产品 | 川土微电子CA-PM79263x-Q1集成电源、通信、高边驱动,支持功能安全ASIL-B的系统基础芯片
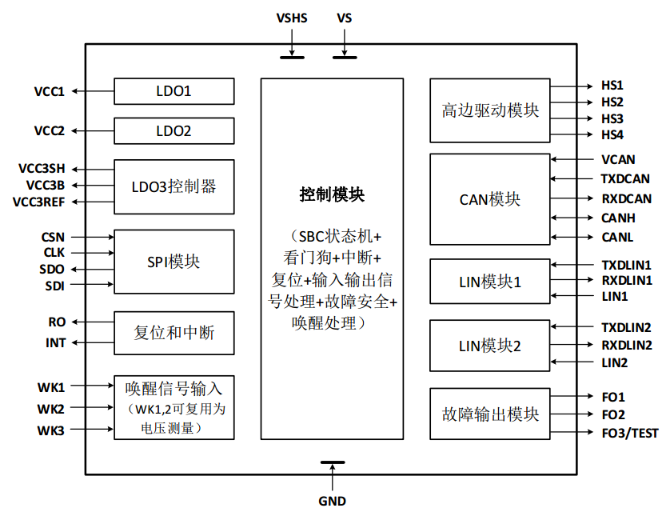
川土微电子CA-PM79263x-Q1系列系统基础芯片新品发布!该产品具备高集成、低功耗、高性能CAN/LIN通信、功能安全ASIL-B等特性,助力汽车电子电气系统实现小型化、长静置时间、高通信速率、高安全等需求。 小型化:解决分立方案的PCB面积过大,布板复杂的问题 长静置时间:解决整车静置功耗较大,导致静置时间不够长,电池馈电无法启动的问题 高通信速率:解决电子电气架构演进过程中通信数据较大,节点数量较多时速率受限的问题 高安全:通过充分的安全机制,解决芯片运行时随机硬件失效带来潜在的危害 产品概述 CA-PM79263x是一款单片集成电路芯片,采用裸露焊盘QFN-48 (7 mm x 7 mm) 功率封装。该器件专为汽车中需要供电,CAN和LIN收发器通信,以及高边驱动等功能的应用而设计,可提供微控制器的主电源,LIN和CAN总线网络(包括CAN局部唤醒功能)的接口以及高边驱动等功能。产品设计遵循功能安全完整的开发流程,集成模拟电路ABIST、关键接口电平的监测功能,专用FO输出管脚指示系统故障,具有CRC校验的数字SPI接口,可实时监控系统状态,并在系统异常时,引导系统进入Fail-Safe模式等。符合ISO26262 规定的ASIL-B标准,支持客户产品获得ASIL-B认证。 为了支持这些应用,系统基础芯片(SBC)提供了以下主要功能: 用于微控制器电源的5V/3.3V低压差稳压器 (LDO); 一个5 V低压差稳压器可用于其他负载供电; 另一个可驱动外部PNP晶体管的5V/3.3V或3.3 V/1.8 V的LDO控制器,可单独给其他负载供电,或与主稳压器VCC1并联使用共享负载; 支持CAN FD和CAN局部唤醒(包括FD 容忍模式)的高速CAN收发器和LIN收发器共同用于数据传输; 具有内置保护功能的高边开关以及用于控制和监控芯片的16位串行外设接口(SPI)。 此外,还集成了一个可配置的超时/窗口看门狗电路,具有复位功能、三个故障输出端和欠压复位功能。 该器件提供低功耗模式,以最大限度地降低在持续连接到电池应用场景下的电流消耗。可以通过总线报文、双电平敏感监控/唤醒输入或循环唤醒从低功耗模式唤醒。 本次发布细分料号有4种,对比如下: 产品特性 产品设计遵循功能安全完整的开发流程,符合ASIL-B标准 - 电源路径的监控、关键信号路径卡滞监控、模拟电路ABIST 休眠模式下超低功耗,典型值为12µA 高性能CAN/LIN接口 - 1路CAN SIC,具备振铃抑制及强EMC能力,支持经典CAN和8Mbps CAN FD,支持选择性唤醒CAN局域网络中的部分节点(包括CAN FD容忍模式),符合 ISO 11898-2:2024 和SAE J2284-1到SAE J2284-5 标准 - 2路LIN,具备低功耗与强抗干扰,LIN收发器符合 LIN2.0、LIN2.1、LIN2.2、LIN2.2A和ISO 17987-4:2016(12V)电气物理层(EPL)标准;符合面向车辆应用的SAE J2602-1 LIN 网络标准和面向车辆应用的SAE J2602-2 LIN 网络标准符合性测试 - CAN和LIN总线都支持±42V的短路保护,适用于12V电池供电系统 3路LDO:两路LDO和一路LDO控制器,分别是: - VCC1:5V 或3.3V(尾缀带“V”)输出电压,250mA输出电流,可给系统MCU供电 - VCC2:5V 输出电压,100mA输出电流,可给CAN收发器和其他离板负载供电 - VCC3:a、搭配外部PNP晶体管实现稳压输出,或 b、可与VCC1并联使用提高输出电流能力,给系统的微控制器或其他负载供电 集成4路智能高边,可驱动150mA负载,具有开路、过流检测和保护等功能 集成三路可编程唤醒输入管脚(WKx),支持42V高压接入 集成三路故障引脚(FOx),其中FO2和FO3可复用为可编程的两路GPIO接口,可配置为唤醒输入、低侧开关或高侧开关 高级ECU电源管理系统 - 通过ISO 11898-2:2024定义的CAN 唤醒序列进行远程唤醒(WUP)或者选择性唤醒帧(WUF)进行远程唤醒 - 通过WAKE管脚进行本地唤醒,本地唤醒可以被关闭以降低功耗 - 本地唤醒可以被关闭以降低功耗 - 支持唤醒源识别 故障指示、保护和诊断特性 - 16-bit SPI 用于配置,控制和诊断,同时具有CRC校验功能(尾缀带“C”) - 驱动器显性超时保护及诊断 - 可配的看门狗定时器 - 在看门狗定时器超时模式下,循环唤醒 - 过温报警和关断 - VS、VSHS管脚欠压保护和恢复 - VCC1和VCC2 过压/欠压检测和保护 - 供电管脚、WAKE管脚和CAN总线管脚可以承受ISO 7637-3中定义的脉冲1,2a,3a和3b - 先进的系统和收发器中断处理 - 集成模拟电路ABIST、关键接口电平的stuck监测功能 - 最多三路故障输出管脚指示系统故障,可引导系统进入Fail-Safe模式 针对不同应用,可以配置不同的上电和复位行为,以及系统基础芯片工作模式的配置 结温范围:-40°C 至 150°C 符合面向汽车应用的AEC-Q100 Grade 1 标准 可提供QFN48封装(wettable flank) 应用场景 车载域控制器 车身电子模块 车载照明系统 智能辅助驾驶系统 新能源汽车热管理系统 车载传感器 车载娱乐系统 汽车动力系统 典型应用
SBC
川土微电子chipanalog . 2026-07-03 2219

方案 | 无感FOC,静享清凉——基于中微爱芯AiP32F7532的落地扇解决方案
【行业介绍】 落地扇作为常见的传统小家电,凭借轻便灵活、低能耗、通风换气效率高、适配场景多的优势,成为家用通风降温的核心配套电器,市场应用需求稳定且广泛。随着消费者对风扇体验的提升,带有静音电机、仿自然风控制、定时控制、摇头控制和遥控远程控制的落地扇产品迎来了更多的市场需求。 中微爱芯推出一款落地扇解决方案,可帮助客户快速完成产品开发,并兼顾产品的稳定性、低成本。同时,也可满足客户对功能高度自由化定义的需求。 【整体解决方案】 该方案采用中微爱芯AiP32F7532芯片。AiP32F7532是一款基于ARM Cortex-M0的电机专用MCU,最高主频60MHz,内置32KB的FLASH,4KB的SRAM,并集成高级定时器TIM1,USART,ADC,DMA等常用的外设资源。此外,为满足电机控制的需求,该芯片内部还集成了两个运算放大器,两个比较器以及一个硬件除法器,极大精简了外围电路,加快了算法运算速度,适用于各类电机控制应用场景。 本方案基于电机控制板开发,并设计了多种外部接口进行人机交互,可实现旋钮启停、无线遥控(RF433)启停、旋钮调速、遥控调速、遥控定时(1-3h)、按键启停摇头、遥控启停摇头等多种落地扇核心功能。同时,软件采用无感FOC算法,实现静止、顺风、逆风下的稳定启动以及平稳运行。 【方案特点】 宽电压适配:支持110VAC-250VAC宽电压输入,适应不同地区电网环境 宽调速范围:转速可调范围300RPM-1350RPM,满足不同风量需求 双模调速控制:支持旋钮无极调速与RF433遥控档位调速,操作灵活随心 多功能集成:集成摇头控制、定时(1-3h)功能 多重保护机制:过欠压保护、堵转保护、过流保护、缺相保护、过温保护,运行安全无忧 无感FOC算法:结合顺逆风检测技术,轻松实现带速状态下的平滑启动,运行平稳、静音舒适 本款落地扇方案,采用无感FOC控制方式,运行时支持旋钮无极调速以及遥控器丰富的风速档位控制,可实现任意启停,任意风量的控制,满足不同的应用需求。该方案对电压的适配范围宽泛,同时各类保护功能充分完善,为夏日带来稳定可靠的清凉。 【典型应用图】 实物展示: PCB正面: 【芯片资源】 适用于落地扇的高性价比MCU: 适用于电机控制的LDO: 适用于电机控制的运放: 适用于电机控制的驱动: 【结语】 中微爱芯落地扇控制板解决方案,以AiP32F7532高性价比MCU为核心,为客户提供了一整套稳定、可靠、易开发、高度自由化定义需求的落地扇控制方案。该方案以无感FOC控制为核心,结合了丰富的人机交互控制方式,在电机控制稳定性,用户操作便捷性和用户体验良好性方面有着显著的优势,能够满足不同家用场景下的降温、通风需求。 如果想了解更多产品资讯,请联系我司授权代理商或销售工程师。
无感FOC控制
中微爱芯官网 . 2026-07-03 154

产品 | 中微爱芯发布7款AiP74HC、HCT系列车规电路
车规电路
中微爱芯官网 . 2026-07-03 294

企业 | 中微爱芯-2026慕尼黑上海电子展完美收官!
2026年7月1日至3日,为期三天的2026慕尼黑上海电子展(Electronica China)在上海新国际博览中心盛大开幕。 中微爱芯本次展出通用逻辑、信号链、触摸MCU、电机控制MCU、LDO等产品线,并推出数十款通过AEC-Q100认证的车规级逻辑芯片、信号链芯片,行业方案覆盖汽车电子、工业控制、智慧安防、消费电子等领域,全方位展现了中微爱芯多元化的技术积累。依托持续的技术突破、精准的市场洞察、丰富的产品矩阵,中微爱芯不断为行业客户提供整体解决方案。 汽车电子应用方案,高可靠车规芯片赋能智能出行 汽车电子展台重点展示了六款汽车应用方案,覆盖电动助力转向系统(EPS)、车载充电机(OBC)、车载无线充、轻型电动汽车牵引驱动、动态LED车灯驱动模块以及车身控制模块(BCM)。并展出数十款已通过AEC-Q100测试的车规级产品包含逻辑门、触发器、反相器/缓冲器、多路复用器、锁存器、寄存器、运算放大器、比较器等。 中微爱芯车规级芯片明星产品 触摸MCU 触摸展台集中展示检水、滑轮滑条、隔空触摸等demo以及落地扇、智能饭煲、咖啡机、空气炸锅、制冰机等生活电器方案,现场为客户展示触摸MCU的高灵敏度和多容量、多封装选择。 电机控制MCU 展区重点呈现电动工具平台、电锯链、水泵、角磨机等自研方案 LED恒流驱动精准调光,赋能消费电子与智能家电显示升级 消费电子与智能家电行业展台重点展示了一系列恒流显示驱动芯片,为设备终端交互体验提供关键支撑,助力智能家电与消费电子显示效果全面升级。 LED恒流驱动芯片-矩阵型 LED恒流驱动芯片-直驱型 LED恒流驱动芯片-低功耗型 工业控制与智慧安防全面覆盖,精准感知构筑可靠基石 工业控制与智慧安防行业展台同样吸引了大量观众驻足。现场展出了光电传感器、光纤传感器、PLC以及安防球机等。 中微爱芯的销售及技术团队在现场根据客户的具体使用需求,提供了专业的解决方案讲解。 展会期间,中微爱芯还受邀走进电子发烧网2026慕尼黑上海电子展现场视频直播间,分享最新公司车规产品布局与行业应用,直播间互动频繁,气氛热烈。 慕展三日,意犹未尽。中微爱芯感谢每一次驻足与深谈,落幕不散场,下一程再见。
电机控制MCU
中微爱芯官网 . 2026-07-03 203

