
兆易创新携前沿解决方案亮相2026慕尼黑电子展,多维突破加速产业智能化转型
兆易创新GigaDevice携70余款产品及解决方案亮相2026慕尼黑上海电子展。本次展品阵容涵盖存储器、微控制器、模拟芯片、传感器等全系产品线,并聚焦AI技术与终端应用的深度融合,覆盖具身智能、数据中心/服务器、工业与数字能源、汽车/两轮车以及消费电子等重点领域,全方位展现了兆易创新在多元应用的技术积淀与广泛布局。依托持续的技术突破、精准的市场洞察、丰富的产品矩阵,兆易创新将不断为客户提供创新的解决方案,驱动行业智能化升级。 2026慕尼黑上海电子展于7月1日至3日在上海新国际博览中心举行,兆易创新位于N5馆205展位,诚邀您莅临。 具身智能:多维布局,释放工业与协作新动能 随着协作机器人、四足机器人等应用加速发展,机器人系统对主控性能、实时通信、运动控制精度和安全交互能力提出更高要求。兆易创新围绕关节驱动、电源管理等环节,展示多款基于GD32 MCU和模拟芯片的机器人应用方案。 基于GD32H7系列MCU的六轴机械臂方案:该方案由关节驱动器和上位机主控两部分组成,面向六自由度协作机器人控制系统。关节驱动器基于GD32H75E,负责关节电机底层伺服控制,配备17/18位双绝对值编码器,实现高精度位置反馈,并支持CoE通信及CiA 402协议。上位机负责轨迹规划、示教记录、轨迹回放和运行监控,并集成静态OBB碰撞检测、动态力控碰撞检测功能。方案可适用于协作搬运、装配、教学实验等场景。 同时,公司还带来了基于GD30AD3642高精度ADC六维力检测方案、GD30DC1901 100V/1A高电压同步降压电源方案、基于GD32H75E的机器人关节等方案,满足具身智能多场景需求。 数据中心与服务器:筑牢算力底座,赋能全生命周期安全支持 伴随大模型训练及海量云计算的井喷,数据中心与服务器主板对数据吞吐的即时性、高密度存储和全面热管理提出了前所未有的严苛挑战。 在数据中心展示区,兆易创新带来了多款适配业界主流服务器GPU、DPU平台的存储方案。GD25/55系列SPI NOR Flash提供512Kb至2Gb的全容量选择、多种电压选项,具备高速读取、高可靠性、多重安全机制等特性,支持不同温度等级,在服务器的BIOS固件存储、基板管理控制器(BMC)代码引导中发挥着“数字基石”的作用,多维立体地构筑了现代算力基础设施的安全底座与功耗管理闭环。 工业与数字能源:高可靠性绿色引擎,技术融合与场景落地并进 在清洁能源光储一体化、高功率密度数字电源以及大模型AI服务器电源需求的驱动下,供电与监测技术的升级已成刚需。兆易创新通过控制、存储、模拟芯片产品,为数字能源和工业控制筑牢了绿色、高效、高可靠性的硬件基石。 基于GD30AD3584的行波测距参考方案:本设计旨在以无FPGA架构,打造一种低成本、低功耗、紧凑型的智能电网故障定位解决方案。方案支持4路交流信号和4路故障波信号同步采集,并集成GPS时间校准以及高速数据采集和存储,同时为客户算法预留充足的MCU算力。 基于GD32H77x系列MCU的QT HMI图形显示方案:得益于GD32H77x的高主频和大容量内置SRAM,能够平稳、流畅地渲染QT的精美图形界面,交互响应毫无延迟,为工业控制终端、智能仪表和高端家电提供了极具市场竞争力的显示控制解决方案。 一并展示的还有GD30系列高压DC-DC电源方案、搭载GD5F4GQ6UEYIGR SPI NAND Flash的全志T153开发板、基于GD32G5系列MCU的1kW一拖二单级型光伏微型逆变器、采用GD32H77D MCU、GD25Q256E Flash和GSL3776 触控芯片的高性能人机界面交互显示等方案,为客户提供便捷的开发体验。 汽车/两轮车:驱动智能出行变革,全方位守护车规级安全 随着汽车电子电气架构由分布式向区域控制和中央计算演进,国产车规级芯片正迎来前所未有的发展机遇。兆易创新构建了涵盖车规存储器、车规级MCU在内的稳固生态圈,全方位赋能智能驾驶与两轮车智能化升级。 搭载GD25/55 SPI NOR Flash和GD5F SPI NAND Flash的汽车电子解决方案:兆易创新车规级产品严格遵循ISO 26262 ASIL D功能安全流程开发,全系列车规级存储产品均已通过AEC-Q100认证,累计出货量突破4.5亿颗,广泛应用于汽车电子领域。本次展会重点展示其在ADAS域控制器、前视一体机及区域控制器等关键场景中的应用,为智能汽车提供高可靠的数据存储支撑。 基于GD32A7x系列MCU的汽车/两轮车解决方案:作为公司的新一代车规级MCU,GD32A7系列采用Arm® Cortex®-M7内核,最高主频为320MHz。凭借卓越的运算性能,可满足汽车与两轮车多样化应用需求。本次展会重点展示了基于GD32A7x系列打造的汽车小电机驱动、电助力转向系统以及摩托车智能仪表等解决方案,全面展现其在智能出行领域的应用潜力。 消费电子:端侧大模型落地,加速AI应用多元场景 AI技术正在重塑传统的消费电子与物联网生态,端侧AI与边缘计算已经成为产业转型的新风口。兆易创新紧密围绕大容量高性能存储和MCU芯片,带来了多款端侧AI方案。 搭载GD25Q256E系列 SPI NOR Flash的瑞芯微RV1126开发板:GD25Q256E系列可支持固件配置加载并具备安全加密功能,方案支持4K@60fps视频处理,并内置1.2TOPS AI算力NPU,广泛适用于智能安防、边缘计算、工业控制等场景。 搭载GD5F2GM7 SPI NAND Flash的AI智慧教育箱:方案采用AI语音采集设备,能够实时追踪儿童语言发展。GD5F2GM7系列以其大容量、高可靠性优势,可实现录音数据的高效存储。 此外,基于GD32H7x系列MCU的3D打印机、基于GD32M531系列MCU的家用变频空调方案,以及基于GD32H7系列MCU的民用飞控方案等也在该区域进行了展示。 兆易创新通过在各细分行业的长久精耕细作,已构筑了多元化产品矩阵和一站式解决方案体系。未来,兆易创新将始终坚持以技术为本,深入挖掘并响应全球客户的差异化需求,精心培育创新性技术,全力推动相关产业向数字化、智能化、绿色化方向飞速转型升级。
兆易创新 . 2026-07-01 1932

兆易创新推出首款GD24CL系列I²C EEPROM,完善存储产品线布局
兆易创新GigaDevice宣布推出全新GD24CL系列I²C通信接口的EEPROM,首发容量为256Kb。该产品系列凭借优异的可靠性指标,高效接口以及全方位的安全防护机制,能够切实满足工业、电表、能源、数字基础设施等领域对关键配置信息长期、稳定保存的严苛需求。作为兆易创新推出的首款EEPROM产品,该系列的发布进一步完善了公司的非易失性存储产品线,并将为客户智能设备的稳健运行提供更具竞争力的存储解决方案。 GD24CL系列在设计之初便紧紧围绕高可靠性这一核心指标。产品擦写寿命高达400万次,是行业传统标准的4倍,能够轻松应对高频次参数改写的严苛挑战;数据保存时间长达100年,可确保归档数据的长效稳定性;芯片内置硬件级ECC纠错功能,可显著提升数据完整性与系统运行可靠性。该系列还支持-40℃~125℃超宽工作温度范围,全面适配各类应用严苛的工作环境。 为了适配多元化的系统通信需求,GD24CL系列支持100KHz、400KHz及1MHz三档时钟频率,全面覆盖从低速传感设备到高速工业控制的各类应用。同时,产品支持字节级随机读写,尤其适用于频繁更新小批量参数的应用场景,在提升操作灵活性的同时,进一步优化了系统的数据写入效率。 针对复杂工况下的系统安全风险,GD24CL系列配备了完善的硬件安全防护机制,为关键数据资产提供多重保障。芯片内置WP(Write Protect)硬件写保护功能,能够有效拦截因系统异常、软件跑飞或恶意攻击导致的数据误写。此外,产品还特别内置附加写可锁页(Additional Write lockable Page),一旦锁定,核心数据信息将不可更改,从根本上杜绝数据篡改风险,在硬件层面筑牢数据安全防线。 功耗控制方面,GD24CL系列也同样具备显著优势。产品支持1.7V至5.5V的宽电压工作范围,其待机电流低至1µA,读电流低至1mA,写电流低至1.5mA。其低功耗特性使该产品系列精准契合工业物联网终端、绿色数据中心以及其他对能耗有严苛限制的应用场景,能够为设备的长效续航提供坚实支撑。 为了配合现代电子产品日益紧凑的电路板设计空间,GD24CL系列采用引脚少、通信简单的I²C总线接口与主控芯片交互。其封装支持SOP8 150mil、TSSOP8 173mil以及更轻薄的UDFN8 2×3mm等多种小型封装形式,助力客户实现更为紧凑的高效系统集成。 作为兆易创新在存储芯片领域的又一里程碑,GD24CL系列EEPROM拥有丰富的容量路线图。目前,首发256Kb容量芯片已开放样片申请,128Kb和512Kb容量产品正在研发中,计划于2027年上半年陆续面世,并将为更多行业客户提供丰富、具有竞争力的存储解决方案。如需获取详细技术资料或报价信息,欢迎联系当地授权销售代表。
兆易创新 . 2026-07-01 819

产品 | 南芯科技发布面向算力芯片供电的多相DrMOS电源方案
今日,南芯科技(证券代码:688484)重磅发布 22V/60A 大电流 DrMOS SD13050,及双路四相控制器 SD22442,为 CPU/GPU/SOC 等算力芯片提供高效可靠的供电解决方案。两款产品均同步提供工规与通过 AEC-Q100 Grade 1 认证的车规版本,可覆盖从数据中心、边缘服务器到自动驾驶的广泛计算场景。 算力爆发,催生多相电源增量蓝海 当前,AI 算力建设已进入爆发期。大模型训练、自动驾驶、工业智联等场景的快速迭代,使算力需求呈指数级增长。据机构预测,2026 年全球 AI 服务器出货量将达到约 370 万台,同比增长 51.3%。 AI 算力热潮带来的不仅是芯片功耗的飙升,更是电流需求的成倍放大。在此背景下,多相控制器 + DrMOS 的低电压大电流方案,凭借其可支持更大电流、更优瞬态响应和更高效率的优势,已成为大算力芯片的主流供电技术,并有望从高端服务器向通用 AI 服务器、边缘算力全面渗透,迎来更广阔的发展空间。 CPU/GPU高效供电解决方案 DrMOS 通过合封或单 die 技术,将驱动器与功率 MOSFET 集成于同一封装内,具备更小体积、更低寄生参数、更快开关速度和更低损耗等优势,同时可简化 PCB 布局,提升热管理性能,尤其适用于对空间和效率要求极高的高密度电源应用场景。其中,单 die 方案有利于未来垂直供电架构中 VRM 封装模块的集成,为下一代算力芯片的供电形态预留了更大的演进空间。通过多路 DrMOS 并联,算力芯片可承载的电流得以线性增加,但随之而来的是指数级增长的控制复杂度。多相控制器正是应对这一挑战的核心,它负责与主芯片通信,动态调配各相输出,实现对整个供电系统的精准协同控制。 南芯科技 CPU/GPU 高效供电解决方案 (SD13050 + SD22442) 支持 5V-16V 输入总线及双电压轨输出,每路相数灵活可配,可适配不同功率等级的设计需求。SD22442 支持 DCM(非连续导通模式)与 APS(主动切相)功能,配合 SD13050 的高精度 ZCD 电流检测,可显著优化轻载条件下的系统效率。 DrMOS SD13050 作为整套方案的能量转换核心,SD13050 可在 5mm*6mm 的极小 LGA 封装内实现高达 60A 的连续输出电流,并在全负载范围内保持高效率,同时具备高精度采样与全面保护机制。通过优化的死区时间控制与寄生电感抑制设计,SD13050 确保系统在全负载条件下维持高效率。此外,SD13050 集成了高精度电感电流采样与温度采样功能,为四相控制器提供实时故障保护的数据支撑。内置的丰富保护机制可有效防止自举电容过度放电,确保高频运行下的系统可靠性。 双轨四相数字控制器 SD22442 SD22442 则是整套方案的指挥中枢,采用 6mm*6mm QFN 封装,支持在两个独立电压轨上灵活配置最多四相输出。其核心竞争力在于全面的数字控制能力与丰富的接口兼容性:兼容 PWMVID 和 PMBus 双通信协议,可灵活适配不同处理器平台的电源管理规范;内置 MTP 存储器,支持用户自定义配置的安全存储与调用。车规版本 SD22442Q 符合 ISO 26262 ASIL-B 功能安全等级,为对安全性有严苛要求的自动驾驶系统提供坚实保障。 南芯科技算力电源产品家族 随着 AI 算力从云端向边缘、终端持续下沉,以及自动驾驶等级的不断提升,大电流、高动态的供电需求将成为算力芯片的长期刚需。南芯科技 SD13050 与 SD22442 的组合方案,以完整的供电架构、灵活的双轨配置和车规级的安全保障,为这一趋势提供了牢固的技术底座。未来,南芯将持续深耕高功率密度电源管理领域,以更全面的产品矩阵,助力全球算力基础设施的能效升级。 SD13050+SD22442 CPU/GPU高效供电解决方案将亮相慕尼黑上海电子展南芯展位(N4 馆 N4.608),欢迎大家莅临参观交流。
南芯科技
南芯科技 . 2026-07-01 1449

