCB占用,更大幅缓解了显示模组的散热压力。 ④ 展频技术:降低EMI峰值 为了优化EMC性能,SYKG1042E/Q5支持±0.1%至±1.5%的中心展频以及-0.1%至-3.0%的向下展频。通过展频功能(SSC),可以将时钟能量分散到更宽的频谱中,有效降低峰值辐射强度,可降低EMI测试失败的风险。 YXC扬兴科技SYKG1042E/Q5可编程时钟发生器,依托宽频灵活配置、超低抖动、高集成低功耗及展频技术四大优势,适配电竞屏、工业屏、医疗影像屏等高端屏,既能保障高清画面稳定流畅输出,又可精简物料、降本增效,是高速智能显示系统理想的时钟优选方案。
时钟发生器
扬兴科技 . 2026-06-02 882

正式推出!德明利首款基于QLC NAND的UFS嵌入式存储方案
随着AI智能终端对数据处理与存储需求持续增长,存储技术正朝着更高密度、更优成本结构的方向快速演进。 德明利正式推出首款基于QLC NAND的UFS嵌入式存储方案,为AI终端提供稳定可靠且高性价比的新选择。目前,该系列已完成验证并进入量产阶段,可保障长期稳定的规模化供应。 1. 释放更高存储密度,提升AI终端系统效率场景需求 在NAND行业整体产能增长趋于理性的背景下,单纯依赖新增产线已难以持续支撑终端快速增长的容量需求。行业正通过升级既有产线、提升单颗存储单元可存储比特数的方式,从而在有限产能条件下释放更多可用容量。 相较于传统TLC存储技术,QLC通过在单个存储单元中存储四比特(4 bit)数据,实现更高的存储密度。 基于成熟的UFS 2.2接口平台,德明利QLC UFS系列通过更高的单元位元密度设计,实现与TLC方案相同的容量目标,为终端容量需求增长提供更具效率的实现路径。 2. 性能与稳定性并重,固件级优化赋能可靠体验 产品依托成熟稳定的NAND闪存供应体系,搭载慧荣科技主控芯片,在关键读取场景下保持稳定一致的输出表现。 优化|固件定制与介质优化 针对QLC NAND单元密度更高、读写更精细、耐受周期相对较低的物理特性,德明利对该系列产品进行了系统性的固件级定制与介质级协同优化,能够满足移动与嵌入式设备对性能稳定性、使用体验与数据可靠性的主流要求。 颗粒耐久性优化:通过动态写入策略与缓存机制,降低写入放大效应,提升写入效率与颗粒使用寿命。 智能缓存与数据迁移机制:优化读写负载、坏块管理与数据完整性,保障长期稳定运行。 跨温应用与温控优化:针对跨温使用场景,引入温度管理演算机制,保障不同温度区间下的稳定效能与数据完整性。 智能巡检与可靠性机制:采用LDPC错误校正与智能巡检机制,提升数据长期可靠性与运行稳定性。 3. 面向读取密集型场景,实现单位容量成本优化 从终端应用特征来看,智能手机、平板等消费电子设备的存储负载以读取行为为主,存储方案的综合价值评估,更关注长期稳定的读取体验与目标容量下的单位成本结构。 4.QLC UFS 具备支撑主流应用体验 德明利QLC UFS已具备充分支撑主流应用体验的能力,在既有的工艺和封装条件下,QLC高存储密度方案有效提升了单位存储资源的使用效率,使存储方案在达成目标容量时具备更优的成本结构。 QLC UFS产品规划将覆盖多个容量 目前,德明利QLC UFS产品规划将率先覆盖128GB、256GB、512GB 等主流容量段,并同步布局1TB、2TB超大容量,重点面向对容量规模与成本效率高度敏感的智能手机、平板电脑等消费电子应用场景。 打造高端嵌入式存储测试验证平台 基于光明高端制造与测试基地,公司持续强化QLC产品在智能终端等场景下的长期运行与兼容性验证能力,进一步提升产品可靠性与规模化导入能力。 结语 德明利首款QLC UFS系列以稳定读取体验、大容量和更优的单位容量成本结构,助力AI终端轻松实现存储容量升级。
TWSC . 2026-06-02 1197
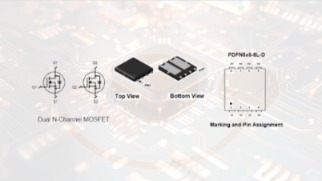
一颗5×6顶两颗管:N+N双芯MOS管选型对比
一个封装里装两颗独立N沟道MOSFET,这种器件在消费电子和工业电源里用得越来越多。PDFN5×6的封装面积不大,但内部集成的是完整的双通道器件,两个源极、两个栅极、一个公共漏极,工程师可以根据需求自由配置。 选这种双芯MOSFET是优势是省位号、省BOM、省布局空间。同样完成一个半桥拓扑,用两颗分立的SOT-23要占两块焊盘加跳线,用一颗双芯器件只需要一个焊盘位。对于空间敏感的消费电子主板来说,这个差距有时候就是塞得进去和塞不进去的区别。 双芯N管的典型用法主要有三种: · 半桥同步整流。 上管下管各用一颗,组成完整的同步Buck或Boost拓扑。两颗器件共用散热焊盘,热阻更低,布局也更紧凑。 · 电池充放电开关。 两颗N管串联,分别控制充电回路和放电回路。电池管理系统里这是常见做法,控制逻辑简单,导通损耗也低。 · 双路独立负载开关。 两颗管子各自独立控制两路负载,各走各的逻辑。比如PD快充的Vbus输出端和CC逻辑检测端,就可以用一颗双芯器件分别管理。 两颗N+N管,参数差在哪 选双芯MOSFET不像选单管那么简单。同一个封装、同一类应用场景,参数选错了轻则效率下降,重则出现直通和误开通。 以合科泰的两款双芯N管为例: 这三个参数直接影响选型结果,展开看一下。 导通损耗:7mΩ和12mΩ的差距 内阻差了这几毫欧,在高电流下直接体现为发热差异。60C04的RDS(on)典型值7mΩ,35C06是12mΩ,同样跑20A电流,60C04的导通损耗约2.8W,35C06约4.8W。这个差距是不可忽视的,在紧凑的PD充电器内要么降额使用,要么就要额外加散热。 低内阻的好处不只是效率,还关系到温升曲线。60C04的RθJC是5°C/W,35C06是2.5°C/W,两者差了一倍。同样的芯片尺寸,35C06的热阻反而更低,这也是它在25W持续功耗下能稳定工作的原因之一。 米勒效应:138pF和8pF差了一个数量级 这是两款器件差异最显著的地方。Crss即反向传输电容,也叫米勒电容。这个参数在单端应用里影响不大,但在半桥拓扑里直接决定了dv/dt误开通的风险。 简单说:当上管快速关断时,DS之间电压上升产生的dv/dt会通过米勒电容耦合到栅极。如果Crss太大,耦合电压可能超过下管的VGS(th),导致下管在不该导通的时候误导通。 轻则增加开关损耗,重则形成上下管直通的短路。 60C04的Crss高达138pF,半桥应用里需要更强的驱动电路或更慢的开关速度来抑制dv/dt。35C06的Crss只有8pF,米勒效应弱得多,同样拓扑下dv/dt误开通的风险低很多。 这也是为什么有些方案里明明60C04的内阻更低,工程师却会选35C06。这是因为这个参数在拓扑里权重更大。 雪崩能量:81mJ和36mJ差了一倍 EAS代表器件能承受的单次雪崩能量。感性负载关断时产生的电压尖峰如果超过VDS耐压,器件会进入雪崩状态,靠自身吸收能量来钳位。EAS越大,能扛住的尖峰越强。 60C04的EAS是81mJ,35C06只有36mJ,差了不止一倍。 在电机驱动、继电器控制这类感性负载场景里,关断尖峰的能量往往不小。如果选了一颗EAS不够的器件,偶尔几次过压可能就导致器件失效。这个参数在消费电子的纯阻性负载里几乎用不上,但一旦碰到电机、线圈、变压器一次侧这类应用,就是硬指标。 按场景选型 选双芯MOSFET没有标准答案,关键看你的电路拓扑和负载类型。 PD快充Vbus负载开关,选60C04 PD快充的Vbus输出端本质上是单端负载开关,不存在上下管交互的dv/dt问题。这种场景里Crss大不是问题,米勒效应的影响几乎为零。 反而内阻低的优势被充分发挥:7mΩ的导通损耗明显低于12mΩ,同样的散热条件可以跑更大电流,或者在同等电流下器件温升更低。 另外,PD快充的同步整流开关频率通常不是特别高,硬开关的dv/dt应力相对可控,所以Crss大在消费电子的低频段影响没那么突出。40V耐压对Vbus场景也足够,余量合理。 同步整流Buck半桥,选35C06 同步整流的半桥拓扑里,上下管交替开关,dv/dt是必须面对的问题。Crss只有8pF的35C06在这一点上优势明显,误开通风险低,开关特性更可控。 虽然RDS(on)比60C04高了近一半,但同步整流的开关频率通常在几百kHz到1MHz以上,这个频段里开关损耗占比更高,Crss和Qg的影响反而比导通损耗更关键。 另外60V耐压的余量也更充足。12V输入的同步Buck最高电压约20V出头,用40V器件勉强够,但输入端如果有电感反弹或启动冲击,40V器件的应力会更高。35C06的60V耐压在这种场景下更从容。 电池充放电开关,看系统电压 电池充放电开关的场景相对单纯,两颗N管串联分别控制充放电回路。这里没有半桥拓扑的dv/dt问题,也没有高开关频率,主要看的是导通损耗和耐压。 · 12V或24V系统(比如单节锂电池、两轮电动车的电池包)→ 选60C04。系统电压低,40V耐压余量足够,内阻低的优势明显,发热也更小。 · 48V系统(比如储能电池、电动车PACK)→ 选35C06。系统电压更高,48V电池满充约56V,加上尖峰余量,40V器件的安全裕量不够。60V耐压的35C06才能覆盖这类应用。 电机驱动H桥,选60C04 H桥驱动电机时,四颗开关管都要面对感性负载的关断尖峰。EAS参数在这里是硬指标。60C04的81mJ雪崩能量比35C06的36mJ高出一倍,在电机堵转、负载突变时能给器件更多的安全余量。 另外H桥的工作电压通常在12V-24V甚至更高,但开关频率不高,Crss大的问题不像同步整流那样突出。综合来看,60C04更适合这类应用。 N+P系列:充放电开关的另一种思路 如果觉得两颗N管串联控制充放电还不够简洁,还有N+P的方案。 N+P双芯器件用一颗P管做充电回路、一颗N管做放电回路。这种搭配的好处是:充电时N管关闭、P管导通,放电时P管关闭、N管导通,一路器件管两条通路,驱动逻辑比N+N更简单,不需要浮驱设计。 合科泰的N+P双芯产品线覆盖了30V到40V多个规格: 相比N+N系列,N+P更推荐用在锂电池保护板的充放电控制场景里。P管的体二极管方向天然适配充电回路,不需要额外的控制逻辑。对于入门级电动工具、便携储能、两轮电动车等应用,这种方案外围器件更少,BOM成本也更低。 选型速查表 选型说到底是场景匹配。没有最好的器件,只有最合适的器件。拓扑有没有半桥、负载是感性还是阻性、系统电压多少这三个关键问题答出来了,型号也就定了。
PDFN5×6
厂商投稿 . 2026-06-02 875

拆解实测 | 这个AI语音模组能在100dB喇叭旁1cm处彻底消回音?
