
MDD辰达半导体推出集成ESD防护小型化MOS,赋能智能穿戴与精密接口开关
当下,智能穿戴设备、便携式数码产品、工业小型模块持续向着微型化、低功耗、高可靠、多电压适配方向升级。PCB 空间愈发紧凑、待机续航要求不断提高、接口信号切换愈发频繁,对小体积 MOS 管的耐压、导通损耗、开关速度、静电防护等综合性能提出了更高标准。 一、小型化封装 兼具ESD防护 MDD 推出MDD3134KM、MDD3139KM、2N7002KM三款同封装 MOSFET 产品。统一采用SOT-723 超小型封装,沟槽工艺,分别覆盖 60V 高压信号开关、20V 低压功率开关、互补推挽电路等主流场景,成为智能穿戴、器件接口开关、电池保护、小型电机驱动等领域的高性价比国产优选方案。 在可靠性防护层面,三款产品全部集成2kV HBM 人体模型 ESD 防护能力,可有效抵御生产焊接、日常使用、人体触碰产生的静电冲击,降低器件意外损坏概率,提升终端产品在复杂环境下的使用寿命与稳定性。此外,全系产品均支持宽温工作,耐高低温性能优异,可从容应对户外、密闭腔体、温差较大等工况。 二、核心参数性能解析 三款器件定位清晰,2N7002KM 为 60V N 沟道高压信号管,主打信号切换、电平转换;MDD3134KM(20V N 沟道)+MDD3139KM(20V P 沟道) 组成 20V 互补 MOS 组合,主打低压功率开关、电源管理、充放电保护。 三、多元应用场景 智能手表、蓝牙耳机、设备拓展口、有线接口产品兼具空间小、功耗敏感、接口多、高低压电路共存的特点,三款器件可分工协作,也可组合搭配,实现全电路覆盖: 1、2N7002KM:负责传感器信号开关、触控按键控制、蓝牙 / 天线信号切换、LED 指示灯 PWM 调光。60V 高耐压可抵御接口静电与电压冲击,逻辑电平直驱特性简化电路。 2、MDD3134KM+MDD3139KM(互补组合):搭建电池充放电保护回路、整机电源总开关、主副电源分时切换电路。超低导通电阻 + 极低漏电流,大幅降低整机功耗,延长穿戴设备续航;同时驱动内部振动马达、微型传动电机,依托优秀体二极管吸收反向电动势,保护核心芯片。 3、多路信号切换:三款器件均可作为模拟 / 数字信号开关,实现多路端口分时复用,微型封装适配密集接口板卡。 四、选型推荐 上述三款器件均支持逻辑芯片直驱,外围电路极简,有效降低 BOM 成本与 PCB 设计难度。除此之外,MDD针对其他小型化封装需求,还有如下多种封装产品推荐,同时兼顾性能、体积、可靠性与成本,欢迎来询。
保护器件
MDD辰达半导体 . 2026-06-29 973
英伟达Rubin架构倒逼封装革命:三星破解AI芯片供电最后一公里
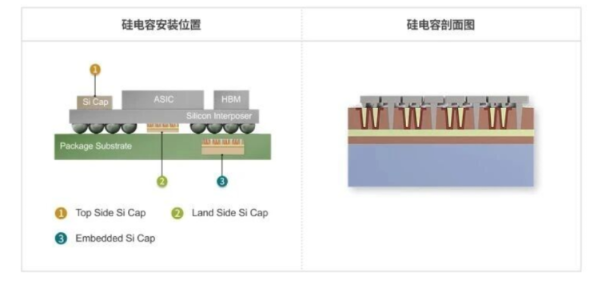
当AI芯片的封装空间被压缩到极致,传统MLCC正在触及物理天花板。硅电容——这项源自半导体晶圆制造工艺的被动元件技术,正在打开高性能封装的新可能。贞光科技作为三星电机授权代理商,从原理、对比、应用到产品选型,为您系统解析三星电机硅电容的技术代差。 什么是硅电容?从半导体工艺中诞生的"新一代电容器" 硅电容(Silicon Capacitor)并非传统意义上将陶瓷介质叠层烧结的MLCC,而是利用半导体技术对硅晶圆进行微细蚀刻,以扩大表面积,从而实现轻薄且高容量的新一代电容器。 这种制造逻辑的根本差异,决定了硅电容在物理形态上就与MLCC分道扬镳: 维度 传统MLCC 硅电容 制造工艺 陶瓷粉体叠层+高温烧结 半导体晶圆蚀刻+薄膜沉积 厚度控制 受限于叠层数,难以突破100μm 可做到68μm甚至更薄 寄生电感(ESL) 通常在数百pH级别 可低至**<<1pH** 温度稳定性 随温度变化容量漂移明显 250°C以上极端环境容量变化极小 正是这种半导体级的精度控制,让硅电容得以突破传统被动元件的物理极限。 