企业 | 慕展高光收官!GD32 MCU硬核秀实力,多场景方案赋能产业升级
上海慕尼黑电子展圆满落下帷幕,GD32 MCU凭借强劲性能与完善生态实力吸睛,深耕具身智能、物联网消费电子、工业、数字能源各大赛道。 具身智能:基于GD32H7系列MCU的六轴机械臂 本次慕展重磅亮相兆易创新全栈自研的基于GD32H7系列MCU的六轴机械臂方案,可实现从底层伺服驱动到上层运动算法全链路自主可控。关节驱动器采用GD32H75E芯片,完成电机底层伺服控制,搭载17/18位双绝对值编码器实现高精度位置采集,支持EtherCAT CoE通信,兼容CiA 402协议,覆盖六种主流伺服控制模式。 上位机搭载地瓜S600,可实现任务调度、轨迹规划、示教回放与设备监控,依托自研算法完成离线OBB避障、实时力控防撞、RRT快速回零、拖动示教等功能,可广泛用于协作搬运、工业装配、教学实训等场景。 方案配套兆易创新自研GD Robocontrol可视化配置软件,集成机械臂三维可视化、六轴关节实时状态监测、单轴独立调试、智能运动规划、拖动示教、轨迹回放与多重安全防护等核心功能。软件基于ROS 2实时订阅各关节运行数据,依托VTK OpenGL引擎渲染机械臂三维模型,可视化直观呈现设备运行状态。用户可直接设定目标关节角度或末端位姿,系统自动完成RRT路径规划与碰撞检测后驱动机械臂平稳运行;拖动示教模式下可自定义示教起止点位、存储运动轨迹、一键复位初始位置并正向复现作业路径,同时实时监测通讯链路、碰撞告警与整机运行参数,极大方便现场调试、功能验证与产品演示。 基于GD32H75E系列MCU的机器人关节方案 本方案搭载GD32H75EYMJ7高性能主控芯片,硬件资源丰富,可完美适配机器人关节高速控制场景。采用了GaN功率器件搭建高效驱动电路,设置200ns死区时间,最高PWM开关频率可达100kHz,有效提升整机驱动效率。此外该方案还具有完善的通信接口配置,集成了EtherCAT从站与双路百兆PHY,同时支持CAN FD、RS485/422等多种工业总线,可实现多路实时通信,位置采集端兼容双路16bit KTM5910磁编码器、SPI编码器以及多摩川BISS C接口,位置检测精度高。整套硬件采用了48V供电设计,搭配多路电平转换、运算放大器采样、比较器保护及全范围预驱电路,系统运行稳定可靠。 物联网和消费电子:基于GD32H737系列MCU的3D打印机 本方案采用Cortex®-M7内核GD32H737高性能MCU,600MHz主频搭配大容量存储与丰富外设资源。通过通用低成本H桥实现四轴步进微步驱动,依托芯片强劲算力替代多颗专用步进控制芯片,大幅缩减硬件成本。搭配自研四轴同步细分、堵转回零、自适应降电流等算法,电机运行平稳静音、低功耗低发热。 基于GD32M531系列MCU的家用变频空调方案 依托Cortex®-M33内核GD32M531电机专用MCU,打造高可靠、高性价比家用变频空调解决方案。支持压缩机单周期闭环启动、风机顺逆风自适应运行,低频6Hz稳定运转,谐波与转矩抑制表现优异。支持整机通讯+串口人机交互,变量波形可视化,集成调试更高效。 基于GD32F50x系列MCU的洗地机主控地刷Wi-Fi三合一方案 本方案基于GD32F50x系列MCU开发,驱动一台洗地机风机BLDC电机、四台直流有刷电机(三个滚刷电机和一个水泵电机)及一台用于机械臂伸展的舵机。 方案还搭配了GD32VW553 Wi-Fi&BLE MCU的拓展板通信,实现远程固件升级与电机实时控制,搭载串口LCD实时展示电机运行参数、电流及故障信息,支持语音开关机、按键启停与模式切换,支持涂鸦云端实时显示当前洗地机的工作状态,实现水泵、多个滚筒电机、风机、舵机的云端操控。 基于GD32H7系列MCU的民用飞控方案 方案基于搭载Cortex®-M7内核的GD32H7系列MCU打造,强劲算力可兼容多款主流飞控操作系统。硬件端搭载双六轴IMU,有效提升姿态解算精度与运行可靠性;搭配GDY1121高精度气压计、机载磁力计,精准获取高度数据与航向信息,辅以GD25Q128 SPI NOR Flash实现飞行数据黑匣子存储,同时集成OSD字符叠加功能。外设方面预留6路独立串口,可同步接驳图传、接收机、GPS及各类传感器,8路硬件定时器支持4至8轴电机PWM/DShot信号输出,能够灵活适配各类多旋翼飞行器开发需求。 基于GD32VW553系列MCU的TuyaOpen AI智能体与物联网设备互联解决方案 本方案以GD32VW553 RISC-V无线MCU为硬件核心,依托集成Wi-Fi 6+BLE5.2双模无线通信、充足片上存储与丰富外设接口的硬件优势,支持TuyaOpen嵌入式开发框架,可搭配涂鸦云低延迟多模态AI(拖拽式工作流),集成顶尖模型(ChatGPT、Gemini、Qwen、Doubao等),可快速接入涂鸦海量物联网生态,轻松构建AI智能体硬件。 基于GD32VW553系列MCU的百度AI语音方案 本方案采用GD32VW553芯片,搭载160MHz主频RISC-V内核,支持Wi-Fi 6与Bluetooth LE 5.2双模无线通信;依托百度AI语音算法优化迭代,设备本地集成回声消除、增益控制功能,搭配云端3A算法大幅提升语音识别准确率,实现高精准、高灵敏度的智能语音交互,可适配多种智能语音终端应用场景。 工业和数字能源:基于GD32H77D系列MCU的LVGL GUI图形显示方案 本LVGL GUI图形显示方案基于GD32H77D高性能MCU开发,芯片主频可达600MHz,通过2通道MIPI-DSI接口驱动720×1280分辨率液晶显示屏,搭配时钟频率166MHz的32位SDRAM保障流畅画面缓存;依托IPA硬件2D图像加速器,可高效实现图片缩放、旋转、图层混合等图形处理能力。 基于GD32H77x系列MCU的QT GUI图形显示方案 基于Qt for MCUs(QUL)2.12.1版本开发,硬件选用搭载Cortex‑M7内核、主频高达600MHz的GD32H77x系列高性能MCU,直观展现兆易创新高端MCU强劲的图形处理能力,包含宫格拖拽、石英钟表、HSV取色、多语言拼音输入、18段实时频谱、图表入场动效、Ken Burns画廊及离线矢量地图导航,以丰富交互与流畅动画重新定义MCU图形性能边界。 基于GD32G5系列MCU的1kW一拖二单级型光伏微型逆变器 该方案采用DAB拓扑,使用GD32G5系列MCU以及纳微半导体GaN器件实现了单级型一拖一微型逆变器,具备高效率、低损耗、高集成度与成本优化的特点。具有可模块化扩展和抗失配能力强的核心优势,配备了丰富的系统软、硬件保护,确保系统的可靠运行,满足户用光伏应用所需。
MCU
GD32MCU . 2026-07-03 2674
产品 | 顺络电子MWTP 系列高性能一体成型电感正式发布
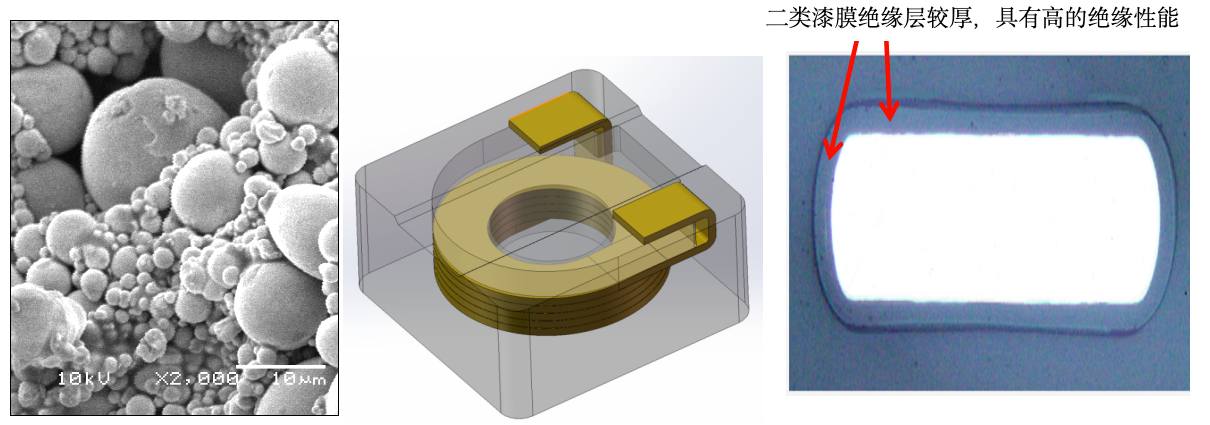
顺络电子高端功率器件研发制造平台,正式推出MWTP 系列高性能一体成型电感。该系列在热压工艺平台基础上,采用T-U core结构设计、扁线绕组与自研高绝缘合金磁粉,具备超大电流、超低 DCR、低损耗、高功率密度、高可靠性、全磁屏蔽等核心优势,覆盖 AI 服务器、新能源汽车、通信设备、工业能源、高端消费电子、机器人等主流场景,是面向下一代高功率供电系统的解决方案,全面助力高端电子元器件国产化替代。 背景 当前,AI 算力爆发、新能源汽车高压化、工业自动化升级、高端消费电子轻薄化,推动一体成型电感进入量价齐升、国产加速的黄金发展期。高端消费电子如AI PC 应用趋势下,要求电感在超薄极小体积下实现更高饱和电流、更低 DCR以及更快瞬态响应,同时满足高温高可靠与长续航效率要求,以支撑 NPU/CPU/GPU 剧烈动态负载与整机轻薄化、高效率、高散热的严苛设计。工业与储能场景强调宽温、长寿命、高稳定,传统电感难以满足。基于此,应对更高性能需求以满足各个应用场景发展趋势,全球对一体成型电感的高性能指标要求持续提升,行业整体向更高规格、更高性能方向快速升级。 产品特点 扁平漆包铜线:更低 DCR,更低损耗,实现更高的转换效率; 自研高 Bs 磁粉:高饱和电流,最高达94A,; 感量丰富,0.1μH–10μH,满足不同应用需求; 尺寸覆盖4.0x4.0x2.0(mm)~7.0x7.0x3.0(mm)。 产品优势 1、材料优势 (1)磁性粉材优势。顺络磁性材料自主开发,采用高绝缘粉材,具有较好的温度稳定性和可靠性,能够在不同环境下保持稳定的性能。 (2)线圈优势。线圈采用二类漆膜厚度的线材,绝缘层较厚,具有高的绝缘性能,产品DC耐压达到45V,满足产品高可靠性高耐压需求。 图片来源:顺络电子 2、小尺寸、超大电流,更高功率密度;超低DCR,更低损耗 相同感量下,顺络新结构T-U Core产品体积比传统frame结构产品小8.5%,饱和电流高56%,DCR低42%,不仅降低占板面积,还大幅提升了产品的电性能;更低的DCR减少了发热,提升转换效率。满足AI PC等高端应用的CORE供电长时间高负载运行。 3、高可靠性 顺络新结构T-U Core产品采用热压成型工艺,大幅减小铜线形变与应力残留,内部结构排布规整、受力均匀,规避了磁芯开裂等可靠性风险。 产品尺寸&规格特性 Series A(mm) B(mm) C(mm) D(mm) E(mm) a Typ b Typ c Typ 0420 4.0±0.2 4.0±0.2 2.0 max 4.0Typ. 1.2±0.2 1.4 3.0 4.2 0430 4.0±0.2 4.0±0.2 3.0 max 4.0Typ. 1.2±0.2 1.4 3.0 4.2 0520 5.3±0.2 5.5±0.2 2.0 max 5.5Typ. 1.6±0.2 1.8 3.9 5.7 0530 5.3±0.2 5.5±0.2 3.0 max 5.5Typ. 1.6±0.2 1.8 3.9 5.7 0630 6.4±0.2 6.6±0.2 3.0 max 6.6Typ. 1.8±0.2 2.0 4.8 6.8 0650 6.4±0.2 6.6±0.2 5.0 max 6.6Typ. 1.8±0.2 2.0 4.8 6.8 0730 7.6±0.2 7.8±0.2 3.0 max 7.8Typ. 2.6±0.3 2.8 5.2 8.0 Series Inductance Range DCR Range Max. Isat Range Max. Irms Range Max. Units μH mΩ A A MWTP0420S 0.10~22 1.6~26 4.5~24.7 6.0~20.5 MWTP0430S 0.10~4.7 1.8~34.8 4.0~24 4.0~20.4 MWTP0520S 0.10~1.5 1.3~16.9 10.6~37.2 8.5~25 MWTP0530S 0.10~4.7 1.1~31.7 6.1~48.3 5.4~33 MWTP0620S 0.10~3.3 1.3~29.4 5.3~63 5.8~26.2 MWTP0630S 0.10~4.7 0.96~24.6 8.3~94.4 4.3~35 MWTP0730S 0.10~10 0.7~47.3 3.8~88 4.6~33
电感
芯查查资讯 . 2026-07-03 2317