开箱实测】巴掌大的语音模组,凭什么敢说“喇叭贴脸也不回音”? 在智能家居、对讲设备、车载蓝牙的DIY圈子里,免提通话的痛点就两个:回音 和 环境噪声。结构做小了,喇叭和麦克风恨不得贴在一起,远端满耳朵都是自己的回声;放到室外用,风一吹、金属一掉,通话直接报废。 最近拿到一颗 JKIN 的 A-29P 语音处理模组,官方标称参数看得我直呼离谱: 喇叭音量 100dB,麦克风距离 1cm —— 回音完全消除 AI 降噪能压住直吹麦克风的风声、金属敲击、汽车喇叭 拾音距离最远 5米,工作电流却只有 28~35mA 作为技术党,光看参数肯定不行,必须拆解、测试、扒原理。下面把我的实测数据和理解分享出来。 一、为什么传统AEC在近距离大音量下会失效? 传统免提通话靠线性自适应滤波器(比如NLMS)估计回音路径。但只要喇叭音量超过90dB,功放和扬声器就会进入非线性区——失真、谐波、腔体共振都来了。线性滤波器无法建模这些成分,残留回音永远消不干净。 A-29P 的思路是:线性AEC处理主要线性回声,再用神经网络专门抑制非线性残差。从模块功耗(35mA)推测,内部可能跑了一个轻量级残差回声掩蔽网络,计算量不大,但效果立竿见影。 实测场景:把一个4Ω/3W 小音箱和驻极体咪头背对背固定,间距1.5cm,播放1kHz正弦波扫频+人声测试音。远端回音几乎不可闻,双讲也不会中断。这已经不是传统DSP能做到的了。 二、AI-ENC:不滤噪声,只留人声 传统降噪算法(谱减法、维纳滤波)依赖噪声平稳假设,遇到风噪、敲击声就露怯。A-29P 的 AI 环境噪音压制换了个赛道:训练一个神经网络,让它学会“人声长什么样”。 我做了几个极限测试: 12V 暴力风扇直吹麦克风(距离5cm) 普通降噪模组输出要么爆音,要么人声变机器人。A-29P 输出的人声清晰度保持80%以上,风声几乎消失。 用螺丝刀敲击金属桌腿 瞬态冲击被压得非常干净,不会像传统算法那样出现“噗噗”的残留。 在路边录汽车鸣笛+人声 喇叭声被抑制,人声轮廓保留,虽然会有轻微的音色变化(高频细节略降),但可懂度远高于无降噪状态。 模块还支持降噪强度调节(45~90dB),安静环境用低档,嘈杂现场开高档。配合AGC,3米外正常说话也能清晰拾取。 三、波束成形 vs AI降噪:为什么只能二选一? A-29P 支持双麦克风波束成形(BF),但文档明确说:开启BF时AI降噪关闭。有人觉得是阉割,其实是算力限制。 我估算了一下计算量: 双麦BF(GSC结构):约 2 MMAC/秒 神经网络降噪(400k参数DNN,16kHz,帧移10ms):约 80 MMAC/秒 两者叠加远超35mA功耗下芯片的算力预算。所以厂家让用户按场景选择: 场景 推荐模式 原因 车载(驾驶员位置固定,侧窗风噪方向固定) BF 空间滤波提升信噪比6~12dB 户外对讲(风声、敲击声,方向不定) AI降噪 非平稳噪声压制强 室内监护(人走动,环境杂音多) AI降噪 不依赖固定方向 如果同时有方向性和非平稳噪声,只能从结构上补救:加防风海绵、优化麦克风减震。 四、三种回音参考取点方案,哪种适合你? A-29P 需要一路参考信号(喇叭在播什么)。它提供了三种取点方式,对应不同硬件拓扑。 模式 参考源 优点 注意点 模式一 功放输入端 信号≤1Vrms,无需分压 不含功放/扬声器非线性 模式二 功放输出端 包含实际非线性失真 D类功放必须加LC滤波,电阻分压 模式三 模块SPK输出 信号路径最短,性能最强 需要将功放改接在模块后 我最推荐模式三,回音消除效果最好。如果板子已经固定,只能用模式二,这里给一个D类功放的分压滤波参考电路: text 复制 下载 功放输出+ ——[ 39kΩ ]——+—— LINE IN | +——[ 10kΩ ]——+—— GND | +——[ 1nF ]——— GND (分压比约1/5,截止频率约16kHz) 五、总结:这颗模组适合谁? 适合: 正在做门禁、车载、会议设备,被回音和风噪折磨的工程师 想DIY一个全双工无线对讲机/婴儿监护器的极客 需要从零快速搭建语音前端的产品经理 不适合: 要求同时开启BF和AI降噪(物理算力限制) 需要处理“另一人说话”干扰(单通道NN无法分离同向人声) 对超高保真音乐传输有要求(AI降噪会改变音色) 最后:A-29P 已经在我的一款对讲产品上量产验证,稳定性超过预期。如果大家有兴趣,后续我可以放出完整的原理图适配和寄存器配置教程。 欢迎留言讨论你的免提通话设计经验!
音频处理模块,降噪消回音,硬件开发, 嵌入式
原创 . 2026-06-02 966

矿山井下呼叫报警难,AP0316 实现超远距离清晰拾音
井下通信的痛点:高噪与远距的双重挑战 在矿山井下作业环境中,语音通信系统的可靠性直接关系到生产安全与应急响应效率。然而,实际部署中工程师们常面临两大棘手难题:一是环境噪音极大,风机轰鸣、机械运转声往往掩盖人声;二是巷道空间空旷深邃,传统对讲设备拾音距离短,导致紧急呼叫信号在传输初期就发生丢失或失真。 普通的消费级音频方案在这种极端工况下几乎无法正常工作。麦克风要么被背景噪音淹没,要么因距离过远而采集不到有效信号。更糟糕的是,若为了覆盖大范围而强行增大喇叭音量,极易引发严重的声反馈(啸叫),使得通话完全不可用。针对这些特定场景,我们需要一种具备工业级鲁棒性、支持超远距离拾音且能灵活驱动大功率扩音设备的解决方案。AP0316 全功能 DSP 语音处理模组正是为此类高难度应用而生,它通过硬件级的参数配置与算法优化,为矿山安全监控和工业报警系统提供了坚实的声学底层支撑。 突破距离限制:T1/T2 端口配置实现 8 米超远拾音 解决井下“听不见”的问题,核心在于提升麦克风的拾音灵敏度与动态范围。AP0316 模组内置了灵活的拾音距离调节机制,无需修改固件或重新编译代码,仅通过两个简单的 GPIO 引脚——T1和T2的电平状态组合,即可在硬件层面切换四种不同的拾音策略。 默认状态下,T1 与 T2 均为高电平,模组工作在“中距离”模式(0.5-2 米),适用于常规办公室或狭小空间。但在矿山巷道或大型车间,这一范围远远不够。要将拾音半径扩展至8 米,覆盖更广阔的作业区域,工程师只需在 PCB 设计时将 T1 和 T2 引脚通过 0Ω电阻拉低接地(即 T1=Low, T2=Low)。 一旦配置为“低 - 低”状态,模组内部的 DSP 算法将自动切换至超远距离拾音模式。在此模式下,系统会显著提升前端增益,并配合优化的波束成形算法,精准捕捉远处微弱的语音信号,同时抑制近场的突发噪声干扰。实测表明,在配置得当的情况下,即便呼叫者距离设备 5 至 8 米,其发出的紧急报警指令依然能被清晰识别并传输,彻底解决了因距离导致的语音丢失问题。这种硬件级的切换方式不仅稳定可靠,还大大降低了现场调试的复杂度,非常适合批量部署的工业设备。 大空间扩音方案:外接功放与 MUTE 引脚的协同工作 解决了“听得见”的问题,接下来要确保“听得清”且“传得远”。井下巷道纵横交错,空间巨大,模组自带的 3W 功放虽然能满足近距离对讲需求,但在需要覆盖百米级巷道的广播报警场景中,功率显得捉襟见肘。此时,必须引入外部大功率功放来驱动号角扬声器或大型音箱。 AP0316 为此专门设计了模式三(外接大功率功放模式)。该模式利用模组上的AOUT2模拟音频输出接口,将经过降噪和回声消除处理后的高质量音频信号输送至外部功放模块。外部功放可轻松驱动几十瓦甚至上百瓦的负载,实现大范围的声波覆盖。 然而,双功放系统(板载 3W+ 外部大功率)若同时工作,不仅造成能源浪费,还可能因声场叠加产生干扰。AP0316 巧妙地通过MUTE引脚解决了这一冲突。在系统设计中,将 MUTE 引脚连接至主控 MCU 的 GPIO。当检测到需要启动外部广播时,主控拉高 MUTE 信号,模组内部会自动静音板载的 3W 功放输出,将全部音频能量导向 AOUT2 接口供外部功放使用;反之,在近距离对讲模式下,则可关闭外部功放,仅使用板载功放以节省功耗。这种智能切换机制确保了在任何工况下,声音输出都是单一、清晰且无冲突的,完美适配矿山复杂的扩音需求。 极端环境下的鲁棒性:90dB 降噪与全双工抗啸叫 矿山井下的声学环境极其恶劣,除了距离挑战,持续的高分贝背景噪音是另一大杀手。风机、传送带和凿岩机产生的噪音频谱复杂且强度极高。AP0316 搭载的AI ENC(环境降噪)算法,针对此类工业噪音进行了深度优化。 通过深度学习海量噪音样本,该模组能够实时分析音频流,精准分离人声与非人声成分。在极限测试中,其降噪深度可达90dB。这意味着,即使背景噪音如同飞机起飞般嘈杂,模组也能将其压制到极低水平,只保留清晰的人声语音。对于紧急呼叫而言,这一特性至关重要,它确保了报警信号不会被环境噪音淹没,指挥中心能准确接收到每一句指令。 此外,在大功率扩音场景下,麦克风与扬声器的距离可能较近,极易产生声反馈(啸叫)。AP0316 集成了高性能的AEC(回声消除)引擎,支持高达100dB的回音消除量,并具备全双工处理能力。即使在外接大功率喇叭全音量输出的情况下,模组也能有效抵消从扬声器返回麦克风的回声,杜绝啸叫现象,保证双向通话如面对面交流般流畅自然。 结合其**-20℃~70℃**的标准工作温度范围(可定制升级至工业级 -40℃~85℃),以及宽电压输入设计,AP0316 在潮湿、高温或严寒的井下环境中依然能保持稳定的性能输出。对于追求高可靠性的矿山安全监控系统设计师而言,这种集超远拾音、大功率驱动适配与极致降噪于一身的方案,无疑是构建清晰、可靠语音通信链路的理想选择。
回声消除
原创,个人观点 . 2026-06-02 959