硅电容 vs MLCC:五个维度的技术代差 在先进封装(Advanced Packaging)时代,工程师对电容的要求已从"能用电容"升级为"电容不能成为瓶颈"。以下是硅电容在五个关键维度上建立的代际优势: 1. 超薄:封装空间的"最后1mm" AI服务器GPU、HBM堆叠芯片、智能手机主板的内部空间已被压缩到微米级。三星电机硅电容的厚度可做到68μm(如SCBCAP305L95EGNNWT),这意味着它可以: 嵌入基板内部(Embedded):不占PCB表面面积 置于芯片顶部(Top Side)或底部(Land Side):为高密度互连释放布线空间 适配2.5D/3D封装:在Silicon Interposer与Package Substrate之间无缝集成 2. 超低ESL:高频电路的"噪声免疫" 寄生电感(ESL)是电流急剧流动时产生的噪声源,会直接降低高频电路性能。硅电容的ESL低于1pH,在AI服务器和自动驾驶等高速通信环境中,可有效降低噪声,实现信号的准确、快速传输。 3. 高可靠性:极端环境的"稳压器" 即使在250°C以上的极端环境下,硅电容仍能提供稳定性能。对于发热严重的AI服务器,或航空航天、汽车等极端环境,容量变化极小,可安心应用。 4. 高容量密度:单位体积的"能量仓库" 通过半导体蚀刻技术扩大有效表面积,硅电容在同等体积下可实现更高的容量密度。例如三星电机的SCHVSP107MH1AGB9WT,尺寸11.01×8.35mm,容量可达103950nF。 5. 集成友好:封装设计的"乐高积木" 硅电容支持多种封装形式——LSC(Land Side Capacitor)、DSC(Die Side Capacitor)、Embedded,可根据芯片架构灵活部署,这是传统MLCC难以实现的系统集成度。 为什么AI芯片封装必须用硅电容? AI算力的爆发正在重塑半导体封装的底层逻辑。以英伟达H100、AMD MI300为代表的AI加速器,其供电设计面临三大挑战: 挑战一:电流密度激增 AI训练芯片的峰值电流可达数百安培,需要大量去耦电容(Decoupling Capacitor)并联 传统MLCC数量过多会挤占宝贵的PCB面积 挑战二:电压纹波容忍度极低 1V以下的核心电压,要求纹波控制在±3%以内 低ESL是抑制高频纹波的关键,硅电容的<<1pH ESL成为刚需 挑战三:热管理耦合 AI芯片的TDP(热设计功耗)突破700W,电容必须承受高温环境 硅电容的250°C+稳定性确保在热应力下不退化 应用场景全景: AI & Cloud Server:最大化高性能AI服务器芯片组性能 Mobile & Wearable:超薄智能手机及AR眼镜等下一代可穿戴设备 Automotive & Aerospace:自动驾驶系统,以及对可靠性要求极高的航空航天、医疗设备 Optical Communication:光通信模块的高速信号完整性保障 三星电机硅电容产品矩阵:9款产品的差异化定位 三星电机目前拥有4款量产产品(MP)针对高性能半导体封装及AI服务器优化,以及5款推广用样品,共计9款产品阵容,覆盖从样品验证到量产导入的全周期需求。 型号 状态 特性 尺寸(mm) 厚度 容量 电源轨数 额定电压 击穿电压 封装类型 焊盘尺寸 SCBCAP305L95EGNNWT 样品 DC去耦 1.26×1.03 68μm 3000nF 4 1.2V 3.7V LSC 60μm SCBCAP105L95AGNNNT 样品 DC去耦 1.26×1.03 68μm 1000nF 4 1.35V 4V LSC 60μm SCBCAP514L95AGNNNT 量产 DC去耦 1.26×1.03 70μm 512nF 4 1.35V 4V LSC 60μm SCBCAP254L95AGNNNT 量产 DC去耦 1.26×0.51 70μm 256nF 2 1.35V 4V LSC 60μm SCG59P105M86AGNNWT 量产 DC去耦 0.96×0.88 60μm 1050nF 2 