2026微碧半导体VBsemi亮相慕尼黑上海电子展-聚焦AI算力、人形机器人、储能与低空经济,共讨功率半导体新机遇
随着AI大模型、人形机器人、新能源储能以及低空经济的快速发展,全球功率半导体产业正迎来新一轮增长周期。MOSFET、SiC、GaN等新一代功率器件正在加速渗透,从AI服务器到人形机器人,从储能PCS到eVTOL航空电推进,功率器件已成为决定系统效率、功率密度与可靠性的核心基础元件。 2026年7月1日至3日,微碧半导体(VBsemi)将携最新功率器件产品矩阵及行业解决方案亮相慕尼黑上海电子展(electronica China 2026),诚邀广大客户、合作伙伴及行业专家莅临交流,共同探讨未来功率半导体产业发展趋势与国产替代新机遇。 AI时代来临,功率器件迎来新增长引擎 近年来,AI算力需求呈指数级增长 随着大型数据中心、AI服务器、高性能GPU集群不断扩容,服务器供电架构正在从传统12V向48V高功率密度平台演进。 与此同时:热插拔(Hot Swap),ORing保护,同步整流,高频DC/DC,Totem Pole PFC 等关键电源环节,对MOSFET、GaN和SiC器件提出了更高要求。 VBsemi持续布局AI服务器与通信电源市场,推出超低导通电阻MOSFET系列、高频GaN平台以及高效率SiC解决方案,为新一代AI算力基础设施提供高可靠功率器件支持。 人形机器人产业爆发,低压MOSFET需求持续增长 2026年,人形机器人产业正在从概念验证逐步迈向规模化应用。 无论是双足机器人、四足机器狗还是协作机器人,其核心都离不开高性能电机驱动系统。 在典型48V机器人平台中:主关节驱动,伺服控制系统,执行器驱动,BMS系统,辅助电源模块 均大量使用低压大电流MOSFET。 VBsemi围绕机器人应用打造DFN5×6、LFPAK56、TOLL等多个明星封装平台,持续优化导通电阻、热性能与功率密度,为机器人产业升级提供核心器件支撑。 储能与新能源市场持续高速增长 随着全球能源结构转型加速,储能市场已成为功率半导体最重要的增长领域之一。 从户外储能到工商业储能,从光伏逆变器到储能PCS,高压功率器件需求快速增长。 VBsemi重点布局: SiC MOSFET平台;;650V SiC;1200V SiC TO247-4L;TOLL-HV;TO263-7L-HV 超结MOS平台;650V Super Junction MOS;850V Super Junction MOS 帮助客户实现:✔ 更高转换效率;✔ 更低系统损耗;✔ 更高功率密度;✔ 更优成本结构 低空经济与eVTOL开启未来蓝海市场 低空经济被认为是未来十年最具潜力的新兴产业之一。 特别是在:eVTOL电动垂直起降飞行器,工业无人机,物流无人机,航空无线充电系统等领域,高压SiC功率器件正逐步成为主流方案。 VBsemi围绕航空电推进系统、高压逆变器、高压DC/DC及无线充电系统等应用场景,积极布局下一代SiC功率平台,为低空经济产业链提供高可靠、高效率功率解决方案。 国产替代进入“方案替代”时代 近年来,国产功率半导体产业取得长足进步。 客户对于国产替代的需求,已经从单纯的器件替代升级到系统级解决方案替代。 VBsemi持续推进:Infineon替代方案;onsemi替代方案;Nexperia替代方案;Vishay替代方案;Toshiba替代方案 在众多机器人、储能、电源及工业控制项目中实现批量导入 通过:性能兼容,封装兼容,成本优化,本地化技术支持,帮助客户构建更加安全、稳定、高效的供应链体系。 展会现场重点展示内容 本次慕尼黑上海电子展期间,VBsemi将重点展示: AI服务器与通信电源解决方案:Hot Swap,ORing,同步整流,高频GaN方案 人形机器人系统解决方案:关节驱动MOSFET,48V电源架构,执行器驱动方案 储能PCS与BMS解决方案:高压SiC平台,超结MOS平台,双向DC/DC方案 eVTOL与低空经济解决方案:高压逆变系统,无线充电系统,航空电推进平台 国产替代与明星产品展示:超低阻MOS系列,高频GaN系列,高压SiC系列,储能专用平台器件 诚邀莅临交流,共探未来功率半导体发展方向 2026年,AI、人形机器人、储能、新能源汽车以及低空经济正在共同推动功率半导体产业进入新的发展阶段。 微碧半导体(VBsemi)期待与广大客户、合作伙伴及行业专家面对面交流,共同探讨未来市场趋势、技术创新方向以及国产替代发展机遇。 2026慕尼黑上海电子展 微碧半导体 VBsemi 展位号:N5.150 展会时间:2026年7月1日-3日 展会地点:上海新国际博览中心 相约上海 · 共话未来 AI算力 × 人形机器人 × 储能 × 低空经济 微碧半导体VBsemi期待与您相聚慕尼黑上海电子展!
微碧
微碧半导体 . 2026-07-01 1337

BVSS123LT1G与VB1106K参数对比报告
N沟道功率MOSFET参数对比分析报告:BVSS123LT1G与VB1106K 一、产品概述 BVSS123LT1G:安森美(onsemi)N沟道100V功率MOSFET,采用车规级AEC-Q101认证流程(BVSS前缀),具有较高的ESD防护能力(HBM Class 0A)。封装:SOT-23。适用于汽车电子、便携设备等需要高可靠性的开关与放大应用。 VB1106K:VBsemi N沟道100V沟槽(Trench)功率MOSFET,低阈值电压,低输入电容,快开关速度,符合RoHS及无卤标准。封装:SOT-23。适用于负载开关、DC-DC转换、信号放大等低压高效应用。 二、绝对最大额定值对比 参数 符号 BVSS123LT1G VB1106K 单位 漏-源电压 VDSS 100 100 V 栅-源电压 - 连续/非重复 VGSS / VGSM ±20 / ±40 ±20 V 连续漏极电流 (Tc=25°C) ID 0.17 0.26 A 脉冲漏极电流 IDM 0.68 0.8 A 最大功率耗散 (Tc=25°C) PD 225 370 mW 结温/存储温度 TJ, Tstg -55 ~ +150 -55 ~ +150 °C 雪崩能量(单脉冲) EAS 未提供 未提供 mJ 雪崩电流 IAV 未提供 未提供 A 分析:两款器件耐压等级相同(100V)。VB1106K在电流与功率能力上更具优势,其连续漏极电流(0.26A vs 0.17A)和最大功耗(370mW vs 225mW)均高于BVSS123LT1G。BVSS123LT1G则提供了非重复的更高栅源电压(±40V)并强调了车规级可靠性。 三、电特性参数对比 3.1 导通特性 参数 符号 BVSS123LT1G VB1106K 单位 漏-源击穿电压 V(BR)DSS 100 (最小) 100 (最小) V 栅极阈值电压 VGS(th) 1.6 ~ 2.6 1 ~ 2.5 V 导通电阻 (VGS=10V, ID见备注) RDS(on) 6.0 (最大) 2.8 (典型) Ω 正向跨导 gfs 80 (最小) 100 (典型) mS 分析:VB1106K展现出更优异的导通性能,其典型导通电阻(2.8Ω)显著低于BVSS123LT1G的最大值(6.0Ω),这意味着在相同电流下导通损耗更低。同时,VB1106K的阈值电压范围下限更低(1V),更易于在低电压逻辑下驱动。 3.2 动态特性 参数 符号 BVSS123LT1G VB1106K 单位 输入电容 Ciss 20 (典型) 30 (典型) pF 输出电容 Coss 9.0 (典型) 7 (典型) pF 反向传输电容 Crss 4.0 (典型) 2.0 (典型) pF 总栅极电荷(注) Qg ~1.6 (图示估算) 0.5 (典型) nC 栅-源电荷 Qgs 未提供 未提供 nC 栅-漏(米勒)电荷 Qgd 未提供 未提供 nC 分析:VB1106K具有更低的输出电容(Coss)和反向传输电容(Crss),这有利于降低开关损耗。尤其值得注意的是,其标称总栅极电荷(0.5nC)远低于BVSS123LT1G(根据图表估算约1.6nC),这意味着VB1106K的栅极驱动损耗极低,非常适合高频开关应用。 3.3 开关时间 参数 符号 BVSS123LT1G VB1106K 单位 开通延迟时间 td(on) 20 (典型) 20 (典型) ns 上升时间 tr 未提供 未提供 ns 关断延迟时间 td(off) 40 (典型) 30 (典型) ns 下降时间 tf 未提供 未提供 ns 分析:两款器件的开通延迟时间相当。VB1106K的关断延迟时间(30ns)短于BVSS123LT1G(40ns),结合其极低的栅极电荷,表明其具备更快的综合开关速度。 四、体二极管特性 参数 符号 BVSS123LT1G VB1106K 单位 二极管正向压降 VSD 1.3 (最大) @ 0.34A 1.3 (最大) @ 0.1A V 反向恢复时间 trr 未提供 未提供 ns 反向恢复电荷 Qrr 未提供 未提供 μC 峰值反向恢复电流 IRRM 未提供 未提供 A 分析:两款器件的体二极管最大正向压降标称值相同(1.3V),但测试条件略有不同。文档均未提供详细的反向恢复参数。 五、热特性 参数 符号 BVSS123LT1G VB1106K 单位 结-壳热阻 RθJC 未提供 未提供 °C/W 结-环境热阻 (FR4板) RθJA 556 350 °C/W 分析:VB1106K的结-环境热阻(350°C/W)明显低于BVSS123LT1G(556°C/W),表明其在相同封装和PCB条件下具有更优的散热能力,这与其更高的功率耗散额定值相匹配。 六、总结与选型建议 BVSS123LT1G 优势 VB1106K 优势 ◆ 车规级认证(AEC-Q101),可靠性高 ◆ 明确的ESD防护等级(HBM 0A) ◆ 非重复栅压承受能力更高(±40V) ◆ 导通电阻显著更低(典型2.8Ω),导通损耗小 ◆ 总栅极电荷极低(0.5nC),开关驱动损耗小 ◆ 开关速度更快(td(off)=30ns) ◆ 连续电流和脉冲电流能力更高(0.26A/0.8A) ◆ 功率耗散能力更强(370mW) ◆ 热阻更低(RθJA=350°C/W),散热性能更好 选型建议 选择 BVSS123LT1G:当应用必须满足汽车级或高可靠性认证要求,或对栅极过压应力有更高防护需求的场景。其参数均衡,适用于对成本和可靠性有综合要求的通用开关电路。 选择 VB1106K:当应用追求高效率、低损耗,尤其是工作频率较高的场合。其极低的RDS(on)和Qg能显著降低导通与开关损耗,更高的电流和功率处理能力也使其在性能导向型设计中更具优势,例如高效率DC-DC转换器或负载开关。 备注:本报告基于 BVSS123LT1G(onsemi)和 VB1106K(VBsemi)官方数据手册生成。所有参数值均来源于原厂数据手册,设计选型请以官方最新文档为准。
微碧
微碧半导体 . 2026-07-01 763

