
技术 | IO-Link小型化设计瓶颈?功耗与散热这样搞定
IO-Link广泛应用于工业自动化各大领域。工厂部分区域环境温度偏高,致使各类模块与电子元件长期处于严苛的工作状态。随着工业4.0持续推进,智能功能不断向边缘端下沉,设备尺寸要求也愈发严苛。想要实现更小的外形尺寸,散热问题便成为设计中必须重点考量的环节。 小型化设计与IO密度提升 工业4.0推动智能向边缘端延伸,IO-Link的应用场景不断拓展,设备安装空间也日趋紧凑。这不仅对每一款IO-Link传感器与执行器的体积和性能提出挑战,也间接提高了IO-Link主站网关在尺寸与接口密度上的设计要求。 这类网关通常集成4路、8路或16路IO-Link主端口,单通道驱动负载电流可达500mA,而整板PCB面积仅略大于普通智能手机。由此可见,功耗分布是核心设计要点,直接决定模块的发热量以及核心电子器件的运行可靠性。 功耗计算 借助器件数据手册中的公开参数,即可快速计算芯片的理论功耗: 根据IO-Link规范,单通道最大负载电流为500mA。计算功耗时,可查询C/Q驱动器的导通电阻,或读取500mA电流工况下的压降数值。 以MAX14819A为例,其最大导通电阻为2.2Ω。 结合上述公式,即可估算出MAX14819A单通道的最大功耗: 这类简易计算可作为产品选型对比的初步依据。下文将结合实测数据,对比实际功耗与理论计算值。 实际案例:MAX14819A 下面以ADI双路IO-Link主站MAX14819A为例,通过实测数据来分析实际功耗与散热表现。 本次测量基于ADI的MAXREFDES165 IO-Link主站参考设计,加载电流设为500mA。 测量每个通道上存在的电压(VCQ),使用已知负载(RLoad = 47.7Ω) MAX14819A = 23.27V 测量电源电压(VS) MAX14819A = 23.81V 计算输出电流(I = VCQ/RLoad ) MAX14819A = 23.27V / 47.7Ω = 488mA 根据测得的电压降(VDrop = VS – VCQ)和输出电流,计算功耗 MAX14819A = (23.81V – 23.27V) x 488mA = 264mW(每通道) 实测结果表明,MAX14819A实际功耗偏低,与典型功耗指标高度吻合。 通过热成像仪可直观观测发热情况:测量持续约10分钟后,MAX14819A核心区域(图中白色区域)温度升至40℃。本次测量期间的环境温度为25℃,温升处于合理范围: MAX14819A:∆T = +15℃ 图1:MAX14819A MAX14819A最高工作温度为125℃。实测数据证明,即便所有通道满负载运行,该芯片也可在工业级高温环境下稳定工作。 有效控制发热量,能够顺应IO-Link技术的普及趋势,助力设备实现小型化,并进一步强化边缘端智能能力。 关键要点 功耗是IO-Link产品设计的关键要素。IO-Link网关大多部署在工厂边缘区域,长期面临高温工况。若设备内部器件发热量过大,不仅会限制产品小型化设计,还需额外加装散热器等配件,推高整体成本。 ADI的IO-Link解决方案,如MAX14819A,充分适配严苛的设计要求,能够将功耗与发热量控制在更低水平。 开展新项目设计前,建议先完成功耗测算与实测验证,既能提升效率、规避问题,也能选出最优方案。
ADI
亚德诺半导体 . 2026-07-16 1092
市场 | 晶圆代工和材料成本上涨,推动显示驱动芯片价格走高
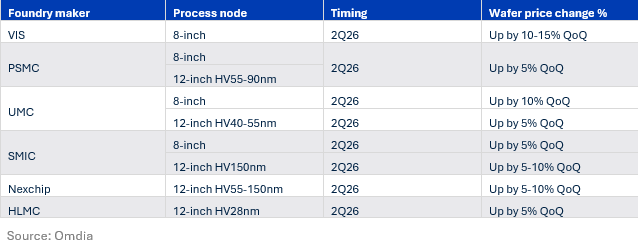
随着晶圆代工产能趋紧以及上游半导体制造成本持续上升,显示驱动芯片(DDIC,Display Driver IC)价格正在上涨。Omdia预计2026年下半年市场需求将弱于上半年,但持续增加的成本压力仍将支撑DDIC价格进一步上涨。 AI相关应用持续带动电源管理芯片(PMIC)和存储器(Memory)需求快速增长,中国台湾地区和韩国晶圆代工厂正减少用于电视、显示器、笔记本电脑DDIC以及触控与显示驱动集成芯片(TDDI)的产能配置。 虽然全球总产能仍然过剩,对于不受地缘政治因素限制的部分大尺寸DDIC订单正逐步由中国台湾地区8英寸晶圆厂向中国大陆12英寸晶圆厂转移,但是订单和生产转移需要时间,这一转变正导致DDIC在一些应用领域的产能暂时趋紧。与此同时,上游半导体制造所需的关键原材料价格也呈现明显上涨趋势。用于封装和芯片制造的黄金、白银、铜等关键金属价格大幅攀升,推高了晶圆代工、封装及测试等环节的整体成本。 因此,世界先进(VIS)、力积电(PSMC)和中芯国际(SMIC)等晶圆代工厂于2026年第一季度将8英寸晶圆厂的晶圆代工价格环比上调5%–10%。与此同时,力积电也于2026年第一季度上调了12英寸晶圆厂HV 90nm(高压90纳米)制程的晶圆代工价格。进入2026年第二季度,晶圆代工价格继续上涨,并有更多晶圆代工厂加入涨价行列。预计2026年下半年部分晶圆代工价格或将继续上涨。 表1:2026年第二季度各供应商价格变动情况 晶圆代工是显示驱动芯片(DDIC)成本中占比最高的环节,占总成本的60%–70%,其中硅片(wafer)成本约占40%。这意味着,晶圆代工价格的任何上涨都会直接影响 DDIC 厂商的成本结构。 对于IC 设计厂商(Design House)而言,晶圆代工成本上升为其上调 DDIC 价格提供了充分依据,以反映不断增加的生产成本。 智能手机和平板电脑TDDI已率先受到影响,价格于2026年第二季度上涨,主要原因是HV 90nm制程产能减少,晶圆厂涨价。其中,高清(HD)智能手机 TDDI价格在2026年第二季度上涨15%–30%,预计2026年下半年仍将继续走高。 与此同时笔记本电脑 DDIC 也受到影响。由于该市场主要由中国台湾地区的 IC 设计厂商主导2026年第二季度笔记本电脑 DDIC 价格已上涨5%–15%。 显示器面板DDIC价格有机会在2026年第三季度迎来上涨,而电视 DDIC价格预计持平。 Omdia 高级分析师蒋与杨(Queenie Jiang)表示:“本轮DDIC涨价的主要驱动力并非需求增长,而是供应收紧。 虽然预计2026年下半年市场需求将弱于上半年,但持续攀升的成本和收紧的产能仍将推动 DDIC 价格上涨,以反映不断增加的生产成本。”
晶圆代工
Omdia . 2026-07-16 931

应用 | 超越 224G:展望共封装铜缆的未来
为了满足 AI 数据中心对更快、更密集互连系统的持续需求,工程师们正在规划超越 224G 的速度。虽然可插拔光学技术仍适用于长距离连接,但共封装铜缆凭借功耗更小、延迟更低、整体系统成本更优等显著优势,可为较短距离传输提供极具吸引力的替代方案。 由于 224G 技术刚刚开始在更广泛的市场中部署,未来的战略发展路径依然充满无限可能。对于任何正在思考共封装铜缆未来发展的系统架构师来说,理解每一种物理层路径的利弊权衡,是至关重要的第一步。 AI数据中心 超越 224G 的三条竞争路径 选择合适的物理层,归根结底在于在模拟信道的难度与数字信号处理的复杂度和功耗之间取得平衡。尽管业界已经讨论过 PAM-8,但工程师普遍认为其复杂度过高,难以实际落地。这样一来,就剩下三条主要的竞争路径:336G PAM-4、448G PAM-6 和 448G PAM-4。 336G PAM-4 选择 336G PAM-4 选项意味着信道目标更易实现,其奈奎斯特频率较低,约为 84 GHz。一些超大规模运营商将 336G 路径视为一种务实、渐进的步骤,因为它采用成熟的编解码技术。 然而,与 448G 方案相比,336G PAM-4 方案的每通道总吞吐量更低。主要缺点在于,336G PAM-4 可能只是一个临时解决方案,不久的将来仍需进一步迁移和重新设计。 448G PAM-6 目前,PAM-6 调制方案是实现 448G 数据传输率最实用的方式。PAM-6 方法可规避超过 110 GHz 的极端奈奎斯特频段,从现有 224Gbps PAM-4 设计完成技术过渡,工程实现难度更低。 与此同时,由于 448G PAM-6 采用非 2 的幂次方映射,因此对信噪比 SNR 的要求更为严格,且可能导致互操作性难题。由于 PAM-6 将六个幅度电平压缩到相同的电压摆幅内,信号眼图张开度会显著变小。这使得信号在整个信道内容易受到串扰、抖动和非线性失真的影响。 448G PAM-4 448G PAM-4 路径是实现光学等效,且符号映射最简单的一种理想方式。如果工程师能够构建出可量产的传输信道,PAM-4 将有望实现最佳的每比特成本。 要达到这一里程碑,需要对芯片布局进行彻底重新设计,以克服约 112 GHz 这一高难度的奈奎斯特频率难题。业界的目标是在不增加表面粗糙度或焊盘清洁度新限制的前提下,达到 112 GHz 目标。虽然 PAM-4 信号本身在数字域中处理起来更简单、更干净,但对于硬件开发人员而言,生成所需的模拟频率要困难得多。 112 GHz 信道的物理现实 将奈奎斯特基本频率提升至 112 GHz,会对物理互连系统和材料的信号完整性造成巨大压力。要达到这样的速度,就必须仔细权衡可接受的 SNR,并避免过度依赖功耗巨大的数字信号处理(DSP)。 走线和转接板损耗 为了在 112 GHz 频率下保持信号完整,电路板需要采用超平滑的铜走线。传统较粗糙的铜会迫使高频信号在微小的凸起上传输,这会大幅增加传输线上的插入损耗。由于超平滑铜会增加电路板分层的风险,制造商通常依赖专用粘合膜来固定走线,同时确保不降低信号质量。 在极端频率下保持信号完整性,还迫使人们转为使用具有更低损耗因子的介电材料。工程师通常采用混合层叠结构,将特氟龙基材料与传统的玻璃纤维结合在一起,以便在低损耗特性和所需的机械稳定性之间取得平衡。 连接器和电缆损耗预算 接触件几何形状或介电转换处微小的阻抗失配都会引起明显的反射,从而干扰高速信号。设计人员必须找出并消除每一个可能的损耗来源。清理信号路径通常意味着优化连接器架构并尽量减少对配接口,以减少信号衰减。 均衡和热权衡 先进的数字信号处理技术可以通过发送端预加重和接收端均衡来补偿部分信道失真。但依赖更重的处理负载会增加芯片功耗并提高热密度,从而给系统级散热带来复杂的挑战。 当增加的功耗和延迟导致总体拥有成本高于竞品光学解决方案时,高强度的数字信号处理方案便不再具备实用价值。当功耗负担过高时,架构师必须转而依靠更加干净的物理信道。 制造良率风险 成功的实验室演示与可量产的传输信道之间的差别,归根结底在于严格的过程控制。在极端频率下,每一个冲压和模塑特性的公差范围都会变得极其严苛。装配过程中的微小变化,例如基板翘曲,都会缩小 SNR 裕度,并危及大规模生产的良率。 由于裕量更加紧张,即使接触件几何形状或基板平整度上存在微小的制造偏差,也可能导致信道不符合规格。微小的装配公差很快就会在制造车间里转化为显著的良率损失。 一句话理解:112 GHz 不只是“信号跑得更快”,而是把材料、几何结构、阻抗控制、散热能力和制造一致性同时推向极限。 共封装铜缆:生态系统协同与市场应用 将高频铜互连从实验室推向数据中心机架,关键在于整个制造生态系统的严格协同。最终,在这三种场景中,哪种能率先以可接受的成本和功耗指标,实现满足目标奈奎斯特频率、可量产的传输信道,才能成为市场标准。 OIF 和 IEEE 等组织负责指导互操作性测试,但对于下一代共封装铜缆技术,目前尚无明确标准。硅 SerDes 供应商将最终决定可用的调制方案,并主导可行部署的时间表。 当某家大型数据中心运营商或交换机供应商集成一种解决方案,为行业其他厂商树立事实标准时,广泛的超大规模应用就可能发生。 在三种场景中,如果 448G PAM-6 在互操作性上遇到困难,或者 448G PAM-4 在 112 GHz 奈奎斯特频率下被证明制造难度过高,系统架构师将需要分阶段迁移策略。在这种情况下,336G PAM-4 将成为业界最有可能的备用路径。 面向共封装铜缆未来的扩展解决方案 系统架构师需要在满足当下实际硬件需求的同时,兼顾未来的发展需求。Molex 莫仕的策略依托为企业级应用生产数百万个近 ASIC 互连产品积累的制造经验,侧重于对现有 Impress 平台进行迭代和优化。 为支持最有可能的近期发展路径,Molex 莫仕将制造用于 336G PAM-4 和 448G PAM-6 链路的演示套件和经验证的评估板。与此同时,工程师们正在积极测试超低损耗材料和先进的微型连接器几何结构,以实现 448G 的光学目标。 Molex 莫仕还将差动信号线对数量翻倍,以满足交换机市场与 GPU 市场的不同需求。当设计方案仍然需要光学器件时,Molex 莫仕将继续通过 ELSFP 互连系统等核心解决方案,为更广泛的生态系统提供支持。这些组件可在铜缆和光学两种路径上实现可靠的集成。 为做出恰当的选择,请了解 Molex 莫仕共封装铜缆解决方案如何提供对下一代数据中心架构至关重要的可靠性能与制造规模。 未来数据中心 结语 224G 之后的共封装铜缆演进,并不存在一个简单直接的标准答案。336G PAM-4、448G PAM-6 与 448G PAM-4,各自代表了不同的工程取舍:更稳妥的过渡、相对现实的折中,或更理想但更具挑战的目标路径。 真正决定哪条路线成为主流的,不只是理论性能,而是可制造性、互操作性、功耗、热设计与市场采纳速度的综合结果。对系统架构师而言,最重要的是为多种可能性提前做好技术准备。
Molex
Molex莫仕连接器 . 2026-07-16 1232