1.35V 4V LSC 55μm SCHVSP107MH1AGB9WT 量产 DC去耦 11.01×8.35 750μm 103950nF 198 1.35V 4V DSC 55μm SCRLLC885M5G5EGNNWT 样品 DC去耦 2.00×2.00 738μm 8800nF 2 1.2V 4V Embedded 200μm SCRNKC166M5G5EGNNWT 样品 DC去耦 4.06×2.00 738μm 17600nF 4 1.2V 4V Embedded 200μm SCRNNC326M5G5EGNNWT 样品 DC去耦 4.02×4.02 738μm 35000nF 4 1.2V 4V Embedded 200μm 选型逻辑: LSC封装(Land Side Capacitor):适用于芯片底部空间,厚度60-70μm,主打超薄去耦 DSC封装(Die Side Capacitor):如SCHVSP107MH1AGB9WT,198路电源轨,面向超大电流AI芯片 Embedded封装:嵌入基板内部,释放表面布线空间,适合超高密度集成 结语:硅电容是先进封装的"水电煤" 当AI芯片的制程进入3nm时代,封装技术的重要性已与制程本身等量齐观。硅电容作为封装供电设计的"水电煤"——看似基础,却决定了整个系统的性能天花板。 68μm的厚度、<<1pH的ESL、250°C的耐温极限——这些数字背后,是半导体制造工艺向被动元件领域的渗透,也是高性能封装设计的必然选择。
贞光科技 . 2026-06-29 1071

双芯合一:HKTG35C06,一颗PDFN5x6装下两颗60V N管
做电源方案的工程师大概都有过这种体验:板子上需要两颗N管,一颗做负载开关,一颗做同步整流,或者一颗控制充电通路、一颗控制放电通路。每颗管子各占一个位号,各走一条驱动线,布局的时候还得注意两管之间的距离别太近,不然散热互相打架。要是能把两颗管子合成一颗呢? 合科泰HKTG35C06就是这么做的。一颗PDFN5x6封装里,集成了两颗独立的60V N沟道MOSFET,各自有独立的栅极、源极和漏极引脚。5mm×6mm的占板面积,只占一个位号,干两颗管的活。 先看参数,再看故事 HKTG35C06的核心参数如下,均来自规格书典型值。 几个值得关注的点。 12mΩ×2通道。两颗管子的导通电阻都是12mΩ典型值,一致性很好,在半桥或双路开关场景中不需要额外匹配。4.5V栅压下17mΩ,5V逻辑电平可以直接驱动;3.3V系统需要确认VGS(th)的具体分布,规格书最大值为2.5V,个别批次在3.3V驱动下可能未完全增强。 Qg=22nC,Crss=8pF。栅极电荷22nC在几百kHz开关频率下驱动损耗可控。更值得注意的是反向传输电容Crss只有8pF,这个值很低。Crss也叫米勒电容,它的大小直接影响开关过程中漏极电压上升和下降的速率。Crss越低,米勒平台越短,开关越干脆,振铃也越少。在半桥应用中,Crss低还有一个好处:下管关断期间,上管开通带来的dv/dt通过Crss耦合到下管栅极的电压尖峰更小,误开通的风险更低。 EAS=36mJ。雪崩能量反映器件抵抗电压尖峰的能力,36mJ意味着在感性负载关断瞬间有一定的雪崩承受余量。电机驱动或继电器驱动场景中,这一点值得关注。 体二极管trr=18ns。这个参数在同步整流中很关键。死区期间下管体二极管导通,上管开通前体二极管需要反向恢复。trr=18ns说明恢复速度比较快,对应的反向恢复电荷Qrr只有12nC,死区期间的损耗和恢复电流尖峰都比较小。 Tj=175℃。比常见的150℃高了25℃,在密闭空间或高温环境下,这25℃的余量可能就是稳定运行和频繁过热保护之间的差别。 三种典型用法 用法一:同步整流Buck变换器 一颗HKTG35C06就能搭一个完整的半桥:上管做主开关,下管做同步整流。接线方式是将上管源极S1外连到下管漏极D2,形成开关节点。