德明利亮相COMPUTEX 2026,全栈存储方案适配“AI Togethe”多元场景需求
2026年6月2日,COMPUTEX 2026以“AI Together”为主题在台北正式开幕。本届展会呈现了AI从数据中心走向手机、PC、汽车、机器人和各类 IoT 终端多场景落地的发展趋势。展会期间,德明利携全栈AI存储解决方案亮相展会,系统回应AI多场景应用对存储提出的全新挑战。 一、AI Together、Data Together 从“保存”到“运行”的数据角色转变 过去,GPU、CPU的峰值算力是AI系统的核心;如今,AI Together”意味着AL从单一计算转向云端、边缘与终端设协同运作,行业关注点不再只是“计算速度”,更是聚焦在数据如何被高效存储、快速调用、稳定传输。 当前AI应用不止于“算”,更在于“存”。训练数据、模型参数、多模态、AI Agent日志....大模型产生的海量数据持续推高对存储的要求:更低延迟、更高并发、更长稳定运行,以及功耗与可靠性的平衡。 因此,存储的重要性被重新认识。它不再只是一个“保存数据”的传统硬件,而是成为影响AI系统运行效率的重要基础能力,决定AI“能否跑起来、跑得顺不顺”。 二、 适配多元场景的产品布局:构建协同的AI数据生态 面向数据中心与企业级AI:支撑高并发数据调用与低延时 德明利依托全栈自研技术体系,推出从主控到模组的一体化企业级存储解决方案,通过自研H3361企业级SSD双模主控夯实技术底座,推出覆盖PCIe/SATA SSD及RDIMM内存模组在内的完整企业级存储产品解决方案。 企业级PCIe SSD TE5133系列:搭载PCle 5.0高速接口与NVMe 1.4协议,依托国产化主控与自主固件,集成掉电保护、原子写、多流调度、Trim、安全擦除等全链路企业级特性。 企业级DDR5 RDIMM内存系列:最高6400MT/s速率、依托On-die ECC 和 ECC 颗粒双重保障、信号抗干扰等防护设计,一站式适配AI计算、数据库、云计算、高并发热数据存储全场景。 企业级SATA SSD TS3160系列:容量覆盖240GB–3.84TB,高达540/510MB/s的顺序读写和99K/45K IOPS的随机读写性能,适配服务器系统及数据等多元场景,兼顾平台兼容性与部署效率。 面向智能终端与个人计算:确保流畅的本地体验 随着本地模型加载、端侧推理和高清内容处理需求增加,终端设备需要更快的数据调用和更稳的并发能力。 PCIe 5.0 SSD:顺序读写最高可达14100MB/s、12200MB/s,容量覆盖1TB–8TB,DRAM缓存版与DRAM-less方案分别适配高性能及轻薄低功耗终端,良好的存储能效和散热能力让本地模型与海量内容轻松存储、快速调用。 DDR5 U/SO-DIMM内存模组:支持4800–7200MT/s频率,并搭载PMIC与On-die ECC纠错能力,同时可提供CKD方案,可提升终端多任务并发能力与运行稳定性。 面向嵌入式与边缘设备:兼顾低功耗与高可靠 嵌入式存储方案:全新发布的首款已量产的QLC NAND UFS。凭借QLC的高密度特性,该方案在同等封装尺寸下提供128GB-1TB容量,顺序读性能领先eMMC 3-5倍。同时提供eMMC、UFS 3.1、LPDDR5X等产品线,满足小型封装、宽温运行及长寿命要求,为边缘与移动设备提供低功耗高可靠底座。 面向移动存储与定制化场景:满足多终端数据存储需求 面向移动办公、影像备份及消费电子场景,德明利提供PSSD、mUDP、UDP、PCBA等灵活定制方案。 S+系列高耐久存储卡:S+系列高耐久存储卡则面向安防监控、车载记录仪及运动影像等长期连续录制场景,支持7×24小时稳定运行,并具备宽温运行、智能温控及数据可靠性管理能力,可满足复杂环境下的长期写入需求。 三、从产品竞争到系统能力竞争 全场景AI存储方案要真正支撑AI“用得好”不仅需要产品覆盖,更需要经过真实负载验证并具备稳定交付能力。 形成“规模交付 + 高端验证”的能力协同 德明利以福田基地作为规模化制造与交付中心,以光明基地作为高端制造与验证中心,形成“规模交付 + 高端验证”的能力协同,支撑企业级SSD、RDIMM及嵌入式产品的测试与量产。 AI重新定义存储,存储也正在重新进入AI系统核心。德明利从底层技术出发,从研发设计、测试验证,到智能制造与产品交付以全场景系统级存储能力,支撑AI从“算得动”走向“用得好”。
TWSC . 2026-07-01 1309

东芝推出采用最新一代工艺的80V N沟道功率MOSFET,助力提升AI数据中心的效率
中国上海,2026年6月30日——东芝电子元件及存储装置株式会社(“东芝”)今日宣布,推出采用东芝最新一代工艺U-MOS11-H[1]制造的80V N沟道功率MOSFET——TPM1R408RH。该MOSFET面向AI数据中心和通信基站等工业设备的开关电源。新产品即日起开始出货。 随着AI处理需求持续扩大,数据中心的功耗需求不断增加;同时,通信基础设施的发展也进一步提高了开关电源在高效率、小型化(高功率密度)和低电磁干扰(EMI)方面的要求。由于功率损耗会直接影响系统功耗、发热量和冷却负荷,因此有必要采用具备相应特性的功率半导体,以能平衡降低导通损耗和开关损耗,并有助于实现包括EMI抑制、热设计和安装便利性在内的系统整体优化。 TPM1R408RH采用优化的器件结构,实现了1.4mΩ(最大值)[2]的漏源导通电阻,与采用上一代U-MOS X-H工艺制造的东芝80V产品“TPM1R908QM”相比降低约26%。此外,该产品还改善漏源导通电阻(RDS(ON))与总栅极电荷(Qg)之间的平衡,相较于TPM1R908QM,品质因数RDS(ON)×Qg约降低45%。这些特性达到了业界领先[3]水平的低功耗损耗表现。 TPM1R408RH还可抑制开关过程中在漏极与源极之间产生的尖峰电压,有助于降低开关电源中的EMI。EMI抑制通常需要在设计后期进行返工,而抑制器件本身产生的尖峰电压有助于减少返工,并简化滤波器和缓冲电路。 新产品采用SOP Advance (E) 封装,与东芝现有的SOP Advance (N) 封装相比,封装电阻约降低65%,热阻约降低15%。通过抑制发热并改善散热性能,该封装支持更高输出功率和更紧凑的电源设计。 东芝还提供支持开关电源电路设计的工具。除可在短时间内验证电路功能的G0 SPICE模型外,现在还提供能够准确再现瞬态特性的高精度G2 SPICE模型。东芝网站上的在线电路仿真器可让用户在网页浏览器中轻松验证电路运行情况,无需搭建仿真环境或下载器件模型。(在线电路仿真器:此处) 东芝将继续扩充有助于提升电源效率的功率MOSFET产品线,从而帮助降低工业设备的功耗。 Ø 应用: 工业设备 - 用于AI数据中心和通信基站的开关电源 Ø 特性: - 低漏源导通电阻:RDS(ON)=1.4mΩ(最大值)(VGS=10V,ID=50A,Ta=25°C) - 低漏源导通电阻×总栅极电荷:RDS(ON)×Qg=1.4mΩ×80nC=112mΩ・nC(约比TPM1R908QM的1.9mΩ×108nC=205.2mΩ・nC低45%) - 采用低封装电阻和低热阻的SOP Advance (E) 封装 Ø 主要规格: (除非另有说明,Ta=25°C) 器件型号 TPM1R408RH 绝对最大额定值 漏极-源极电压VDSS(V) 80 漏极电流(DC)ID(A) Tc=25°C 288 结温Tch(°C) 175 电气特性 漏源导通电阻 RDS(ON)(mΩ) VGS=10V Max 1.4 VGS=8V Max 1.7 总栅极电荷 Qg(nC) VGS=10V 典型值 80 栅极开关电荷 Qsw(nC) 典型值 23 输出电荷Qoss(nC) 典型值 161 反向恢复时间trr(ns) 典型值 74 反向恢复电荷Qrr(nC) 典型值 115 封装 名称 SOP Advance (E) 尺寸(mm) 典型值 4.9×6.1×1.0 库存查询与购买 在线购买 注: [1] 截至2026年6月,基于东芝低压功率MOSFET工艺。 [2] VGS=10V,ID=50A,Ta=25°C [3] 截至2026年6月的东芝调研。 如需了解有关新产品的更多信息,请访问以下网址: TPM1R408RH https://toshiba-semicon-storage.com/cn/semiconductor/product/mosfets/12v-300v-mosfets/detail.TPM1R408RH.html 如需了解有关东芝MOSFET的更多信息,请访问以下网址: MOSFET https://toshiba-semicon-storage.com/cn/semiconductor/product/mosfets.html 如需了解有关新产品在线分销商网站的更多信息,请访问以下网址: TPM1R408RH https://toshiba-semicon-storage.com/cn/semiconductor/where-to-buy/stockcheck.TPM1R408RH.html *本文提及的公司名称、产品名称和服务名称可能是其各自公司的商标。 *本文档中的产品价格和规格、服务内容和联系方式等信息,在公告之日仍为最新信息,但如有变更,恕不另行通知。 关于东芝电子元件及存储装置株式会社 东芝电子元件及存储装置株式会社是先进的半导体和存储解决方案的领先供应商,公司累积了半个多世纪的经验和创新,为客户和合作伙伴提供分立半导体、系统LSI和HDD领域的杰出解决方案。 公司17,400名员工遍布世界各地,致力于实现产品价值的最大化,东芝电子元件及存储装置株式会社十分注重与客户的密切协作,旨在促进价值共创,共同开拓新市场,期待为世界各地的人们建设更美好的未来并做出贡献。 如需了解有关东芝电子元件及存储装置株式会社的更多信息,请访问以下网址:https://toshiba–semicon–storage.com
东芝 . 2026-07-01 819