方案 | 意法半导体 × 睿研智控:高精度协作机器人灵巧手
人形机器人正在重塑工厂生产流程 在现代化工厂和仓储物流中,机器人再也不只是搬运重物或在不同点位间转运托盘,越来越多的机器人开始接手以往交由人类手工完成的最精细、要求最高的生产作业。机器人企业睿研智控开发出了仿人灵巧手,可替代人类操作员在危险的环境中作业,同时还能满足工业制造对作业速度和精度的要求。每只灵巧手的核心是一个采用意法半导体芯片设计的小巧的“电子神经系统”,赋予机器人精细操控的能力,与人类一起安全、精准地协同作业。 挑战 研发仿人形灵巧手,可以安全接手工厂和仓库中的精细、高精度手工作业 将多轴电机控制、感知和保护三种功能全都集成到比手掌还要小的6×6厘米电路板内 在紧凑的机械结构中,提供强劲的仿人持握力,而不产生过多的热量,也无需大型散热装置 在恶劣的工业环境中可靠、长时间作业,可与人类协同工作 解决方案 两片STM32微控制器可并行控制6个电机,执行手部6个关节的运动 采用先进的STM32定时器与高精度ADC模数转换器实现电机控制的高度同步,持续反馈位置与力控信息 意法半导体电机驱动芯片,提供更高的额定电压的同时提供更大的驱动电流,保障电机更高的额定功率。更低的导通阻抗压低了长时间工作产生的热量,仅需被动散热,给PCB和机械结构设计提供更大的空间 意法半导体的电源管理芯片,包括DC-DC控制器,低压N-MOSFET,LDO,实现多级降压。更高的开关频率保障了大电流的降压效率,同时更低的噪声保障后级更高的电机电流采样精度 使用意法半导体瞬态电压抑制器(TVS)保护紧凑的电子系统 影响 危险或重复性工作实现自动化,提高工人的劳动安全,同时解放劳动力去做更有价值的工作 在劳动力短缺、需求高峰期或突发事件时,帮助工厂维持连续生产,运营活动不中断 打造灵巧、敏捷的灵巧手 要在工业自动化领域真正发挥实用价值,人形灵巧手必须能像人类手掌那样灵巧,在抓取螺钉、玻璃瓶等不同物品时,能够根据不同的形状、重量与材质,灵活地调整握持动作和力度。睿研智控攻克重重挑战,终于将这一设想变为现实,在一块可置于掌心的6×6厘米的六层印刷电路板上,成功地集成了完整的灵巧手控制系统。STM32微控制器是系统的核心控制器,同步协调多达六个关节,执行六个自由度的运动。同时,来自意法半导体的多款高精度模数转换器连续不断地采集传感器数据,精准感知手指位置与抓握力度。 田波先生睿研智控CEO 我们这款六自由度灵巧手,超过90%的芯片来自于意法半导体。 功率增大时如何有效散热? 在灵巧手内部,空间和温度的重要性丝毫不低于力量。把太大的功率不加控制地塞进灵巧手内,如同把赛车引擎装进微型轿车内,热量与应力问题会迅速凸显。睿研智控用意法半导体的电机驱动芯片解决了这一难题。意法半导体的电机驱动设计的内部导通电阻非常低,这意味着电流通过芯片时,以热量形式损耗的电能会更少。同时,它们还能为电机提供强大的电流,让每个关节都获得精准运动所需的扭矩。综合这些特性,灵巧手可以产生完成各类作业所需的抓取力,同时避免过热问题发生。由于耗散功率低,发热少,元器件的可靠性更高,这是全天候工业生产环境的必备要求。这也意味着机械结构可以设计得更纤薄、更简单,无需配备体积很大的散热系统,从而留出更多空间放置更重要的器件,打造更聪明、更能干的灵巧手指。 提升人形机器人在多品种混线生产中的实用价值 更实际地说,在分秒必争、每一次失误都要付出成本代价的环境下,灵活的人形机器人究竟能为工厂车间带来什么?睿研智控的灵巧手基于意法半导体技术,手指定位准确度达到0.6毫米,以仅大约信用卡大小的驱动板,输出最大握力高达120牛的力矩,相当于人手用力握紧的力量。它既能拿捏普通工具,又能凭借灵巧的指尖,轻松拾取微小易碎物品。这种闭环反馈,结合连续工作1000多个小时的系统设计,让机器人手可以实时调整,并在工厂里长时间连续作业。 对于制造厂商而言,人形机器人相当于一个更灵活的自动化平台,能够随着产品组合的变化,轻松适应新的生产环境。基于意法半导体技术平台,睿研智控为制造厂商提供一系列灵巧手,包括可直接集成的灵巧手解决方案,满足客户希望将定制灵巧手集成到更大系统里面的需求。 睿研智控是意法半导体机器人解决方案独立设计公司(IDH),也是“联合市场推广合作计划”的重要合作伙伴。 “ 睿研智控高度珍视与意法半导体的战略合作伙伴关系,并对双方共同成立机器人联合实验室深感振奋,意味着双方从单纯的供需关系升级为协同创新的战略合作伙伴。通过与ST的Co-Marketing Collaboration合作推广模式,借助ST覆盖全球的销售与市场网络,让我们的产品获得知名度和被认可的同时,也获得了非常可观的灵巧手订单数量。”睿研智控CEO田波先生重点强调。 田波先生睿研智控CEO 选择意法半导体作为几乎全类型芯片的唯一供应商,对睿研智控而言是一项具有战略远见的决策。
ST
意法半导体中国 . 2026-07-16 1225

产品 | 盛思锐宣布 STC42A 车规级氢气传感器全球上市,用于电池热失控检测
盛思锐(Sensirion)正式宣布其 STC42A 氢气传感器全面进入市场。该产品是电池热失控及氢气泄漏检测应用的理想选择。STC42A 专为需要在洁净空气环境中进行可靠氢气浓度测量的汽车应用而设计,目前可通过盛思锐全球授权渠道合作伙伴网络进行采购。 STC42A 是盛思锐基于热导技术开发的数字式氢气传感器,专门面向汽车电池监测系统(BMS)中用于电池热失控的早期预警。该产品符合 AEC-Q100(Grade 2)车规认证标准,满足汽车行业对于可靠性与耐久性的严苛要求,并针对安全相关的电池应用进行了优化设计。 依托盛思锐在热导式气体检测领域的长期技术积累,STC42A 在出厂前已完成校准,可提供经过全面补偿的数字氢气输出。其成熟的热导测量原理具备极高的鲁棒性、出色的长期稳定性以及极低的功耗,使其成为各类电池系统中安全关键型热失控检测的可靠解决方案。 该传感器配备数字 I²C 接口,可与外部 SHT41A 温湿度传感器协同工作,实现自主通信。通过 I²C 控制接口,系统可读取 SHT41A 的温湿度数据并直接传输至 STC42A,从而实现对氢气信号的实时绝对湿度补偿。 作为 STC4x 产品系列的一员,STC42A 针对热失控应用中的氢气检测进行了进一步优化,是电池热失控及氢气泄漏检测的理想选择。其核心优势在于基于盛思锐 CMOSens® 技术实现的卓越性能——将传感元件、信号处理和数字校准完全集成于单一 CMOS 芯片之上。 盛思锐电池状态监测产品经理 Pascal Erne 表示:“通过 STC42A,我们为汽车行业提供了一款能够检测电池热失控早期气体释放的氢气传感器。这有助于系统设计师根据相关安全标准中提出的‘5分钟预警’要求,及时触发安全措施。”
盛思锐
盛思锐 . 2026-07-16 1204