市场 | 涨价公司继续新增!7月涨价的半导体公司在这里
2026年6月底至7月初,半导体及被动元件行业迎来史上密集的一轮涨价潮,从海外 IDM 巨头到国内核心厂商,从主动器件到被动元件,多家企业先后发布调价通知,成本压力与供需格局变化共同推动了这一轮全产业链价格调整。 华润微电子有限公司 涨价信息:7 月 1 日,华润微发布《价格调整通知函》,宣布自 2026 年 7 月 1 日起,对全品类产品价格上调 15%。公司称,全球半导体上游原材料、贵金属、辅材及物流成本持续攀升,晶圆制造与封测全链路成本大幅上涨,叠加市场供需因素,内部降本空间已触顶,调价是为保障稳定供货、坚守产品与服务品质。 公司简介:华润微是华润集团旗下高科技企业,也是国内领先的全产业链一体化半导体企业,2020 年登陆科创板。公司聚焦功率半导体、智能传感器与智能控制领域,拥有从设计、掩模制造、晶圆制造到封装测试的完整流程,当前产能与订单饱满,部分热门型号待交订单周期超一年,是国产替代的核心力量之一。 深圳市金誉半导体股份有限公司 涨价信息:公司决定从2026年7月1日起对其二三极管、MOS管和IC产品价格适当调整,涨幅为10%~30%,即日起执行,具体的产品最新报价和订单的执行安排,需要客户与公司相关业务负责人对接落实。 公司简介:公司成立于2011年5月17日,总部位于深圳市龙华区,是国家级高新技术企业和国家专精特新“小巨人”企业。公司专注于半导体功率器件、分立器件及集成电路的研发设计、封装测试和销售,产品广泛应用于储能、通讯电源、智能家居等领域。在功率器件与集成电路领域实现多项进口替代,车规级产品线增速超过200%,第三代半导体产线即将完成扩产。 杭州士兰微电子股份有限公司 涨价信息:6 月 29 日,士兰微发布《价格调整通知函》,明确自 2026 年 7 月 1 日起,对公司全产品线业务进行价格调整,上调幅度 15% 起。公司指出,上游原材料市场波动及产业链供需结构变化导致供应链成本持续攀升,尤其是晶圆制造关键原材料与封装测试环节成本显著增加,已超出内部可消化范围,调价旨在保障稳定供应与产品品质。 公司简介:士兰微成立于 1997 年,总部位于杭州,是国内最早上市的集成电路设计企业之一,也是少数具备芯片设计、晶圆制造、封装测试全产业链能力的 IDM 龙头。公司产品覆盖集成电路、分立器件、LED 等领域,在功率半导体、车规级芯片等赛道具备较强竞争力,2026 年一季度营收同比增长 17.31%,归母净利润同比增长 40.57%。 Microchip Technology Inc. 涨价信息:6 月 29 日,Microchip 向客户发布调价通知,宣布自 2026 年 8 月 14 日起,对其广泛产品组合中的部分产品进行价格调整,新价格将适用于所有新订单及出货。公司表示,调价源于原材料、人工、物流及能源成本的持续上涨,尽管公司持续提升运营效率,仍无法完全抵消来自供应商、组装厂和晶圆厂的制造成本压力。 公司简介:Microchip 是全球领先的微控制器、模拟半导体和存储解决方案供应商,总部位于美国亚利桑那州,产品广泛应用于工业控制、汽车电子、消费电子等领域,以高可靠性和完整生态系统著称,是嵌入式系统领域的核心厂商之一。 国巨股份有限公司(Yageo) 涨价信息:近日,国巨向全球客户发布全面涨价通知,宣布自 2026 年 7 月 1 日起,对旗下所有 MLCC、电阻、电感等被动元件产品进行价格上调,平均涨幅约 12%-18%,部分高毛利车规级产品涨幅超 20%。公司表示,上游原材料、贵金属及能源成本持续上涨,叠加汽车电子、新能源等下游需求爆发,为保障产能投资与供应链稳定,启动本次全面调价。 公司简介:国巨成立于 1977 年,总部位于中国台湾,是全球第一大被动元件制造商,MLCC、芯片电阻市占率均居全球前列,产品广泛应用于消费电子、汽车电子、工业控制等领域,是全球电子产业链的核心供应商。 日本 Rubycon(红宝石电容) 涨价信息:日本第三大铝电解电容厂商 Rubycon 向客户发出调价通知,宣布自 2026 年 8 月 1 日起上调全系列铝电解电容产品售价,平均涨幅约 15%-20%。公司指出,铝箔、电解液等核心原材料价格持续飙升,叠加能源与物流成本上涨,制造成本压力已无法通过内部优化消化,调价旨在保障产能与交付能力。 公司简介:Rubycon 成立于 1952 年,总部位于日本东京,是全球知名的铝电解电容制造商,以高可靠性、长寿命产品著称,产品广泛应用于工业电源、汽车电子、消费电子等领域,在高端铝电解电容市场占据重要份额。 聚辰股份 涨价信息:聚辰股份向客户发函,确定上调旗下 Nor Flash 全线产品供货价格,上调幅度为 25%,新价格体系将于 2026 年 7 月 6 日正式生效。公司称,存储芯片上游原材料与制造成本持续上涨,叠加市场需求回暖,为保障供应链稳定与研发投入,启动本次调价。 公司简介:聚辰股份成立于 2005 年,总部位于上海,专注于存储芯片、模拟芯片等产品的设计与销售,核心产品包括 Nor Flash、EEPROM 等,在消费电子、工业控制、汽车电子等领域拥有稳定客户群,是国内存储芯片设计领域的代表性企业。 意法半导体(STMicroelectronics) 涨价信息:意法半导体率先启动新一轮涨价,针对功率半导体、模拟芯片等产品进行价格上调,新价格自 2026 年 7 月 1 日起生效。公司表示,全球供应链成本持续高企,为平衡供需与保障长期产能投资,执行本次价格调整。 公司简介:意法半导体是全球领先的半导体企业,总部位于瑞士日内瓦,产品覆盖微控制器、功率半导体、传感器等,在汽车电子、工业自动化、消费电子等领域占据重要市场份额,是全球汽车半导体市场的核心供应商之一。 芯联集成 涨价信息:芯联集成向客户发函,受成本上涨与 AI 算力需求拉动影响,对部分模拟与功率芯片产品进行价格上调,新价格自 2026 年 7 月 1 日起执行。公司强调,本轮调价旨在保障高端芯片研发与产能扩张,支撑长期技术迭代。 公司简介:芯联集成成立于 2014 年,总部位于上海,专注于模拟集成电路、功率半导体的设计与销售,产品聚焦工业控制、汽车电子、AIoT 等领域,在高压模拟芯片、电源管理芯片等细分赛道具备技术优势。 厚声(Uniohm) 涨价信息:全系列电阻产品自2026年7月1日起上调价格,平均涨幅10%-18%,覆盖贴片厚膜电阻、合金电阻、功率电阻、精密电阻等全系品类。核心涨价诱因是贵金属浆料、陶瓷基板、电极材料等核心原材料价格持续走高,叠加行业订单饱满、产能紧张,生产成本已无法通过内部优化消化。 公司简介:厚声创立于1978年,是中国台湾老牌被动元件企业,全球核心电阻制造商。专注各类精密电阻、功率电阻研发生产,产品精度高、稳定性强,适配消费电子、工控、汽车、通信等高端场景,电阻产品出货量与市场占有率稳居全球第一梯队。 友台半导体(UMW) 涨价信息:全系列MOSFET、IGBT、二极管等功率器件自2026年7月1日起涨价,涨幅15%-30%,为本轮涨价潮中涨幅较高的分立器件企业。受上游晶圆资源紧张、制造成本飙升、下游需求集中爆发三重因素影响,行业供需缺口扩大,企业通过调价平衡产能与订单。 公司简介:友台半导体是马来西亚知名功率半导体厂商,深耕中低压MOSFET、IGBT及整流器件领域多年。产品性价比突出、稳定性优异,广泛配套于消费电子、电源设备、工业控制、新能源等领域,是全球分立器件供应链的重要组成部分。
半导体
九如芯闻 . 2026-07-03 1 4 8153