展会 | 2026上海国际CPO光电共封装产业展览会暨发展会议邀请函
尊敬的各企事业单位、行业专家、产业同仁: 当前,AI算力高速迭代驱动全球光互联技术变革,CPO光电共封装技术作为突破高端光模块带宽、功耗、体积瓶颈的核心方案,已成为数据中心、超算算力、6G通信、智能终端产业升级的核心赛道,全球产业化落地进入关键爆发期。上海作为全球科创中心、国际数字之都、长三角光电半导体产业核心枢纽,集聚全国顶尖的芯片设计、先进封装、高端设备、国际商贸、跨境投融资资源,汇聚大量外资总部、上市龙头、专精特新科创企业与高端科研平台,是国内CPO技术国产化攻坚、国际化交流、高端商贸对接、产业链协同创新的核心承载高地。为抢抓全球CPO产业变革机遇,打通国际国内双循环产业链,推动CPO前沿技术量产落地、标准共建、供需互通、国际合作,赋能全国AI算力与高速光互联产业高质量发展,特重磅举办2026上海国际CPO光电共封装产业展览会暨发展会议。 本次活动是国内极具国际化、专业化、商业化的CPO垂直产业盛会,立足上海、联动长三角、辐射全球,打造「国际展览+顶尖峰会+技术迭代+全球对接+新品首发+标准共建+投融资落地」七位一体的高端产业平台,填补国内高端国际化CPO专业展会空白,现诚挚邀请全球产业同仁莅临参展、参会、洽谈合作、共拓万亿算力新蓝海! 一、基本信息 活动名称:2026上海国际CPO光电共封装产业展览会暨发展会议 组织单位:上海市信息通讯行业协会 中国信息通讯研究院 上海市人工智能行业协会 上海市人工智能技术协会 承办单位:旻生展览会议(深圳)有限公司 展会时间:2026年9月10日-12日 展会地点:上海·跨国采购会展中心 大会官网:www.nnfts.cn 展会定位:国际化、高端化、商业化、专业化,聚焦CPO量产落地、国产替代、国际合作、算力赋能,打造全球CPO产业年度标杆盛会,本次展览聚焦 CPO 光电共封装前沿技术与产业生态,汇聚产业链各环节头部企业,阵容重磅、含金量高。届时将邀请工业富联、中际旭创、新易盛、立讯精密、东山精密、胜宏科技、长飞光纤、天孚通信、生益科技、亨通光电、鹏鼎控股、三环集团、光迅科技、中天科技、协创数据、华工科技、德明利、源杰科技、联讯仪器、领益智造等二十家行业龙头企业集中亮相。企业覆盖从上游光芯片、光源、高速 PCB 与封装基材,到中游高速光模块、CPO 光引擎、硅光集成,再到下游精密结构件、系统级封装与测试设备等全产业链关键环节,代表了当前 CPO 领域的顶尖技术水平与产业实力。本次盛会将为行业搭建技术交流、产品展示与商务合作的高端平台,共探高速光互联技术创新与产业发展新机遇。 二、核心活动板块 本次大会打破传统单一展会模式,融合展览、会议、技术攻坚、全球供需、新品首发、行业标准、资本赋能全链条活动,精准匹配企业品牌展示、技术交流、订单洽谈、资源对接、项目落地、国际合作多元需求。 板块一:CPO全产业链品牌展 展会规划高端国际化展区,汇聚全球数百家顶尖产业链企业、国内外上市龙头、海外知名厂商、长三角专精特新企业集中亮相,覆盖CPO全产业链上中下游,聚焦量产技术、前沿产品、核心设备与高端解决方案,打造国内规模最大、品类最全、规格最高的CPO垂直专业展。 六大核心展区设置: CPO整机与光引擎展区:国内外头部CPO光引擎、1.6T/3.2T高速共封装光模块、AI算力集群光互联系统、超高速光电集成解决方案、下一代算力网络核心设备 高端光芯片与硅光集成展区:高速DFB/EML激光芯片、硅光PIC芯片、AWG无源芯片、高速调制器、光电探测器、芯片设计IP、晶圆代工、芯片测试解决方案 精密光学器件与核心配套展区:高精度光纤阵列、微透镜阵列、高速光纤、精密耦合器件、高速连接器、隔离器、滤波器件、光电封装专用辅料 先进光电封装与制程展区:光电共封装工艺、COB/FOFC/CPO异构集成技术、高端载板、高速基板、封装热管理、精密封装设备、微纳加工技术 测试设备与智能制造展区:CPO专用全自动测试设备、光学检测系统、高速光电性能测试仪、自动化耦合封装设备、量产智能制造产线、质量检测解决方案 长三角产业集群与科创成果展区:上海、江苏、浙江、安徽光电半导体龙头企业、科研院所前沿成果、科创企业新品、产业园区招商成果、国产替代攻坚成果 板块二:CPO产业发展主旨会议 作为本次大会核心会议,打造产业链顶级产业峰会,汇聚国内外院士、行业主管领导、CPO龙头企业CEO、技术总工、算力平台负责人、海外行业专家、头部机构投资人,聚焦全球产业顶层趋势。 核心演讲议题:全球CPO产业发展格局与未来五年趋势、光电产业政策与国产替代战略、AI超算中心高速光互联建设规划、1.6T/3.2T CPO量产技术突破、国际CPO技术标准共建、长三角CPO产业集群协同发展、海外市场布局与跨境合作机遇。 板块三:八大垂直细分技术会议 紧扣产业量产痛点、技术难点、市场热点,开设多场平行高端分论坛,聚焦细分赛道深度研讨,助力企业攻克技术瓶颈、对接精准资源、把握行业风口: 《全球1.6T/3.2T CPO规模化量产技术与良率提升会议》 《硅光芯片国产化设计、制造、封装全链路创新会议》 《AI大算力中心、智算集群CPO规模化落地应用会议》 《CPO光电共封装可靠性、行业标准与质量体系会议》 《高速光电材料、高端载板与核心配套国产化攻坚会议》 《海外CPO市场准入、国际贸易与跨境合作对接会议》 《长三角光电半导体产业链协同与国产替代发展会议》 《下一代4T超高速光互联技术前瞻创新会议》 板块四:CPO新品首发暨前沿技术成果发布会 搭建年度行业新品首发官方平台,邀请国内外头部企业、高校科研院所、重点实验室,集中发布年度CPO全新量产产品、前沿技术成果、专利技术、创新解决方案、中试落地项目。同步举办技术路演、成果签约仪式,打通「科研攻关—中试测试—量产落地—市场应用」全链条转化通道,打造全国CPO产业技术风向标。 板块五:海内外精准供需闭门对接会(商贸落地) 依托上海国际化商贸优势,定向邀约云厂商、超算中心、三大运营商、海内外光模块龙头、封装代工巨头、设备材料采购方、跨境贸易商参与闭门精准对接。采用「企业专场路演+一对一私密洽谈+集中签约」模式,聚焦供应链集采、产能合作、技术代工、跨境贸易、项目共建,高效促成年度订单签约与深度战略合作。 板块六:2026国际CPO产业年度盛典暨标杆颁奖 举办行业权威年度盛典,立足行业视野评选产业标杆,树立行业典范,助力企业品牌升级、提升行业话语权与国际影响力。 权威奖项设置:CPO产业年度领军企业、国际技术创新标杆企业、国产替代优质供应链企业、年度新锐科创企业、最佳量产解决方案奖、优秀科研创新成果奖、行业杰出贡献人物奖。 板块七:长三角科创投融资&高端人才对接专场 汇聚国家级产业基金、长三角政府引导基金、海内外头部创投机构、产业资本,开展CPO优质项目投融资路演,助力优质科创项目融资落地、企业产能扩张。同时联动上海高校、科研院所、人社部门,搭建高端技术人才、管理人才引育对接平台,补齐产业人才短板,完善长三角CPO产业创新生态。 三、参展参会核心价值 1、立足国际高地,抢占全球行业话语权:上海国际化科创枢纽定位,汇聚全球行业资源、海外客商与国际专家,是企业展示品牌、出海布局、参与国际标准共建的核心平台。 2、全链高端汇聚,精准对接全球商机:覆盖全球上中下游优质企业、采购方、资本方、科研机构,打通国内国际双循环商贸渠道,高效拓展海内外市场。 3、把握量产窗口期,锁定年度核心订单:产业关键节点,恰逢企业年度技术迭代、产能规划、供应链招标窗口期,是洽谈合作、锁定全年订单、布局明年产能的黄金契机。 4、借力长三角势能,赋能企业长效发展:依托长三角产业集群优势,对接顶级科研资源、产业政策、园区载体、投融资资源,助力企业技术升级、产能落地、规模化发展。 四、邀约对象 本次盛会诚挚邀约各地从事光电信息、半导体芯片、高速光通信、硅光光子集成、光电共封装(CPO)、先进封装制程、AI 人工智能算力、大型数据中心、超算中心集群、电子高端材料、精密智能装备、光电测试仪器等领域的龙头企业、专精特新企业及上下游配套企业;同时邀请国内外知名高校、光电类科研院所、重点实验室、全国及地方行业协会、产业联盟;面向海内外产业投融资机构、科创产业园区、跨境商贸企业、系统集成商、工程总包商、渠道经销商,以及行业主流媒体、专业自媒体、产业研究机构等 CPO 及光电子全产业链各界同仁莅临参会、参展交流、共话合作。 诚邀全球产业同仁相聚上海,共探CPO千亿新赛道、共筑高速光互联新生态! 联系我们: 蔡森 先生 电话:+86-21-54375929 手机(微信):18701903309 电邮:sen.cai@minshengexpo.com Q Q: 2667958770 大会官网:www.nnfts.cn
展会
芯查查资讯 . 2026-06-30 1 2177

企业 | 百度昆仑芯,拟赴港IPO
百度集团今日股价走强,涨近7%。据了解,百度旗下昆仑芯计划赴港上市,目标估值约500亿美元。 知情人士透露,腾讯已成为昆仑芯客户,字节跳动亦在考虑采用其AI芯片。目前,昆仑芯P800已完成规模化验证,2025年至今已交付多个万卡集群,并在全国产集群上完成文心5.1重要版本训练。
昆仑芯
科创板日报 . 2026-06-30 875

产品 | 面向工业设备的高精度6DoF惯性传感器
随着工业设备的自动化与高性能化不断推进,对机器人、无人机、相机等的高性能需求也持续增长。尤其是在需要精细运动控制的场景中,对自定位与姿态的高精度计算,以及在图像与视频质量改良中不可或缺的抖动降低,均离不开能够同时测量三轴加速度与三轴角速度的六自由度(6DoF)惯性传感器。 株式会社村田制作所将为面向工业设备的高精度6DoF惯性传感器“SCH16T”系列新增“SCH16T-K20”。本产品可在宽温范围内的长期使用场景中,为自定位与姿态控制的稳定性提供支持。 6DoF惯性传感器的使用环境正从以往的限定场所扩展至室内外的多种场景。然而,当在宽范围温度变化及严格振动、冲击条件下传感器输出(偏移)的变化量(漂移)增大时,长时间测量会导致输出误差累积,进而向终端产品输出不准确的数据。并且,为了在故障发生前就进行防范,市场对传感器具备能够自判定错误的自诊断功能的需求也在增加。 因此,市场需要一种能够在低温到高温的宽温条件以及强振动、强冲击下仍然能稳定运行、并具备错误状态自诊断功能的6DoF惯性传感器。 对此,村田通过专有的3D MEMS技术与封装技术,开发出了本产品:可在−40~+110 °C的温度范围内稳定运行,具备较小的振动整流误差(VRE)与低噪声特性,实现高精度测量。这将有助于机器人、无人机、相机等应用中的高精度自定位与姿态估计,以及稳定控制。 主要特点 −40~+110 °C宽工作温度范围: 在−40~+85 °C范围内实现优良的偏移特性。 低噪声、低漂移的陀螺仪: 达业内较高水平。典型值:噪声密度 0.0004 (°/s)/√Hz,零偏不稳定性 0.3 °/h。 通过3D MEMS与双差分结构及封装技术实现低VRE(振动整流误差)。 配备自诊断功能,并在SCH16T系列内具备引脚/软件兼容性。 新品SCH16T-K20显著提高了陀螺仪和加速度计的性能,与本系列早期的产品K01和K10型号相比,SCH16T-K20中的新型加速度计MEMS降低了温度偏置漂移并将噪声密度降低了一半。 此外,尽管本产品系列面向工业设备,仍依据车规级质量标准(AEC-Q100)开展了相关测试(注:本产品不适用于车载用途)。并且,本产品配备与SCH16T系列通用的自诊断功能,可支持信号可靠性监测与故障检测。同时,凭借在SCH16T系列内的引脚与软件兼容性,便于进行产品替换,有助于减少设计工时。 主要参数 产品 SCH16T-K20 尺寸(长×宽×高) 11.8×13.4×2.9mm (0.46×0.53×0.11英寸) 工作温度范围 −40~+110 °C 陀螺仪零偏不稳定性(典型值) 0.3 °/h 陀螺仪噪声密度(典型值) 0.0004(dps)/√Hz 加速度计噪声密度(典型值) 33 µg/√Hz SCHA16T系列可应用于在严苛环境条件下追求高性能表现的应用领域。代表性应用领域包括 : 高精度惯性测量单元(IMU) 惯性导航与定位 无人机飞行控制器 动态倾角测量 高精度机器人控制和UAV 人形机器人控制 相机稳定 村田预计于2026年上半年开始量产SCH16T-K20,并计划在2026年年初提供样品。 今后,村田将持续推进高精度6DoF惯性传感器的研发,为工业领域的高功能化作出贡献。
新品
Murata村田中国 . 2026-06-30 1330