企业 | 长鑫科技发行价8.66元/股,估值超5700亿
长鑫科技公告称,公司首次公开发行股票并在科创板上市,发行价格为8.66元/股。投资者请按此价格在2026年7月16日(T日)进行网上和网下申购,申购时无需缴付申购资金。 其中,网下申购时间为9:30-15:00,网上申购时间为9:30-11:30,13:00-15:00。本次初始发行股份数量为668,808.8608万股,占发行后总股本约10.00%,并授予中金公司不超过初始发行股份15.00%的超额配售选择权。发行价格对应的2025年扣非前后孰低摊薄后市盈率为308.92倍(未行使超额配售选择权),高于行业平均市盈率76.32倍及可比公司平均市盈率134.62倍。 预计募集资金总额约579.19亿元(超额配售选择权行使前),扣除发行费用后净额约576.38亿元。长鑫科技发行后总股本(超额配售选择权行使前)为6,688,088.6077万股,据此计算,此次发行总市值约为5791.88亿元。
长鑫科技
芯查查资讯 . 2026-07-16 1309
市场 | 照护、情感需求发酵,预估陪伴型人形机器人2030年产值达11亿美元
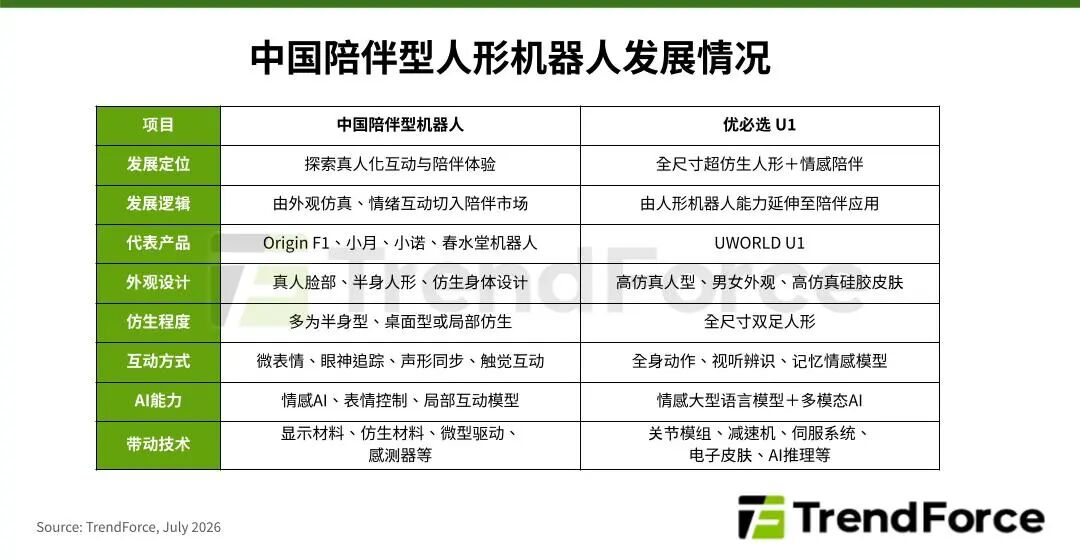
根据TrendForce集邦咨询最新机器人产业研究,陪伴型机器人已从早期的养老照护陪伴、疗愈设计,拓展至近年来的真人化互动和情感陪伴,日前中国厂商优必选发表超仿生人形机器人U1,象征此类陪伴型产品正式跨入真人化时代。随着全球人口结构走向老龄化、少子化,且独居人口持续增加,陪伴型人形机器人需求获得快速崛起的“陪伴经济”支撑,预估其产值将于2030年达到11亿美元。 中国设计追求真人化体验 近年中国陪伴型机器人更加重视仿生外观、情绪表达和自然应对,旨在提升真人互动感,多数厂商以陪伴功能为前提,开发局部人形产品。如松延动力的桌面陪伴机器人小月,强调声形同步与家庭陪伴;春水堂聚焦高仿真人体外观、触觉反馈和体温模拟,着眼陪伴沉浸感。 优必选U1则拥有高仿真硅胶皮肤、88个自由度,搭载养成系情感大模型以识别多种情绪状态,锁定家庭互动、心理支持等消费市场。与其他业者的切入方式不同,优必选原就专注开发人形机器人,现在更赋予产品互动陪伴能力,其中关键在于中国供应链、AI模型、制造技术快速积累,有助于结合人形机器人的硬件能力与情感陪伴需求,开启新商业模式。 TrendForce集邦咨询表示,U1问世代表人形机器人供应链已从工业延伸至消费电子市场。未来,除了伺服电机、减速机、关节模组等传统关键零部件,高仿真材料、多模态传感器、微表情驱动器、情感模型,以及本地端AI推理能力的重要性将同步提升,创造新的供应链机会。 然而,陪伴型人形机器人仍面临不少挑战,不仅续航力已备受关注,还包括情感互动自然度、人格记忆维持性、功能安全隐私等,以及产品成本与价格区间的平衡。由于情感陪伴机器人与用户互动更频繁,预期将促使厂商更聚焦于硬件、AI模型、生态系统与内容服务的整合,优必选U1的上万笔订单反映市场初步回响,然而如何延续尝新过后的市场动能仍待观察。
人形机器人
TrendForce集邦 . 2026-07-16 973
产品 | 国产16nm钛金系列FPGA TJ135开发套件,面向视觉 / 边缘计算的标准化验证平台
一、引言 在工业视觉、高速通信等项目预研阶段,硬件工程师常会遇到开发平台碎片化问题:CPU、存储、高速图像 / 通信接口需多块板卡拼接调试,硬件联调周期长;自研核心SOM前期投入成本高、存在流片风险;配套开发工具、例程分散,软硬件协同开发门槛较高。 易灵思官方合作伙伴-深圳奥唯思科技基于16nm钛金系列FPGA TJ135N676X芯片推出的VC-TJ135开发套件,集成芯片全部原生硬核资源,配套完整工具链与标准化Demo工程,可完成算法验证、接口调试、整机功能预研,前期验证完成后可直接复用核心板做量产硬件,缩短项目开发周期。 图1 VC-TJ135开发板 二、核心芯片硬件规格(TJ135N676X) TJ135采用16nm Quantum工艺架构,芯片内置全套固化高速硬核,无需额外外挂桥接芯片: 1 基础逻辑资源 132K逻辑单元,9.83Mbit片上SRAM,40路DSP运算单元,可完成图像滤波、目标检测、数据预处理等并行硬件运算;内置9路独立分数PLL,支持动态相位调整 SHIFT_SEL、展频输出,配套可视化PLL时钟配置工具,多速率接口时钟可统一管理。 图2 钛金系列TJ135 FPGA芯片架构框图 2 内置四大专用硬核 四核1GHz硬核RISC-V:六级流水线架构,完整支持RISC-VI/M/A/F/D指令集,通过AXI总线与FPGA逻辑互通,可运行裸机程序或FreeRTOS;支持多核分区运行、硬件冗余设计。 2.5G MIPI D-PHY硬核:2组接收、2组发送4 lane通道,单链路带宽2.5Gbps,多路工业相机、高清显示屏幕可直连,无需外部转换电路。 32bit LPDDR4控制器:最高3200Mbps速率,峰值带宽12.8GB/s,满足4K图像缓存、轻量化AI推理大吞吐量存储需求。 8对16Gbps SerDes收发器:原生支持PCIe4.0、万兆以太网、SGMII千兆网、PMA直通模式,适配高速数据回传、设备互联设计。 图3 易灵思钛金系列Transceiver FPGA选型表——高速互联平台 三、VC-TJ135开发套件硬件架构 套件采用核心板 + 底板分体式SOM设计,兼顾前期调试与后期量产复用: 1 VC-TJ135-C核心板(68mm×58mm) 板载完整最小运行系统,可独立作为量产核心模块使用: 主芯片TJ135N676X,配套专用PMIC电源管理电路; 存储配置:2GB 32bit LPDDR4、8GB eMMC、256Mbit SPI Flash; 基础外设:JTAG调试接口、8路状态LED、2路用户功能按键; 高速广濑板对板连接器,完整引出MIPI、SerDes、DDR、AXI等全部高速信号。 图4 VC-TJ135-C核心板顶层与底层布局图 2 VC-TJ135-B扩展底板 面向预研调试,配齐行业通用对外接口,无需额外制作转接板: 图像接口:双路MIPI输入、双路MIPI输出、HDMI1.4、LVDS液晶屏接口; 通信接口:千兆以太网、CH340 USB转UART调试串口、2.4G WIFI、TF存储卡插槽; 扩展资源:标准FMC高速扩展槽、40路通用GPIO、4个物理功能按键。 3 配套调试硬件 UB-ELITE-001 JTAG下载器,搭配专用排线,支持FPGA临时下载、固件固化两种模式。 四、配套完整开发软件生态 整套开发无授权费用,工具链全覆盖FPGA RTL、RISC-V嵌入式两条开发链路: 1 Efinity IDE主开发软件 支持Verilog/VHDL语言,集成综合、布局布线、时序分析、Floorplan可视化、Interface Designer IP可视化配置工具,拖拽式配置RISC-V、PLL、LPDDR4、MIPI等全部硬核,无需手写复杂约束文件。 2 仿真调试工具 兼容Modelsim、iVerilog仿真,支持GtkWave离线波形查看,可在线抓取内部信号用于问题定位。 3 RISC-V专用开发环境 独立RISC-V IDE,支持FreeRTOS工程编译,可生成bin、elf、hex固件文件;支持FPGA逻辑固件与RISC-V程序合并打包,一键固化至外部Flash。 4 标准化Demo工程(开箱可用) 官方预置15套完整参考工程,覆盖基础调试与主流业务场景: 基础类:LED流水灯、按键检测、UART串口回环; 图像类:LPDDR缓存1080P显示、多路MIPI相机采集、LVDS屏幕输出; 通信类:千兆以太网UDP回环、12G SerDes收发回环; 嵌入式类:RISC-V读写EEPROM、SD卡数据读取。 五、两种固件加载模式:适配研发 / 量产 1 SRAM临时加载(研发调试) 通过JTAG将.bit比特流文件下发至片内SRAM,掉电程序清除,修改逻辑后可快速重新下载迭代,适合算法、接口调试阶段。 2 SPI Flash永久固化(量产标准) 借助官方JTAG桥接文件,将FPGA逻辑、RISC-V应用软件合并为统一hex文件写入SPI Flash,设备上电自动加载运行,匹配量产设备启动逻辑,配套完整固化操作文档。 六、典型适用场景 1 工业机器视觉检测 多路相机同步采集、4K图像实时缓存、缺陷检测硬件加速,HDMI直出检测画面。 2 万兆高速数据采集、边缘通信 SerDes+PCIE 4.0实现大流量数据转发、加密传输。 3 轻量化边缘AI推理 DSP阵列搭配片上大容量RAM,完成小型目标检测、图像分类硬件加速。 七、套件交付内容 1 VC-TJ135-C核心板、VC-TJ135-B扩展底板 2UB-ELITE-001 JTAG下载器、配套排线、Type-C供电线 3全套资料包:Efinity/RISC-V IDE安装包、完整产品手册、硬件原理图 & PCB封装、全部Demo源码、仿真工程、程序固化操作指引 VC-TJ135开发套件基于国产16nm钛金系列FPGA TJ135,集成完整高速硬核与标准化软硬件配套,可高效完成视觉、通信类产品前期功能验证。核心板可直接复用至量产硬件,降低二次硬件设计成本。
易灵思
易灵思官微 . 2026-07-16 3122

Vishay新款IHXL系列电感器提供高达209 A的额定电流,磁芯损耗降低20 %
新款汽车级和商用器件的成本低于现有解决方案,不仅具备更强的电磁兼容性,还可提供高达10 µH的电感值 日前,威世科技Vishay Intertechnology宣布,其IHXL系列径向通孔电感器新增四款产品---IHXL1500VZ-3A、IHXL-2000VZ-3A和IHXL1500VZ-31、IHXL-2000VZ-31,旨在以更低的成本提供更佳的性能。车规级IHXL1500VZ-3A和IHXL-2000VZ-3A以及商用型IHXL1500VZ-31和IHXL-2000VZ-31采用新型铁合金磁芯材料,与上一代相比,磁芯损耗降低20 %,同时温升更低。该系列器件可在+155 C高温下工作,并为高达209 A的滤波应用提供出色的电磁兼容性(EMC)。 此次发布的Vishay Dale器件可应用于汽车、工业、太阳能及风能领域,可在电池充电系统、无刷直流电机(BLDC)以及差模扼流圈和升压功率因数校正(PFC)扼流圈中充当大电流输入滤波器、DC/DC转换器和DC-Link滤波器。相较于上一代IHXL系列器件,该系列电感器价格更低,同时兼具铁芯损耗更小、电感值高达10 µH的优势,可实现更高阻抗以优化滤波性能,并增强开关转换器的纹波电流控制。 IHXL1500VZ-3A、IHXL1500VZ-31、IHXL-2000VZ-3A和IHXL-2000VZ-31采用磁屏蔽结构,配有压制铁粉芯体,可约束杂散磁通,最大限度减少与周围元器件的耦合,相较于内部线圈裸露的传统绕线器件,最大程度地提升了EMC。这种压制铁粉结构还具有内部热阻低的特性,可减少热点,通过主动冷却进一步提升性能,同时,平顶设计简化了外部散热器的安装。 该系列电感器内部采用厚实的铜导体,支持55 A至209 A的宽范围负载电流,适用于1500(38.1 mm x 38.1 mm x 21.89 mm)和2000(50.8 mm x 50.8 mm x 21.7 mm)封装尺寸。其软饱和磁芯材料可避免硬饱和,确保在宽负载条件下(包括高瞬变电流尖峰期间),电感保持稳定。IHXL-2000VZ-3A和IHXL-2000VZ-31符合RoHS标准,无卤素,且满足Vishay绿色要求,具有高抗热冲击、耐潮和抗机械冲击性能,并可提供定制的端接方式、电感值、电流、温度和电压额定值。 器件规格表: (1) 分别导致ΔT约为40 C和80 C的直流电流 (A) (2) 分别导致L0下降约为20 %和30 %的直流电流 (A) 新款IHXL系列电感器现已上市,供货周期为14周。
vishay . 2026-07-16 861