技术 | SmartDV车载以太网IP赋能智能汽车SoC差异化升级、快速研发及功能安全合规
随着汽车电子架构由传统分布式域控架构加速向中央计算架构演进,整车智能化、网联化与数字化水平持续提升。车载以太网凭借高带宽、低时延、高精度时钟同步及支持基于IP的通信等突出优势,正不断对CAN、LIN等传统低速总线形成补充;同时在高带宽骨干通信场景中,更是取而代之成为支撑整车多场景智能化升级的核心通信骨干网络。这使得分布在智能车辆各域的控制SoC和处理器开始全面集成车载以太网接口。 除了最先得到应用的智能座舱,车载以太网还广泛覆盖自动驾驶与ADAS、车联网V2X通信、整车电子架构控制、新能源管理等关键领域,整车各类域控SoC、感知单元、控制终端与人机交互设备均依托车载以太网实现跨域、跨设备的高速数据交互与实时协同,为整车功能稳定运行与架构迭代升级提供核心网络支撑,并成为推动整车创新的关键支撑。 以智能座舱为例,随着车载智能体(AI Agent)、舱驾融合和软件定义驾乘功能逐步落地,智能座舱已然成为打造用户体验的核心交互场景。它们正迎来多屏互联、高清影音传输、可视化驾驶辅助和全域OTA等创新高速普及的新发展阶段,也成为了车载以太网落地最成熟、应用最密集的核心场景。因此,车用以太网IP已然成为智能汽车SoC的重要基础单元,直接决定了这些SoC的研发速度、量产落地周期和车规级合规认证周期。 汽车产业的智能化变革为更多的芯片企业入局车载市场创造全新机遇。新的用户价值推动了车载SoC芯片赛道竞争逻辑开始改变:叠加硬件层面技术日趋标准化,使新的芯片设计企业可以深耕智能座舱等应用并打破老牌厂商和主流平台长期形成的寡头垄断格局。行业竞争重心已从硬件堆叠,转向软件协议适配、车规稳定性、场景化定制、差异化功能落地,这也为新晋车用SoC设计企业破局带来至关重要的发展契机。 一、车载以太网核心价值与解决行业量产痛点 在中央计算架构和新一代智能座舱落地进程中,整车数据交互量呈指数级增长。智能座舱多屏4K高清传输、DMS/OMS乘员感知传感器数据汇聚、舱驾协同联动、全车高频OTA迭代等场景,对车载网络的实时性、稳定性、同步性、低功耗能力提出极致要求,进一步凸显了车载以太网的重要地位。 车载SoC快速研发、配套软件研发与合规验证环节,成为制约新的车载芯片企业实现产品快速落地的核心难题,其中车载以太网尤为突出。一方面,车载TSN、AVB、gPTP、TC10等协议体系复杂庞大,从零自研门槛高、周期长、容错率极低;另一方面,自研方案通用性不足,极易出现PHY适配异常、链路抖动、音画不同步、数据丢包等量产问题。同时,严苛的ISO 26262车规功能安全认证、繁杂的协议一致性测试,大幅增加企业研发成本与量产风险,也是中小型芯片设计团队难以攻克的技术壁垒。 通用现成IP方案已无法满足车企个性化座舱功能、差异化整车架构的定制需求,基于标准的差异化硬件+软件功能支持,已然成为新兴车载芯片厂商构筑竞争优势的核心路径。 二、SmartDV车载以太网IP在合规和认证基础上的核心优势 针对行业同质化严重、自研成本高、定制化能力缺失、车规落地难的行业痛点,SmartDV聚焦车载以太网核心赛道,深耕智能座舱与其他车载SoC应用场景,其全栈IP解决方案具备完整的标准合规性、高度可定制性与差异化竞争优势,是助力新兴车载芯片设计公司在激烈的市场竞争中脱颖而出的核心利器。其可为客户带来的核心价值如下: 1. 严格遵从行业标准,兼容性全覆盖 SmartDV全套车载以太网IP严格对标IEEE 802.1系列、AVB、TSN、TC10等国际车载标准,支持包括100/1000/10GBASE-T1等各类主流车载以太网规格,可完美适配集成式以太网SoC、外置以太网芯片等主流行业硬件方案。其标准化协议架构与通用接口设计,有效改善了通用IP普遍存在的协议互操作性差、硬件不兼容、通信不稳定等问题,保障芯片设计的通用性与合规性,满足车企大批量量产需求。 2. 深度场景化定制,适配各类个性化开发需求 区别于行业通用标准化IP,SmartDV支持全维度定制化开发。其技术团队会根据客户车载SoC定位、智能座舱功能配置、整车中央计算架构、功耗/性能比目标进行针对性优化。无论是中低端入门座舱的轻量化精简方案,还是高端旗舰座舱的多屏联动、超低时延、高精度音视频同步高端方案,均可灵活定制裁剪,适配不同车企、不同车型的差异化功能需求,打破行业方案同质化参考设计带来的市场僵局。 3. 打造差异化产品护城河,助力创新芯片产品突围 长久以来,智能座舱芯片等车载SoC市场一直被寡头厂商垄断,新兴芯片厂商如缺乏深度适配场景的核心差异化优势,就很难被主机厂和Tier-1选择上车。依托可定制化的车载以太网IP方案,SmartDV可帮助新兴车载SoC设计工程师围绕底层通信架构、座舱流媒体体验、低功耗休眠唤醒、时序同步精度等核心维度打造具备实际价值的技术差异化优势。 在行业全面走向SoC单芯片集成化的未来趋势下,车载以太网将广泛集成于主控SoC内部,新兴SoC开发企业可以以更高性价比去与独立外置芯片方案开展竞争。SmartDV紧跟行业发展趋势,聚焦SoC片上以太网IP优化,助力客户打造集成度更高、功耗更低、稳定性更强、体验更优的车载主控芯片,构建了独有的竞争壁垒。 三、SmartDV全套量产级车载以太网解决方案 SmartDV聚焦智能座舱、车载影音、全车电子数字化全量产场景,构建核心IP+场景化定制+自动化验证的闭环解决方案。该方案旨在降低企业自主研发流程的风险与成本,加速创新型车载芯片实现规模化量产落地。 1. 全规格车载以太网MAC/TSN核心IP 方案覆盖全等级车载以太网传输规格,内置完整的TSN时间同步、智能流量调度、带宽整形、TC10低功耗休眠唤醒机制,可满足车载SoC在严苛工作环境下的运行要求,能够适应极端高低温、强电磁干扰,并满足严苛的实时性指标。可直接集成于座舱SoC、域控芯片、车载MCU,帮助研发团队规避复杂协议栈底层研发工作,大幅缩短芯片研发周期,并有效降低链路抖动、时序错乱、通信异常等量产风险。 2. 座舱专属AVB流媒体优化IP 针对智能座舱核心使用场景深度差异化优化,全面兼容车载流媒体通用标准,精准攻克行业多屏异步、高清影音卡顿、音频分区传输异常、流媒体丢包等长期痛点。有效提升整车多屏互动、影音娱乐、沉浸式座舱交互的稳定性与流畅度,并支持中高端智能座舱的功能迭代与量产升级需求,直接提升终端用户体验优势。 3. 一站式自动化车规验证VIP套件 SmartDV还配套提供全覆盖自动化验证体系,涵盖MAC链路通信、TSN时序同步、AVB流媒体传输、低功耗唤醒、软硬件联调等全部测试场景,内置海量标准化测试用例,支持极限压力测试与故障注入。支持客户满足ISO 26262汽车功能安全认证验证要求,有效降低测试覆盖率不全、合规难度大、量产BUG遗留等风险,助力客户顺利推进车规认证,加速合规量产进程。 四、总结 在两大趋势共同驱动下——汽车电子架构迎来根本性革新,和用户价值主张被重新定义,智能座舱与车载SoC领域的市场竞争,已不再局限于单纯的硬件参数比拼。依托硬件层面的功能支撑,整个行业迈入了以差异化、高度定制化、严苛合规为核心特征的全新竞争时代。 依托经验丰富的车载工程技术团队与自研SmartCompiler IP生成工具链,SmartDV以标准化协议合规为基础、以场景化差异优化为核心、以全车规验证保障为支撑,帮助新兴车载芯片设计企业规避自研风险、降低研发成本、缩短量产周期。凭借独有的差异化竞争力,助力创新型车载以太网、智能座舱域控制器芯片打破头部厂商垄断格局,抢抓中央计算架构与智能汽车发展红利。同时提供可靠的底层IP支撑,保障车载SoC顺利完成设计、实现批量量产,且高效完成各项严苛车规认证。
车载以太网
芯查查资讯 . 2026-07-03 1995