产品 | Melexis推出数字电流传感器,有效解决高功率电动汽车信号完整性难题
Melexis宣布推出MLX91229,这是一款采用Σ-Δ(sigma-delta)数字输出的霍尔效应电流传感器,旨在提升强电磁噪声环境下的信号完整性。该全新集成电路(IC)支持200A至2000A的电流测量范围,针对牵引逆变器及其他汽车系统进行了深度优化,有效解决局部功率电子器件通常会干扰标准传感器传输的难题。 随着电动汽车动力总成不断向更高电压发展,并采用碳化硅(SiC)和氮化镓(GaN)等开关速度更快的技术,这使得车辆内部的电磁环境正面临前所未有的严峻挑战。在传感器与微控制器(MCU)之间的信号路径上,这些苛刻的条件极易引入干扰,特别是在需要较长PCB走线或复杂布线的系统中尤为明显。虽然模拟电流测量技术目前仍被广泛应用且行之有效,但在这些充满挑战的环境中要确保信号完整性,往往需要精心的设计以及多次开发迭代。 提升高功率汽车系统的信号完整性 MLX91229通过将信号传输从模拟域转移到数字域,成功化解了这些棘手问题。在传统的模拟实现方案中,测得的电流大小由微小的电压变化来表示,这意味着信号路径中耦合的任何干扰都会直接转化为测量误差。相比之下,MLX91229将测得的电流编码为Σ-Δ位流,其信息通过数字脉冲的密度而非绝对电压水平来承载。这种机制建立了一种固有的噪声容限,使信号在传输过程中能够有效抵御干扰,而不会对MCU端重建的测量结果产生显著影响。 通过维持传感元件与接收MCU之间的信号完整性,该器件有助于大幅降低沿信号路径引入的噪声影响。这在牵引逆变器系统中尤为适用,因为高电流和高频开关事件会产生显著的电磁干扰(EMI),并对PCB设计和信号布线带来巨大的压力。 此外,由于MLX91229拥有与现有模拟霍尔效应解决方案高度兼容的封装尺寸(footprint),工程师无需对系统布局进行重大更改,即可轻松评估数字输出传感技术。同时,Σ-Δ输出在系统级提供了极高的灵活性,使工程师能够根据应用需求,自由选择在带宽、噪声和响应时间之间取得最佳平衡的解调策略。 Melexis产品线总监Bruno Boury表示: 随着功率电子环境的要求日益严苛,确保信号完整性正变得愈发关键。通过推出MLX91229,我们正在积极推动真实汽车系统向数字电流传感技术的迈进,在充满电气挑战的环境中提供更出色的强健性能。 面向汽车和移动出行应用的MLX91229,基于在严苛工作环境中得到长期验证的成熟技术打造。通过在其电流传感器产品组合中引入数字输出,迈来芯旨在为迎战不断演进的系统需求的工程师们提供强有力的支持。
新品
迈来芯Melexis . 2026-06-30 1141

产品 | 一颗芯片搞定USB PD EPR/无线充电/工业高压DC供电全场景,65V宽输入+9A峰值输出效率拉满!
关键词:高效同步降压转换器、USB PD EPR、无线充电、65V宽输入、9A峰值电流、高功率 近日,MPS宣布推出高效同步降压转换器——MP8887。该产品支持4.5V至65V宽输入电压范围、最高9A峰值输出电流,并集成I2C数字接口、可编程频率以及可调过流保护,适用于无线充电、USB PD3.2 EPR(Extended Power Range)以及高功率直流供电等应用场景,为新一代高压大功率系统提供兼具效率、灵活性与可靠性的电源解决方案。 为什么需要这款高效同步降压转换器? 近年来,USB PD EPR、高功率无线充电以及高压DC供电系统快速发展,终端设备对于电源芯片的要求正在不断提升。尤其是在高功率密度应用中,系统不仅需要更高输入耐压与更强输出能力,同时还需要在有限空间内实现更精准的功率管理、更低发热以及更灵活的动态调节能力。在这一趋势下,MP8887通过高电流能力、高集成度以及数字化控制特性,为高压大功率电源设计提供了更高效的实现方式。 MP8887 典型应用原理图 四大核心优势,一看就懂 高电流能力满足高功率应用需求 随着USB PD3.2 EPR规范将供电能力提升至240W,以及无线充电系统持续向更高功率升级,电源系统对于大电流输出能力的需求显著提升。作为一款为大功率场景打造的65V/9A高效同步降压转换器,MP8887内置两颗功率MOSFET,支持最大四相并联应用,单颗峰值9A输出电流,并支持1V至51V宽输出电压范围,可覆盖无线充电发射端、USB PD EPR电源、高功率DC模块以及工业设备等多种应用需求。 MP8887四相并联应用原理图 同时,产品支持4.5V至65V宽输入电压范围,最大绝对耐压达到70V,可直接适配24V、36V、48V等商用车,消费电子和工业应用场景,减少额外前级转换电路需求,帮助系统降低复杂度与整体BOM成本。对于高功率供电平台而言,更高输入耐压与更强输出能力不仅能够提升系统兼容性,也有助于为未来更高功率设计预留充足余量。 灵活可编程配置,适配多样化应用平台 随着终端设备功能持续复杂化,系统对于电源动态调节能力的需求也在不断提升。传统固定参数电源方案在面对多协议、多工作模式应用时,往往缺乏足够灵活性。为满足不同系统平台对电源管理的差异化需求,MP8887支持I2C接口,可对输出电压、输出电流限制及保护参数进行灵活配置。相比传统固定参数方案,该设计能够显著提升系统适配能力。例如,在USB PD3.2 EPR应用中,可根据不同功率档位动态调整输出;在无线充电系统中,则能够针对不同负载状态优化供电性能。 此外,MP8887支持200kHz至600kHz可配置开关频率支持外部时钟同步功能,并具备频谱扩展功能FSS(Frequency Spread Spectrum),可帮助系统进一步优化EMI表现与整体效率。同时,产品支持100% Duty导通,可在输入输出压差较小时维持稳定输出,进一步提升应用适配性。 高集成与紧凑封装兼顾性能与空间需求 除了更高性能外,小型化同样是当前高功率设备的重要发展趋势。对于无线充电设备、扩展坞、电源模块以及工业便携设备而言,有限PCB空间往往要求电源方案在更小尺寸内实现更高功率输出。MP8887采用4mm × 5mm紧凑QFN封装,在提供高压、大电流输出能力的同时,有效节省PCB面积,帮助客户实现更高功率密度设计。 MP8887 封装参考图 高效率设计,满足高功率系统需求 在高功率应用中,效率与热性能直接影响产品可靠性与整体设计难度。尤其是在无线充电、快充适配器以及紧凑型工业设备中,有限空间往往难以容纳复杂散热结构,因此电源系统需要尽可能降低功耗与发热。MP8887采用高效同步降压架构,在36V输入、5A负载条件下,效率最高可达97.67%,有效降低功率损耗与热耗散。 MP8887 效率负载曲线图 与此同时,MP8887单颗convertor实现USB-PD3.2 EPR全功率范围,还具有优异的热性能,有助于降低系统散热压力并提升长期运行稳定性。在36V/5A输出条件下,Tcase仅为94.2℃;在频率200kHz的运行条件下,Tcase温度可降至80°C。这一特性不仅能够帮助系统减少散热器件设计,还能够进一步提升整体功率密度,更适合高性能、小型化终端设备。 MP8887 热性能测试图 此外,针对高压、高功率应用环境,MP8887还集成了过压保护(OVP)、过流保护(OCP)以及过温保护(OTP)等多重保护机制,可有效应对复杂工作环境中的异常情况,提升系统长期运行可靠性。 产品特性一览 4.5V至65V宽输入电压 (VIN) 范围,70V最大绝对电压 1V至65V宽输出电压 (VOUT) 范围 0V至2.047V反馈 (FB) 参考电压范围,0.5mV步长 高达9A的峰值输出电流 (IOUT) 36V/5A负载条件下效率高达97.67% I2C操作关闭状态下,具有低至180µA的静态电流 (IQ) 可配置峰/谷值电流限 ±5%输出恒流 (CC) 电流限精度 自动高级异步调制 (AAM)/脉宽调制 (PWM) 模式,以及带频谱扩展(FSS)的FPWM 模式 200kHz至600kHz可配置的开关频率 (fSW),支持外部时钟同步 支持VCC偏置供电功能以提高效率 可配置线路压降补偿 可配置输出放电电流 过压保护 (OVP)、过流保护 (OCP)、过温保护 (OTP) 和中断 电源正常 (PG) 指示 采用侧面镀锡的QFN-24 (4mmx5mm) 封装 样品申请 MP8887现已开放限时福利——免费样品申请(1分购),每人限领2颗,仅限工程师参与,审核通过后发货。
新品
MPS芯源系统 . 2026-06-30 1057

涨价 | 铝电容大厂,集体涨价
最新消息显示,日本第三大铝电容厂Rubycon向客户发出调价通知,宣布自2026年8月1日起上调产品售价。更值得关注的是,Rubycon在通知中特别提到,鉴于国际局势和成本变化存在较大不确定性,后续不排除再次调价的可能。 而在这之前,国内铝电容龙头江海股份也启动了产品价格调整。 至此,日本前三大铝电容厂商与中国龙头企业相继加入提价阵营,一场由成本上涨和AI需求共同推动的铝电容涨价潮,正在席卷整个产业链。 日系三巨头全部提价,行业释放强烈信号 在被动元件领域,MLCC和芯片电阻的涨价并不罕见,但铝电容集体涨价却并不多见。 随着Rubycon宣布涨价,日本三大铝电容制造商——佳美工、尼吉康和Rubycon已经全部进入调价状态。三家头部企业在全球高端铝电容市场占据重要份额,其产品广泛应用于工业电源、通信设备、服务器、新能源以及汽车电子等领域。 过去几年,即便部分原材料出现波动,铝电容行业整体仍保持相对克制,价格变化远不及MLCC市场剧烈。因此,此次日系三巨头几乎同步调价,被业内视为一个十分罕见的现象。 而龙头企业集体行动,往往意味着行业已经发生深层变化。 铝、铜、锡齐涨,企业已难以自行消化成本 从Rubycon公布的信息来看,本轮涨价的直接原因是生产成本全面攀升。 首先是能源价格持续高位运行。尽管中东局势出现缓和迹象,但国际原油价格依然维持高位,石油化工相关材料成本并未出现明显回落。与此同时,运输、包装以及辅助材料费用也在不断增加。 其次是金属原材料价格持续上涨。 铝电容的制造离不开铝、铜、锡等基础金属。其中,铝用于电极材料和外壳制造,铜用于导针和连接部件,锡则大量应用于焊接工艺。这些关键材料自去年以来持续上涨,并且仍处于历史较高水平。 对于制造企业而言,单纯依靠内部降本增效已经难以抵消成本压力。 Rubycon坦言,目前成本上涨幅度已经超出企业可承受范围,调整产品价格成为保障稳定供货和维持长期经营能力的必要选择。 此次调价范围涵盖:铝电解电容;固态铝电容;薄膜电容。新价格将于2026年8月1日起正式执行。 事实上,成本压力并非日本企业独有。 6月下旬,国内铝电容龙头江海股份同样向客户发布调价通知。公司表示,近年来铝箔、化工原料、碳粉以及能源成本持续上涨,现有成本结构已经远远超出此前的价格测算体系。 基于经营压力,公司决定对部分产品进行价格调整。此次调价产品包括:铝电解电容;薄膜电容;超级电容。 作为国内铝电容行业的重要风向标,江海股份的动作进一步说明,涨价已经不再是个别企业的应急措施,而正在演变为整个行业的共同选择。
涨价
九如芯闻 . 2026-06-30 2604