IRLU110ATU 与 VBFB1102M 参数对比报告
N沟道功率MOSFET参数对比分析报告:IRLU110ATU 与 VBFB1102M 一、产品概述 IRLU110ATU:安森美(onsemi/Fairchild)N沟道100V功率MOSFET,采用雪崩耐用技术和坚固栅极氧化层技术,具有较低的输入电容和改进的栅极电荷。封装:DPAK (TO-252) / I-PAK。适用于通用开关应用。 VBFB1102M:VBsemi N沟道100V功率MOSFET,符合无卤素标准(IEC 61249-2-21),具备动态dV/dt额定值和重复雪崩额定值,支持高达175°C的工作结温,开关速度快,易于并联。封装:TO-251。适用于高效率开关电源、电机驱动等应用。 二、绝对最大额定值对比 参数 符号 IRLU110ATU VBFB1102M 单位 漏-源电压 VDSS 100 100 V 栅-源电压 VGSS ±20 ±20 V 连续漏极电流 (Tc=25°C) ID 4.7 12 A 连续漏极电流 (Tc=100°C) ID 3 7.5 A 脉冲漏极电流 IDM 16 37 A 最大功率耗散 (Tc=25°C) PD 40 60 W 最大功率耗散 (TA=25°C, PCB Mount) PD - 3.7 W 沟道/结温 Tch/TJ 150 175 °C 存储温度范围 Tstg -55 ~ +150 -55 ~ +175 °C 雪崩能量(单脉冲) EAS 58 (条件见注) 200 mJ 雪崩电流 IAR 4.7 (条件见注) 9.2 A 重复雪崩能量 EAR - 6.0 mJ 峰值二极管恢复dv/dt dv/dt - 5.5 V/ns 线性降额因子 - 0.32 0.40 W/°C 分析:两款器件耐压等级相同(100V)。VBFB1102M 在电流能力上优势显著,连续电流(12A vs 4.7A)和脉冲电流(37A vs 16A)都更高,且最大工作结温达175°C,适应性更强。其单脉冲雪崩能量(200mJ)也远高于 IRLU110ATU,在感性负载中的鲁棒性更佳。IRLU110ATU 的功率耗散值较低。 三、电特性参数对比 3.1 导通特性 参数 符号 IRLU110ATU VBFB1102M 单位 漏-源击穿电压 V(BR)DSS 100 (最小) 100 (最小) V 栅极阈值电压 VGS(th) 1.0 ~ 2.0 1.0 ~ 3.0 V 导通电阻 (VGS=10V, ID见注) RDS(on) 0.44 最大 / 0.336 典型 0.20 典型 Ω 正向跨导 gfs 5.6 典型 2.7 典型 S 分析:在典型值上,VBFB1102M 的导通电阻显著更低(0.20Ω vs 0.336Ω),意味着其导通损耗更小,这是其一大核心优势。IRLU110ATU 的阈值电压范围更窄,开启特性可能更一致,且跨导典型值更高。 3.2 动态特性 参数 符号 IRLU110ATU VBFB1102M 单位 输入电容 Ciss 1100 360 pF 输出电容 Coss 235 150 pF 反向传输电容 Crss 65 34 pF 总栅极电荷 Qg 25 16 (最大) nC 栅-源电荷 Qgs 8 4.4 (最大) nC 栅-漏(米勒)电荷 Qgd 10 7.7 (最大) nC 分析:VBFB1102M 的动态特性全面占优,其所有电容值(Ciss、Coss、Crss)均显著低于 IRLU110ATU,且总栅极电荷(Qg)也更低。这直接转化为更快的开关速度、更低的开关损耗和更低的栅极驱动需求,非常适用于高频应用。 3.3 开关时间 参数 符号 IRLU110ATU VBFB1102M 单位 开通延迟时间 td(on) - 8.8 典型 ns 上升时间 tr - 30 典型 ns 关断延迟时间 td(off) - 19 典型 ns 下降时间 tf - 20 典型 ns 分析:IRLU110ATU 的数据手册中未提供具体的开关时间参数。VBFB1102M 提供了完整的开关时间参数,从数值看,其开关速度很快,这与其低电容、低栅极电荷的特性相符。 四、体二极管特性 参数 符号 IRLU110ATU VBFB1102M 单位 连续源极电流(体二极管) IS 4.7 9.2 A 脉冲源极电流(体二极管) ISM 16 37 A 二极管正向压降 VSD 1.5 最大 @ 5.6A 1.8 最大 @ 9.2A V 反向恢复时间 trr 85 典型 110 典型 (最大 260) ns 反向恢复电荷 Qrr 0.23 典型 0.53 典型 (最大 1.3) μC 分析:VBFB1102M 的体二极管电流能力同样更强(连续9.2A vs 4.7A)。其二极管正向压降略高,但在更大电流下测试。两款器件都提供了反向恢复参数,IRLU110ATU 的 trr 和 Qrr 典型值更低,可能在高频续流或同步整流应用中略有优势。 五、热特性 参数 符号 IRLU110ATU VBFB1102M 单位 结-壳热阻 RθJC 5.6 最大 2.5 最大 °C/W 结-环境热阻(PCB Mount) RθJA - 40 最大 °C/W 分析:VBFB1102M 的结-壳热阻(2.5°C/W)远低于 IRLU110ATU(5.6°C/W),表明其芯片到封装外壳的热传导效率更高,结合其更高的最大功率耗散(60W vs 40W),在相同散热条件下能够处理更大的功率,热管理性能更优。 六、总结与选型建议 IRLU110ATU 优势 VBFB1102M 优势 ◆ 更低的栅极阈值电压(开启更容易) ◆ 更高的正向跨导典型值 ◆ 体二极管反向恢复时间/电荷典型值更低 ◆ 型号历史久,应用案例可能更丰富 ◆ 显著更低的导通电阻(RDS(on)) ◆ 全面领先的动态特性(低电容、低栅极电荷) ◆ 更高的电流能力(连续12A,脉冲37A) ◆ 更高的工作结温(175°C) ◆ 更强的雪崩能量耐受(200mJ) ◆ 更优的热阻(RθJC=2.5°C/W)和功率耗散 ◆ 开关速度更快,提供完整开关时间参数 ◆ 符合无卤素环保标准 选型建议 选择 IRLU110ATU:当应用对成本极其敏感,且工作频率、电流应力不高,但对器件开启电压的阈值有较严格要求,或对体二极管的反向恢复特性有特定需求的传统设计中。 选择 VBFB1102M:当设计追求高效率、高功率密度和高可靠性时。其低导通电阻和优异的动态特性能有效降低导通与开关损耗,非常适合高频开关电源(如DC-DC转换器、PFC)、电机驱动等应用。更高的电流定额、雪崩能力和175°C工作结温提供了更充足的设计裕量和更强的环境适应性。其热性能也更有利于紧凑型设计。 备注:本报告基于 IRLU110ATU(onsemi/Fairchild)和 VBFB1102M(VBsemi)官方数据手册内容生成。所有参数值均来源于原厂数据手册,设计选型请以官方最新文档为准。部分测试条件可能存在差异,建议进行详细对比验证。
微碧
微碧半导体 . 2026-07-16 931

从母线纹波到相位裕度:AI数据中心UPS直流侧电流检测面临的四个新挑战
过去十年,大功率UPS的技术演进主要围绕三个方向展开:更高效率、更高功率密度和更高可靠性。 但随着AI大模型训练和推理集群快速扩张,一个过去很少被单独讨论的问题,开始逐渐成为UPS设计的新挑战——直流侧电流检测。 传统数据中心负载以CPU服务器、存储和网络设备为主,其功率变化相对缓慢,UPS控制系统面对的是一个动态特性相对平稳的对象。而在AI数据中心中,大规模GPU集群在计算同步、参数更新、通信调度以及Checkpoint写入过程中,会产生频繁的脉冲式功率变化(Burst Load)。这种变化虽然持续时间通常只有毫秒级,但对于UPS而言,却意味着持续不断的瞬态功率冲击。 越来越多的UPS厂商开始发现,在AI负载场景下,首先遇到瓶颈的往往不是IGBT,不是DSP,也不是控制算法,而是长期被认为已经足够成熟的直流侧电流检测链路。 为什么AI负载首先挑战的是直流侧? 在典型双变换在线UPS架构中,直流母线是整个系统的能量交换中心。 它连接着: l AC/DC整流器; l 储能电池及双向DC/DC; l DC/AC逆变器; l 直流母线储能电容。 所有功率流动最终都需要经过直流侧完成交换。 与交流侧相比,直流侧电流检测具有几个天然特点: · 同时包含直流分量和高频动态分量; · 承受高共模电压环境; · 存在储能电容参与的瞬态能量交换; · 长期工作于双向功率流状态。 过去,这些特性并不会成为系统瓶颈;但随着AI负载动态特性的不断增强,直流侧开始成为影响UPS动态性能的重要环节。 挑战一:母线电容正在"掩盖"真实负载变化 很多人会认为: l GPU负载增加多少,UPS输出电流就同步增加多少。 但对于双变换UPS而言,实际情况并非如此。 在直流母线侧,瞬态电流关系可以表示为: Iload = Irectifier + Icapacitor 当GPU负载在毫秒级内突然增加时,首先响应的往往不是整流器,而是直流母线储能电容。 其过程通常表现为: · GPU负载快速上升; · 直流母线电压开始下降; · 母线电容立即释放能量; · 电流控制环检测变化; · 整流器逐步提升输出功率; · 系统重新达到平衡。 这意味着: 在负载动态变化初期,直流侧电流传感器测量到的电流,并不完全等于负载真实需求。 对于传统IT负载,这种差异几乎可以忽略;但在AI数据中心持续脉冲负载环境下,这种瞬态偏差会直接影响: · 电流环动态响应; · 功率预测算法; · 电池充放电调度; · 并机均流控制。 因此,对于AI数据中心UPS而言,电流传感器首先需要解决的问题不是"测得更准",而是"反应更快"。 挑战二:直流母线并不是真正意义上的"直流" 在工程实践中,"800V DC母线"并不意味着母线电流是理想直流。 实际上,直流母线电流通常可以表示为: IDC = IAVG + ΔIHF 其中: · IAVG表示平均功率流; · ΔIHF表示高频动态分量。 这些高频分量主要来自: · PWM开关谐波; · LC滤波残余纹波; · 母线电容充放电电流; · 并联模块环流; · AI负载带来的脉冲功率扰动。 尤其是在采用SiC功率器件的新一代UPS中,更高的开关频率和更大的di/dt,使母线纹波频谱进一步扩展至几十kHz甚至上百kHz范围。 这意味着,电流传感器实际面对的并不是一个简单的直流测量问题,而是: 在测量大直流电流的同时,还必须保留足够丰富的动态信息。 如果传感器带宽不足,高频信息会被等效低通滤波,控制器获得的就不是实际电流,而是一个被平滑后的近似值,从而降低系统动态响应能力。 挑战三:相位裕度,正在成为新的隐形瓶颈 在现代UPS控制系统中,决定动态性能的关键因素已经不再是静态精度,而是系统稳定裕度。 典型控制链路为: 在这个闭环系统中,每一个环节都会引入时间延迟。 其中,电流传感器带来的相位滞后往往最容易被忽视。 工程上通常要求: l 电流检测链路带宽至少达到控制带宽的5~10倍。 原因在于,只有这样才能保证检测链路在控制交越频率附近引入的额外相位滞后仅为数度,从而维持足够的系统相位裕度。 以当前主流MW级双变换UPS为参考,其参数通常为: 参数 典型参考范围 开关频率 10kHz~20kHz 电流环带宽 50kHz~150kHz 电压环带宽 100Hz~500Hz 而针对AI动态负载优化的新一代UPS系统,这些参数仍在持续提升。 因此,对于AI数据中心UPS而言,电流传感器已经不再只是一个测量元件,而成为整个控制环路动态性能的重要组成部分。 挑战四:2000A时代,需要重新定义"够用精度" 随着AI数据中心功率等级不断提升,UPS直流侧电流规格也在快速增长。 以1MW UPS为例: · 800V直流母线额定电流约1250A; · 考虑过载能力和冗余设计,实际测量范围通常需要覆盖±2000A以上; · 多机并联系统甚至需要覆盖更高电流。 在这一电流等级下,系统同时要求: · 大量程; · 快响应; · 高隔离; · 良好线性度; · 长期可靠性。 理论上,磁通门技术能够实现更高的测量精度。 但对于当前AI数据中心UPS而言,功率控制、SOC估算以及并机均流通常要求系统综合误差控制在0.5%左右。闭环霍尔传感器±0.3%的本体精度,已经能够满足当前绝大多数控制需求。 因此,在现阶段AI UPS应用中,需要解决的问题不再是: 谁的精度最高? 而是: 谁能够在动态性能、精度、可靠性和成本之间取得最佳平衡? 为什么闭环霍尔仍然是MW级UPS的重要选择? 以CM5A 2000 H21闭环霍尔电流传感器为例,其额定量程为±2000A,最大测量范围可达±4250A,能够覆盖当前兆瓦级UPS系统在过载、并机以及动态功率波动场景下的测量需求。其±0.3%FS的测量精度、±0.1%的线性度以及150kHz带宽,使其能够在大电流、高动态响应和长期可靠性之间取得较好的工程平衡。 其主要参数如下: 参数 CM5A 2000 H21 额定量程 ±2000A 最大测量范围 ±4250A 精度 ±0.3%FS 线性度 ±0.1% 响应时间 0.5μs 带宽 150kHz 隔离耐压 6kV AC 冲击耐压 23kV 其中: · 150kHz带宽能够覆盖UPS控制所需的主要动态频谱; · 微秒级响应时间不会成为系统动态响应瓶颈; · ±0.3%精度能够满足当前AI UPS控制需求; · 高隔离和高冲击耐压能力适用于高压直流母线环境。 因此,闭环霍尔方案的价值并不在于追求极限精度,而在于: 它在动态性能、测量精度、系统复杂度和经济性之间,提供了一个符合当前AI数据中心UPS需求的工程平衡点。 结语:AI时代正在重新定义UPS中的电流检测 过去,人们更多将UPS中的电流传感器视为一个测量器件。 而在AI数据中心时代,它正在逐渐演变成影响系统动态性能的重要组成部分。 当GPU集群的功率波动速度越来越快、系统功率等级越来越高时,真正决定UPS性能上限的,可能已经不再是功率器件本身,而是系统能否足够快速、足够准确地感知真实的电流变化。 从母线纹波,到相位裕度,再到动态稳定性,AI负载正在迫使UPS重新审视那个曾经被认为已经成熟的技术环节——直流侧电流检测。
芯森电子 . 2026-07-16 868