Vishay特种薄膜业务部门推出薄膜金属化基板平台
基板支持下一代热、光和RF封装 日前,Vishay宣布,推出新的薄膜基板平台,旨在支持下一代光收发器、RF模块以及要求高散热性能、精确准直和高频信号完整性的高级电子封装应用。 Vishay以提供高性能薄膜基板而闻名,在传统解决方案难以满足的环境中,这些基板能够支持构建体积更小、速度更快、效率更高的电子系统。Vishay采用精密沉积技术制造无源电路元件,并精密加工包括氮化铝(AlN)在内的先进陶瓷基板。通过这个新的平台,这种方法能够在苛刻环境中提供优异的导热性、尺寸稳定性和电气性能。 该平台针对高速数据通信领域的新兴应用进行了优化,包括800G、1.6T和3.2T光收发器,在这些应用中,日益提高的功率密度和更严格的封装限制要求增强散热,解决准直难题,并实现低损耗互连性能。Vishay的薄膜基板使设计人员能够从器件层面改善热管理,同时保持高频率下的精确准直和信号完整性。 Vishay特种薄膜副总裁Michael Casper表示:“下一代光子学和RF系统将封装的散热、机械和电气性能发挥到了极致。我们的薄膜基板平台为工程师提供了一种灵活的解决方案,能够在不损害可靠性的前提下实现高性能。” 主要特性和优势: 快速进行原型制作,在三座工厂批量生产 高热导率:AlN衬底支持高功率器件的高效散热 高频性能:低损耗薄膜互连支持微波和毫米波应用 小型化:紧凑型集成式设计支持空间受限的模块 降低制造复杂性:预沉积AuSn或EPIG和精密加工为复杂的制造工艺提供支持 设计灵活性:量身定制的几何形状、金属化方案和电路集成支持为客户定制设计 Vishay的薄膜基板平台已在大量应用中得到了验证,包括激光二极管贴妆、RF /微波模块、光学准直、引线键合和SMT工艺以及密封封装解决方案。公司与航空航天和高可靠性工业应用领域的客户密切合作,共同开发满足严苛性能和环境要求的设计 Vishay现可提供样品并支持定制设计,并由全球生产能力提供保障。
Vishay . 2026-06-02 784

2026GTC | NVIDIA DSX 为基础设施建设者提供 AI 工厂实战指南
NVIDIA DSX 平台专为从零开始建设 AI 工厂而打造,它重新定义了下一代基础设施的设计、建设与运营模式——通过整合 NVIDIA 芯片、系统、软件、配套设施及合作伙伴技术,在实现更低 Token 成本的同时,加速实现首次投产。 全新 DSX MaxLPS 软件能够通过最大化每兆瓦 Token 性能,助力 AI 基础设施和 AI 工厂实现最低 Token 成本。 开源且模块化的 DSX OS 软件集成了全生命周期管理、运行时一致性与自动化健康巡检、系统韧性、多租户 AI 工厂运营以及各类平台服务。 行业领先制造商正在打造 NVIDIA DSX 就绪系统,通过极致的协同设计支持 AI 工厂建设。 覆盖技术栈各层的 DSX 合作伙伴生态正日益壮大,加速推动全球 AI 工厂的设计、部署与运营。 NVIDIA GTC 台北 —— 2026 年 6 月 1 日 —— NVIDIA 今日宣布推出 NVIDIA DSX™ 平台,为基础设施建设者提供了一套建造 AI 工厂的完整实战指南。 NVIDIA DSX 整合了开源、模块化软件库、应用程序接口(API)、参考设计、NVIDIA 加速计算平台以及合作伙伴技术,打造出一个通用协同设计平台,专门用于 AI 工厂的设计、部署与运营。 NVIDIA 是目前唯一一家能够构建完整 AI 工厂的企业。通过在计算、软件、配套设施及合作伙伴技术等技术栈各层实现协同,DSX 为基础设施建设者提供了一套经过验证的框架,帮助他们实现 AI 工厂的大规模设计、部署和运营。 这一集成化平台不仅加速了部署进程,还大幅提升了大规模运营下的可靠性与韧性,同时,它构建了一个丰富的生态系统解决方案,以实现最低 Token 成本,将每兆瓦电力转化为更强大的智能。 NVIDIA 创始人兼首席执行官黄仁勋表示:“我们不仅仅是在交付芯片,更是在为每一个基础设施建设者提供一套打造 AI 工厂的完整实战指南。借助 DSX 平台,你甚至可以在花出一元钱之前,就对整座工厂进行全面模拟,在一台机柜装上之前,就能验证其性能表现,并且能够以生产级 AI 所需的可靠性来运营。” DSX 平台组成 DSX 现已涵盖整个技术栈,从芯片、系统到基础设施软件、配套设施以及合作伙伴技术,无所不包。该平台最新引入的组件包括以下全新的开源软件: DSX MaxLPS™:一套旨在既定电力预算内,最大化每兆瓦 Token 产出性能的技术组合,从而为 AI 工厂带来极致的每 Token 成本优势。通过将 45°C 液冷技术与优化每瓦性能的机架级技术相结合,DSX MaxLPS 让运营商能够在几乎不影响工作负载性能的前提下,将 GPU 运行在其最高能效点,从而额外部署高达 40% 的 GPU。 DSX OS™:一款专为 AI 工厂运营量身打造的开源、模块化软件,提供全生命周期管理、智能调度、运行时一致性、自动化健康巡检、系统韧性、多租户运营以及各类平台服务。 DSX MaxLPS 和 DSX OS 已加入 DSX 平台现有功能矩阵: DSX 参考设计:提供面向不同代际产品、经过验证的 AI 工厂架构,覆盖计算、网络、存储、硬件集群设计和配套设施——包括供电、制冷与控制系统,以及土建、结构和建筑设计。 DSX Sim™:面向 AI 工厂全生命周期的高保真仿真层,帮助 NVIDIA、合作伙伴及客户对基础设施决策进行建模、验证和优化,贯穿从规划、设计到部署运营的每个环节。 DSX Flex:将 AI 工厂与电网服务连接,使其能够根据负载削减、需求响应和电价波动等电网信号,动态调整工作负载,同时还能跨公用电网、现场可再生能源以及储能系统,对绿色能源与混合能源进行统一编排调度。 DSX Exchange™:实现在 IT、运营技术与运营智能体之间,对计算、网络、能源、电力及冷却系统的各类信号进行可扩展且安全的集成交互。 不断壮大的 DSX 生态系统 NVIDIA 正与行业领先的台湾地区系统制造商合作,扩展 DSX 生态系统,并以极致协同设计为核心,全力助推 AI 工厂的建设。 NVIDIA 云合作伙伴 CoreWeave、Crusoe、Firmus、IREN、Lambda、Nebius、Nscale 和 Yotta Data Services 正在部署 DSX 平台堆栈的核心组件——包括 DSX Sim、DSX MaxLPS 和 DSX OS——以降低风险、提高 GPU 利用率,并让 AI 云算力更快上线。 戴尔科技、HPE、联想和 Supermicro,与华硕、Foxconn、技嘉、和硕、云达科技(QCT)、纬创资通以及纬颖,正在打造 NVIDIA DSX 就绪系统,并提供仿真就绪资产,助力客户在全球范围内规模化部署完整的全栈 AI 工厂解决方案。 在该生态系统中,基于模型的系统工程充当了从机架设计到配套设施部署之间的桥梁,旨在打造出针对每兆瓦 Token 性能进行优化的 AI 基础设施。云达科技与和硕正与达索系统合作,打造一个实时 AI 工厂数字孪生配置器,通过自动化实现从机架到配套设施设计,在提升质量的同时大幅减少工作量。各大系统制造商对 DSX Sim 的采用进一步扩展了 NVIDIA Omniverse DSX Blueprint 生态系统,并与 Cadence、PTC 和西门子等软件合作伙伴实现更深层的集成。 DSX Flex 正在助力 Emerald AI 与 Silicon Valley Power 开展的一项商业化兆瓦级试点项目,该项目旨在展示具备电网信号响应能力的 AI 工厂。这类工厂能够在确保 AI 工作负载性能不受影响的前提下,根据公用电网信号动态调整用电量,这不仅有助于维护电网的可靠性和用户的用电经济性,还能释放出额外的电力容量,从而为 AI 产业的持续增长提供动力。 众多合作伙伴正在采用多种 DSX OS 软件组件,以实现全生命周期管理、多租户支持、安全防护、自动化健康巡检、系统韧性及各类平台服务。采用 DSX OS 组件的生态合作伙伴包括 Aible、BeyondAI、Bhashini、DCAI、Mirantis、OpenNebula Systems、Rafay、Red Hat、Sarvam、Simplismart、Spectro Cloud、Supermicro、vCluster 以及 Vultr。
NVIDIA
芯查查资讯 . 2026-06-01 1477

GTC | NVIDIA在全球首个Agent原生电脑问世