产品 | 智能自举充电控制赋能高可靠性GaN驱动,纳芯微推出110V半桥驱动芯片NSD2123
随着AI算力需求爆发,GaN器件在AI数据中心电源的渗透率正加速提升,以突破功率密度瓶颈;与此同时,机器人关节驱动、光储、Class D音频等领域也对高效紧凑的电源方案提出需求,共同推动GaN技术从消费快充迈向泛工业市场。GaN器件凭借低损耗、高开关频率等优势,已成为新一代电源设计的核心选择,而其价值释放离不开专用驱动芯片的精准适配。 在此背景下,纳芯微全新推出110V半桥GaN驱动芯片NSD2123,具备智能自举充电控制、桥臂中点耐负压和抗干扰能力强、内置有源米勒钳位等特点,广泛适用于电源模块、同步整流、机器人、光储、音频功放等领域,以及Buck、Boost、LLC、HSC等各类硬开关或软开关拓扑。 产品特性 专为增强型E mode GaN HEMT驱动优化 采用自举开关代替自举二极管,消除自举电容压降 自举开关采用智能充电控制,避免GaN第三象限导通时自举电容被过充 HS耐压范围:-10V~110V HS dv/dt抑制能力100V/ns 推荐供电范围4.5V~5.5V HI/LI输入支持TTL逻辑电平 3A/5A峰值驱动电流,并且内置有源米勒钳位 灌电流/拉电流输出引脚分开,可独立调节开通、关断速度 典型值10ns最小输入脉宽 典型值17ns输入输出传输延时 典型值1ns HO/LO传输延时失配 典型值6ns上升时间(1nF 负载) 典型值4ns下降时间(1nF 负载) 封装:2mm*2mm WLCSP、2mm*2mm LGA 工作结温范围:-40℃~150℃ NSD2123功能框图 智能充电控制,消除自举过压风险 GaN器件没有传统硅MOSFET的体二极管,而是依靠第三象限导通实现续流。在半桥拓扑中,死区时间内下管续流会使HS节点出现负压,传统自举供电方式可能导致自举电容过充,增加高边GaN栅极过压风险,影响系统长期运行可靠性。 GaN/Si MOSFET/IGBT 导通和续流特性对比 针对这一挑战,NSD2123采用智能自举充电控制,仅在低边GaN导通期间开启自举充电路径,在死区时间自动停止充电,从而有效避免自举电容过充,降低高边GaN栅极过压风险,为GaN应用提供更加可靠的驱动方案。 同时,NSD2123采用MOSFET替代传统自举二极管作为充电通路,大幅降低自举充电路径压降,使高边GaN能够获得接近VDD的驱动电压,在保证可靠驱动的同时进一步降低导通损耗,充分释放GaN器件的高效率优势。 兼顾耐负压与抗干扰能力,契合高频、高速应用 由于GaN器件的高速开关特性,在各类应用中容易引起桥臂中点的负压振荡现象,特别是在电机短路等大电流关断的应用场景下,桥臂中点的负压震荡最低可达-10V左右,如果GaN半桥驱动芯片设计不当,可能导致闩锁或误触发,影响系统稳定运行。 桥臂中点产生负压震荡的机理 针对这一挑战,NSD2123通过专门强化的电路工艺,可以实现瞬态-10V的桥臂中点耐负压能力,从而避免发生闩锁问题。此外,通过对内部level shifter电路的特殊设计,可以实现100V/ns的dv/dt抑制能力,充分释放GaN高频、高速开关性能。 驱动输出独立调节,内置有源米勒钳位,降低误导通风险 GaN器件对栅极驱动电压和开关速度更加敏感,传统驱动方案通常需要借助外部二极管实现开通、关断速度的独立调节,但二极管压降会降低GaN栅极驱动电压影响导通损耗,或增加关断状态下的误导通风险。 GaN采用Split Output驱动芯片方案 NSD2123采用Split Output驱动架构,无需额外串联二极管,即可分别调节GaN器件的开通和关断速度。此外,NSD2123提供3A拉电流、5A灌电流峰值驱动能力,即使在多颗GaN并联应用中也能实现快速稳定驱动;内置有源米勒钳位,进一步增强关断期间的栅极下拉能力,有效降低误导通风险,提升系统可靠性。 封装与选型 纳芯微110V半桥GaN驱动芯片NSD2123提供WLCSP及LGA两种2mm*2mm小尺寸封装,进一步咨询NSD2123产品及申请样片,可邮件sales@novosns.com。
纳芯微
纳芯微电子 . 2026-06-30 1 938

市场 | 消费级DRAM与NAND价格全面走高,LPDDR4X 4GB价格较第一季度上涨75%
市场研究机构群智咨询(Sigmaintell)最新报告指出,今年第二季度消费级DRAM与NAND价格全面走高,其中LPDDR4X4GB价格较第一季度上涨75%,LPDDR5X12GB价格则大涨89%。群智咨询表示,随着LPDDR内存导入英伟达下一代AI运算平台VeraRubin等服务器GPU,供应竞争进一步加剧。 NAND市场第二季同样维持上涨趋势,其中SSD价格较第一季上涨约50%。企业级SSD(eSSD)需求不受现货价格波动影响,AI丛集与AI代理(Agent)服务器持续扩充储存容量,成为需求成长的主要动能。 群智咨询指出,第二季HBM、服务器DRAM、企业级SSD(eSSD)等高附加价值产品优先取得产能,使消费性内存供应不足。受到成本上升影响,部分智能手机与PC品牌厂已开始调整内存采购订单。 随着eSSD需求扩大及供给紧张,缺货情况已逐渐蔓延至移动设备和PC用NAND市场。低容量嵌入式多媒体卡(eMMC)等低端NAND供应持续缩减,进一步加剧消费性NAND市场供应紧张局面。 投行杰富瑞(Jefferies)最新研报指出,2026年第三季度存储均价环比涨幅或冲高至40%~50%,第四季度预计再环比上涨30%~40%;2027年存储芯片全年均价预计将较2026年整体抬升40%~45%。 近日,美光(Micron)发表财报后直言,DRAM供应紧张的局势将一路延续到2027年以后,2028年才有机会改善。美光财报发布后不久,苹果(Apple)调整了官网Mac系列电脑的价格。 市场普遍认为,连苹果都难以承担本轮成本上涨压力,后续消费电子产品涨价潮大概率将进一步升级。存储芯片持续涨价、供给紧缺,将对整体消费电子销量形成明显负面影响。 业内人士表示,存储芯片供不应求的影响主要分为两个层面。一是存储芯片价格大幅上涨,挤压了周边芯片的规格升级与调价空间;二是存储芯片供给不足,直接导致终端客户下调其他芯片的整体采购量。 从当前市场情况来看,供给短缺带来的第二层影响,整体比单纯涨价的影响更为严重。与此同时,终端产品涨价会压制消费者购买意愿,即便存储芯片货源充足,整体芯片采购需求也会出现下滑。 IC设计行业普遍认为,目前最棘手的问题是存储芯片供需失衡、价格暴涨带来的市场不确定性。上游无法预判下游真实需求,下游厂商难以评估终端市场对涨价的接受程度,有限的存储芯片产能如何分配至各产品线难以预判,行业订单能见度持续降低。 苹果CEO表示,本轮成本大幅跳升,是其四十余年从业经历中前所未见的情况。特斯拉CEO同样形容此次存储价格暴涨为前所未有。马斯克称,“相对于需求而言,产能缺口简直离谱,亟需大幅提高产量。”
存储
芯极速 . 2026-06-30 1078
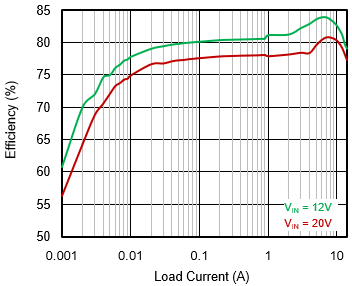
产品 | AI算力爆发,供电不拖后腿——圣邦微电子推出14A(33A峰值)同步降压转换器SGM612A122,精准适配Intel VNNAON Rail
圣邦微电子正式推出SGM612A122,一款支持4.5V至24V宽输入电压范围、0.6V至2V可调输出电压、可持续输出14A电流,峰值电流高达33A的高性能同步降压转换器,精准适配Intel VNNAON核心电源轨。 芯片采用自适应恒定导通时间(COT)控制架构,具备快速动态响应能力,可显著优化负载瞬态性能。兼具高灵活配置性,支持四档开关频率与三档谷值电流限制可调,轻松适配多样化应用需求。轻载工况下,提供PSM(省电模式)与USM(超声模式)两种选择,兼顾高效率与低噪声表现,为系统设计带来更多可能。 SGM612A122广泛适用于笔记本电脑/平板电脑及工业计算机等需要宽电压输入的大电流场景,以紧凑的TQFN-3×4-19L封装实现高效可靠的供电方案。 同系列产品SGM612A12也已同步供应,支持0.6V至5V可调输出电压,持续输出电流能力达12A,满足更广泛的系统设计需求。 宽压高效 SGM612A122以效率驱动为核心设计理念,通过低RDSON功率器件与高速栅极驱动技术协同,在VIN = 12V、VOUT = 0.77V、fSW = 800kHz的典型条件下,峰值效率可达84%。且从0.1A轻载至14A满载,其效率均能保持在80%以上,有效降低系统功耗,助力实现更环保、更可靠的电源设计。 SGM612A122具备56μA的低静态电流,在笔记本S3~S5软关机状态下功耗极低,有效延长笔记本待机续航,助力移动终端能效优化。 图1 VIN = 12V or VIN = 20V,VOUT = 0.77V,fSW = 800kHz(PSM) 高稳定性、快速动态响应 稳定性是衡量电源品质的重要指标。在不同工作模式下,SGM612A122开关波形始终保持干净、连续,输出电压纹波被精准控制在极小范围内,从而最大限度地减少电源噪声对敏感电路的干扰,为系统的高可靠运行提供纯净的供电环境。 图2 SGM612A122空载输出电压纹波波形(PSM) 图3 SGM612A122满载输出电压纹波波形(PSM) 卓越的动态响应能力是SGM612A122的核心优势所在。基于自适应恒定导通时间(COT)控制架构,结合内部环路参数的精心调校,实现快速、精准的闭环调节。在快速负载跳变时,其瞬态电压跌落与过冲幅度均能控制在50mV以内,稳态恢复时间亦较短,确保输出电压在剧烈负载波动下依然保持稳定可靠。 高灵活配置 SGM612A122提供了多档可调参数,方便工程师根据具体应用做针对性优化: 开关频率可调:通过FS引脚外接电阻,可选择500kHz、800kHz、1MHz、1.2MHz; 谷值电流限制可调:通过CLM引脚外接电阻,可选20A、26A、33A三档; 轻载模式可选:PSM模式专注轻载高效率,USM模式消除音频噪声,两种模式兼顾能效与静音表现,适配不同场景需求。 保护功能齐全 SGM612A122集成了多种保护机制: 输出过压(OVP)和欠压(UVP)保护,触发后进入锁存模式; 逐周期谷值电流限制; 过热关断保护(典型值+165℃,滞回+25℃),非锁存,温度下降后自动软启动; 输入欠压锁定(UVLO),非锁存; 集成输出放电电阻:典型值50Ω; 开漏Power Good指示引脚。SGM612A122凭借宽输入电压范围、出色的动态响应、优异的效率表现以及灵活的多模式配置,为大电流DC/DC应用提供了一套兼顾性能与可靠性的完整供电方案。无论是笔记本电脑、便携终端,还是工业计算机,都可以用精简的外围电路实现高性能电源转换,助力工程师加速产品落地。
圣邦微
圣邦微电子 . 2026-06-30 826