BLDC无刷电机普及背后:功率分立器件支撑机器人
最近发现一个很有意思的细节,现在的扫地机器人、机械臂、AGV小车运行起来越来越顺滑安静,耐用性也大幅提升。 深究下来,核心原因就是BLDC无刷电机基本取代了老式有刷电机。没有电刷摩擦损耗,转速稳、效率高、寿命长,刚好适配机器人精密运作、长时间工作的需求。 但很多做研发、选型的朋友都知道,电机只是表象,真正决定设备稳定、续航的恰恰是不起眼的功率分立器件。 行业痛点:很多机器人翻车的真实原因 很多人觉得BLDC方案很成熟,但实际落地调试,总会遇到各种问题,大多都是功率分立器件没选对: 工况复杂容易坏:机器人频繁启停、偶尔堵转、高频调速,普通MOS管损耗大、抗冲击差,长时间运行容易发烫、卡顿,甚至直接烧坏,设备寿命大打折扣。 体积冲突难适配:现在机器人都在做小型轻量化,传统功率器件封装太大,电路板布局很受限,根本塞不下。 续航短板明显:通用器件导通电阻偏高,电机工作运转损耗大,设备续航缩水,没办法长时间连续作业。 进口供货不稳:进口器件价格高、交期久,中小厂商备货压力大。 合科泰功率分立器件:针对性解决BLDC驱动难题 针对上述痛点,合科泰功率分立器件给出了系统性答案。产品采用先进SGT工艺,打磨出了适配机器人BLDC驱动的专用功率器件,实测适配性和稳定性都很能打: 1. 低损耗、控温稳:导通电阻做得很低,工作发热大幅减少,对比普通器件整机温升能降18℃左右,长时间运行也不会积热发烫,稳定性拉满。 2. 响应快、调速准:开关速度达到纳秒级,能适配高频PWM调速,电机启停顺滑不顿挫,机器人关节微调、精准走位的需求都能满足。 3. 抗造耐用、适配多工况:雪崩抗冲击性能优秀,遇到电机堵转、瞬时大电流冲击也不容易损坏,完美适配机器人复杂的工作场景。 4. 小型封装、适配轻量化:主流PDFN封装,散热效果好,不占用过多板上空间;TO-252封装作为经典封装,同样适用于对空间有一定要求但无需极致紧凑的中小型设备场景,为客户提供更多选型灵活性。 实用选型参考|按场景选不踩坑 给大家整理好了不同机器人工况的适配型号,按需选择就不用盲目堆参数,性价比更高: 轻负载家用设备(扫地机、家用服务机器人) HKTD70N04完全适配小功率需求,低延迟、低损耗,日常运行稳定,还能有效提升设备整体续航。 中负载商用设备(AGV小车、轻型协作机器人) HKTG90N03适配性最佳,90A大电流承载力,轻松应对高频启停、长时间连续作业,动力输出很稳定。 重载工业设备(人形机器人、工业自动化设备) 优先 HKTD100N03或HKTG120N04,超大电流承载搭配强效散热,高强度高负荷的工业工况也能轻松搞定。 最后小结 说到底,BLDC无刷电机让机器人动力体验大幅升级,而靠谱的功率器件,就是设备稳定运行的核心底气。合科泰这套国产器件方案,针对性解决了机器人驱动的发热、不稳、续航差等常见问题,兼顾高可靠性和低成本,也是现在很多机器人厂商的优选方案。 补充给正在选型的工程师们,建议找合科泰的业务团队获取详细的应用支持。咱们有针对不同功率段、拓扑结构的器件推荐清单,可以帮助大家快速缩小选择范围,选到符合心理预期的器件,大大节省时间,提高效率。欢迎大家在评论区留言咨询! 免责声明:本号内容仅作交流学习,非商业,侵权可联系13670157085微信删除,未经允许禁止转载,违者将依法追究相关责任。
厂商投稿 . 2026-07-16 952

AI边缘设备MLCC选型指南——贞光科技代理三星电机01005阵列(最高22μF)
智能手表里的语音助手、AR眼镜的实时翻译、TWS耳机的降噪算法——这些日常功能背后,都有一个共同趋势:AI运算正在从云端搬到设备本地。对硬件工程师来说,这意味着PCB上的器件密度陡增,而电源稳定化用的MLCC,必须在更小的面积里塞入更大的容量。作为三星电机MLCC的授权代理商,贞光科技近期收到不少客户咨询:超小型高容量MLCC到底怎么选? 今天,我们结合三星电机最新发布的产品阵列,把选型要点梳理清楚。 端侧AI爆发,MLCC面临三重挤压 与云端AI不同,Edge Device要在极小的物理空间内完成推理运算,这对电源管理提出了近乎苛刻的要求。当前MLCC的选型困境,可以归纳为三个维度: 1. 功耗激增:高容量成为刚需 AP/NPU在本地运行AI模型时,功耗呈指数级上升,电源线路上的纹波和噪声随之恶化。传统的电容配置已难以满足电源稳定化需求,高容量MLCC成为抑制噪声的首选方案。 2. 部件堆叠:安装面积急剧收缩 AI加速器、蓝牙/Wi-Fi/UWB通信模块、各类传感器……这些新增模块都在瓜分有限的PCB面积。以Wearable设备为例,PCB空间堪称”寸土寸金”,必须在更小的封装尺寸内实现同等甚至更高的电容量。 3. 轻薄化趋势:超薄Profile不可或缺 最新一代智能手表和健康贴片追求极致纤薄,这要求MLCC不仅”小”,还要”薄”。例如三星电机CL03A475MQ3CRN#的厚度仅为0.39Tmax,正是应对这一需求的典型设计。 尺寸演进:从0603到01005,安装面积持续压缩 三星电机的技术数据显示,MLCC尺寸的迭代正在加速。以安装100颗MLCC为基准,各尺寸带来的面积缩减效果十分显著: 尺寸演进 安装面积减少幅度 0805 → 0603 -30% 0603 → 0402 -40% 0402 → 0201 -34% 0201 → 01005 -29% 市场趋势同样明确:随着On-Device AI功能从高端机型向中低端渗透,现有主流的0603/0402英寸规格正加速向0201/01005英寸迁移;同时,0402尺寸中22μF以上的超高容量产品采用率也在快速提升。 对于硬件工程师而言,提前布局超小型MLCC的选型验证,已成为缩短产品上市周期的关键动作。 产品详解:三星电机四款核心型号 针对AI Edge Device及Wearable的严苛需求,三星电机构建了完整的超小型·超高容量MLCC产品阵列。贞光科技作为授权代理商,可为客户提供以下四款核心型号的样品支持与技术咨询: 型号 尺寸 (inch/mm) 容量 额定电压 温度特性 厚度 备注 CL02A105MQ2NQN# 01005/0402 1μF 6.3Vdc X5R 0.25Tmax 超微型入门款 CL03A475MQ3CRN# 0201/0603 4.7μF 6.3Vdc X6S 0.39Tmax Low Profile CL03X106MS5C6W# 0201/0603 10μF 2.5Vdc X6S 0.55Tmax 高容量中端方案 CL05A226MP6NUN# 0402/1005 22μF 10Vdc X5R 0.8Tmax 超高容量旗舰 选型建议: 空间极度受限场景(如TWS耳机、智能戒指):优先考虑01005尺寸的CL02A105MQ2NQN#,0.25Tmax厚度几乎不占用Z轴空间。 超薄Wearable(如健康贴片、智能手表):CL03A475MQ3CRN#的Low Profile特性(0.39Tmax)是平衡容量与厚度的最优解。 大电流AI模组供电:CL05A226MP6NUN#以22μF/10Vdc的规格,可有效抑制AP/NPU负载跳变引起的电压跌落。 贞光科技能为您做什么 作为三星电机MLCC产品的授权代理商,贞光科技不仅提供上述型号的样品申请与批量供货,更可协助客户完成: 替代选型分析:针对现有0603/0402方案,评估迁移至0201/01005的可行性 库存与交期管理:平衡项目周期与供应链风险 技术参数确认:协助核对温度特性、DC Bias特性等关键指标 结语 01005尺寸的MLCC已经不再是实验室里的概念产品。从智能手表到AI眼镜,它正在批量进入消费级硬件的BOM表。三星电机的产品阵列覆盖了从1μF到22μF的主流需求,而贞光科技作为授权代理,可以帮您把样品快速拿到手,把技术参数对清楚,把供应链跑顺畅。 注:本文技术资料来源于三星电机官方发布,贞光科技整理编辑。
三星电容代理MLCC
三星电容代理 . 2026-07-16 945