英伟达中国台北GTC大会,大幕拉开! 就在刚刚,老黄再次站上绝对C位,开启了震撼全场的主题演讲——有用AI的时代,全面来临。 全场压轴好戏,是英伟达首款RTX Spark「超级芯片」! 它史无前例地搭载了6144个GPU核心、128GB统一内存,把过去只有数据中心才有的算力,塞进了一台笔记本。 全球首款专为Agent打造的Windows PC,此刻诞生了。 一眼看懂老黄这场2小时硬核演讲: Vera Rubin全面量产,组装一个机架从两小时砍到五分钟 Vera CPU登场,第一颗不为人、只为Agent造的CPU RTX Spark(N1X),全球首台为个人Agent打造的个人电脑 Nemotron 3 Ultra开源,英伟达最大模型,5500亿参数 超级芯片RTX Spark首秀PC被彻底重新发明 这场大会最重量级的发布,非「超级芯片RTX Spark」莫属。 「四十年后,英伟达要和微软,一起重新发明PC」! 黄仁勋这句话一出口,全场炸了。 他先讲了段历史。Windows 3.1时代,PC还只是企业的工具,直到Windows 95,才把PC变成了人手一台的消费电子。 而今天,那个让一切发生的「DirectX加应用」组合,要被「LLM加Agent」彻底取代。 大模型,就是新时代的DirectX。Agent,就是新时代的应用。 然后,他掏出了那颗「超级芯片」RTX Spark,核心是和联发科联手打造的N1X CPU。 这是有史以来能效最高的PC芯片! 老黄说,这是英伟达把33年的全部积累,蒸馏进了一颗芯片。 Blackwell RTX GPU,6144个CUDA核心,1 PFLOP的AI算力 定制20核Grace CPU,与联发科联手打造 128GB统一内存,NVLink全程融合 台积电3nm工艺,700亿晶体管 英伟达100%的软件栈,全跑在这上面。 更重磅的是,这不止一台笔记本。 微软和英伟达一口气端出桌面、笔记本、工作站三件套,全部100% Windows兼容、100% CUDA、100% Tensor Core。 那台桌面机最有意思。它能让Agent7天24小时跑着,不计费。 没有额度焦虑,下载一个本地模型,这个Agent就彻底是你自己的。 而那台名叫DGX Station for Windows的怪兽,直接堆到768GB内存、20 PFLOPS算力、8TB/s内存带宽。 未来在个人桌面上,跑一个万亿参数的模型,都不是问题。 老黄说,这是四十年来第一次,整条PC产品线被推倒重来。一条新的产品线,一个新的开始。 Vera Rubin全面量产为Agent而造 接下来,当传闻中的「性能怪兽」Vera Rubin真机登场那一刻,全场瞬间沸腾。 老黄在台上掷地有声,「Vera Rubin不只是为了跑AI而生的,它是为了运行Agent而生」! 如今,Vera Rubin正全面投入量产。 供应链规模是上一代Grace Blackwell的两倍。过去组装一个机架要两个小时,现在只要五分钟。 你没看错,五分钟。 当场,他对Vera Rubin真机来了一次「解剖」。 Vera Rubin NVLink 72,整个系统的核心大脑,72块Rubin GPU加36颗Vera CPU Vera CPU机架,256颗全液冷CPU Vera BlueField存储与安全处理系统 Mellanox网络系统,世界上第一个CPO共封装光学 最抓眼球的,是Vera Rubin硬件形态的终极进化,无电缆、无软管、无风扇。 老黄把它从台上推走时还调侃,后面大概有2000个人在拉。 Vera CPU:老黄把CPU重造了一遍 在Vera Rubin背后,植入的是英伟达专为Agentic AI时代打造的CPU,Vera CPU。 老黄的解释很深刻,「到今天为止,世界上所有的CPU都是为人造的。这一刻,Vera CPU是给智能体用的」。 既然是为Agent定制的CPU,Vera必须具备超越常理的特性。老黄总结了三个硬核指标。 第一,世界第一的单核性能。 Vera做到了每个时钟周期抓取、解码、执行10条指令,创下世界最高纪录。 第二,每核带宽和总线带宽,刷新天花板。 Vera内部用一张「光速级」的Scalable Coherency Fabric把所有核心连起来,没有chiplet税,没有跨芯片边界的损耗。 它还是第一颗用上PCIe Gen6的CPU,配1.2TB/s的LPDDR5X带宽,是市面最强x86 CPU的2到3倍。 第三,极致的能效。 把尽可能多的CPU塞进AI数据中心,又不能抢走生成token那点宝贵的电力。 实测里,对比x86,Vera CPU跑SQL的速度狂飙3倍。盯纽交所那种实时流处理,更是直接拉到6倍。 老黄给了一个极致的比喻,「CPU是指挥家,GPU是交响乐团」。 Agent,就是新的「操作系统」 老黄抛出了一个更底层的判断,「我们进入了全新的Agent时代,智能体就是未来的操作系统」。 传统时代,计算机的运行逻辑是,应用层加代码加操作系统。 而今天,这个架构变成了,智能体+Harness。 输入与感知、推理与规划、工具调用与行动,加上短期和长期记忆,构成了智能体完整的工作流。 这里面,LLM负责「思考」,而Harness就像一个操作系统,负责连接一切、调度信息。 硬件就位,还差软件生态。 现场,老黄端出了NVIDIA Agent Toolkit,四层架构。 模型层,Nemotron 3 Ultra,英伟达最大的开源模型,约5500亿总参数,每token激活550亿 框架层,支持Claude Code、Codex、OpenClaw等各种Agent直接运行 工具和技能层,CUDA X库全部附带skills文件,Agent自学即用 运行时层,OpenShell,英伟达的开源安全运行时,Apache 2.0 这四层叠起来,就是一个无敌的Agent系统。 就拿英伟达和Cadence联合打造的「芯片设计超级Agent」来说。 其中,Codex负责总指挥,Cadence ChipStack启动RTL验证循环,底层跑Nemotron模型,外层套OpenShell做安全。 Agent自己跑仿真、做形式化验证、发现设计缺陷、修复代码bug,整个过程自驱动,人类工程师可以在任何环节介入。 验证周期从数周压缩到数小时,加速超过40倍。 这就是Agentic AI。为了这一天,英伟达已经准备了整整两年! 算力就是营收,AI工厂来了 对AI大厂来说,他们其实不想买计算机,想要的是一座AI工厂。 于是英伟达又往上长了一层,叫DSX,一套AI工厂的施工蓝图。 先在Omniverse里建一座数字孪生工厂,电力、散热、网络全部模拟验证一遍,一个机架还没运到,整座工厂已经在虚拟世界里跑通了。 工厂一通电,DSX OS接管运营。 DSX Max LPS负责榨电,今天的AI工厂普遍超配电力高达40%,而它能在同样的电力预算下塞进更多GPU,45度的热液冷更省水更省电。 老黄说,到本世纪末,100吉瓦的AI工厂要陆续上线。 算力就是营收,算力就是利润。没有营收和利润,就是亏损。 这一层,把英伟达从一家卖芯片的公司,彻底变成了一家卖整座工厂的公司。 这里,老黄再次祭出了自己的经典语录:「买越多,赚越多!」 Agent时代,用户再不是人类 两个小时,几十个发布点砸下来。 但老黄从头到尾,其实只讲了一句话。过去四十年,计算机是为人造的。从今天起,它要为Agent造。CPU重做,PC重新发明,数据中心重构,软件栈重搭,全是这一句话的注脚。 上一个敢说「重新发明PC」的人,掏出来的是iPhone,它重新定义了人和设备的关系。 这一次,老黄掏出来的东西看着没那么性感,但它要重新定义的是另一件事。 谁,才是这台设备真正的主人。
NVIDIA
新智元 . 2026-06-01 1 2632

企业 | OpenAI官宣进军机器人赛道,短期内专注研发协助型机器人
OpenAI官宣进军机器人赛道。 6月1日,OpenAI CEO山姆·奥特曼(Sam Altman)在社交平台发布OpenAI Robotics招聘信息,称公司正在寻找杰出的全栈硬件、运营、系统及机器学习工程师,共同编程并制造对社会真正有用的机器人。 奥特曼表示,人工智能应当能够在现实世界中帮助人类。短期内,OpenAI专注于研发能够协助技术工人建设未来基础设施的机器人;长远来看,公司设想未来的每个人都能拥有一个可以完成各种需求的个人机器人。 奥特曼透露,OpenAI的世界模拟研究项目在过去一年中发展迅速,现演变为OpenAI Robotics。项目由阿迪亚·拉梅什(Aditya Ramesh)领导,目前的进展十分迅猛,其根基在于机器人硬件研究与机器学习研究的深度融合与协同设计。 阿迪亚·拉梅什是OpenAI资深研究员,是DALL-E系列模型的发明者和Sora视频生成模型的主要开发者和负责人。 此前,OpenAI宣布关停Sora,并将重新调整团队重心,致力于研发能够与物理世界互动的高级机器人和人工智能模型。 目前,OpenAI正在准备IPO上市,上市估值有望达到1万亿美元。有外媒消息称,OpenAI最快将于今年9月上市。
OpenAI
芯查查资讯 . 2026-06-01 1 1134

政策 | 美国封堵漏洞,阻止先进芯片流向中企海外分支
美国商务部堵住一个潜在漏洞,此前该漏洞允许向中国企业的海外分支出口AI芯片 据业内消息人士估计,可能已有数十万枚芯片流入中国企业海外分支 新指南不要求数据中心停止使用或维护相关芯片 美国商务部周日采取行动,在网站上发布新指南,试图堵住一个其已存在一年的潜在漏洞。该漏洞可能导致企业向位于中国境外的中国实体出口全球最先进的芯片,例如Nvidia(英伟达) 最先进的Rubin和Blackwell处理器,以及AMD的MI350x芯片。 这一出乎意料的指南表明,尽管美国大力限制中国企业获取发展关键人工智能(AI)能力所需的半导体,但美国最先进的AI芯片可能在近一年时间里持续流向位于马来西亚等地的中国AI企业子公司。 目前尚不清楚在该政策漏洞存在的一年内,究竟有多少芯片被出口。一位熟悉供应链情况的芯片行业消息人士估计,数量达数十万枚。 美国商务部在此次不同寻常的周末公告中表示,将对总部在中国的实体(即便这些实体位于中国境外)实施先进芯片许可要求。 美国商务部尚未立即回应置评请求。Nvidia和AMD也未立即回应置评请求。 这一漏洞源于2025年5月商务部的一项决定:当时宣布不再执行拜登政府任期末期颁布的“AI扩散规则”(AI Diffusion Rule)。该规则原本用于规范全球对AI芯片的获取。 科技专家、前美国国务院官员Chris McGuire周日在社交媒体发文称:“这是一个巨大的问题。”他表示,这一漏洞使得中国企业的海外子公司无需许可证即可购买Nvidia Blackwell芯片。 “中国企业一直在购买这些芯片,而且很可能是大规模采购,”McGuire称。 另外值得注意的是,新指南并未要求数据中心停止使用这些芯片,也未要求中止对服务器等先进计算设备的维护服务。