产品 | AMD 推出第二代 Versal Premium MoP,在更小设计中实现更高内存容量与性能
AMD 今日宣布推出第二代 AMD Versal Premium MoP( Memory on Package,封装上内存)自适应片上系统( SoC )。MoP 架构将最高 32GB 的 LPDDR5X 集成到单个封装中,可在最多减少 60% 板级面积1的同时,实现至高 288GB/s 的带宽,使工程师无需面临板级内存设计带来的风险与耗时,即可构建高带宽系统。随着物理 AI、网络等工作负载要在日益严格的空间与功耗预算下处理更多数据,MoP 恰能满足这些最迫切需要它的设计场景:测试与测量、专业视频编辑等需求。 图 1:第二代 AMD Versal Premium Memory on Package( MoP )器件 AMD 自适应和嵌入式计算事业部产品管理和营销负责人 Sumit Shah 表示:“多年来,系统架构师必须在所需的内存带宽与其项目实际能够承受的空间、功耗和生命周期之间做出取舍。MoP 消除了上述权衡。客户可以围绕其目标系统进行设计,而不再受限于内存约束,从而更快将其推向市场。” 缩小占用空间并扩展带宽 凭借全新的封装上内存自适应 SoC,我们正在重新定义紧凑型系统设计的可能性。通过将 LPDDR5X 直接集成到封装中,该器件相比板载 LPDDR5X 实现了更高性能2,同时占用面积比离散实现方案更小。 这使得以往在采用外部内存时难以实现或不具可行性的系统形态成为可能,例如企业和数据中心标准外形规格( EDSFF )等,同时也帮助设计人员满足电信等领域的需求,而这些需求往往是离散内存方案无法满足的。 第二代 Versal Premium MoP 器件在硬 IP 中集成了 64Gb/s 的 CXL® 3.1 和 PCIe® 6.0,与 AMD EPYC 处理器搭配使用时,可实现高速数据传输,从而加速数据密集型应用。我们通过支持最高 9,600Mb/s 的 LPDDR5X 以及连接 CXL 内存池化与扩展模块,帮助系统架构师更灵活地扩展内存资源。 专为长生命周期部署打造 第二代 Versal Premium MoP 自适应 SoC 专为严苛的物理与企业级 AI 环境而设计,支持 -40°C 至 110°C 的工业级工作条件。其非常适合始终在线的关键任务系统,在这些系统中,性能和可靠性必须同时兼顾。 依托于 LPDDR5X 以及超过 15 年的生命周期支持,第二代 Versal Premium MoP 器件有助于使产品供应不再受高带宽内存( HBM )较短的、以数据中心为驱动的更新周期影响,从而降低因内存停产或可获性受限而导致被迫重新设计的风险。 PCIe 完整性和数据加密( IDE)作为 PCIe 6.0 引入的一项特性,通过在链路层对传输中的数据进行保护,帮助抵御物理攻击。集成控制器中的 DDR 内存加密功能,无需占用可编程逻辑资源即可帮助保护静态数据。硬化 400G 高速加密引擎支持高带宽安全处理,能在不牺牲吞吐量的前提下增强安全性。 加速产品上市进程 第二代 Versal Premium MoP 器件包含经过预验证的封装内 LPDDR5X 接口,无需在电路板上进行高速内存布线,从而减少了板级仿真与验证工作,同时有助于缩短开发周期、降低设计风险,并最大限度减少成本高昂的反复流片。 用户现在即可使用现已出货的标准第二代 AMD Versal Premium 系列器件着手开发。对成熟的 AMD Vivado 和 Vitis™ 工具流程、兼容 IP 以及可用参考设计的支持,有助于快速将设计从概念推进至部署阶段,同时使现有客户在无需重新设计或重新学习的情况下,即可采用新的 MoP 器件。 第二代 AMD Versal Premium MoP 器件将于 2026 年底开始提供样片,预计将于次年下半年开始量产出货。
自适应SoC
芯查查资讯 . 2026-07-03 2037
企业 | 从高性能ADC到完整信号链方案,士模微电子以自主创新服务中国智造升级
在工业自动化、能源电力、轨道交通和高端装备持续升级的背景下,中国制造对模拟芯片的要求已经不再是有没有,而是能不能稳定地高性能运行,以及可靠的本土流片供货能力。长期以来,国内高端装备在高性能ADC、DAC等核心模拟器件上依赖进口,不仅面临成本高还有供货不稳等问题。作为国内极少数覆盖信号链七大产品线、具备全品类架构自主定义能力的高端模拟信号链企业,北京士模微电子有限责任公司正是在这一产业背景下,以全正向设计和架构创新切入高性能模拟信号链,补齐国产高端模拟芯片的关键短板。 士模微电子的技术底座,来自其创始人、哈佛大学博士孙楠深厚的学术积累和产业判断,作为清华大学电子系长聘教授、IEEE Fellow,孙楠长期深耕ADC/DAC方向,团队近年在该领域顶刊顶会论文数量行业领先,他放弃美国绿卡全职回国之后,带领团队在ISSCC上发表了大陆首篇ADC方向论文,为士模微电子的自主研发和工程化落地提供了坚实支撑。在2026慕尼黑上海电子展中,士模微电子围绕高性能ADC、DAC、放大器及配套信号链产品,集中展示其面向中国工业升级需求打造的产品布局与应用方案,这些方案是士模微电子从架构设计全正向研发到国内流片验证及规模量产,实现完整技术闭环。 自主高性能ADC矩阵,夯实中国智造的数据采集底座 随着人工智能技术的快速迭代,制造业正在从自动化进入智能化时代。核心数据采集作为这些工业系统智能化的入口,工业现场对采得准、采得快、采得稳的要求越来越高。从电力系统行波故障定位,到工业设备状态监测,再到测试测量和高端仪器,数据采集能力决定了系统能否真正实现智能化。 围绕这一需求,士模微电子构建了覆盖低速高精度、多通道同步采样和高速采集的高性能ADC产品矩阵,并通过自主研发能力持续完善产品布局。以CM2368等多通道同步采样SAR ADC为代表的产品,面向继电保护、行波测距和工业多路采集等高可靠场景,重点解决多路信号同步一致性、长期稳定性和国产供应链可控性等问题,帮助客户在关键采样环节建立更稳健的国产替代方案。 面向高精度测量和传感器接口场景,士模微电子也布局了更高分辨率的Σ-Δ ADC及AFE类产品,覆盖温度、压力、称重等低速高精度应用;面向通信、宽带接收和高速采集场景,则推出了更高速率、高动态性能的数据转换器;……对客户而言,士模微电子提供的不只是几颗ADC,而是一套能够适配不同场景、兼顾性能与可靠性的数据采集解决方案底层支撑。 士模微电子没有止步于单颗芯片参数的提升,而是同步构建DAC、放大器、基准源和LDO等完整信号链能力。在真实系统中,性能瓶颈往往并不只来自转换器本身,还包括前端调理、电源噪声、同步误差、长期漂移和系统稳定性。通过完整链路设计,士模微电子帮助客户把“芯片参数”转化为“整机性能”,把“器件可用”转化为“系统好用、稳定可量产”。 从温度采集到环路驱动,打通工业现场全链路自主能力 围绕工业自动化、过程控制和现场仪表等典型应用,士模微电子在展会现场重点展示了温度采集、模拟量输入、模拟量输出和环路驱动等工业信号链方案。这些方案共同指向一个核心目标:让客户在国产核心器件平台上获得更稳定、更可靠、更易集成的工业系统能力。 在温度采集方面,士模微电子提供了全集成 NTC/TC/RTD等传感器采集AFE方案。CM1310系列产品集成了1-128倍程控增益放大器,匹配恒流源,内置高精度基准源等模块,在低功耗的同时,满足工业现场24-bit高精度的温度测量需求。这类方案的价值不仅在于“能准确测温”,更在于在复杂干扰环境中保持长期稳定、可重复、可校准,减少现场调试和维护负担。 在模拟量输入方向,士模微电子围绕PLC、DCS、工业控制器和现场采集模块等典型应用,推出了高精度多通道模拟量输入方案。以CM1348为代表的产品,能够支持工业现场多路信号接入和传感器前端采集,帮助客户在国产芯片平台上实现更高精度、更强抗干扰能力和更灵活的输入设计,进一步实现降低前端设计复杂度,缩短开发周期,提升系统导入效率。 在模拟量输出方向,士模微电子同步推出了全集成±10V/4-20mA模拟量输出方案,覆盖常规电流输出与环路供电4-20mA输出等典型应用。前者适用于工业控制中的模拟量执行与驱动,兼顾电压和电流输出,能够简化系统设计;后者则面向工业仪表和现场变送器等场景,在低功耗条件下实现稳定输出。两类方案共同体现出士模微电子在工业模拟量输出链路上的系统化设计能力,也为客户提供了从高集成输出到现场低功耗输出的完整选择。 这一系列工业方案是士模微电子常见的工业应用场景构建起完整的工业信号链布局。对于中国工业产业整机研发制造企业而言,这意味着更可控的核心器件供应链、更短的设计周期、更低的外围复杂度,以及更稳定的长期运行表现。 慕尼黑上海电子展展示的士模微电子主要工控解决方案一览 高速数据采集在带宽、动态性能与低功耗中鱼与熊掌兼得 在通信、测试测量和工业监测等应用中,高速数据采集系统不仅要求更高采样能力和更宽带宽,还必须同时兼顾动态性能、功耗控制、散热和系统可靠性。 士模微电子推出了面向高速采集系统的解决方案,依托自主创新架构推出高速高精度ADC CM3452,在保障双通道同步高速转换性能的同时,功耗960mW,仅为国际竞品的1/3,该产品也是首颗国产晶圆厂商工艺流片并量产的高速高精度ADC,尤其适合多通道、高密度数据采集系统。对客户而言,这不仅意味着更小的散热压力,也意味着更高的系统集成度和更好的整机设计空间。 更值得关注的是,这一成果摆脱了此类器件对境外工艺依赖,体现出公司在国产工艺适配、架构实现和工程化验证方面的综合能力。对于高端模拟芯片而言,真正的难点不只是性能指标,更是如何在国产制造体系下实现可重复、可验证、可量产的高性能表现。士模微电子在这一方向上的突破,意味着其高速产品不仅做得出来,更具备进入实际应用、服务规模化需求的基础。 与此同时,士模微电子还通过高速ADC与低噪声、高PSRR LDO等产品的协同设计,优化ADC及周边供电环境,降低电源噪声对动态性能的影响。通过“ADC + 前端器件 + 电源管理”的协同布局,士模微电子为行业客户提供的不只是单颗高速ADC,而是一条更容易落地、也更稳定可控的国产化高速信号链,帮助客户减少调试复杂度,提升系统长期稳定性。 以高精度编码器方案赋能智能装备运动控制升级 编码器是伺服驱动、机器人、数控机床、电梯和轨道交通等系统中的关键感知部件,也是高端装备实现高精度运动控制的重要基础。随着制造业对定位精度、响应速度和长期可靠性的要求持续提高,编码器信号链的性能已经成为影响整机控制精度和系统稳定性的关键因素之一。 围绕SIN/COS信号调理与同步采样,士模微电子展出了完整的编码器应用方案,覆盖前端信号放大、精准采样和低噪声供电等关键环节。在这一方案中,CM4132等运放器件用于前端放大与缓冲,有助于降低微弱信号采集中的噪声和失真风险,为后级采样提供更稳定的输入条件;CM2272等双通道同步采样SAR ADC则可对SIN/COS两路信号进行精准同步采集,减少通道间相位与时序误差,提升角度解算精度和系统一致性;CM6511、CM6111等低噪声LDO则为模拟前端和ADC提供稳定、洁净的电源支持,进一步保障整条信号链的动态性能和长期运行稳定性。 这套方案在提升编码器本身的性能同时,更为高端运动控制应用提供更容易国产化替代、更适合规模部署的硬件基础。对于正在加速国产化的智能装备企业而言,这套编码器信号链在确保更高的控制精度、更强的抗干扰能力和更稳定的长期运行表现,也为长期的供应链稳定提供了信心保证。 士模微电子编码器解决方案及关键ADC和LDO组件 结语 此次慕尼黑上海电子展上,士模微电子传递出的核心信号是:国产高端模拟芯片的竞争,正在从单颗器件的参数替代,走向面向真实应用的系统级信号链能力建设。 无论是工业采集、过程控制、高速数据采集,还是高精度编码器应用,其背后共同考验的都不是某一颗芯片的性能,而是前端调理、数据转换、低噪声供电、长期稳定性与量产交付能力多个权衡维度。士模微电子围绕这些关键环节进行产品布局和方案验证,体现出其从芯片设计到系统落地的完整能力。 对于中国高端装备产业而言,这种能力的意义在于,让核心模拟器件不只停留在“国产可选”,而是进一步走向“可靠可用、稳定可供、易于集成”。这也是士模微电子区别于单点国产替代的价值所在。随着工业自动化、能源电力、测试测量和智能装备等领域持续升级,高性能模拟信号链的重要性将进一步提升。士模微电子也将继续以自主创新和工程化能力为支撑,推动更多国产高端模拟芯片进入核心应用场景,为中国智造升级提供更坚实的底层支撑。
ADC
芯查查资讯 . 2026-07-03 2177
VBsemi 汽车防盗系统 MOSFET 推荐方案-面向UWB数字钥匙、智能感知与主动报警系统的功率器件选型指南
随着智能汽车、数字钥匙以及车联网技术的快速发展,传统机械防盗系统正逐步向智能化、主动化、多传感器融合方向升级。当前主流汽车防盗系统已经从简单的门锁控制扩展到UWB数字钥匙、BLE蓝牙识别、NFC近场通信、车内外摄像头监控、震动检测、超声波感知以及主动声光报警等多个功能模块。 在整个汽车防盗系统中,MOSFET承担着电源管理、负载开关、信号隔离、电池保护以及报警驱动等关键任务。器件不仅需要具备低功耗、小封装、高可靠性等特点,还必须满足汽车电子长期稳定运行需求。 针对智能汽车防盗系统应用,VBsemi推出了一套完整的MOSFET选型方案,可覆盖数字钥匙、无线通信、传感器管理、MCU供电以及报警器驱动等核心功能模块。以帮助工程师在紧凑布局中实现低损耗、快速切换和高可靠性设计。 具体分配如下: 功能模块 推荐型号 封装 类型/配置 主要优势 UWB数字钥匙 SI1401EDH-T1-GE3-VB SC70-6 单P沟道 超低功耗、小封装 BLE模块 SI1401EDH-T1-GE3-VB SC70-6 单P沟道 快速唤醒、低待机电流 NFC模块 SI1401EDH-T1-GE3-VB SC70-6 单P沟道 电源门控、安全隔离 超声波传感器 SI1401EDH-T1-GE3-VB SC70-6 单P沟道 低损耗供电管理 摄像头模块 SI1401EDH-T1-GE3-VB SC70-6 单P沟道 快速启动、低噪声 振动传感器 VBQG5222 DFN6(2×2)-B 双N+P沟道 Dual N+P集成方案 MCU管理 VBQG5222 DFN6(2×2)-B 双N+P沟道 电源时序控制 报警器控制 VBQF3310G DFN8(3×3)-C 半桥N+N沟道 半桥驱动、大电流输出 模块详细推荐 1. 低功耗通信与感知模块(UWB/BLE/NFC/超声波/摄像头) 推荐型号:SI1401EDH-T1-GE3-VB 封装:SC70-6 (2.0×2.1mm) 配置:Single P-Channel 关键参数:VDS=-20V,ID=-4A,Vth=-0.6V,RDS(on)=45mΩ(@VGS=-2.5V)/34mΩ(@VGS=-4.5V) 这些模块通常由电池或低压LDO供电,需要负载开关进行电源管理以降低待机功耗。SI1401EDH-T1-GE3-VB的P沟道结构在高侧驱动中极为便利:栅极拉低即可导通,无需自举升压。其仅-0.6V的阈值电压,可直接由1.8V或3.3V的GPIO驱动,完全适配BLE SoC、NFC控制器的低电压逻辑。SC70-6封装占板面积不足5mm²,可轻松集成在空间受限的钥匙模块或传感器小板上。Trench工艺保证了在-4A额定电流下依然有较低的导通电阻,减小传导损耗和温升。 2. 振动传感器与MCU管理 推荐型号:VBQG5222 封装:DFN6(2×2mm) 配置:Dual N+P-Channel 关键参数:VDS=±20V,ID=±5A;N沟道Vth=0.8V, RDS(on)=24mΩ(@2.5V)/20mΩ(@4.5V);P沟道Vth=-0.8V, RDS(on)=40mΩ(@-2.5V)/32mΩ(@-4.5V) 振动传感器信号调理电路常需电平转换或互补驱动,VBQG5222内部集成一颗N沟道和一颗P沟道MOSFET,为设计提供了极高的灵活性。例如,N-MOS可用于低侧开关驱动振动马达或传感器供电,P-MOS作为高侧反接保护或负载开关。其±12V的栅源电压范围、0.8V/-0.8V的低阈值,意味着微弱的传感器唤醒信号足以让MOSFET动作。在MCU管理部分,双管配合可实现多路电源轨的时序控制和复位信号生成,DFN6的微型封装便于放置在MCU近端,减少走线电感。 3. 高功率报警器驱动 推荐型号:VBQF3310G 封装:DFN8(3×3mm) 配置:Half-Bridge N+N 关键参数:VDS=30V,ID=35A,Vth=1.7V,RDS(on)=16mΩ(@VGS=4.5V)/9mΩ(@VGS=10V) 报警喇叭或蜂鸣器需要高效率的半桥或全桥驱动,以实现高低侧交替导通产生音频信号。VBQF3310G内置两颗N沟道MOSFET组成半桥,共漏/共源灵活配置,两颗管子的典型RDS(on)在4.5V驱动下仅16mΩ,10V时降至9mΩ,可连续通过35A电流,轻松驱动数十瓦级报警音圈。1.7V的栅极阈值确保普通的MCU PWM输出经电平移位后能可靠开关。紧凑的DFN8封装有利于散热设计,保障长时间报警时系统不会过热。同时30V的耐压可承受车载电源总线上常见的瞬态尖峰,配合适当的TVS可满足ISO 7637-2抛负载测试。 选型优势总结 小封装高密度:SC70-6、DFN6、DFN8均为超小型无铅封装,契合汽车电子“模块小型化”趋势。 低栅压驱动能力:SI1401EDH-T1-GE3-VB和VBQG5222的阈值电压低于1V,可直接用低电压逻辑控制,省去额外驱动芯片。 Trench工艺,低导通电阻:相同封装尺寸下提供更低的RDS(on),降低损耗,提高可靠性。 配置灵活,一站配齐:从单P沟道到互补双管再到集成半桥,满足通信、感知、控制、驱动全部需求,减少BOM供应商数量。 适应汽车环境:虽然本方案器件为工业级,但宽工作温度范围和可靠的Trench结构使得它们能应对防盗系统所处的车厢内温度环境。 VBsemi以SI1401EDH-T1-GE3-VB、VBQG5222和VBQF3310G三款MOSFET为核心,构建了覆盖汽车防盗系统所有功能环节的高效、紧凑功率解决方案。设计人员可直接依据上述推荐进行原理图开发,快速完成智能防盗终端的电源与驱动电路设计。如有特殊参数需求,欢迎联系VBsemi获取更多技术支持与样品测试。 展会邀请 面向2026年汽车电子高速化、智能化与工业化升级趋势,VBsemi将持续优化功率器件选型方案,助力客户提升整机稳定性与产品竞争力。 2026年7月1日—3日,微碧半导体 VBsemi 将亮相 2026慕尼黑上海电子展,在现场展示面向AI服务器电源、机器人、储能、新能源及高频电源等应用领域的功率器件解决方案。 诚邀各位客户、合作伙伴及行业朋友莅临 上海新国际博览中心 N5.150展位,与VBsemi团队面对面交流,共同探讨功率器件国产化替代与高可靠应用方案。 VBsemi期待与您相聚上海,共话功率器件创新应用与未来合作机遇!
微碧
微碧半导体 . 2026-07-03 2163