Melexis拓展突破性Triphibian技术,发力低压应用领域
Melexis宣布,推出Triphibian®压力传感器系列的全新低压型号——MLX90830、MLX90833和MLX90834,支持低至2bar的可配置压力范围。今天推出的这些器件将迈来芯特有的Triphibian®技术(能够同时测量气体和液体压力)成功拓展至电动汽车的热管理回路和人工智能(AI)数据中心的液冷系统中。 迈来芯现有型号支持高达70bar的压力测量,适用于制冷回路和机油测量等严苛应用。全新低压型号凭借其出色的乙二醇兼容性,将这一能力扩展至冷却液等介质。 冷却系统对于日益复杂的电子和机电系统的性能和可靠性至关重要。在电动汽车电池热管理以及高密度数据中心的液冷应用中,压力测量有助于验证冷却液是否正常循环,支持故障诊断,并保护高价值组件免受潜在故障的影响。然而,在低压环境中实现可靠的压力传感仍面临挑战。传统的MEMS传感器或陶瓷传感方法,很难在气体、液体和冷冻介质中提供稳健的测量。此外,这些传统方案还可能带来集成挑战并需要模块级校准,这无疑增加了系统成本、开发工作量和机械复杂度,与当前制造商优化设计压力的需求背道而驰。 Triphibian 2bar 全新低压Triphibian®型号通过将迈来芯首创的能够测量气体、液体和冷冻介质压力的传感技术引入工作范围为2或4bar的应用中,成功解决上述挑战。这些器件采用紧凑的、出厂已校准的SOIC16宽体封装,将独特的悬臂梁式MEMS压力传感元件与信号处理、调理和输出驱动器相结合,专为直接接触气体、液体和冷冻介质而设计。这简化了将稳健压力传感集成到紧凑型低压系统设计中的过程。 对于工程师而言,这种封装级的集成提供了两条清晰的实现路径。这些器件既可用于独立的压力模块,也可直接集成到泵或冷却液分配单元等更大型的系统组件中。这种方法允许在更接近测量点的位置进行压力测量,同时帮助设计人员规避大型独立模块的物理限制,并降低校准工作量与机械集成复杂度。 主要优势包括: 低压Triphibian®覆盖范围:全新型号支持低至2bar的可配置压力范围,将该系列的工作压力范围从2bar扩展至70bar,并支持对气体、液体和冷冻介质的直接测量。 紧凑型集成架构:在出厂已校准的SOIC16宽体封装中,融合了MEMS压力传感元件、数字信号处理(DSP)和输出驱动器。 简化校准流程:每颗传感器均由迈来芯在多个压力和温度点进行校准,免去了模块级下线校准的工作。 汽车级可靠性:具备高达+40V的过压保护和低至-40V的反向电压保护能力,并根据ISO 26262标准开发脱离上下文的安全要素(SEooC),支持高达ASIL B等级的系统集成。 灵活的输出和温度选项:提供模拟、SENT和LIN型号,其中数字版本支持片上温度信息,并可在需要压力和温度数据时选择连接外部负温度系数(NTC)电阻器。 “我们提供从2bar开始的压力测量,为紧凑型液冷系统带来了直接传感优势,消除了传统方案中模块级集成和校准相关的复杂性,”迈来芯产品线总监Karel Claesen表示,“无论是用于下一代汽车系统,还是为AI数据中心提供支撑,Triphibian®技术都能提供确保硬件持续稳定运行所需的关键监测。” 全新低压型号现已在Triphibian®系列中全面上市,包括MLX90830(模拟)、MLX90833(LIN)和MLX90834(SENT),支持SPI/I²C接口的版本将于2027年推出。 准备好升级您的液体介质系统了吗?欢迎浏览产品页面或立即联系迈来芯专家:https://www.melexis.com/contact。
Melexis . 2026-07-16 700

东芝扩展四通道标准数字隔离器产品线,助力降低工业设备功耗
东芝电子元件及存储装置株式会社(“东芝”)今日宣布,面向工业设备应用扩展了DCL34xx0B系列四通道标准数字隔离器,新增四款产品——“DCL340L0B”、“DCL340H0B”、“DCL342L0B”和“DCL342H0B”。该系列所有产品均实现每通道0.2mA(典型值)[1]的低电流消耗,采用小型SSOP16封装,并支持中速通信[2]。 其中“DCL340L0B”和“DCL340H0B”为4个正向通道、0个反向通道,“DCL342L0B”和“DCL342H0B”为2个正向通道、2个反向通道。 在可编程逻辑控制器(PLC)、执行器和逆变器等工业设备中,防止设备故障、异常传输以及由噪声引起的误动作至关重要,而随着器件运行速度提高,噪声也会增加。电气隔离技术能够实现在不同电位(如高压与低压)电路之间进行信号传输,从而有效解决上述问题,这也推动了市场对安全、高可靠且能在噪声环境下保持稳定运行的隔离器件的需求。除高可靠性外,随着设备持续小型化,隔离器件也比以往更需要具备更小尺寸和更长使用寿命。 此外,降低系统整体功耗是实现碳中和的核心,而低功耗运行已成为包括隔离器件在内的各类电子产品日益重要的要求 这四款新产品均采用东芝专有的磁耦合隔离传输技术[3],满足市场对高可靠性和长使用寿命的需求。同时,它们在隔离信号传输部分采用东芝新的电路技术,在保持最高25Mbps(最大值)稳定数据传输速度的同时,实现每通道0.2mA的低功耗。 新产品的隔离电压额定值为3,000Vrms(最小值),工作温度范围为–40°C至125°C,并支持2.25V至5.5V的宽电源电压范围。这些特性有助于设备稳定运行并降低功耗。 此外,新产品采用行业标准的SSOP16封装,满足紧凑设计需求。 DCL340L0B和DCL340H0B采用4通道配置,支持单向数字信号传输;DCL342L0B和DCL342H0B则通过2个正向通道和2个反向通道支持双向数字信号传输。 已量产的早期产品DCL341L0B和DCL341H0B采用3个正向通道/1个反向通道配置,支持包含SPI通信[4]在内的接口。 所有DCL34xx0B系列产品均适用于需要多通道配置的I/O接口应用,可根据应用需求灵活选择产品。 东芝提供适用于支持高速数据通信的工业设备的“DCL54xx01A系列”和“DCL52xx00系列”标准数字隔离器,以及适用于汽车应用的“DCM34xx01系列”和“DCM32xx00系列”标准数字隔离器,方便客户根据应用需求进行选择。 东芝将继续扩充面向工业和汽车设备的数字隔离器产品线,增加通道数和封装选择,并进一步提升性能,为实现碳中和作出贡献。除了提供实现光隔离的光耦外,东芝还将提供高品质隔离器件产品,确保在需要电气隔离的通信及控制系统中实现稳定运行。 ·应用: - 工业自动化(可编程逻辑控制器(PLC)、I/O接口等) - 现场设备(传感器、执行器等) - 电机控制 - 逆变器 - 开关电源 ·特性: - 低工作电流消耗:每通道0.2mA(典型值)[1] - 支持中速数据传输:tbps=25Mbps(最大值) - 宽工作温度范围:Topr=–40至125°C - 4通道配置: 4个正向通道、0个反向通道(DCL340L0B、DCL340H0B) 2个正向通道、2个反向通道(DCL342L0B、DCL342H0B) - SSOP16封装 ·主要规格: 注: [1] 基于1Mbps工作电流值计算,由(IDD1+IDD2)除以四个通道得出。 测量条件:VDD1=VDD2=3.3V,数据传输速率tbps=1Mbps,CL=15pF,Ta=25°C [2] 通信速度范围最高可达25Mbps [3] 一种信号传输方法,将调制芯片和解调芯片与绝缘层集成在同一封装中,并利用磁场传输信号。 [4] SPI(串行外设接口):一种同步串行通信方式,通过与时钟信号同步来发送和接收数据。 [5] 默认输出逻辑表示当输入信号未定义时,例如刚上电后或输入悬空时,数字隔离输出引脚所保持的初始逻辑电平。 [6] VDDI指输入侧的VDD1或VDD2 如需了解有关新产品的更多信息,请访问以下网址: DCL340L0B https://toshiba-semicon-storage.com/cn/semiconductor/product/isolators-solid-state-relays/standard-digital-isolators/detail.DCL340L0B.html DCL340H0B https://toshiba-semicon-storage.com/cn/semiconductor/product/isolators-solid-state-relays/standard-digital-isolators/detail.DCL340H0B.html DCL342L0B https://toshiba-semicon-storage.com/cn/semiconductor/product/isolators-solid-state-relays/standard-digital-isolators/detail.DCL342L0B.html DCL342H0B https://toshiba-semicon-storage.com/cn/semiconductor/product/isolators-solid-state-relays/standard-digital-isolators/detail.DCL342H0B.html 如需了解有关东芝隔离器/固态继电器的更多信息,请访问以下网址: 隔离器/固态继电器 https://toshiba-semicon-storage.com/cn/semiconductor/product/isolators-solid-state-relays.html 如需了解有关新产品在线分销商网站的更多信息,请访问以下网址: DCL340L0B https://toshiba-semicon-storage.com/cn/semiconductor/where-to-buy/stockcheck.DCL340L0B.html DCL340H0B https://toshiba-semicon-storage.com/cn/semiconductor/where-to-buy/stockcheck.DCL340H0B.html DCL342L0B https://toshiba-semicon-storage.com/cn/semiconductor/where-to-buy/stockcheck.DCL342L0B.html DCL342H0B https://toshiba-semicon-storage.com/cn/semiconductor/where-to-buy/stockcheck.DCL342H0B.html *本文提及的公司名称、产品名称和服务名称可能是其各自公司的商标。 *本文档中的产品价格和规格、服务内容和联系方式等信息,在公告之日仍为最新信息,但如有变更,恕不另行通知。
东芝 . 2026-07-16 574

Vishay推出兼顾超小体积、高可靠性和高性能的新款1.5 kV 车规级和商用版 IHDV 电感器
器件阻抗大于1 kW,有效滤除10 MHz 以上高频噪声;软饱和特性保障电感稳定性;可在+ 180℃ 高温下连续工作;并增强了抗震动、抗冲击性能 今天Vishay宣布,首度推出四款面向新一代车载、储能及工业系统的全新 IHDV 系列高压功率电感器---IHDV-0808AC-3A、IHDV-1008BB-3A 、IHDV-0808AC-30 和 IHDV-1008BB-30。产品分别采用0808(20mm × 14mm × 14mm)和1008(25mm × 20mm × 23mm)封装,专门满足1.5kV 隔离电压的设计要求。车规级IHDV-0808AC-3A 和 IHDV-1008BB-3A 以及商用版IHDV-0808AC-30 和 IHDV-1008BB-30可在180 °C 高温下连续工作,具有软饱和特性。 现有常规电感器隔离电压多为 350 V,为进一步提升耐压能力,日前发布的 Vishay Dale 系列产品采用 PET 塑料线圈绝缘骨架,隔离电压达1.5 kV。产品采用铁粉合金磁芯,其软饱和特性可在负载下保持电感稳定性,实现优异的纹波电流控制;器件还可承受高达额定温升电流 5 倍的瞬时浪涌电流。 在高频滤波应用中,IHDV 器件相比尺寸相近的铁芯复合电感器阻抗明显更高。0808 型器件在 80 MHz峰值频率下阻抗可达 1 kΩ,1008型器件在 25 MHz 时阻抗为 2.8 kΩ—在四倍工作频率下,阻抗仍为同类电感器的三倍。器件典型应用包括车载充电器、电池充电电路、功率因数校正(PFC)以及高压直流电池滤波。 IHDV-0808AC-3A 和 IHDV-0808AC-30 为紧凑型表面贴装封装,体积约为 1008 型器件的三分之一;而尺寸较大的 IHDV-1008BB-3A 和 IHDV-1008BB-30 采用插件固定方式,在恶劣工况下具备极佳的机械强度。四款产品均符合 RoHS和Vishay绿色标准,无卤素,;器件增设加固脚,进一步提升抗冲击与抗振动性能。此外,车规级 IHDV-0808AC-3A 和 IHDV-1008BB-3A 均已通过AEC-Q200 认证。 器件规格表: 产品编号 IHDV-0808AC-3A IHDV-0808AC-30 IHDV-1008BB-3A IHDV-1008BB-30 尺寸 (mm) 20 × 14 × 14 25 × 20 × 23 电感 (µH) 1.9 10 DCR 典型值 (mΩ) 1.3 2.7 DCR 最大值 (mΩ) 1.5 2.9 温升电流典型值 (A)(1) 30.0 30.0 饱和电流典型值 (A)(2) 110 68 SRF 典型值 (MHz) 83 22 AEC-Q200 是 否 是 否 (1) ΔT上升约40 °C时的直流电流 (A) (2) L0下降约30 %时的直流电流 (A) HDV 系列电感器现可提供样品并已实现量产,供货周期为 12 周。
Vishay . 2026-07-16 623