政策
路透财经早报 . 2026-06-01 1610

方案 | ZX86赋能创新 兆芯 x 昱格共建广电行业内容创作存储一体化解决方案
凭借过硬的产品性能、全方位的安全防护以及成熟的端到端整体解决方案,兆芯方案已在广电行业完成标杆落地验证,充分印证了ZX86自主算力平台在完美适配广电高清内容生产、多业务并发承载、融媒体全流程运营等核心场景的同时,完全满足广电行业信创合规、数据安全与7×24小时稳定运行的要求,为各级广播电视台、融媒体中心提供了成熟可复制、落地性极强的标杆案例。 既要满足4K高清内容生产、海量素材管理的业务刚需,也要依托信创架构,筑牢全流程数据安全壁垒,实现团队协同效率与内容生产质量的双重升级。 传统广电内容生产模式普遍存在素材分散存储、文件反复拷贝、多人协同卡顿低效、数据安全防护薄弱等痛点。老旧的单机制作、分散存储模式,已无法适配当下高清化、规模化、常态化的融媒体生产场景,行业亟需一套适配信创标准、兼顾高性能创作与安全存储的一体化解决方案。 兆芯拥有以开先KX-7000桌面处理器、开胜KH-50000/ KH-40000高中端服务器处理器为代表的全系列自主ZX86算力产品矩阵,覆盖广电端侧、边缘、中心全层级算力需求,具备为广电行业提供全场景、一体化整体解决方案的核心能力。立足广电行业场景痛点与信创升级需求,兆芯联合昱格深度产业协同,推出基于ZX86架构平台的广电内容创作与存储一体化解决方案。 本文方案依托兆芯全栈自主可信算力底座,打通前端创作、在线协同、后端存储、智能归档全业务链路,为广电融媒体内容生产提供闭环式、标准化、国产化的全新技术支撑,助力行业高效完成信创落地与业务数字化升级。 方案简介 本方案基于统一的兆芯自主ZX86平台搭建,前端采用KH-40000/32处理器的 “高性能创作工作站”+后端KX-7000桌面式、KH-40000/12/16机架式 “信创NAS分布式存储”一体化方案打造,具备企业级高并发数据处理能力,可实现多位剪辑师同时在线协作,无需反复拷贝素材,极大降低协作沟通成本,支持高效热数据存储,集成自动归档与多副本备份机制,为融媒体中心的内容资产保障安全。 前端高性能创作工作站 前端创作场景采用了昱格YGT542-Z4高性能信创工作站,搭载兆芯开胜KH-40000/32服务器处理器,支持双路全高双宽GPU卡扩展,全面适配主流剪辑、调色、渲染等专业应用软件。设备凭借强劲的自主算力与稳定的运行性能,可流畅支撑4K超高清剪辑、特效合成、批量素材处理等高频业务,满足栏目包装、素材处理等多种创作需求,为广电内容创作提供纯国产化、高性能的生产终端支撑。 后端一体化智能存储平台 后端高性能存储场景采用了基于兆芯KX-7000处理器、开胜KH-40000/12/16处理器研发的昱格信创NAS存储产品,采用标准化分布式存储架构,实现内容创作、在线编辑、素材调用、数据归档、安全备份的无缝协同。产品矩阵覆盖大、中、小型广电机构场景,可精准适配不同规模单位的海量素材存储、高频数据调取、团队协同生产需求。 方案特性 智能热库 自动识别数据热度,将热数据(如正在剪辑的素材)存放在NAS高速区,冷数据(如归档影像)迁移至存储区,实现性能与成本的平衡。 高并发处理 支持多人在线协同工作,可多用户同时进行4K视频剪辑,系统通过万兆网络保障数据传输不卡顿。 数据安全与归档 NAS系列存储产品采用企业级硬盘,提供数据保护机制,支持长期归档,确保数据安全无忧。 用户受益 重构协同模式 提升内容生产效能 面对广电行业日益增长的高清化、4K化内容需求,单机存储与本地拷贝模式已经难以支撑高效率协作。本方案具备企业级高并发数据处理能力,可实现素材集中管控、资源统一调度、多人同步在线创作,彻底解决传统模式下素材分散、流转繁琐、协同低效等问题。有效缩短内容制作周期,降低团队沟通与素材流转成本,助力广电机构构建素材集中、协同高效、创作流畅的现代化融媒体生产模式,真正实现“素材集中、协作高效、创作流畅”的内容生产模式,适配行业高清化、精品化发展趋势。 对于融媒体中心而言,这意味着: 内容素材统一管理 多人同步在线剪辑 项目协作效率提升 内容制作周期缩短 数据调用更加便捷 智能资产管控 夯实安全运营体系 在广电行业,内容资产的安全性同样至关重要。本方案通过冷热数据智能分层管理,精准匹配日常高频创作与长期静态归档的差异化业务需求,搭配自动归档、多副本备份机制等多重数据安全防护机制,实现广电内容资产全生命周期智能化管理。既保障日常生产的高速访问体验,又实现历史精品内容、核心素材的安全长效留存,全面适配广电行业规范化、安全化、可持续运营要求。 通过智能资产管理方式,可帮助用户实现: 热数据高速访问 冷数据自动归档 多副本数据保护 内容资产长期保存 存储空间高效利用 产品矩阵 昱格 YGT542-Z4 高性能工作站 专为广电内容创作场景定制研发,搭载兆芯开胜KH-40000/32服务器处理器,支持GPU扩展与硬件升级,全面满足视频剪辑、特效包装、素材渲染等全流程创作业务需求。凭借高性能、高稳定、全自主等特性,可以为各级融媒体中心、广电制作团队提供可靠的国产化创作算力支撑。 昱格 NAS VH8桌面式存储 基于兆芯开先KX-7000自主平台打造,采用轻量化桌面式设计,无需专属机房,部署灵活便捷。最大支持240TB大容量存储与16TB个闪存空间,兼顾性能、安全与性价比,适用于中小型融媒体中心、专业影视工作室等场景。 昱格 NAS RH12\RH16\RH24\RH36 机架式存储 搭载兆芯开胜KH-40000/12/16服务器处理器,面向大型广电集团、核心融媒体中心打造,具备超大容量与超强高并发处理能力,可轻松承载海量影视素材集中存储、大规模团队协同创作、高频数据调取等高强度业务场景,是大型广电机构信创升级的核心存储设备。 总结 兆芯完整掌握通用处理器及系统平台芯片研发设计的核心技术,已自主完成ZX86指令集定义、扩展与迭代兼容,构建自主不封闭、兼容不依附的核心知识产权体系。旗下开胜服务器处理器、开先PC及嵌入式处理器,具备高性能、高兼容、高安全、全自主的核心优势,可搭建云、边、端全栈自主算力体系,为各行业数字化、智能化转型筑牢算力底座。 凭借过硬的产品性能与成熟的行业适配能力,兆芯已在广电行业完成标杆落地验证,2025年底,基于兆芯开胜KH-40000/32核心的高性能服务器产品成功中标内蒙古广播电视台项目。该省级广电标杆项目的顺利落地,充分印证了兆芯ZX86自主算力平台,在适配广电高清内容生产、多业务并发承载、融媒体全流程运营等核心场景应用的同时,完全满足广电行业严苛的信创合规、数据安全与稳定运行要求,为全国省、市、县各级广播电视台、融媒体中心的国产化替代与数字化升级,提供了成熟可复制、落地性极强的标杆案例。 面向行业信创持续深化,加速推进数字化、智能化转型升级的发展趋势,未来,兆芯将持续深化与昱格等生态伙伴的技术协同与产品创新,持续深耕广电融媒体场景,以更贴合行业需求、更富有行业竞争力的信创产品与解决方案,以自主硬核算力赋能广电内容生产革新,助力行业实现高质量、安全化、智能化长效发展。
兆芯
兆芯 . 2026-06-01 1330
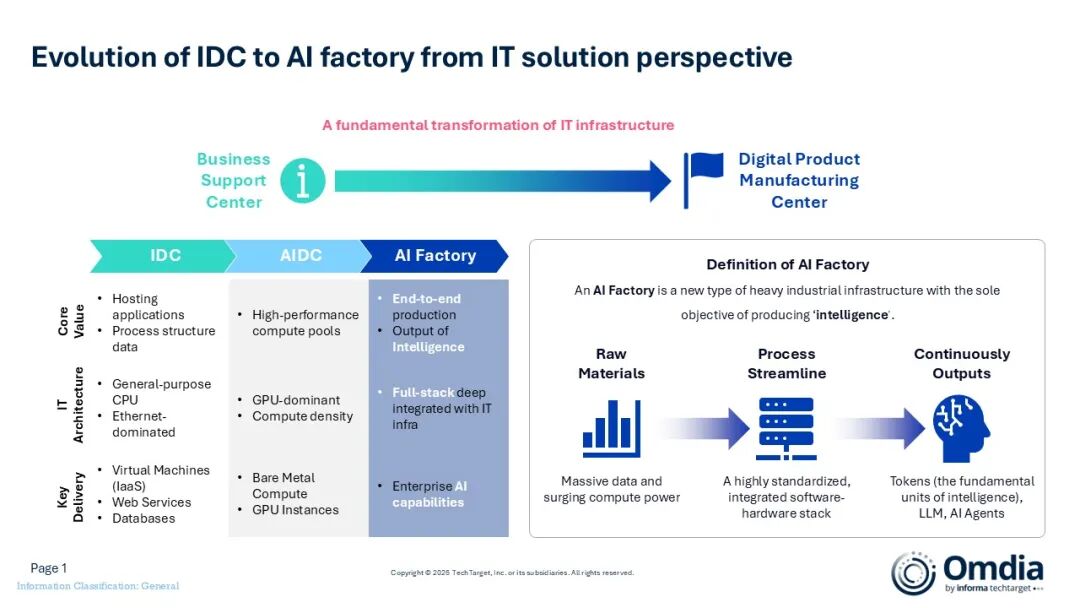
市场 | Omdia:AI Factory市场进入工业化阶段,五大动态重塑2026
Omdia发布的《全球AI工厂市场格局》报告预测,到2030年,全球数据中心的累计投资额将接近1.6万亿美元。仅在2026年,全球领先科技企业将在AI基础设施上的资本支出合计超过6000亿美元。这一巨额资本投入表明,AI Factory市场已跨越不可逆的临界点,正演变为一种全新的工业组织形态,其核心特征为超高的资本密集度、显著的地缘属性以及复杂的工程技术壁垒。 市场现状:从IDC到AIDC再到AI Factory Omdia将AI Factory定义为以"生产智能"为目标的新型工业基础设施,其根本产出单位是Token(词元)。无论规模大小,数据中心正从传统的业务支撑中心转变为数字产品制造中心转型,并遵循四层架构进行组织:能源与物理基础设施层、硬件与网络互联、调度与虚拟化编排层,以及MaaS与AI应用生态层。 当前,生态系统涵盖四种解决方案范式——全栈公有AI云超大规模厂商、计算原生AI云专业厂商、交钥匙式私有AI底座供应商,以及区域/行业AI基础设施运营商 。Omdia基于对超过200家企业的调研,识别出四大核心市场挑战:ROI与上市周期、数字主权、AI人才缺口和系统性工程复杂度 。 重塑2026市场的五大动态: 动态一:从FLOPS(浮点运算次数)到TTFT(首字延迟):由于企业面临“僵尸GPU”效应(即昂贵的GPU因I/O等待而闲置),盲目囤积算力的预算已被冻结;评估指标正转向首字延迟和向量检索速度。供应商案例研究显示,已取得的成效包括向量索引速度提升12倍,以及在API和算力冗余方面实现高达75%的成本削减。 动态二:顶级云厂商在敏捷性与主权之间寻求平衡: 两种交付范式应运而生:一种是全栈式整体交付(如AWS、华为、GCP、OCI),即将具备公共云级AI能力的集成物理单元直接部署到客户的数据中心;另一种是软硬件解耦,这是一条以软件能力本地化和生态系统驱动硬件为特征的路径。 