Vishay汽车级环境光传感器可实现精确的可见光测量且无红外凸点
这些通过AEC-Q102认证的器件具有与人眼相当的光谱感光度,并采用紧凑的0805和顶视QFN封装,可实现更优的光谱角性能 日前,威世科技Vishay Intertechnology宣布,推出两款汽车级PIN光电二极管环境光传感器---VEMD4210FX02和VEMD5525FX02,可在严苛环境下实现更高的光学精度和长期可靠性,从而进一步扩展了其光电子产品的阵容。Vishay VEMD4210FX02和VEMD5525FX02均通过AEC-Q102认证,其光谱感光度极为接近人眼响应能力 — 峰值波长达530 nm — 且无红外(IR)凸点。 此次发布的这些器件专为汽车应用而设计,包括中央信息显示屏(CID)、抬头显示器(HUD)和雨光隧道(RLT)系统的自动光控,以及工业设备的背光调光。通过消除光谱感光度曲线中的红外凸点,这些器件可确保上述应用中可见光的精确测量,同时避免受到红外光的不良影响。此外,这些器件卓越的视角特性确保了稳定的光谱精度—无论入射光的角度是多少—从而实现一致且可靠的光测量性能。 对于空间受限的应用,VEMD4210FX02采用紧凑的0805封装,其典型反向光电流为0.014 μA,感光范围为470 nm至610 nm,辐照感光面积仅为0.42 mm2。对于需要更高感光度的应用—尤其是在低光照条件下—VEMD5525FX02采用顶视QFN 封装,具有7.5 mm2的大辐照感光面积,反向光电流为0.11 μA,感光范围为480 nm至590。这两款器件均具有易于吸附焊锡的侧边焊盘,便于进行光学焊点检测。 这些传感器符合RoHS标准,无卤素,且满足Vishay绿色标准,符合J-STD-020的潮湿敏感度等级(MSL)4级,车间存放时间为72小时。这些器件支持无铅回流焊接,工作环境温度范围为-40 °C至+110 °C。 器件规格表: 新款环境光传感器现可提供样品并已实现量产,供货周期为8周。
Vishay . 2026-07-03 2072

Littelfuse NANO²® SMD 708系列保险丝为大电流48 VDC AI数据中心提供保护
今天Littelfuse(力特)宣布,推出NANO²® 表面贴装型708系列保险丝,这是Littelfuse首款表面贴装式保险丝,在80 VDC电压下额定分断电流为14,000 A。(观看视频。) 708系列专为下一代48 VDC电力架构而设计,可满足AI服务器、超大规模数据中心和高密度配电系统不断增长的保护需求。随着功率水平的提高和电路板空间的缩小,设计人员不得不使用超大尺寸的手动安装插件式或螺栓固定式保险丝。708系列在不影响性能的情况下提供了紧凑、自动化友好的替代方案。 NANO²® 708系列在紧凑的表面贴装封装中结合了高额定电流(60A至200A)和行业领先的分断额定值。这使设计人员能够保护暴露在高故障电流下的电路,同时优化布局效率并实现全自动组装过程。 “我们的首款Littelfuse表面贴装保险丝在80 VDC下具有14,000 A的分断额定值,凭借这款新型保险丝,我们为使用传统插件式或螺栓固定式解决方案的设计人员提供了向表面贴装技术过渡的途径。”Littelfuse过流无源器件产品管理高级总监Daniel Wang表示。“这种转变使自动化制造成为可能,提高了生产率,并降低了整体系统成本。” 主要功能与优势包括: · 业界领先的额定分断电流:80 VDC时为14 kA,支持高故障电流环境 · 高电流能力:60 A 至200 A范围,适用于要求苛刻的电源应用 · 紧凑的表面贴装尺寸:节省空间并支持高密度设计 · 自动化就绪型装配:无需手动安装与传统保险丝格式相关的操作 · 性能可靠:高浪涌冲击的耐受力,符合全球安全标准 708系列旨在为预计会出现高故障电流的电路提供补充过流保护,包括配电单元(PDU)、电源架、电池备份单元(BBU)和电源单元(PSU)。它特别适用于AI服务器集群、网络设备和超大规模数据中心基础设施。 其他应用包括可再生能源系统和电池管理系统(BMS),在这些应用中,紧凑型大功率保护解决方案至关重要。 708系列是Littelfuse面向数据中心基础设施的48 V保护解决方案广泛产品组合的一部分,是对包括456、871和881系列在内的现有保险丝系列的补充。 NANO²® SMD 708系列保险丝常见问答 1. 708系列与现有SMD保险丝有何不同? 它采用表面安装式封装,在80 VDC条件下提供业界领先的14 kA分断额定值。这种级别的保护以前只适用于较大的插件式保险丝或螺栓固定式保险丝。 2. 为什么高分断额定值在人工智能数据中心很重要? AI服务器和高密度电力系统面临巨大的故障电流潜力。高分断额定值可确保故障电流安全中断,而不会损坏周围电路。 3. 708系列能否取代现有的管状或螺栓固定式保险丝? 是的。它是许多传统保险丝解决方案的替代产品,可实现更小的尺寸、更高的可制造性和自动化装配。 4. 表面贴装设计如何为制造商带来好处? 表面贴装可实现自动化拾放组装,从而降低人工成本、提高一致性并提高产量。 5. 708系列适用于哪些系统和电源架构? 708系列针对AI服务器、超大规模数据中心和高密度配电系统中常用的48 VDC电源架构进行了优化。它特别适用于PDU、PSU、备用电池单元以及其他对高电流和紧凑设计至关重要的应用。 6. 设计师应该在什么情况下选择708系列而不是其他保险丝? 当应用要求在紧凑的结构中同时具有高电流处理能力和极高的分断额定值时,708系列是理想选择。在更换空间受限设计中的超大插件式或螺栓固定式保险丝时,或过渡到自动化表面贴装组装时,尤其有益。 供货情况 NANO²® 表面贴装型708系列保险丝提供500只装的卷带包装。通过全球任何一家Littelfuse授权经销商索取样品。如需了解Littelfuse授权经销商名单,请访问Littelfuse.com。 更多信息 可通过以下方式查看更多信息:NANO²® 表面贴装型 708 系列保险丝。如有技术问题,请联系产品经理John Emmanuel C. Semana,jsemana@littelfuse.com.
Littelfuse . 2026-07-03 2884

高功率多口PD快充耐用不发烫的 秘密藏在MOS管里!
有没有人很疑惑:同样是高功率多口PD快充,为什么有的耐用不发烫、电池超长寿,有的才用了半年就出现发烫、充电慢,甚至伤机等情况。真正数码内行都在看充电器分立器件清单!而清单里最核心、最不能缩水的元器件非MOS管莫属! 什么是高功率多口 PD 快充 高功率多口 PD 快充,是搭载 PD 通用快充协议、配备 2 个及以上 Type-C 输出口、额定总功率 65W 及以上的电源适配器。 它依托 PD快充沟通通道,能够自动适配手机、平板、笔记本等一系列办公设备,自主协商多档充电电压,支持多设备同时满功率充电,是当下办公、出差、数码设备收纳的主流充电方案。核心在于MOS 管的器件选型,优质分立器件才能实现长期满载不发烫、不伤电池。 传统充电方案核心痛点 设备兼容性差:手机、电脑、游戏机充电头规格互不通用,桌面堆满适配器,出行携带繁琐; 单口功率上限低:多设备同充功率对半拆分,笔记本长期慢充、回血速度跟不上耗电; 劣质器件发热严重:满载高温触发断崖降速,长期高温加速电池老化,存在安全隐患; 电网电压频繁掉线:边充边玩功率跳变,使用体验差。 多口高功率 PD 快充赛道持续高速增长,行业头部品牌(安克、绿联、倍思、华为、小米)合计占据国内 68.3% 市场份额,且头部厂商已全面采用高压MOS管成熟方案,高品质稳定器件方案成为厂商差异化竞争核心。 今天就重点围绕MOS管,给大家分析分析,带大家看懂合科泰 MOS 管在高功率多口PD快充方面的独家核心优势。 合科泰 MOS管:快充精密电控开关(两款型号按需适配) 很多人忽略 MOS 管,其实它才是决定充电稳不稳、温控好不好的关键元器件,合科泰两款产品完美适配全档位高功率 PD 快充,从电性参数、封装散热、高频拓扑三方面高度匹配,能够实现效率加快: 电性参数适配多口满载 产品均采用 650V 高耐压 N 沟道 MOS架构,充足电压余量能够有效抵御家用电网浪涌、电压波动,即便多设备同步充电也能保持无功率跳变;同时超低导通电阻大幅降低导通损耗,从源头减少整机发热,减轻温控电路负荷压力。 TO-252 封装适配迷你多口 PCB 产品统一采用 TO-252 贴片封装,自带大面积散热焊盘,适配小型化、轻量化的多口充电头电路板设计。无需额外增加散热结构,在保障充电头小巧携外观的同时,兼顾小巧体积与散热能力;平衡产品的颜值、体积与使用稳定性。 高频开关特性适配整流电流拓扑 产品开关响应速度快,可平滑切换快充 / 恒压 / 涓流三阶段电流,适配整流电路拓扑。手机、平板、电脑等多设备同时充电时,功率动态分配更精准,不会出现设备抢电、功率紊乱的情况,多口快充体验感拉满。 (PD快充基本拓扑架构图) 两款通用优势:MOS管的充头热稳定性拉满,夏冬极端环境都耐用,夏天放高温车里暴晒充电,冬天放户外背包、也不会出现充电异常、自动断电的情况,一年四季充电状态稳定。 主控会平缓调节功率降温,兼顾快充速度与使用安全。边充边刷剧、打游戏依旧维持快充速度,机身只是微微温热,不会烫手。 原厂现货保障 + 合科泰企业实力,品质更靠谱 现货稳定交付,供货无忧 合科泰产品HKTD4N65、HKTD7N65等常规型号长期常备大量现货,无断货、交期延迟灯风险;可灵活适配小批量样品试产、大批量订单稳定排产,可精准匹配快充厂商新品迭代、销售旺季爆单等各类需求,相较于进口 mos管,合科泰交期直接缩短 50%,助力厂商高效落地生产。 自研自产一体化,品质全链路可控 合科泰是集研发、晶圆封测、销售一体化的国家级高新技术原厂,拥有惠州、南充两大智能化生产基地,配备3000余台自动化生产设备,月产能可达 800KK 功率器件。 从晶圆来料、固晶封装到电性测试,全流程自主把控,品质标准,万级无尘车间生产,关键工序良率达 99.8%;所有出厂全检电性参数,器件参数离散度极低,批量一致性、稳定性远超杂牌代工MOS管。 专属FAE技术支持,高效赋能研发 品牌配备50人专业半导体研发FAE团队,针对多口 PD 快充主流拓扑,提供免费电路适配、参数调试支持,方案优化等专属技术服务,可提供完整功率段器件选型清单,帮助硬件工程师缩小选型范围、缩短研发周期,高效落地稳定可靠的快充方案。 简单总结选购干货: 搭配普通杂牌 MOS管:充电容易发烫、快充频繁掉线; 只标注 PD 协议 :基础入门慢充款,发热与稳定性一般; 搭配合科泰 mos管:行业全能顶配快充、稳定、低温、耐用、不伤机。 补充给正在选型的工程师们,建议找合科泰的业务团队可随时对接,获取专属应用方案与技术支持,精准匹配各类功率、拓扑结构的快充产品,省时高效完成选型! 欢迎大家在评论区留言咨询!
#HKT #工业级MOS管 #车规级 #工业级MOS管 #原厂直供 #MOS管
厂商投稿 . 2026-07-03 2156