1.8mA立体声录音、106dB高保真—TP9243S 这颗音频ADC把“长续航+好音质”做到了新高度
在音频产品开发中,工程师们常常面临一个两难选择: 想要录音音质好,就得接受高功耗;想要续航长,就得牺牲录音质量。 尤其在做麦克风阵列、智能穿戴、无线麦克风这类产品时,这个矛盾更加突出——既要听得清,又要用得久。 作为芯片原厂,我们在设计TP9243S之初,就把这个行业痛点作为核心攻关方向。今天,我们从技术角度,聊聊这颗立体声音频ADC的设计思路与实测表现。 01 功耗做到1.8mA怎么实现的? 先看一组实测数据: 立体声录音功耗:1.8mA(48kHz采样率) 单声道录音功耗:1.0mA(48kHz采样率) 这些数据来自规格书电气参数表,在25℃、VDD=3.3V条件下实测得出。 很多工程师关心一个细节:这个功耗是芯片自身消耗,还是包括外围电路? 答案是:TP9243S内部集成了ALDO和DLDO,支持1.8V~3.3V单电源供电,无需外部LDO或电源管理芯片。 这意味着规格书上的1.8mA就是系统实际增加的功耗,没有隐藏成本。 为了做到这个水平,我们在架构设计上做了三件事: 优化模拟前端电路,降低静态电流; 采用低漏电工艺,减少待机损耗; 数字部分采用门控时钟技术,动态调节功耗。 最终结果就是:在106dB高信噪比的前提下,功耗做到行业领先水平。 对于电池容量有限的设备来说,这意味着: 智能手表、录音笔、无线麦克风,续航时间明显延长; 穿戴设备、会议麦克风,整机发热更低; PCB散热压力小,结构设计更自由。 02 106dB信噪比背后的设计考量 低功耗不难,难的是低功耗 + 高信噪比。 TP9243S的信噪比(SNR)达到106dB(PGA=0dB),总谐波失真+噪声(THD+N)为-92dB,采样率支持8kHz~192kHz。 这些指标在消费级音频ADC中属于第一梯队。 我们在设计时重点优化了三个环节: 差分输入结构 很多音频ADC为了节省引脚,采用单端输入。但单端输入抗共模干扰能力弱,在复杂电磁环境下,底噪会明显上升。 TP9243S采用差分输入(AINLP/AINLN、AINRP/AINRN),虽然多用了两个引脚,但在实际产品中抗干扰能力提升明显。尤其在做麦克风阵列时,多颗芯片协同工作,差分结构的优势更加突出。 内置抗混叠滤波器(AAF) 很多方案为了降低成本,省去外部抗混叠滤波电路,结果就是带外噪声混叠进通带,录音质量下降。 TP9243S在芯片内部集成了高性能抗混叠滤波器,无需外部滤波器件,就能保证20Hz~20kHz通带内的信号纯净度。 可编程PGA(0dB~42dB) 不同麦克风的灵敏度差异很大。有的驻极体麦输出只有几毫伏,有的数字麦输出能达到几百毫伏。 TP9243S的PGA支持0dB到42dB增益调节,步进3dB。工程师可以根据实际麦克风选型,在软件层面灵活配置,无需更换外围电阻,适配性更强。输入电阻典型值为12.5kΩ,可匹配大多数麦克风。 03 高度集成,外围电路能有多简单? 一颗音频ADC,外围电路能有多简单? TP9243S给出的答案是:电源、时钟、滤波、偏置,全在内部搞定。 我们把这几个模块全部集成进芯片: 封装上采用QFN 3×3-20,底部带散热焊盘。这个尺寸在音频ADC里属于紧凑型,适合智能穿戴、耳机、便携录音设备等空间受限的产品。 04 接口灵活,I²S/I²C和PDM都能接 在产品开发中,经常遇到这样的问题:主控芯片的音频接口五花八门,有的只有I²S,有的更偏好PDM。 TP9243S同时支持两种数字音频输出: I²S接口:标准音频接口,位时钟最高20MHz,左右声道时钟最高200kHz,适配绝大多数主控平台 1位PDM输出:走线少,适合对PCB布局敏感的场景 此外,TP9243S支持最多8颗芯片同步工作。做高通道麦克风阵列时,所有芯片共享同一时钟,采样同步,数据对齐,后端算法处理更简单。 I²C控制接口支持400kHz高速配置,增益、滤波器、音量都可以动态调整,方便软件调试和量产校准。 另外,芯片预留了数字麦克风输入(DMICDAT)接口(管脚8),可以直接接入数字麦克风。如果项目从模拟麦切换到数字麦,无需更换ADC芯片,硬件平台可以复用。 TP9243S单芯片典型应用电路图▲ TP9243S多芯片典型应用电路图▲ 05 原厂能提供什么? 做芯片,不只是卖一颗器件。我们更希望帮助客户把产品做出来、做好、做稳。 完整的参考设计 提供基于主流主控平台的参考原理图和PCB Layout。工程师可以直接复用,缩短开发周期。 驱动代码与调试工具 提供I²C配置例程、寄存器手册、调试上位机工具。软件工程师无需从头摸索寄存器配置,上手更快。 量产支持 提供量产测试程序,支持自动化校准; 提供ESD防护建议(芯片ESD符合工业标准),提升生产良率; 技术支持团队可协助解决量产过程中的异常问题。 稳定的供应链 TP9243S采用成熟工艺制程,供应链稳定,交期可控。对于生产端来说,这意味着不会因为芯片供应问题影响出货。 06 适合哪些产品? 根据实际项目落地情况,TP9243S在以下场景中表现突出: 麦克风阵列 / 回声消除系统 多芯片同步,采样率最高192kHz 106dB SNR保证回声消除精度 差分输入抗干扰,适合复杂电磁环境 智能穿戴 / 便携设备 QFN 3×3mm小封装 1.8mA低功耗,延长续航 PDM输出减少走线,降低PCB层数压力 AI智能音箱 / 闹钟 / 数字电视 内置PLL,适配12MHz、24MHz等常见主控时钟 集成麦克风偏置(20mA驱动能力),可直接驱动驻极体麦 -40℃~85℃工业级工作温度范围,量产一致性有保障 无线麦克风 / 录音笔 超低功耗,单声道仅1mA 高信噪比,录音清晰 单电源供电,电池直接供电 07 TP9243S-高音质+长续航 TP9243S是针对“高音质+长续航”市场需求推出的立体声音频ADC解决方案。 从技术指标上看: 106dB SNR、-92dB THD+N,录音够清晰; 1.8mA立体声功耗,续航够持久; 高度集成(PLL、LDO、AAF、PGA、偏置),开发够省心; I²S+PDM双接口、多芯片同步,适配够广泛。 从原厂支持上看: 完整的参考设计与驱动代码; 稳定的供应链与量产支持; 专业的技术团队,随时响应客户需求。 一颗好的芯片,应该让工程师少踩坑、让产品更好卖、让生产更省心。 如果你正在选型音频ADC,欢迎联系我们获取参考设计原理图、驱动代码或评估板。实测数据可提供,量产支持可对接。 让音频采集,不再成为产品续航的短板。 *注:本文数据基于TP9243S规格书(版本V1.02)电气参数表,测试条件为25℃、VDD=3.3V、VDDIO=3.3V、采样率48kHz、1kHz正弦波输入。实际应用效果可能因主控平台、PCB布局及使用环境略有差异。如需技术支持或样品申请,请联系我们。*
音频ADC
天源中芯公众号 . 2026-07-16 693

打破传统!AR1105模组仅用3颗麦克风实现360°声源定位
在智能硬件开发的“红海”中,声源定位(Sound Source Localization)一直是一个让开发者“又爱又恨”的功能。 爱它,是因为它能赋予设备“耳听八方”的灵性,是人机交互(HMI)中极具科技感的一环;恨它,是因为传统实现方案门槛太高——往往需要堆砌4到8颗麦克风阵列,还得在MCU或DSP里跑复杂的GCC-PHAT或TDOA算法。这不仅疯狂吞噬MCU的算力,还极大地增加了PCB的面积和BOM成本。 最近在芯查查平台调研低功耗语音交互方案时,我们发现了一款打破行业惯性思维的模组——AR1105六向音源定位模组。它走了一条极具“极客精神”的极简路线:仅用3颗数字麦克风,通过硬件级DSP直接输出方位IO信号。 对于想要快速落地语音交互、机器人寻声功能的开发者来说,这绝对是一个值得深挖的“降维打击”方案。今天我们就从原理到实战,彻底拆解这款模组。 极简架构:3麦如何撬动360°定位? 很多工程师的第一反应是:“3颗麦克风怎么做360°定位?这不是至少需要4麦或环形阵列吗?” AR1105的核心逻辑非常反直觉,它打破了“麦克风越多定位越准”的刻板印象。模组本体尺寸仅为 37mm×26mm,却集成了自研的DSP算法芯片。它不需要庞大的麦克风阵列,只需要外部搭配 3颗间距为10mm的数字麦克风,组成一个紧凑的等边三角形阵列。 它的工作原理主要基于“双麦心形指向性技术”: 硬件层解算:模组内部将3颗麦克风两两组合,利用声波到达不同麦克风的相位差,在硬件底层完成波束成形。 空间离散化:系统上电后,DSP会实时刷新数据,将360°圆周空间离散化为 6个60°的扇区(0°、60°、120°、180°、240°、300°)。 IO直出:一旦捕捉到有效声音,对应的IO端口(DO0-DO5)就会输出高电平。 对于主控MCU来说,根本不需要知道什么是波束成形,也不需要跑FFT。你只需要像读取按键(GPIO Input)一样读取状态,就能瞬间知道声音来自哪个方向。这种“算力下沉、接口简化”的设计,极大地降低了开发门槛,让几块钱的51单片机也能做声源定位。 接口与电气:工业级的“鲁棒性”设计 做硬件的朋友都知道,实验室里的Demo好做,但能抗住工业现场干扰的才叫好产品。AR1105在电气特性上表现得相当“皮实”,非常适合嵌入到各类IoT设备中。 核心电气参数表: 表格 下载为表格 导出为图片 参数项 规格指标 备注 供电电压 4.0V - 6.5V 完美适配5V系统,兼容车载/工控环境 工作电流 28mA - 31mA 低功耗设计,比同类产品节能约30% 工作温度 -20℃ ~ 85℃ 宽温设计,适应户外或车间环境 音频输出 MIC OUT (模拟) + I2S (数字) 16kHz/16bit,支持同步录音 亮点解析: 宽压供电:很多模组对电源纹波极其敏感,而AR1105支持4-6.5V宽压,意味着在电池供电电压波动时也能稳定工作。 音频解耦:模组同步输出了模拟音频和I2S数字音频。这意味着你在获取方位的同时,还能拿到干净的原始音频流用于后续的离线语音识别(如LD3320等)或云端录音,实现了“定位”与“拾音”的完美解耦。 实战避坑:硬件集成时的“黄金法则” 虽然AR1105号称“免算法、零代码”,但在实际画板和结构设计(ID/MD)中,有几个物理层面的细节决定了成败。根据Datasheet和实测经验,这里必须给大家划个重点: 1. 麦克风的一致性是关键(BOM选型) 官方强烈建议选用误差率在 ±1dBFS以内 的数字麦克风。 推荐型号:灵敏度为 -26dBFS 或 -29dBFS 的型号。 避坑指南:如果3颗麦克风的灵敏度一致性差,会导致心形指向性畸变。后果就是:声音明明在左边,模组却告诉你“在右边”。建议在芯查查上通过“参数对比”功能严格筛选物料。 2. 布局决定上限(PCB设计) 间距严格:3颗麦克风必须严格保持 10mm 的间距(中心对中心)。 共面性:拾音孔必须处于绝对同一平面,高度差不能太大。 密封性:结构设计时务必保证声学孔的密封性,避免机身内部噪音干扰,同时防止漏音导致相位计算错误。 3. 预留启动时间(软件逻辑) 模组上电后,内部DSP需要进行初始化和环境底噪学习,耗时约 7-9秒。 代码处理:在编写代码时,务必做好延时处理或状态检测,不要一上电就急着读取IO口,否则前几秒的数据是无效的。 总结:为什么选择AR1105? 在当前的嵌入式市场,AR1105用极简的硬件架构解决了复杂的声源定位问题。 对于算法工程师:你不用再为了TDOA在低端MCU上优化汇编代码了。 对于硬件工程师:你不用再为了麦克风阵列的走线头疼了。 对于产品经理:BOM成本可控,且开发周期极短。 对于智能机器人、摇头摄像头、会议追踪系统或者简单的语音玩具来说,它提供了一个高性价比、低开发门槛的“交钥匙”方案。如果你不想在算法的海洋里“卷”生“卷”死,这种硬件级的降维打击方案,或许就是你正在寻找的答案。
声源定位,拾音降噪
原创 . 2026-07-16 763