动态三:计算原生型AI云的升级:机柜功率密度已从2024年的10–15千瓦跃升至2026年的40–250千瓦,工作负载也从概念验证阶段迈向生产级部署。欧洲的Nebius和中国的商汤科技是两个代表性玩家,已经将其商业模式逐渐从裸金属租赁转变为模型即服务(MaaS)。其中,商汤科技还推行了“IaaS + MaaS + 算电协同”的一体化框架,以确保对算力和能源的有效掌控。 动态四:AI工业化的“最后一公里”:最后一公里需要通过长周期的数据治理、遗留系统集成以及特定场景的智能体组装来实现。与此同时,浪潮云采取了重资产AI基础设施与高强度场景化AI产线运营相结合的策略,极大地推动了AI工业化的跨越式发展。 动态五:主权数据工厂的崛起:《欧盟人工智能法案》(EU AI Act)、《数字运营弹性法案》(DORA)及相关合规框架,正推动敏感数据必须保留在物理隔离设施内的要求。这使得G42等区域运营商的角色,跃升为国家级数据的物理守门人。 Omdia云与AI高级首席分析师(Senior Principal Analyst)詹墨磊(Raymond Zhan)表示:"未来的竞争将不再由模型参数或GPU数量定义,而是能源、液冷、芯片、自治软件栈、主权合规和长期资本耐力的综合较量。对于企业客户而言,AI工厂的供应商选择并非 ‘一刀切’的游戏,企业应根据自身稳态业务与创新业务之间的平衡来做出定制化的选择。" 展望未来,Omdia预计2026年和2027年将成为AI工厂发展的关键窗口期,而在未来五年内,区域性及行业性运营将成长为确定性最高的增长板块。
AI工厂
Omdia . 2026-06-01 1057

企业 | 江波龙申请港交所IPO
5月29日,广东深圳存储芯片企业江波龙正式递表港交所。 江波龙成立于1999年,是一家独立品牌半导体存储器厂商,拥有涵盖主控芯片及存储芯片设计、固件开发、系统级封装及测试的垂直整合能力,经营FORESEE、Zilia、雷克沙三个品牌,存储产品组合面向端侧AI及传统消费级、企业级及工规级应用。 根据灼识咨询的资料,以2025年存储产品的收入计,江波龙是全球超过100名市场参与者中第九大存储器厂商、第二大独立半导体存储器厂商,以及中国超过30个市场参与者中第三大存储器厂商、最大的独立存储器厂商。 2025年,江波龙占据全球半导体存储产品市场1.2%的市场份额。 该公司也是少数在B2B及B2C市场均拥有独立品牌的中国公司,并在国际上处于领先地位。其客户群包括戴尔、联想、迈瑞医疗、OPPO、三星、传音、小米等知名企业。江波龙自2022年8月起在A股深交所上市,受益于存储芯片需求旺盛,今年迄今股价已经大涨125%。截至上周五收盘,其最新市值为2332亿元。 ▲江波龙股权架构 招股书显示,2025年江波龙营收为227.66亿元,净利润为14.98亿元。另据江波龙最新季报,其今年第一季度营收为99.09亿元,同比增长132.79%;归母净利润为38.62亿元,同比增长2644.05%,已超过2025年全年的净利润数据。目前,江波龙正在进行AI应用高端存储产品、高性能主控芯片、小容量Flash存储芯片设计、车规级LPDDR5X、高端移动存储用LPDDR5X、ePOP5X产品开发、大容量UFS嵌入式存储、车规级嵌入式/移动存储等研发项目。 年收入超227亿元,净利润近15亿元 2023年、2024年、2025年,江波龙营收分别为101.25亿元、174.63亿元、227.66亿元,净利润分别为-8.37亿元、5.05亿元、14.98亿元,研发费用分别为5.94亿元、9.10亿元、10.48亿元。 ▲2023年~2025年江波龙的营收、净利润、研发支出变化(芯东西制图) 其经调整净利润分别为-6.75亿元、4.51亿元、13.98亿元。 江波龙拥有四大产品线: 嵌入式存储解决方案,将存储器直接集成到AI智能手机、智能穿戴、智能汽车及其他智能设备等电子产品主系统中; 固态硬盘,独立的存储设备,以快速的数据访问速度、可靠性高及易于更换而著称,用于AI服务器、AI电脑、数据中心及其他应用; 移动存储产品,包括U盘、存储卡及便携式固态硬盘,主要支持消费级存储设备、嵌入式AI设备、智能汽车等应用情景的数据传输及备份; 内存条,是搭载DRAM芯片的电路板,用于AI服务器、AI电脑、数据中心及相关应用的临时数据处理及程序执行。 近三年,嵌入式存储为江波龙最大收入支柱,占比超过40%。 来自消费级产品的收入分别占其2023年、2024年、2025年收入的94.7%、92.9%、89.8%,非消费级产品在绝对金额及收入贡献方面均实现显著增长。其各产品线销售量和每GB平均售价如下: 2023年、2024年、2025年,江波龙的毛利率分别为4.7%、15.8%、18.0%,呈逐年改善趋势。 目前江波龙拥有并经营三个品牌:FORESEE (主要服务于B2B市场)、Zilia(主要服务于拉丁美洲B2B市场)、雷克沙(主要服务于高端B2C市场)。 根据灼识咨询的资料,以2025年B2B存储产品收入计,FORESEE在独立存储器品牌中排名第二,市场份额为0.5%。Zilia是江波龙在收购SMART Brazil (SMART Global旗下领先的巴西半导体存储器厂商)后于2023年推出的品牌。以2025年收入计,Zilia是拉丁美洲最大的独立存储器品牌。雷克沙是江波龙于2017年收购的全球领先高端品牌。迄今雷克沙品牌的产品已销往60多个国家及地区。以2025年收入计,雷克沙在全球独立B2C存储器品牌中排名第二,市场份额为3.3%。江波龙的合并财务报表如下: 现金流如下: 自研主控芯片产量超过2.5亿颗,SLC NAND产量超过2亿颗 截至2025年12月31日,江波龙研发团队共1240人,占总员工数的30.7%;拥有610项授权专利,包括218项发明专利、169项软件著作权及13项已注册的集成电路布图设计。 在芯片设计方面,截至2026年4月30日,江波龙自主设计的主控芯片已累计生产超过2.5亿颗,自主设计的SLC NAND芯片已累计生产超过2亿颗。采用其自研SLC NAND芯片的存储产品,已获得以车规级、工规级为主的目标客户的设计批准,目前已投入量产。 该公司已在存储产品价值链的关键领域形成自主能力: (1)主控芯片设计:已自主设计8款主控芯片,其中6款已成功商业化,余下2款正处于商业化过程中,涵盖USB、SD、eMMC、UFS产品以及SSD;2026年3月推出了自主研发的存储处理单元(SPU)主控芯片,旨在为AI时代的智能存储提供动力。 (2)存储芯片设计:专注于SLC NAND Flash及其他小容量存储芯片,已成功流片9款SLC NAND Flash系列存储芯片,并正扩展至其他小容量存储芯片技术,填补主要晶圆IDM从小容量存储市场缩减规模后留下的空白,能够与晶圆IDM进行差异化竞争。 (3)固件开发:产品通常使用自研固件,且各产品线统一固件平台,可实现快速适配;高级缓存(HLC)技术和专为在端侧设备上进行AI推理而设计的智能存储代理iSA,是江波龙为AI时代开发的最新固件级创新技术。 (4)封装及测试能力:苏州工厂具备高端SiP技术及多芯片封装MCP技术(包括堆叠封装),且能够生产16层堆叠存储产品;中山工厂的数据中心存储产品专线集研发和再测试于一体,各产品线的DPPM在50以内;阿蒂巴亚工厂和马瑙斯工厂能够为一系列存储产品进行封装、测试、SMT贴片及组包。 超过66%收入来自境外 江波龙生产工厂的总设计产能、实际产能及利用率如下: 该公司已建立完善的全球布局,2023年、2024年、2025年,其分别有77.1%、71.1%、66.8%的收入来自中国内地以外的地区。 中国内地、中国香港及巴西是其核心创收地区,合计分别占2023年、2024年、2025年总收入的69.0%、74.0%、70.8%。来自五大客户的收入分别占江波龙2023年、2024年、2025年总收入的34.6%、36.8%、29.0%。 与传统IDM不同,江波龙并无晶圆制造设施,而是采取开放灵活的模式,分别向IDM及主控芯片供应商采购存储晶圆及主控芯片。 OSAT合作伙伴(如华泰电子、华天科技及通富微电)亦协助江波龙进行存储产品的封装及测试。2023年、2024年、2025年,江波龙向五大供应商作出的采购额分别占同期采购总额的48.6%、50.0%、52.0%。 结语:AI带飞存储芯片需求,国产存储产品乘风起势 受AI推动存储芯片需求日益增长及中国国内生产规模扩大的推动,半导体存储产品市场有望实现大幅增长。根据灼识咨询的资料,全球存储市场规模于2025年达到2754亿美元,并预计将于2030年达到8756亿美元,CAGR为26.0%。虽然中国市场占比约30%,但其目前国内生产严重滞后,国产化率低于30%。 江波龙在B2B及B2C市场均占有一席之地,其消费级产品专为智能手机、平板电脑及可穿戴设备等消费电子产品而设计,企业级产品服务于企业服务器及数据中心,工规级产品面向工业自动化设备、工业PC、汽车及广泛的工业应用。该公司发布了首款自主设计的UFS4.1主控芯片WM7400及SPU主控芯片WM8500,两者均适用于端侧AI设备;亦迅速推出小尺寸产品(如mSSD、超薄ePOP5x及ePOP4x以及超小尺寸eMMC产品),以满足端侧AI设备对极致性能及紧凑尺寸的苛刻要求,使其能把握市场的快速增长。
江波龙
芯东西 . 2026-06-01 2359

企业 | SK海力士发生火灾