物流机器人之AGV/AMR无人搬运车MOSFET系统选型指南
VBsemi高效功率器件方案,助力无人搬运系统实现高扭矩、长续航与高可靠运行 随着智能仓储、柔性制造和无人配送的发展,AGV/AMR无人搬运车正从单一的路径搬运设备,升级为集驱动、导航、感知、充电、安全保护与智能调度于一体的移动机器人平台。 在这一过程中,电机驱动效率、电池能量利用率、瞬态过流承受能力以及整机热管理能力,都会直接影响AGV/AMR的续航时间、载重能力、运行稳定性和维护成本。MOSFET作为动力系统、电池主回路、充电保护、制动回收与辅助负载控制的核心功率器件,需要同时满足低导通损耗、高电流能力、高耐压裕量、紧凑封装和可靠散热等要求。 针对48V、60V、72V及200V级AGV/AMR系统平台,VBsemi推出覆盖主牵引驱动、电池主开关、液压泵、充电保护、制动回收及辅助系统的MOSFET选型方案,为物流机器人构建高效、稳定、紧凑的功率链路。 一、AGV/AMR核心功率链路解析 一台典型的AGV/AMR无人搬运车,通常包括以下功率模块: 主牵引电机控制器:负责轮毂电机、差速驱动或伺服驱动,是整车最大的功率消耗单元。 升降机构与液压泵驱动:用于货叉升降、载具举升、牵引机构或液压执行系统,对峰值电流能力要求较高。 电池主开关与热插拔保护:负责72V电池主回路通断、预充、热插拔和电子保险丝保护。 充电输入保护:用于充电桩输入端、防反接、浪涌抑制及充电回路保护。 制动能量回收:对电机回馈能量进行路径控制,提高续航并降低制动热损耗。 转向、抱闸与辅助执行机构:包含转向电机、抱闸、电磁阀、风扇、传感器及其他外围负载。 VBsemi通过不同耐压等级、不同封装形式和不同导通电阻的MOSFET组合,可为AGV/AMR构建从主功率回路到低压辅助供电的一站式器件方案。 二、AGV/AMR无人搬运车MOSFET选型总表 功能模块 功率等级 推荐型号 封装 关键参数 选型价值 主牵引电机控制器 48V / 72V VBGQA1805 DFN8(5×6) 80V / 120A / 4.5mΩ 适合轮毂电机、差速驱动及主牵引逆变器 升降/液压泵驱动 48V–60V VBGED1601 LFPAK56 60V / 270A / 1.2mΩ 超低导阻,高峰值电流能力,适合升降与液压驱动 电池主开关 72V平台 VBGQA1802 DFN8(5×6) 80V / 180A / 1.9mΩ 低损耗主回路,适合电池主开关与预充电路 热插拔/电子保险丝 72V平台 VBGP1803 TO247 80V / 215A / 2.9mΩ 大封装、散热裕量高,适合大电流保护回路 充电输入保护 100V–200V VBM1202N TO220 200V / 80A / 17mΩ 高耐压,适合充电口、防反接及浪涌保护 制动能量回收 100V–200V VBMB1202N TO220F 200V / 65A / 17mΩ 绝缘封装,便于安规与散热布局 转向/抱闸小电机 24V–60V VBQA3615 DFN8(5×6)-B 双N管 / 60V / 40A / 11mΩ 双管集成,适合小电机、抱闸及双向驱动 辅助高侧开关 24V–60V VBQF2658 DFN8(3×3) P-MOS / -60V / -11A / 60mΩ 适合辅助负载、电磁阀、风扇及低功率高侧控制 三、主牵引电机控制器:VBGQA1805 80V / 120A / 4.5mΩ,面向48V与72V主驱动平台 AGV/AMR的主牵引电机控制器通常采用三相逆变结构,为轮毂电机、差速电机或伺服电机提供动力。该模块需要频繁承受加速、爬坡、急停、重载启动等工况,对MOSFET的导通损耗、开关效率和热性能提出较高要求。 VBGQA1805采用DFN8(5×6)封装,具备80V耐压、120A连续电流能力及4.5mΩ超低导通电阻。其SGT工艺有助于降低大电流驱动过程中的导通损耗,适用于48V、60V和72V平台下的主牵引电机控制器。 对于轮毂驱动和差速驱动系统,VBGQA1805能够帮助降低桥臂温升,提高电机控制器的持续输出能力,并为整车爬坡、载重和长时间运行提供更稳定的功率基础。 四、升降与液压泵驱动:VBGED1601 60V / 270A / 1.2mΩ,低导阻应对高峰值负载 在货叉升降、液压泵、电动推杆和高负载执行机构中,系统往往需要在短时间内输出较大电流。此类工况不仅对MOSFET的电流能力要求高,同时也需要较低的RDS(on)来减少热损耗。 VBGED1601采用LFPAK56封装,具备60V耐压、270A电流能力和1.2mΩ超低导通电阻。该器件适合应用于48V–60V升降机构、电动液压泵及高电流执行器驱动模块。 超低导通电阻能够显著降低大电流工作时的功率损耗,减少散热器和铜箔面积压力,有助于提升AGV/AMR升降系统的响应速度、持续负载能力及整机功率密度。 五、电池主回路与热插拔保护:VBGQA1802 + VBGP1803 低损耗主开关与高散热保护方案 72V电池平台是中大型AGV/AMR的常见方案。电池主回路承担整车供电、预充、急停、短路保护及热插拔等重要任务,对器件耐压、电流能力和散热设计均提出更高要求。 1. 电池主开关:VBGQA1802 VBGQA1802采用DFN8(5×6)封装,具备80V耐压、180A电流能力和1.9mΩ低导通电阻。该器件适合用于72V电池主开关、主电源回路和预充控制电路。 低导通损耗有助于降低主回路压降,提高电池能量利用率,并减少长时间运行过程中的温升,为整车续航和稳定性提供支持。 2. 热插拔/电子保险丝:VBGP1803 VBGP1803采用TO247封装,具备80V耐压、215A电流能力和2.9mΩ导通电阻。TO247封装具有更大的散热面积和更高的热容量,适用于热插拔、电子保险丝、大电流保护及高功率主回路控制。 在电池插拔、启动浪涌、负载突变和异常短路等场景下,VBGP1803可为系统提供更大的电流与散热裕量,便于工程师构建更可靠的保护回路。 六、充电保护与制动能量回收:200V平台双器件组合 随着AGV/AMR平台电压升级,充电输入端和制动回收通路往往需要更高耐压的MOSFET来覆盖浪涌、电压尖峰和高压回馈能量。 1. 充电输入保护:VBM1202N VBM1202N采用TO220封装,具备200V耐压、80A电流能力和17mΩ导通电阻,适用于充电口保护、防反接、输入浪涌抑制及高压开关控制。 在外部充电设备接入时,充电输入端可能面临反接、突波、电压不稳和异常电流等风险。VBM1202N能够为充电路径提供较高的耐压裕量,帮助提高充电接口的可靠性。 2. 制动能量回收:VBMB1202N VBMB1202N采用TO220F绝缘封装,具备200V耐压、65A电流能力和17mΩ导通电阻。该器件适合用于制动能量回收、电机反电动势吸收及高压隔离型功率路径。 TO220F绝缘封装有利于安规设计和散热器安装,可减少绝缘片等辅助结构的复杂度,适合对电气隔离和系统安全有要求的AGV/AMR制动系统。 七、转向、抱闸与辅助高侧开关:紧凑型低压驱动方案 除主功率回路外,AGV/AMR还包含转向电机、抱闸、电磁阀、照明、风扇、传感器、通信模块等大量辅助负载。此类模块通常要求器件封装小、驱动方便、功耗低,并具备较高的集成度。 1. 转向/抱闸小电机:VBQA3615 VBQA3615采用DFN8(5×6)-B封装,内部为双N沟道MOSFET配置,具备60V耐压、40A电流能力,RDS(on)低至11mΩ。 双N管集成结构适合用于转向电机、抱闸线圈、小型直流电机、双向开关和同步驱动等场景。相比两颗分立MOSFET方案,VBQA3615可减少PCB占板面积,降低寄生参数,并简化外围驱动与布局设计。 2. 辅助高侧开关:VBQF2658 VBQF2658采用DFN8(3×3)封装,为P沟道MOSFET,具备-60V耐压、-11A电流能力和60mΩ导通电阻。 P沟道器件适合用于低压高侧负载开关,可直接通过低压逻辑信号实现控制,适用于风扇、电磁阀、传感器供电、通信模块、照明模块及其他辅助电源路径。 紧凑的DFN8(3×3)封装适合空间受限的控制板布局,可帮助AGV/AMR在功能扩展的同时保持较高集成度。 方案核心优势 1. 覆盖48V、60V、72V与200V多电压平台 从低压辅助模块到高压充电与回收路径,VBsemi可提供完整的MOSFET器件组合,适应不同功率等级AGV/AMR平台。 2. 低导通电阻,降低整机能耗 VBGED1601的1.2mΩ、VBGQA1802的1.9mΩ、VBGP1803的2.9mΩ及VBGQA1805的4.5mΩ导通电阻,为主功率回路降低损耗、减少温升、提升续航提供支撑。 3. 多种封装,兼顾功率密度与散热能力 DFN8、LFPAK56、TO220、TO220F和TO247等封装,能够分别覆盖高集成控制板、大电流驱动板和高散热主功率模块。 4. 从主驱动到辅助负载的一站式配套 方案覆盖主牵引、液压泵、主电池开关、热插拔、充电保护、制动回收、转向抱闸和辅助高侧开关,减少客户多供应商选型与验证成本。 5. 适合高频启动、重载运行与复杂工况 针对AGV/AMR频繁启动、反复启停、满载爬坡、制动回收和长时间运行等特点,VBsemi通过不同电流等级与耐压等级器件组合,为系统提供更合理的功率器件匹配。 AGV/AMR无人搬运车的竞争,正在从单纯的路径导航与机械结构竞争,逐步进入能效、续航、载重能力、可靠性和智能化协同优化阶段。 VBsemi以VBGQA1805、VBGED1601、VBGQA1802、VBGP1803、VBM1202N、VBMB1202N、VBQA3615和VBQF2658为核心,构建覆盖主牵引驱动、电池管理、升降执行、充电保护、制动回收及辅助负载控制的MOSFET系统解决方案。 通过低导通损耗、高电流能力、多封装适配和完整功率链路覆盖,VBsemi可帮助AGV/AMR设备制造商在整机效率、功率密度、热管理和系统可靠性之间取得更优平衡,为智能物流和无人搬运设备提供更具竞争力的功率器件支持。 VBsemi——以高效功率器件,赋能物流机器人稳定运行。 相约2026慕尼黑上海电子展,共探物流机器人高效功率方案 面向智能仓储、柔性制造与无人搬运设备持续升级的市场需求,微碧半导体 VBsemi 将持续完善低中压MOSFET、SiC及GaN等功率器件产品布局,为AGV/AMR无人搬运车的主牵引驱动、电池管理、升降执行、充电保护、能量回收及辅助供电等应用,提供高效率、高可靠性、高功率密度的系统级选型支持。 2026慕尼黑上海电子展期间,VBsemi将携多款高性能功率器件及行业应用方案亮相现场,诚邀物流机器人、工业自动化、电机控制、电源管理及智能制造领域的客户与合作伙伴莅临交流,共同探讨无人搬运车功率系统的技术升级与应用落地。 2026慕尼黑上海电子展 微碧半导体 VBsemi 展位号:N5.150 展会时间:2026年7月1日-3日 展会地点:上海新国际博览中心 VBsemi期待与您相聚上海,共话智能物流与高效功率器件新未来!
微碧
微碧半导体 . 2026-06-30 1 1295

解码H3361:流控算法如何稳住企业级SSD的性能曲线
顺序读写、随机性能和接口带宽 是衡量SSD的重要指标 但在数据库、虚拟化企业级场景中 eSSD面对的是持续写入、高并发访问 与后台维护并行运行的复杂负载环境 因此,稳定响应能力往往比单次跑分更重要 H3361企业级SSD双模主控:流控算法 用户通过PCIe/SATA接口向NAND写入数据,期间SSD主控内部也会有GC等任务占用资源。流控算法通过监测空闲块与后端资源状态,有效调度Host IO(主机输入输出)、GC(垃圾回收)及其它后台维护任务的资源占用,把后台回收从突发动作变成受控过程,从而提升SSD在复杂负载环境下的性能一致性。 一、延迟波动和性能抖动来自哪: Host IO与GC的资源竞争 受NAND Flash物理特性影响,数据更新无法直接覆盖旧位置,而需要先完成块擦除后再重新写入。因此,SSD会通过FTL映射将新数据写入新位置,并将旧数据标记为无效。 1. 随着写入持续进行,系统内部会逐渐形成待回收空间 垃圾回收(GC)、磨损均衡(WL)等后台维护任务随之启动,通过数据搬移与块擦除释放空间,同时也会占用SSD内部读写资源。 2. 前台Host IO与后台维护任务并行,内部资源竞争加剧 后台任务运行过于集中时,前台业务容易出现写入掉速、延迟升高以及性能波动等一系列性能问题。 二、流控算法如何把突发阻塞变成平滑调度 H3361的流控算法并非单一限速策略,而是一套围绕资源调度构建的协同机制。系统会根据当前空间压力与回收效率动态调整后台回收节奏,降低GC对Host IO的扰动,使整体性能曲线更加平滑稳定。 时间片调度-把集中波动拆解成连续的小幅调度 Ø GC原本可能形成较长时间的资源占用,主控将其拆分为更小的任务单元,并穿插在Host IO的间隙中执行。 Ø 对于持续小流量扰动和频繁大流量突发场景,这种细颗粒度调度有助于吸收突发压力,降低性能曲线的锯齿感。 滞回曲线流控-采用更平滑的调节方式 传统阈值控制容易因资源波动频繁切换策略,从而引入新的性能抖动。 Ø 滞回控制当资源下降时,及时降低前台写入压力,为GC释放更多资源; Ø 当资源恢复后,再逐步归还带宽,避免瞬间放开导致系统再次进入高压状态。 预测层面的生产者-消费者模型 判断下一阶段的空间压力 Ø Host IO与GC写入会消耗空闲页,GC完成与块擦除则释放空闲页。主控基于上一时间片的资源变化,结合VPC滑模控制动态评估回收成本并调整GC强度,使前台业务性能更加平滑稳定。 三、接口决定速度上限,流控决定稳定下限 相比传统线性控制方式,面向复杂场景设计的滞回曲线流控更适合SSD内部的非线性资源竞争,既能缓解持续小流量扰动带来的长期压力,也能吸收大流量突发的瞬时冲击,从而保持更稳定的控制精度与性能表现。 H3361的双模主控的价值在于 以统一资源管理逻辑适配不同业务压力 在SATA III场景中保障稳定响应 在 PCIe 3.0 高并发场景中降低资源竞争影响 从而帮助eSSD能够在复杂环境下 依然保持稳定一致的性能表现 更好应对复杂业务负载
TWSC . 2026-06-30 1 791