A-68 语音处理模组:双麦波束成型 + I2S数字输出,搞定全双工对讲与远场拾音
一、 开篇:为什么选它?(痛点解决) 最近在折腾一个可视门铃/远程对讲的项目,最大的痛点就是:喇叭放歌时,麦克风会啸叫(回声);环境一吵,人声就听不清(噪声)。 市面上很多方案要么只能降噪不能消回声,要么是模拟输出容易被射频干扰(WiFi/4G模块旁边根本没法用)。直到我遇到了 A-68 模组。 这玩意儿最让我心动的地方在于: I2S 数字音频输出:直接干掉了底噪和射频干扰,接MCU/Codec芯片非常干净。 双麦波束成型 (Beamforming):不是简单的单麦降噪,而是利用两个麦克风的物理位置差,像“聚光灯”一样只收音人声方向,侧面的噪音直接过滤。 真·全双工:一边放音乐一边说话,对方能听清,而且没有回声。 二、 硬件规格书 (Datasheet) 核心参数速览 这是一块基于 DSP 架构的独立处理模组,不是简单的运放电路,它是有算法的。 核心性能: 回声消除 (AEC):高达 85dB(这意味着即使喇叭声音很大,也不会把声音传回给对方造成啸叫)。 噪声抑制 (ENC):45dB - 90dB(稳态噪声如风扇声,非稳态如键盘声都能压)。 工作电流:< 25mA @ 5V(低功耗,电池设备也能用)。 尺寸:23.5mm × 19mm(标准2.54mm排针间距,面包板直插友好)。 三、 引脚定义与硬件接口 这个模组的接口非常丰富,模拟+数字同时输出,给了我们很多玩法。 引脚定义速查表(重点看这几个): 表格 引脚 名称 功能 玩法/备注 11 5V 电源输入 4-6.5V宽压输入 1,5,19 3V3 3.3V输出/输入 注意:19脚可出可进,接反了会烧! 17, 18 LIN/RIN 模拟输入 可接模拟硅麦或线路输入 1-4 PDM_CLK/DAT 数字麦接口 支持双数字麦克风(PDM格式) 7-10 I2S 数字音频输出 推荐:主模式,16KHz/16bit 13, 15 LOUT/ROUT 模拟音频输出 接功放或ADC采集 四、 三种工作模式(怎么玩?) 根据你的项目需求,刷不同的程序进去,它就能变成三种不同的“神器”: 纯降噪模式(录音神器) 场景:录音笔、采访机。 玩法:接两个麦克风(数字或模拟),开启波束成型。你可以设定一个60度的“拾音角度”,角度外的噪音直接忽略。实测在3-5米远场,人声依然清晰。 消回音模式(对讲神器) 场景:可视门铃、车载蓝牙、会议终端。 玩法:这是最复杂的,也是最难调的。你需要把喇叭的信号(经过分压电阻)引到模组的 17 脚(参考输入)。 避坑指南:如果你用的是 D类功放,千万不能直接把PWM波怼进去!文档里提到了,必须加 LC滤波电路(比如 22uH电感 + 1uF电容)把方波滤成正弦波,否则回声消除效果会崩。 立体声降噪模式 场景:双人访谈、特殊监听。 玩法:左右声道独立降噪,互不干扰。 五、 麦克风接入实战(DIY指南) 很多兄弟手头不一定有数字麦克风,别急,这板子兼容性很强: 数字麦克风 (推荐):直接接 1-4 脚。选 PDM 接口的,记得麦克风的接地脚不能悬空。 模拟硅麦:接 17/18 脚,简单省事。 驻极体麦克风 (ECM):注意! 驻极体信号很弱。如果你要用老式的咪头,必须在外部加偏置电阻(10K),最好再加一级运放(增益 8-10倍),否则底噪会很大,信噪比不够。 六、 总结与建议 适合谁? 正在做 安防监控、可视门铃 的工程师。 想做一个 高逼格蓝牙对讲机 。 受够了模拟电路底噪,想上 I2S 数字音频 的玩家。 吐槽点(不足): 它是 固定功能 的 DSP,不能像 FPGA 那样自己写逻辑,只能通过上位机配置参数。 19 脚电源设计有点反人类,既是输出又是输入,焊接时一定要看清楚板子上的丝印标识。 大家有什么关于硬件连接的具体问题,楼下留言!
回音消除
原创 . 2026-07-03 2009

德明利推出TC301 Type-C车载U盘,打造更稳定的车载哨兵存储体验
智能汽车驻车监控、录像等场景持续增长 单日录像数据可达数10GB 普通U盘写满后无法循环覆盖易造成录像中断 德明利推出TC301系列USB Type-C车载U盘 兼顾高速读写、稳定运行的可靠性能 适配车载录像存储需求 让全天候录制“不断档” 01|小巧机身,更贴合车机空间 不遮挡、不硌手,T型短机身更适配 TC301采用T型短机身设计,整体尺寸仅26.1mm×16.1mm×16mm,长期插载不遮挡、不硌手,更适配隐藏式车载接口环境。 全金属+Type-C,质感与耐用兼得 产品采用全金属外壳设计搭配USB Type-C接口,兼顾产品质感、散热性能与长期耐用性,适用于更多智能汽车及车载设备场景。 02|高速稳定存储,满足持续录像需求 TC301核心性能要点 产品参数 采用USB 3.2 Gen1高速传输协议 读取速度最高可达320MB/s、写入速度最高可达255MB/s 精选原厂TLC NAND Flash,品质有保障 搭配稳定可靠的存储方案,运行更安心 满足高清视频循环录制、录像回看需求 03|7×24H循环录像,复杂环境稳定运行 全场景录像,模式随心切换 针对车载长期在线运行场景,TC301支持行车记录、停车监控、哨兵模式及长时间循环录像等应用需求。 高负载环境下稳定不掉线 当存储空间写满后,系统可自动循环覆盖旧录像,持续记录关键画面。产品支持-25℃~85℃工作温度及-40℃~85℃存储温度,并通过EMI/EMC、静电、盐雾等多项可靠性测试,可适应高负载循环录像及复杂车载环境。 面向智能汽车与车载录像持续升级趋势 德明利将持续围绕高速、稳定、可靠的存储需求 打造更适配智能终端与 车载场景的存储产品解决方案
TWSC . 2026-07-03 4165

思特威携MicroLED高速光互连方案重磅亮相慕尼黑上海电子展
思特威(上海)电子科技股份有限公司于7月1日至3日,亮相上海新国际博览中心举行的2026慕尼黑上海电子展。作为电子行业年度标杆盛会,展会聚焦工业互联网、智能汽车、数据中心、智能家居等热门赛道,搭建起供全球企业与行业专家开展技术交流、新品发布的专业平台,集中展现全球电子产业前沿发展趋势。在本届展会上,思特威以“感知、互连、计算”为主题,携全新工业机器视觉图像传感器产品矩阵、高性能AI视觉处理芯片以及新一代高速光互连方案重磅亮相。这也是自思特威发布 “3+AI” 战略后,一次完整的阶段性创新成果展示。 图:思特威亮相2026慕尼黑上海电子展 高精感知,赋能工业AI检测 面向智能交通场景,思特威在现场展示了1400万像素高性能全局快门图像传感器SC1435HGS。该产品基于思特威SmartGS™-2 Plus技术平台打造,搭载Lightbox IR®近红外增强技术。SC1435HGS具备高感度、高动态范围、高帧率与低噪声等核心优势,基于4480Hx3072V的优化分辨率比例,SC1435HGS的横向画幅可稳定覆盖城市五条车道,大幅减少视野盲区,为智能交通摄像头提供清晰、完整的高质量图像数据支持。 图:高性能智能交通应用展示 随着印刷、纺织、金属加工等行业智能化转型的加速,产线对检测精度与效率的要求持续攀升,线阵图像传感器已成为实现高效高精度检测的关键设备。本次慕尼黑上海电子展上,思特威通过花布滚筒演示装置,展出了8K超高分辨率高速线阵CMOS图像传感器SC835LA。SC835LA依托思特威SmartClarity®-3成像平台打造,搭载全新升级的BSI像素工艺和掩膜拼接技术,兼具高行频、高感度、低功耗、低噪声多重性能优势。同时,SC835LA提供黑白、彩色双版本,搭配其出众的成像画质与高速传输能力,能够精准匹配超长连续物件的高速检测需求,为复杂的工业智能产线提供高效、稳定的视觉支撑。 图:高端工业线阵相机应用展示 此外,思特威在展会现场还展出了超大靶面超高分辨率工业相机应用CIS SC4880RS、12MP AI眼镜应用CIS SC1220IOT和2MP超小尺寸医疗应用CIS SC1400ME等多款前沿产品与多元应用解决方案,全方位展示了思特威在工业机器视觉领域的深厚积累和产业布局。 高速互连,搭建高带宽光传输通道 作为本次参展的第二个重磅板块,思特威新一代高速光互连方案首次亮相。该方案利用MicroLED作为光源替代传统激光器,依托其非激光自发辐射特性,可将光电转换效率提升30%,显著优化整机供电利用效率,有效缓解算力设备长期运行下的功耗压力。面向50 米内短距通信,适配芯片间、板间互联场景,方案原生支持GPU/HBM 全并行互联协议,凭借集成光源 + 直接调制 + 信号直连架构实现物理层接口精准匹配,可承载算力集群海量数据高速吞吐,广泛赋能 AI 数据中心、智能驾驶、高端工业视觉等领域。 图:高速光互连原型样机演示 针对传统电互联架构存在的传输性能瓶颈,本方案采用MicroLED 并行光传输架构,整体可支持 1Tbps+ 超大并行传输带宽,以数百路并行低速光通道替代传统少量高速电通道,从根源解决电互联带宽不足、功耗高、信号串扰、传输距离受限等多重痛点。现场展示的数据显示,MicroLED 单通道传输速率已突破 3Gbps,典型功耗低至 0.8pJ/bit,兼具高速传输与低能耗优势。思特威高速光互联BG联席总经理王文轩表示,光互连是算力产业发展的重要基石,其核心技术的国产替代已是必然趋势。思特威自布局之初便秉持开放合作理念,持续深化与产业链伙伴全域协同,填补国内高端短距光互连领域空白,推动国内半导体与算力产业实现高质量自主发展。同时,王文轩提到,MicroLED高速光互连方案有望在2027年商用落地。 图:MicroLED单路3Gbps传输速率实时眼图 智能计算,构筑端侧视觉AI 聚焦轻量级AI边缘计算,思特威子品牌飞凌微在现场展出全新迭代车载视觉处理SoC M2。M2 采用了ARM 4核A53 CPU搭配双核R52 MCU 的双域架构设计,内置自研NPU,算力可达10TOPS,多模型并行推理能力强劲,可同步接入多路摄像头。同时,依托稠密算力架构支撑车载高清视觉全流程处理,针对环视、前视、车内监控等多路高清图像完成全像素运算,完整保留画面细节,保障行车感知可靠性。M2拥有自研AI-ISP技术,减少图像数据反复内存读写操作,显著降低处理时延与整机功耗;并且能更好地实现HDR合成、2D与3D降噪等功能,大幅提升了成像画质。M2符合AEC-Q100 Grade2 车规标准,原生达到ISO 26262 ASIL-B 功能安全等级,适用于L2前视一体机、流媒体&电子后视镜、DMS & OMS、高清环视系统等多种车载视觉方案。 图:飞凌微车载后视行人感知演示 飞凌微同步推出面向机器人、工业视觉领域的AI视觉处理SoC A2。该芯片支持四路摄像头同步接入,搭载硬件 DPU 实现双目深度运算;内置 NPU 可并行运行图像分割、避障、VSLAM 定位等多类算法,一站式实现高精度视觉感知与高可靠实时安全控制。 图:飞凌微 AI视觉处理SoC A2双目实时深度图 以技术筑基,以创新赋能,自创立以来,思特威始终深耕高端成像技术的研发迭代。依托“3+AI”发展战略,构建“高精感知—高速互连—智能计算”技术闭环,促进三大核心技术与AI的深度融合。在夯实车载、安防、消费电子 CIS 核心主业基本盘的同时,思特威积极布局工业视觉、光互连、端侧 AI SoC新兴赛道,持续完善全栈技术矩阵与多元产品生态。凭借自主前沿技术推动成像技术的革新,为千行百业的智能化、数字化发展进程注入核“芯”动力,护航智能制造产业高质量发展。
思特威 . 2026-07-03 2065