据韩联社报道,当地时间6月1日上午10点32分左右,存储芯片大厂SK海力士清州第四园区连接M15和M15X工厂的6楼燃气室发生火灾。 虽然喷水灭火系统启动后,火势立即得到控制,但少量(5 ppm)对人体有毒的氟化物泄漏出来,导致7人受伤被送往附属医院。 报道称,SK海力士代表称,当时现场有10人在工作。其中5人抱怨眼睛刺激,另外2人无异常症状,但均处于燃气泄漏冲击区内,被送往医院接受准确检查。 一名消防部门官员表示:“身穿防护服的消防员正在内部调查具体情况”,并补充说:“伤者人数可能会增加。” 泄漏发生后,SK海力士立即疏散了M15和M15X工厂的全部3600名员工,以应对任何突发情况。 一位韩国海力士官员表示:“我们正在操作环境净化设备并开展防灾工作”,并补充道,“一旦完成如空气质量测量等安全检查,我们计划将员工遣返。” 他继续说:“设备运行没有问题,因此不会中断生产。”并补充道:“我们怀疑问题发生在天然气管道,并将调查具体情况。”
SK海力士
芯智讯 . 2026-06-01 931

涨价 | MCU涨价潮扩散,新唐跟进
新唐与欧洲IDM大厂意法半导体(STMicroelectronics)近日相继向客户发出涨价通知,显示半导体供应链成本压力持续向终端传导,MCU产业正式进入新一轮价格上行周期。 业内人士分析,主要原因是AI服务器、数据中心及高速网络通信需求持续扩张,带动成熟工艺产能供给趋紧,加上NOR Flash、封装测试(OSAT)及原材料成本持续攀升,MCU市场涨价趋势进一步确立。 新唐于5月29日发布产品价格调整通知称,受全球市场环境变化及供应链通胀压力影响,原材料、存储器及封装测试成本持续上涨。 尽管该公司已通过提升运营效率吸收部分成本,但仍决定自7月1日起调整部分产品线价格,实际涨幅与产品项目将由业务及渠道伙伴另行通知客户。 意法半导体则于5月28日通知客户,受原材料、运输及人工成本上升影响,将自6月28日起调涨部分产品价格。 意法半导体指出,该公司年初已针对部分产品实施价格调整,此次进一步扩大至此前未纳入调整范围的产品,以反映成本压力。 MCU涨价潮自今年初即已展开。大陆MCU厂商中微半导体于1月率先宣布MCU与NOR Flash产品调涨15%至50%;其后芯海科技、国民技术、小华半导体等厂商陆续跟进,涨幅多落在10%至20%之间。 中国台湾厂商方面,应广1月底率先发布涨价通知,雅特力-KY则因NOR Flash KGD成本大幅上升,针对部分M4系列产品实施10%至20%的调价机制。 供应链人士分析,此次涨价与过去景气周期导致的短期供需失衡不同,背后主要来自结构性供给压力。 半导体供应链资源向高毛利AI产品集中,成熟工艺产能供给相对紧张。 同时,NOR Flash价格自2025年底起快速攀升,进一步带动KGD、嵌入式存储及相关控制芯片成本上涨。 由于MCU产品多需搭配NOR Flash作为代码与固件存储空间,因此存储器涨价效应已开始向MCU供应链传导,成为本轮MCU调价的重要推动力之一。 在AI需求持续强劲、成熟工艺产能供给仍偏紧的情况下,市场预计MCU、电源管理IC及各类控制芯片价格涨势有望延续至2027年,工业控制、车载电子、消费电子及网络通信设备厂商后续恐面临新一轮成本转嫁压力。
涨价
芯查查资讯 . 2026-06-01 2478

2026 年端侧 AI 芯片格局:手机、PC、汽车与机器人谁先跑出来?
重点内容速览: 1. 端侧AI背后的驱动力是什么? 2. 手机移动端:消费级端侧AI的主战场 3. PC 与计算端:生产力场景的新竞赛 4. 汽车与机器人:端侧 AI 的高价值场景 5. IoT与边缘计算:中国厂商的主场 6. 端侧AI 的真正门槛:不是算力,而是系统能力 过去两年,AI 的主舞台在云端。大模型训练、推理集群、HBM、CoWos、先进制程,构成了半导体产业最显性的增长主线。但进入 2026 年之后,另一个变化正在加速发生:AI 正在从数据中心走向手机、PC、汽车、机器人和各类 IoT 终端。 这不是简单的“把大模型塞进设备里”,而是一次计算架构的迁移。端侧 AI 的价值,不只是在于隐私保护、低延迟、离线可用和推理成本下降,更重要的是,它让 AI 从“被调用的云服务”变成“随时在设备本地运行的能力”。当 AI 完成本地能力,SoC 的竞争逻辑也随之改变。 过去评价一颗 SoC,核心指标是 CPU、GPU、制程、功耗和基带。现在,NPU 算力、内存带宽、模型压缩能力、软件栈成熟度、多模态处理能力,以及与操作系统和应用生态的结合深度,正在成为新的胜负手。 2026 年将是端侧 AI 从概念验证走向规模落地的关键窗口。虽然存储价格上涨、端侧模型体验不稳定、开发者适配成本较高等因素仍会影响节奏,但大方向已经清晰:未来的 AI 不会只存在于云端,它会被分布到每一类设备中。据弗若斯特·沙利文预测,全球端侧市场将从2025年的3219亿元,跃升至2029年的1.2万亿元,复合年均增长率(CAGR)高达39.6%。 手机移动端:消费级端侧AI的主战场 手机是端侧AI最重要的入口,竞争也最为激烈。原因很简单,它是用户使用最高频的设备;有最大的出货量,全球每年出货超过12亿部;也有最完整的传感器体系。语音、图像、相机、位置、支付、社交、办公,几乎所有个人数据都在手机上发生。谁能在手机端把 AI 做成系统级能力,谁就掌握了消费级终端 AI 的第一入口。 高通:全平台生态布局 高通在安卓旗舰市场的统治地位依然稳固。2025年发布的骁龙8至尊版Gen 5(Snapdragon 8 Elite Gen 5)是其目前最强移动端芯片,搭载第三代Oryon自研 CPU架构,Hexagon NPU 算力达到75TOPS,能在本地流畅运行Llama3 8B这个量级的大模型,AI语音识别响应速度提升了约3倍。 但高通的野心不只是"手机 NPU 最快"。他们真正押注的是跨设备的AI生态:手机、PC、XR眼镜、智能手表、汽车、机器人——所有骁龙平台的设备联动,在本地网络里协同完成Agentic任务。用高通CEO安蒙的话来说:"AI的竞争将在边缘端决出胜负。" 联发科:全大核架构 + AI 算力下沉 联发科在过去两年完成了一次品牌升级——天玑9500(Dimensity 9500)搭载第九代NPU990,算力逼近100TOPS,首次在安卓平台实现了实时端侧文生图。 更值得关注的是联发科的"AI下沉"战略:天玑8400、8450、8500等中端芯片已率先支持Agentic AI,让2000–3000元价位段的手机也能用上智能体功能。只有当 Agentic AI、多模态识别、本地文生图等能力进入 2000 元至 3000 元价位段,端侧 AI 才可能从“旗舰卖点”变成“普遍体验”。这也是联发科在中国安卓市场值得关注的地方。 三星:Exynos 的2nm回归 三星自研的Exynos 2600是首款采用三星2nm GAA制程的手机SoC,搭载于部分地区版本的Galaxy S26系列。这款芯片对三星来说意义重大——它是三星对高端 SoC 主导权的一次重新争夺。先进制程、自研架构和 Galaxy 终端生态,是三星必须重新打通的闭环。但 Exynos 过去几年在性能、功耗和市场口碑上的波动,也意味着它需要用连续几代产品证明稳定性,而不是只靠单代参数反转预期。 华为海思:自主路线的新章 华为麒麟芯片选择了一条完全不同的路。受制于出口管制,华为无法使用台积电先进制程,但2026年5月正式发布的"韬(τ)定律"给出了一种替代路线:通过逻辑折叠(Logic Folding)技术,在不缩小晶体管物理尺寸的前提下,将电路垂直堆叠在多层晶圆上,实现密度提升。 搭载这一技术的麒麟2026芯片,晶体管密度比上代提升约55%,能效提升41%,目标是在2031年达到等效台积电1.4nm水平的密度。这是中国第一次在全球半导体领域提出系统性演进新原则,它的产业意义不只在一颗麒麟芯片,而在于中国半导体企业开始系统性探索“后摩尔时代”的替代路径。 手机端的竞争已经不再是单点算力竞赛,而是“芯片+操作系统+应用生态+模型能力”的综合战。苹果、高通、联发科、三星和华为,分别代表了不同的组织方式:封闭生态、平台生态、性价比普及、垂直整合,以及自主替代。 图:主流移动端SoC对比(数据来源:各公司官网,芯查查) PC 与计算端:生产力场景的新竞赛 如果说手机决定端侧 AI 的普及速度,PC 则决定的是端侧 AI 的生产力价值。 在手机上,AI 摘要、修图、语音助手往往是体验增强;但在 PC 上,本地大模型、会议转写、代码辅助、离线文档处理、企业知识库检索,直接对应办公效率和数据安全。PC 是端侧 AI 从“好玩”,走向“有用”的关键场景。 NVIDIA 与微软在 5 月 30 日披露,计划在中国台北 Computex 与微软 Build 上联合发布首批以 NVIDIA 芯片作为主处理器的 Windows 电脑。这意味着 NVIDIA 正从 AI 加速卡进一步切入端侧/客户端 SoC,若正式落地,将把 Arm PC、端侧 AI Agent 与本地推理进一步绑定到新的芯片平台生态。 高通 Snapdragon X2 Elite Extreme(2026 年上半年)是目前 AI PC 赛道的性能标杆:3nm制程,18核Oryon CPU,NPU达到80TOPS,内存带宽最高228 GB/s,并将最大可寻址内存扩展到128GB。和第一代Snapdragon X Elite相比,NPU性能提升78%,多线程性能提升25%,同时功耗降低43%。也就是说,它的核心卖点不是极限性能,而是在较低功耗下提供足够强的 CPU、NPU 和续航表现。如果 Windows on Arm 的应用兼容性继续改善,高通有机会在轻薄本和商务移动办公市场持续扩大存在感。 