巧用图像传感器模块参考设计(PRISM),简化成像设备从设计到制造的全流程
摘要:本教程围绕安森美(onsemi)图像传感器模块参考设计(PRISM)展开,聚焦成像设备从设计到制造的全流程优化需求,系统介绍PRISM方案的核心架构、功能模块、性能特性及生态接入方式,为成像设备从业者提供从设计到制造全流程的实操指导。本文为第一部分,将介绍PRISM简介、实现全新器件开发流程、视觉系统五大核心器件等。 一、 引言:从设计到制造 创新,尽管字面意为全新创造,却绝非凭空而来。创新者勇于另辟蹊径,也难免遭遇挫折,有时甚至是惨痛失败。过往经验会告诉产品创新者,曾经尝试的方案是否可行,也会沉淀下那些从一开始或经过一段时间后证明行不通的方法与路径。 电子成像技术领域的每一项伟大新创意,都建立在现有平台之上。无论是成像产品制造领域的新手,还是拥有丰富经验的行家,创新都需要一个切实可行的起点作为基础。有时,您恰恰需要这样一个基础,才能发现什么是行不通的。 George Eastman在对其1888年推出的柯达便携式手持相机进行创新改进时,深思熟虑后得出结论:他拥有专利的镜间快门结构,难以在大批量生产的设备中持续生产与维护。这样的洞察,Eastman或许曾希望自己能早三年拥有。 资料来源:美国国家档案馆 二、 PRISM简介 如今,成像平台厂商完全可以采用创新方案,无需从头开始、重复造轮子,不必重蹈Eastman当年重新研发快门结构的覆辙。安森美推出的Premier图像传感器模块参考设计(PRISM)平台,是一套预先优化的子系统解决方案,旨在简化数字成像产品的开发流程。PRISM为创新者提供低成本、预调校、已优化的模块化器件,这些器件经过精心设计、可无缝协同,专为产品原型构建量身打造。 PRISM模块 PRISM模块是一款经过严格测试、充分验证的高品质模块参考设计,旨在确保出众的成像性能。该模块通用性强,可适配各类工业及商用传感器,即便在客户早期样品验证阶段也能游刃有余。它通过采用标准化通用接口,确保传感器之间灵活适配、无缝切换。 安森美提供转接板,确保成像器件可与SoC平台无缝集成。对于批量生产,基于PRISM开发的器件可轻松适配安森美图像接入系统(IAS)。如此一来,采用PRISM模块的器件可与PRISM生态合作伙伴的其他硬件转接板及开发套件集成。 PRISM有助于简化成像产品原型构建流程,加快设计进度,缩短产品上市周期。对于成功攻坚克难、最终实现量产的典型图像传感器件应用而言,PRISM最多可将产品上市时间缩短六个月。 安森美PRISM模块,搭载AR0830图像传感器 三、 实现全新器件开发流程 PRISM能够缩短设计周期、降低开发成本,解决成像产品设计师在为全新设计或前沿的成像应用构建原型时所面临的难题。很多时候,基础技术与架构细节往往成为成像应用设计推进的阻碍,即便是仅仅找到可协同工作、能代表最终设计的合适器件,也困难重重。 在任何涉及光学元件的产品工程项目中,让所有部件适配有限空间并非最大障碍。对各类光学设备运行而言,光线、空间和气流与供电同样至关重要。在处理这些精密器件时,任何因镜头景深调节失准、传感器阵列白平衡失效或接口连接不可靠所造成的拖累都是不可接受的。 四、 视觉系统五大核心器件 典型视觉系统由许多要素组成,包括光学元件(镜头)、图像传感器、传感器接口、图像信号处理器和应用软件或人工智能(AI)。 1. 光学元件(镜头) 镜头的作用是将光线聚焦至传感器元件。而要实现高效成像,镜头必须与传感器的光学规格匹配。获取并按需调整所需的视场角(FOV)、景深(DOF)及有效传感器分辨率,均取决于器件设计师对镜头的选型。 与所有光学相机原理一样,镜头光圈与景深呈反比关系,并会影响视场观感。镜头光圈越大,景深越浅,视场角看起来越窄;反之,光圈越小,景深越深,画面清晰区域更大,视场角也显得更宽。然而,缩小光圈以获得更深的景深通常会导致分辨率降低。倘若图像传感器对低分辨率场景的处理效果不佳,即便目标是呈现更深的景深,最终画面仍可能模糊不清。 2. 图像传感器元件 图像传感器是一种半导体器件,其作用是对镜头投射到其上的光学图像进行光电转换,生成可被还原的数字信号。其内部集成了由相互关联的电容组成的阵列,每个电容都是一个感光单元,即像素。 CMOS结构的基础是感光元件阵列。两个移位寄存器产生脉冲信号,分别控制水平与垂直扫描电路,按行、列依次对每个元件进行寻址。这些电路可对每一行元件先执行复位,然后重新扫描。在复位与扫描之间,每行像素会对入射光进行光电荷积分。系统会采用相应的快门机制:可以是卷帘快门这类机械快门,也可选用电子快门(逐行扫描相机通常采用电子快门,无需进行信号隔行扫描)。 3. 图像信号处理器(ISP) 图像信号处理器(ISP)对图像传感器采集的原始数据进行数字化处理,并将其重新解释为实用可靠、误差极低的数据格式。ISP通常承担的处理任务包括:去马赛克、降噪、色彩校正、伽马校正等。 4. 传感器/处理器接口 物理接口负责确保图像传感器与图像信号处理器所在的片上系统(SoC)之间实现完整、畅通的通信。由于这两类器件在设计与制造中采用不同行业标准,通常会衍生出多套独立接口规范,业界常用标准多达五种以上。 5. 应用处理器(AP) 应用处理器(AP)是成像系统的核心数字处理单元。该器件也可集成图形处理器,用于在显示器或屏幕上渲染画面;同时集成数字信号处理器(DSP),以实现图像增强、图像处理等专门的处理功能。设备所采用的、供用户操作的软件或固件,均由AP统一调度。 未完待续,后续推文将陆续介绍评估套件、AP1302协处理器、多种图像传感器等。
安森美 . 2026-07-16 602

冰箱耗电居高不下?关键不在压缩机,是你的MOS管选错了!!
冰箱作为全年运行的家电,日常耗电累积量大,如今消费者选购冰箱,除了关注基础保鲜效果,更看重一级能效省电、运行低分贝静音、金属底板散热的核心体验。行业产品也普遍朝着这些方向升级。 但存在一个普遍难题:想要做到冰箱一级能效省电、低分贝静音运行,整机硬件成本会上涨。 冰箱的耗电核心主要集中在变频压缩机的电控系统,传统mos管的短板,也是整机难以达到一级能效标准的关键。因此,通过国产mos管迭代升级,实现「低能耗+低成本」平衡,已经成为冰箱行业的刚需。 行业现状:高耗能的三大核心困境 轻载损耗高,难以达成超低耗标准 冰箱日常大多是低速恒温的轻载运行状态,普通MOS管工作时内阻大,持续产生热量、损耗电能,日积月累耗电差距十分明显,无法满足长效一级能效设计要求。 开关卡顿,运行分贝高、噪音杂乱 冰箱依靠PWM高频调速精准控温,老旧器件开关反应慢、参数不稳定,容易导致压缩机转速不稳、频繁启停。不仅额外耗电,启停顿挫还会产生明显工作噪音,即便机身做了静音处理,整机运行分贝依旧偏高,静音体验差。 热衰减快,浪费金属底板散热优势 现在新款冰箱大多升级金属底板,导热快、散热均匀、辅助整机降温稳压。但普通MOS管耐温性差、温漂大,冷热环境交替下性能快速衰减,工作发热严重,不仅自身损耗飙升,还会加重机身散热负担,白白浪费金属底板的优质散热性能,越用越费电、越用越吵。 合科泰mos管全场景低耗能选型指南 想要解决这些问题,核心就是更换低损耗、高稳定的优质MOS管。合科泰三款MOS管精准适配冰箱全场景工况,兼顾一级能效、低分贝、稳散热,非常适合冰箱产品升级需求。 HKTD7N65压缩机逆变核心,一级能效+静音 作为冰箱变频逆变电路的核心器件,适配冰箱常规电路工况,采用新一代超结沟槽工艺,大幅降低导通内阻与栅极电荷,开关损耗更低、运行更稳定。从源头稳定的低耗工作状态,可让冰箱持续贴合一级能效标准,降低运行分贝,适配冰箱静音运行需求,整机温控更稳、省电效果更持久。 HKTD90N03风机/化霜系统,降本降耗+稳散热 适配冰箱风机循环、自动化霜等长期不间断工作的低压大电流场景,极大减少辅助设备持续工作的发热损耗。同时器件温漂系数低、长时间运行不易发热、性能不衰减,有效降低冰箱整机基础能耗。同时精准配合金属底板散热结构,减少整机积热,减轻散热压力,让机身散热优势完全发挥。 AO3402待机小信号,补齐微损耗短板 主打超低漏电、极速响应,体积小巧适配性强,专门优化冰箱待机电源、低压信号开关场景。能有效解决传统mos管待机漏电、微量耗电累积的问题,精细补齐节能短板,实现冰箱运行、待机全场景低耗。 最后总结:mos管迭代,产品优质升级 整套选型精准适配新一代冰箱升级需求:性能全面迭代、损耗更低、稳定性更强。合科泰MOS管损耗更低、调速更顺滑、运行更安静、热稳定性更强,能充分发挥冰箱一级能效、低分贝、金属底板高效散热的优势,适配当下家电国产化、节能化、高性价比的发展趋势。
合科泰
厂商投稿 . 2026-07-16 609
- 1
- 2
- 3
- 4
- 5
- 6
- 500