算力狂飙,大联大诠鼎携手MPS展现AI数据中心电源方案的革新与未来
大联大控股旗下诠鼎集团宣布,携手全球领先的半导体公司芯源系统(MPS)成功举办“算力狂飙下AI数据中心电源方案的革新与未来”线上研讨会。本次会议聚焦AI数据中心电源领域的核心变革与实战方案,围绕算力增长对电源方案的深层影响、电源架构迭代路径、高功率密度方案落地、前沿技术趋势四大维度展开深度交流,携手破解研发难题,共探技术方向和合作先机。 在生成式AI与大模型训练需求爆发的当下,全球算力基础设施正迈入高功率、高密度、高能效的全新阶段。目前,AI服务器整机柜功耗已从传统数十千瓦跃升至数百千瓦,部分高端智算机柜更是向兆瓦级迈进。算力的指数级增长,已让电源系统从“配套支撑”变为决定AI算力上限的核心命脉,传统供电架构与方案正面临前所未有的挑战。 会上,MPS FAE主管王鑫诚(Seazen)指出,算力爆发下,AI服务器功耗急剧攀升,负载剧烈波动,散热逼近风冷极限,倒逼电源向高功率、高效率、高可靠、高集成演进。在架构演进层面,他系统梳理了从传统到革新的供电范式迭代路径。从早先的12V母线供电,到如今主流的48V配电架构,以及未来的800V母线配电架构,输入电压的提升显著降低了母线损耗,让数据中心的电力配置更加高效安全。另外,主芯片端Z轴供电(ZPD™)方式打破了传统平面供电的思维定式,将电压调节模块垂直布置于处理器正下方或紧邻侧方,极大缩短了功率传输路径。这种三维立体供电思路,不仅能够大幅将PDN(配电网络)路径损耗降低十倍以上,还显著改善了整机的瞬态响应能力和功率密度。 在实践层面,王鑫诚着重介绍了MPS高功率密度方案的技术突破与落地成果。MPS为DrMOS(驱动+MOSFET集成功率器件)开发的Quiet Switcher™ Technology(QST,低噪声开关技术),其核心目标是抑制开关节点电压尖峰,同时不牺牲开关速度和效率,这在高压大电流场景下尤为重要。凭借基于第六代BCD6工艺的产品布局,MPS在单片上实现了更高的功率密度和更优的效率性能。此外,MPS产品采用独立温度监测与自适应温度平衡技术,搭配顶部散热的先进封装,大幅降低了电源的运行温度,使得功率器件在高负载工况下依然能保持卓越的温度特性,为AI服务器的稳定运行提供了根本保障。 王鑫诚进一步分享了MPS在AI供电领域的核心产品矩阵:MPS高性能48V IBC(中间总线转换器),依托LLC软开关拓扑,在功率密度与转换效率之间实现了双重突破,特别适用于高密度计算场景;MPC22166-D与MPC22175均以超小体积集成两路130A输出能力,凭借高效集成优势,完美适配中高端AI服务器的GPU/CPU核心供电需求;同时,MPS推出的第四代DrMOS模块产品,集成4相DrMOS,具备的强大输出,专为顶级GPU/TPU加速卡设计,支持垂直供电形态,为下一代超大规模AI集群的供电设计树立了全新标杆。 展望未来,王鑫诚预判了AI电源方案的若干关键趋势:800V HVDC将在未来三至五年内实现规模化商业落地,从超大规模云服务商率先部署,逐步向企业级数据中心渗透;SiC(碳化硅)与GaN(氮化镓)等宽禁带半导体器件的成本持续下探,将加速其在AC-DC前端和高压DC-DC段的应用普及,进一步推高整机效率;数字电源的智能化管理将成为标配,通过实时监测、自适应控制和预测性维护,实现供电系统与AI负载的深度协同。这些技术趋势的融合,将帮助构建面向智算数据中心AI服务器、大模型算力机房、高端GPU配套供电系统的高效、绿色、可扩展的下一代AI供电体系。 未来,大联大诠鼎将持续携手MPS,依托双方在技术洞察、产品落地和供应链整合上的深厚积累,不断优化电源解决方案,助力更多企业实现产品小型化、高效化、节能化升级,共同推动全球电源产业绿色低碳、高质量发展,为AI时代的算力底座筑牢每一瓦特的根基。 作为全球领先电子元器件分销商,大联大诠鼎集团凭借多年的渠道经验,不仅是零件供应商,更是客户的技术战略伙伴。为迎战全球化布局,自2026年起,原品佳、诠鼎、友尚三大集团整合为全新的诠鼎集团,深度聚合三方优势资源,实现资源更集中、服务更全面、供应链韧性更强的综合效益。通过整合数字化供应链管理与专业技术支持优势:在开发端,协助解决技术难题,加速产品上市;在量产端,提供精准的库存管理与实时交货服务,致力于为客户优化营运成本、应对市场变局,并提供稳定、及时的交付承诺。 本次研讨会全程通过大联大旗下平台“诠鼎大大芯”进行直播,无需注册登录即可观看,“诠鼎大大芯”平台每月举办多场研讨会,分享市场最新技术趋势与热门应用实例。欢迎业界同仁随时回顾精彩内容,深入了解AI数据中心电源方案的革新与未来。
大联大诠鼎 . 2026-07-03 1925
企业 | 英飞凌侵权产品在上海慕尼黑电子展遭当场撤展下架
2026年7月1日,英飞凌在上海慕尼黑电子展上再陷尴尬:因展出已被中国法院明确禁止销售、许诺销售、进口的侵权氮化镓(GaN)产品,被专利权人英诺赛科当场发现后,撤展下架。 此前,英飞凌已因侵犯全球氮化镓领军企业英诺赛科的两项核心发明专利,被苏州市中级人民法院判令立即停止侵权并赔偿1000万元,相关行为保全裁定更被最高人民法院复议维持。 苏州中院一审认定侵权成立,行为保全裁定立即生效 本案源于2024年底,英诺赛科向苏州市中级人民法院提起诉讼,指控英飞凌科技(中国)有限公司、英飞凌科技(无锡)有限公司及代理商侵犯其两项氮化镓核心发明专利(专利号:202311774650.7和202211387983.X)。 2026年5月27日,苏州市中级人民法院作出一审判决,认定英飞凌侵犯英诺赛科两项发明专利,侵权产品涵盖英飞凌CoolGaN™系列等多款氮化镓功率器件。法院判令英飞凌停止销售、许诺销售、进口等侵权行为,并赔偿英诺赛科经济损失合计人民币1000万元。随同判决书同时送达双方当事人的,还有苏州中院针对英飞凌一次性发出的两张诉中临时禁令(行为保全)裁定,要求英飞凌立即停止许诺销售、销售、进口相关被诉侵权产品,裁定效力维持至案件裁判生效时止。 最高人民法院复议维持禁令,英飞凌不得再行上诉,禁令已生效 英飞凌不服苏州中院的行为保全裁定,向最高人民法院申请复议。2026年6月12日,最高人民法院正式发出两份诉中临时禁令复议裁定书,驳回英飞凌全部复议请求,明确维持苏州市中级人民法院此前作出的临时禁令裁定。这意味着,英飞凌相关氮化镓产品自5月27日起在中国境内被全面禁止销售、许诺销售和进口,且英飞凌无法再对最高人民法院的复议裁定继续上诉。 禁令之下英飞凌竟公然展出侵权产品,展会现场被当场撤展下架 然而,就在最高人民法院复议裁定维持禁令、正式宣告英飞凌相关氮化镓产品在中国境内禁售之后不到三周,英飞凌竟在2026年7月1日开幕的上海慕尼黑电子展上,公然展出已被法院认定侵权的氮化镓产品。 权利人英诺赛科在展会现场发现英飞凌仍在展出禁令中涵盖的侵权产品后,当即找到展会方派驻的上海市浦东新区知识产权纠纷人民调解委员会的调解员,提出要求英飞凌针对侵权产品的撤展要求。调解员在听取了双方意见并在英飞凌展区实地调查后,支持了英诺赛科的主张。在确凿的司法裁定和无可辩驳的侵权事实面前,英飞凌当场撤下相关侵权展品。 英飞凌这一行为是对中国司法权威的公然藐视,因为苏州中院的行为保全裁定自2026年5月27日送达之日起即已生效,最高人民法院于6月12日复议维持后,禁令的法律效力已无可争议,英飞凌竟仍然公开展出侵权产品,简直令人匪夷所思。 国际企业不应凌驾于中国法律之上 英飞凌作为全球半导体行业的跨国公司,在中国市场经营多年,理应熟知并严格遵守中国法律法规。在经历苏州中院一审判决、行为保全裁定以及最高人民法院复议维持的全链条司法程序之后,英飞凌仍然在大型行业展会上展出侵权产品,不仅是对权利人合法权益的持续侵害,更是对中国司法权威的严重挑衅。今天英飞凌的侵权产品在展会上被当场撤展下架,正是说明了任何国际企业都不能凌驾于中国法律之上,英诺赛科的自主原创知识产权不容任何人的侵犯。
英诺赛科
英诺赛科 INNOSCIENCE . 2026-07-02 2625

涨价 | 日月光投控将再度调整封装报价,最高涨幅超过20%。
7月1日消息,据台媒MoneyDJ报道,由于原料成本上涨、长期投资成本提升及供给紧俏,业界传出消息称,全球最大的半导体封测厂商——日月光投控将再度调整封装报价,最高涨幅超过20%。 报道指出,日月光投控本次涨价涵盖CoWoS、FoCoS等先进封装,并且包括了一线美系大客户。 值得注意的是,今年1月8日,摩根士丹利就曾发布研究报告透露,在人工智能芯片需求持续爆发的推动下,日月光正计划将先进封装服务的报价上调5%至20%,远超市场此前普遍预期的5%至10%区间。 由于AI应用带动半导体需求强劲,叠加台积电CoWoS先进封装产能供不应求、外包比重持续提升,日月光投控承接的基板上封装(oS)、晶圆测试(CP)也在持续增加。 可以说,目前封装龙头及中小型封测厂产能利用率几乎都维持满载水准,相关公司也在积极扩充产能应对。与此同时,封装所需的原材料、运输等成本,以及扩产所需的设备、人力成本也都在持续上涨。一方面是产能供不应求,另一方面是成本上涨,这两大因素推动了封测厂的涨价。 针对涨价策略,日月光投控营运长吴田玉在今年6月股东会后接受媒体采访时回应称,涨价是非常敏感的问题,大致可分成几个部分来看:首先是反映原材料价格上涨,这类涨价有其必要性。其次,是反映投资金额增加、投资成本的考察。 吴田玉进一步指出,日月光过去每年资本支出大约20亿美元,2025年提升至53亿美元,今年则上调到85亿美元,未来也不排除再上调,这也是成本结构一部分。 吴田玉称,过去准备的所有厂房产能,在面对突如其来的强劲AI需求时,瞬间就被消耗殆尽。目前,日月光集团正火力全开地进行扩产,包含日月光本身的6个新建厂房(Greenfield)计划、旗下矽品的7个新厂计划,若再计入收购群创及其他公司的厂区,集团整体的扩产计划高达约15个。 至于是否因市场供需失调而采取价格策略,吴田玉表示,这部分见仁见智,公司希望保留给经营团队有考察空间。 AI实体经济、车用电子、Humanoid等下一波应用投资。因此,价格调整必须兼顾未来与客户的合作紧密性、客户信任度,以及长远投资信心。
涨价
芯智讯 . 2026-07-02 2492
- 1
- 7
- 8
- 9
- 10
- 11
- 500