苹果 M5 系列走的是另一条路:通过在GPU每个核心内嵌Neural Accelerator,M5 Max的AI峰值算力比M4提升超4倍,546 GB/s的内存带宽让本地运行70B量级大模型成为可能——这是目前消费级设备里最强的端侧大模型运行能力。苹果的封闭生态在这里成了优势:Core ML统一API让开发者几乎不需要操心NPU适配问题。 英特尔Core Ultra Series3(Panther Lake)于 2025 年 10 月公布架构,2026 年 1 月随 CES 2026 正式进入市场。该芯片采用了英特尔 18A 工艺、多芯粒架构、最高 16 核 CPU、最多 12 Xe 核显,其总算力可达180TOPS。据芯查查了解,目前采用 Core Ultra Series3平台的 OEM 厂商包括联想、惠普、微星和华硕等。 AMD Ryzen AI Max 400/300 系列(2026年1月)则走双线策略:AI Max 400配合40CU的强力集成GPU,瞄准创意专业人士;AI Max 300从700欧元左右起价,把AI PC推向主流消费市场。XDNA 2架构的50 TOPS NPU在大参数量模型推理上具有高带宽内存协同优势,适合AI开发者本地调试大模型。 总的来看,PC端的竞争逻辑是:高通和苹果以Arm架构拼效率,Intel和AMD以x86生态拼兼容性和软件深度。两条路线各有受众,短期内不会分出绝对胜负。 图:主流端侧PC芯片对比(数据来源:各公司官网、芯查查) 汽车与机器人:端侧 AI 的高价值场景 汽车和机器人是端侧 AI 最复杂、也是商业价值最高的场景。它们与手机、PC 的最大不同在于:这里的 AI 不只是交互体验,而是感知、决策和控制系统的一部分。 自动驾驶芯片需要实时性、安全冗余、车规认证和长生命周期供货。NVIDIA Drive Orin 已经量产,Thor 则面向更高阶的集中式计算架构。英伟达的优势在于,它把数据中心和机器人领域的软件生态延伸到汽车端,形成从训练、仿真到部署的完整闭环。 高通的汽车路线更偏“智能座舱 + 辅助驾驶 + 连接能力”的融合。它不一定在单颗智驾芯片算力上追求极限,但在座舱、通信、娱乐和多屏交互方面具备天然优势。随着座舱和智驾域逐步融合,高通的系统级平台能力会继续放大。 中国本土企业的机会在于速度、成本和场景协同。地平线、黑芝麻智能、芯擎科技等厂商,依托国内新能源汽车市场的快速迭代,正在形成自己的客户基础和工具链生态。国内车企的开发节奏快、场景复杂、成本敏感,这反而给本土芯片公司提供了难得的训练场。 机器人则是另一个正在打开的市场。与汽车相比,机器人对芯片的要求更分散:人形机器人需要高算力和多传感器融合,四足机器人强调实时控制和环境感知,扫地机器人则更看重成本、功耗和视觉算法。瑞芯微、全志、地平线等公司能够切入不同层级的机器人市场,关键就在于它们能把芯片、算法和客户场景绑定得更紧。 汽车和机器人共同说明了一点:端侧 AI 越往高价值场景走,越不是通用芯片单独取胜,而是“芯片 + 工具链 + 算法 + 场景数据 + 客户联合开发”的系统竞争。 IoT与边缘计算:中国厂商的主场 IoT边缘侧是中国芯片厂商最密集、最有优势的战场。这个领域对"极致性价比""垂直场景适配"和"低功耗部署"的要求,恰好是中国厂商的传统强项。 芯查查整理了几家值得重点关注的厂商: 瑞芯微(Rockchip)的 RK3588 是目前 AIoT 领域的标杆产品,6 TOPS NPU配合强大的CPU/GPU,以极高的性价比横扫NVR、工业网关、边缘服务器等场景;2025年发布的 RK3576则以更低功耗瞄准中端AIoT市场。 晶晨股份(Amlogic)深耕流媒体盒子、智能电视等消费IoT场景,在全球流媒体芯片市场份额领先,正向AI图像处理升级迭代。 爱芯元智(Axera)专注于AI视觉芯片,主要面向端侧/边缘侧视觉应用,强项在于多路视频分析、暗光成像、Transformer 视觉模型部署等,例如,AX650N等产品主打安防IPC和智能摄像头,在低功耗端侧推理上表现突出,已进入海康威视、大华等头部安防品牌的供应链。 乐鑫科技(Espressif)的ESP32系列芯片几乎是全球Wi-Fi +蓝牙物联网设备的标准配置,面向对成本极度敏感的低端IoT市场拥有近乎垄断的地位,正在向更高算力的AIoT芯片延伸。 此外,星宸科技、全志科技、北京君正等公司,也都在各自细分市场形成稳定客户基础。它们的特点不是横扫所有场景,而是在一个个垂直市场里做深、做稳、做便宜。 这类市场看似不如 AI GPU 和 HBM 那样耀眼,却可能是端侧 AI 最早规模化变现的地方。原因很现实:摄像头、网关、门锁、机器人、工业终端、家电设备,都需要本地识别、本地决策和低成本部署。云端 AI 再强,也无法替代这些场景对实时性、成本和离线能力的要求。 端侧 AI 的真正门槛:不是算力,而是系统能力 讨论端侧 AI,最容易陷入 TOPS 军备竞赛。但 TOPS 只是纸面指标,不能直接等同于用户体验。真正重要的是在有限功耗、有限内存、有限散热条件下,设备能不能稳定运行有用的模型,并且被开发者和应用真正调用起来。 因此,端侧 AI 的竞争会围绕三个维度展开。 第一是算力效率。手机有功耗墙,PC 有续航约束,汽车有安全冗余,IoT 有极低成本和待机要求。端侧 AI 不是把算力堆得越高越好,而是在每一瓦功耗里跑出足够有价值的推理能力。 第二是软件生态。苹果有 Core ML,高通有 AI Stack,英特尔有 OpenVINO,英伟达有 CUDA 和 Isaac。芯片厂商如果只提供硬件,不解决模型部署、算子优化、开发工具和系统调用问题,就很难让开发者真正用起来。这也是中国端侧 AI 芯片公司未来必须补强的部分。 第三是垂直场景适配。汽车要功能安全认证,安防要多路视频和暗光识别,工业要长期稳定和抗干扰,医疗要数据合规。越到行业深水区,通用 AI 芯片越不够用,快速理解客户场景、共同定义产品,才是形成护城河的关键。 2026 年的端侧 AI,不是云端 AI 的缩小版,而是一次新的产业分工。云端负责大模型训练、复杂推理和跨场景知识能力,端侧负责实时响应、隐私保护、个性化执行和低成本常态化运行。未来主流架构大概率不是纯云端,也不是纯端侧,而是端云协同。 手机会推动端侧 AI 普及,PC 会验证生产力价值,汽车和机器人会打开高单价市场,IoT 和边缘计算会带来最广泛的碎片化落地。不同场景会产生不同赢家,没有一家公司能够通吃所有市场。 端侧 AI 的本质,不是让每台设备都拥有一个“小号 ChatGPT”,而是让智能成为终端设备的基础能力。谁能在算力、效率、生态和场景之间找到最优解,谁就能在这场从云到端的迁移中占据更长期的位置。
端侧AI
芯查查资讯 . 2026-06-01 1 1 9317
市场 | 黄仁勋将发布Windows专用处理器:20核CPU+6144核集显怪兽来了!
距离台北国际电脑展正式揭幕仅剩一周(6月2-6月5日),NVIDIA和微软在官方X账号同步发布了一条极具暗示性的神秘预告,内容为"PC的新时代"和一组地理坐标"25.0528,121.5990"。 经外界查证,该坐标直指中国台北南港展览馆附近的台北流行音乐中心,应该是发布会场地。 这项高调的同步造势瞬间点燃了全球科技圈的热情。业界普遍预测,NVIDIA筹备已久,专为Windows平台打造的旗舰级Arm架构移动处理器N1X(及其轻量版N1),即将在本次Computex上正式亮相。 更有消息称,这款芯片将成为微软下一代Surface系列旗舰笔电的核心处理器。 根据目前流出的详细规格,N1X将采用台积电最先进的3nm制程技术。在CPU部分,它采用了20核心的Armbig.LITTLE混合架构,包含10个高性能核心与10个节能核心,并配备32MB的共享末级缓存。 不过,这款芯片最令人震撼的还是其图形与AI运算能力。N1X直接整合了基于NVIDIA最新Blackwell架构的内置显卡,内建高达6144个CUDA核心,图形性能传闻可媲美独立显卡RTX 5060Ti甚至RTX 5070级别。 采用统一内存架构,最高支持128GBLPDDR5X内存,其综合运算实力将直接对标苹果M5 Pro及AMD Ryzen AI Max400等顶级移动芯片。 微软对此次合作的重视程度非同寻常。除了官方账号同步预热外,Windows与Surface业务主管Pavan Davuluri也在个人社交平台发文,明确表示这次发布的并非"全新操作系统版本",同时上传了一张暗光下隐约露出机身弧形边缘的产品图。 种种迹象表明,微软正在与NVIDIA深度合作,为其高端Surface硬件产品铺路,包括传闻中的Surface Laptop Studio 3或新一代Surface Pro旗舰型号。 在此之前,Windows on Arm生态圈几乎完全依赖高通的骁龙X系列芯片。而NVIDIA N1X的加入,不仅能提供更为出色的本地AI运算能力,更能彻底补足Arm笔电过去在游戏以及3D渲染、4K视频剪辑等重度影音创作领域的性能短板。 近日,已有多家科技媒体从各大厂商流出的宣传文件与系统登录页面中发现了N1X的踪迹。戴尔高端XPS系列、联想Legion游戏本系列以及华硕专为创作者打造的Pro Art系列,都已准备好相应的N1/N1X机型,并有望在下周的展览中同步亮相。 此次NVIDIA正式从GPU与AI加速器领域跨足PC主处理器市场,无疑将打破由Intel与AMD主导了数十年的传统x86架构市场格局。 随着AI时代的全面到来,这场围绕下一代PC计算平台的争夺战才刚刚拉开序幕。
CPU
硬件世界 . 2026-06-01 1512
- 1
- 20
- 21
- 22
- 23
- 24
- 500