企业 | AI赋能全电时代,贸泽电子重磅亮相2026慕尼黑上海电子展
2026年6月29日 – 提供超丰富半导体和电子元器件™的业界知名新品引入 (NPI) 代理商贸泽电子 (Mouser Electronics)宣布,将于7月1-3日重磅亮相2026慕尼黑上海电子展(展位号:N2馆 621号展位)。本届展会,贸泽电子将携手Amphenol (安费诺)、Bel Group (Bel集团)、NXP Semiconductors (恩智浦)、Phoenix Contact (菲尼克斯)、Renesas Electronics (瑞萨电子)、Silicon Labs (芯科科技)、VICOR、Würth Elektronik (伍尔特电子)等头部厂商,围绕人工智能、工业自动化、低空经济、能量收集与存储、智能家居、智能汽车等核心赛道,全方位呈现各领域前沿技术与创新方案。 贸泽电子亚太区市场及商务拓展副总裁田吉平表示:“随着人工智能与电力电子技术的深度融合,全电时代正加速到来,并持续重塑多个行业的应用场景。贸泽电子始终密切关注这一趋势,围绕‘AI赋能全电系统’整合全球优质供应商资源,在本届慕尼黑上海电子展上深度覆盖多类热门应用领域,集中呈现原厂核心产品与前沿技术。我们诚挚邀请现场观众莅临贸泽展台,近距离感受科技创新带来的行业变革,共同展望产业的未来发展。” 今年展会现场,贸泽将带来自主开发的AI语音互动机器人M-bot,为观众带来耳目一新的人机互动体验。该机器人支持流畅自然的中英双语智能交互,依托直观、高效的语音交互模式,观众可实时查询贸泽官网产品资讯、库存状态、价格及出货周期等信息,同时针对电子元器件选型、场景应用方案、技术疑难问题,可获得专业及时的参考方案。从资讯查询到技术咨询,M-bot皆能一站式的回应,大幅提升互动效率与服务体验,充分彰显贸泽电子以数字化技术赋能服务升级,布局智慧未来的前瞻性战略。 此外,贸泽还将展出另一款由工程师开发的方案产品,该设计是一款基于 STM32H7 高性能微控制器的双足轮足式机器人。项目融合了足式机器人的高通过性与轮式机器人灵活、高速、低能耗的特点。通过五连杆机械拓扑结构和准直驱(MIT 方案)力控电机,机器人能够在非平整地面上实现自平衡、高度适应、跳跃及快速滑行。贸泽还将带来2026 M-Design设计大赛的优秀参赛作品,聚焦“AI+硬件创新”,开启AI与硬件深度融合的更多可能,以电子设计创新助推行业智能化发展。 今年展会上,贸泽将集中展示原厂的多款最新开发板,包括: ESP32-C5-DevKitC-1 Development Kit KIT_A3G_TC4D7_LITE AURIX™ A3G Lite套件 PIC32CZ CA70 Curiosity Ultra开发板 nRF9151 SMA开发套件 FRDM-A-S32K344 评估板 1MP图像传感器评估板 Compute Module 5 (CM5) Development Kit EK-RA8P1 评估套件 GNP2130TEC-1-EVK-001 评估套件 Robot SO-ARM101 AI Arm Kits STM32MP215x-DK 探索套件 AUDIO-AM275-EVM 评估模块 展会期间,贸泽电子还将携手B站知名科技博主开展云逛展直播,并联合恩智浦、菲尼克斯、太阳诱电和莫仕,探访原厂最新应用方案。用户可关注贸泽电子B站直播间和贸泽视频号,直播时间为7月2日12:30至14:30。此外,展台现场还将设置机器人互动体验、创客DIY工作坊及“芯动大转盘”等活动,为观众带来丰富的互动体验。欢迎广大用户莅临贸泽展台,参与活动并赢取定制好礼。
慕尼黑上海电子展
芯查查资讯 . 2026-06-30 1 1295
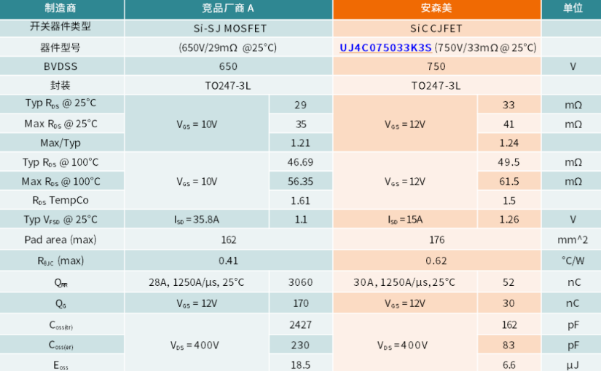
碳化硅赋能浪潮教程:利用SiC CJFET替代超结MOSFET
摘要:碳化硅(SiC)凭借其优异的材料特性,在服务器、工业电源等关键领域掀起技术变革浪潮。本教程聚焦SiC 尤其是SiC JFET系列器件,从碳化硅如何重构电源设计逻辑出发,剖析其在工业与服务器电源场景的应用价值。我们已经介绍了《碳化硅如何革新电源设计、工业与服务器电源》《三种替代Si和SiC MOSFET的方案》《SiC Cascode JFET与SiC Combo JFET深度解析》。本文将介绍利用SiC CJFET替代超结MOSFET以及开关电源应用。 (一) 利用SiC CJFET替代超结MOSFET (1) 安森美与竞品对比 本表对比了安森美(onsemi)EliteSiC CJFET器件UJ4C075033K3S与某竞品厂商的Si超结(SJ)MOSFET的关键特性。其中,UJ4C075033K3S在25℃下的额定值为750V,33mΩ;而竞品Si SJ MOSFET在25℃下的额定值为650V,29mΩ。在此对比中,该CJFET的反向恢复电荷QRR降低至1/60,栅极电荷QG降低至1/6,反向传输电容COSS(tr)降低至1/10。 (2) 最大限度降低反向传输电容 SiC CJFET与Si SJ MOSFET之间最显著的差异在于电容特性与裸片尺寸。在安森美UJ4C075044B7S CJFET与某竞品Si SJ MOSFET的对比中,尽管CJFET的阻断电压VBRDSS高出100V,且两者的导通电阻RDS(on)额定值相近,但SJ MOSFET的反向传输电容COSS(tr)却高出13倍以上。这一差异源于SJ MOSFET在低压范围内表现出的非线性特性,如下图所示。CJFET的电压转换时间远短于SJ MOSFET。在采用半桥整流拓扑(而非全桥)的电源系统中,CJFET能始终实现显著更快的开关速度。 (3) 降低导通损耗,缩短死区时间 在用SiC CJFET替代Si SJ MOSFET时,安森美建议通过调整死区时间(dead time)或在CJFET上增加缓冲电容,以有效管理因死区引起的导通损耗。尤其在较高开关频率下,死区时间带来的影响会变得更加显著。 对于CJFET而言,从检测到电流反向到JFET沟道完全导通通常存在延迟。举例来说:若死区时间为100ns,而开关频率为100kHz,则开关周期为10µs,此时死区仅占周期的1%,该延迟影响相对较小。然而,若开关频率提升至1MHz,开关周期将缩短至1µs,死区时间便占整个周期的10%,其影响不可忽视。 在相同死区时间下,相较于Si SJ MOSFET,SiC CJFET的漏源电压VDS放电速度更快,导致其体二极管在剩余死区时间内持续导通。假设CJFET剩余死区时间TDT(CJFET)为0.2µs,体二极管正向压降VFD为1.2V,开关频率FSW为100kHz,开关电流IC为10A,则全桥拓扑中由剩余死区引起的功率损耗PDT可通过以下公式计算: 在此案例中,计算得出的损耗为0.96W。然而,通过对栅极应用Adaptive Gate Control,在死区时间内提前提升VG2,让VDS(CJFET)降至0V的瞬间开通。即可使该部分损耗趋近于零。这一效果可通过观测VDS与VGS的输出波形加以验证。 死区时间越长,体二极管导通损耗的持续时间也越长。通过缩短CJFET的死区时间,或为其增加缓冲电容以匹配Si SJ MOSFET的COSS,可有效改善此问题。 (4) 消除反向恢复失效风险 在对比SiC CJFET与Si SJ MOSFET时,当两者具有相同的电流变化率(Δi/Δt)并在相同的结温(TJ=25℃)下工作,安森美UJ4C075033K3S CJFET的反向恢复电荷(QRR)最多可比后者低60倍。更小的反向恢复电荷意味着更高效率、更低噪声与更优的电磁兼容性。此外,CJFET在反向恢复过程中没有导致器件失效的风险,可显著提升系统整体稳健性。 (二) 开关电源应用 (1) 适用于任何电压等级的高能效表现 为展示CJFET在电源快速开关需求下的性能,我们测试了四款不同的安森美CJFET器件在3.6kW图腾柱功率因数校正(TPPFC)硬开关拓扑中的效率。所有被测CJFET在半负载条件下均实现了超过99%的峰值效率。 (2) 同步整流(SR)技术 同步整流的实现,首先在于用可控的场效应晶体管(FET)替代谐振型电源转换器中通常在初级侧(有时也在次级侧)使用的二极管。由于这些FET的开关时序可以更直接地控制,转换器输出的直流波形能够更准确地匹配负载所需的电压和频率。 全桥移相有源桥零电压转换拓扑 以这种在AC-DC应用中日益普及的电路拓扑为例:所有通常使用二极管的开关位置均被场效应晶体管替代。“ZVT”代表零电压转换,该技术巧妙利用了主变压器的漏电感与开关的输出电容——这些通常被视为寄生元件的特性——并将其转化为优势。 例如,在标准全桥拓扑中置于初级侧外部的漏电感,现在可集成至内部。它在实现相同功能的同时,大幅缩减了占用空间。 通过有源桥移相控制,脉宽调制(PWM)可转换为固定开关频率的工作模式,这使控制实现更为简便,同时降低了开关对击穿电压的耐压要求。电磁干扰频谱也更为集中,使系统在整个宽输出电压范围内均能实现稳定且高效率的运行。 (3) 零电压开关(ZVS) 从电气工程师的角度来看,全桥功率转换过程的一大优势在于它能够实现软开关。严格来说,ZVS并非一种刻意设计的技术手段,而更像是一种可被巧妙利用的物理现象。它通过功率转换器的谐振网络(或称“谐振腔”)得以实现。 典型的零电压开关会利用电容和电感构成一个谐振电路(即“谐振腔”)。而在实际应用中,常以变压器固有的励磁电流作为便捷的替代。可以把这个励磁电流看作一种振荡信号,它能够在PFC电路中MOSFET(或CJFET)两端电压为零(或极低)时,将器件导通。 波形整形的核心思想是:在输入电压处于波峰或波谷时导通或关断输出开关,而谐振所产生的自然振荡,恰好为这种基于电感特性的开关动作提供了理想时序。 该电流被有意设置为相位滞后于谐振网络的电压,正是这种滞后引发了谐振,从而触发场效应晶体管导通(并促使其他开关按序关断)。在此过程中,开关损耗得以有效避免,EMI噪声也显著降低。 (4) 高频电源的五个转换级 这是前文介绍的图腾柱PFC完整电路图。这种全“无桥式”拓扑结构包含五个功率转换级。最左侧为硬开关,其余四个均采用软开关技术。从左至右,每个同步整流转换级的电路结构逐级简化。 对于“快速桥臂”(即硬开关),图腾柱PFC需搭配RC缓冲器使用CJFET。若PCB布局空间受限无法容纳此元件,则SiC MOSFET可能成为唯一选择。否则,若考虑CJFET配合RC缓冲电路所能实现的性能特性,CJFET将是更优方案。 对于“慢速桥臂”(即同步整流器件),其核心要求是具备低导通电阻RDS(on),因此CJFET是最佳选择。 对于位于中间的初级LLC转换级(因其紧邻两个电感L和一个电容C而得名),导通损耗是主要损耗因素。在高开关频率下,关断开关损耗是另一个关键参数,因为LLC作为一种零电压开关(ZVS)拓扑,不存在导通损耗。CJFET在配置缓冲器后已展现出极低的关断能量损耗Eoff,因此是初级LLC转换级的最佳选择。 随后的次级LLC转换级以及最右侧的O-Ring级可用于400V输出电压的设计中。对于此类高压应用,低导通电阻RDS(on)和低输出电容COSS至关重要,这使得CJFET在整个次级侧相比SiC MOSFET或Si SJ MOSFET更具优势。 未完待续,我们将介绍CJFET通常需要配置缓冲电路的原因等。
安森美 . 2026-06-29 868
- 1
- 9
- 10
- 11
- 12
- 13
- 500