两颗管芯在同一个5×6封装内,物理距离很近,S1到D2的PCB走线可以做到很短,换流回路的寄生电感比两颗分立管分散布局时要小,开关振铃和EMI都有改善空间。需要注意的是,S1到D2仍然需要外部PCB连线,不像有些内置半桥的产品那样内部已连接,布局时尽量缩短这段走线即可。 在12V转5V或12V转3.3V的降压方案中,60V耐压留出了充足余量,每通道45A@Tc=25℃的电流能力覆盖大多数中小功率场景。 用法二:电池充放电开关 锂电池保护板上,充电通路和放电通路各需要一颗开关管。传统方案用两颗分立N管,各占一个位号。HKTG35C06两通道独立控制,一个栅极管充电、一个栅极管放电,一颗器件解决两条通路。PCB上省了一个位号,BOM少了一行,布局也更简洁。 用法三:双路独立负载开关 有些系统需要同时控制两路电源通断,比如主电源和待机电源的切换,或者两路负载的独立开关控制。HKTG35C06的两颗管子各自独立,互不干扰,一颗器件管两路,省空间也省成本。 样品与供货 HKTG35C06目前已有样品和一定数量的成品可供评估,封装为PDFN5x6-8L,兼容标准DFN5×6焊盘设计,无需额外修改PCB布局即可替换现有方案。 如需规格书或申请样品,请联系合科泰团队。 以上参数均来自HKTG35C06规格书典型值,实际选型请以数据手册为准。
双芯MOS管
厂商投稿 . 2026-06-29 1155

YOV2525DP 10MHz恒温晶振:专为HiFi音频打造的超低相噪时钟方案
随着数字音频技术的发展,DAC 解码器、数字转盘、网络播放器等 HiFi 设备对时钟性能的要求越来越高。在音频系统中,时钟不仅决定数据传输的准确性,更直接影响声音的解析力、声场表现和细节还原能力。作为数字音频链路中的核心基准,恒温晶振(OCXO)凭借超高稳定度和超低相位噪声,正逐渐成为发烧级 HiFi 设备和10MHz 主时钟(Master Clock)系统的主流选择。 一、时钟如何决定数字音频的上限 数字音频的本质是通过精准的时间基准完成采样与重建。当时钟存在频率漂移或抖动时,会影响 DAC 的转换精度,从而导致声场定位模糊、弱音细节损失以及背景噪声增加。因此,一款具备极致稳定性的时钟源,是数字音频系统实现高保真重放的底层基石。 二、YOV2525DP OCXO:参数指标及应用场景 YXC 扬兴科技推出的 YOV2525DP 恒温晶振,内置压控功能(VCXO,支持 0~4V 调谐电压输入,可实现频率微调和锁相控制),能够在长期运行中保持极高稳定度与深海级纯净声底。 相比普通晶振产品,YOV2525DP 能够在长期运行过程中保持更加稳定的频率输出,有效降低时钟抖动,带来更高解析力、更精准的声场定位、更纯净的背景以及更加自然真实的音乐表现,充分满足高端时钟系统需求。 (1)核心性能参数 Ø 标称频率:10MHz Ø 频率准确度:±0. 1ppm Ø 温度稳定度:≤±5ppb(-40℃~+85℃) Ø 电源稳定度:≤±2ppb Ø 负载稳定度:≤±2ppb Ø 老化率:≤±2ppb/天,≤±0. 1ppm/年 Ø 输出方式:CMOS方波输出 (2)典型相位噪声性能 Ø 1Hz:-100dBc/Hz Ø 10Hz:-120dBc/Hz Ø 100Hz:-135dBc/Hz Ø 1kHz:-155dBc/Hz Ø 10kHz:-160dBc/Hz Ø 100kHz:-160dBc/Hz (3)典型应用场景 Ø 外置10MHz主时钟(Master Clock) Ø 高端DAC解码器 Ø 网络流媒体播放器 Ø 数字转盘 Ø 专业录音与母带设备 三、关于YXC扬兴科技 作为专注高性能频率器件的国产原厂,YXC扬兴科技坚持以应用需求为导向,持续为高端音频与专业时钟系统提供稳定可靠的时钟解决方案。依托成熟的原厂交付能力与FAE技术支持,我们围绕YOV2525DP等核心产品,持续优化低相噪与高稳定度指标,为HiFi音频、数字音频设备及专业录音系统提供高品质时钟基准,并助力客户提升整体系统的时序性能与音频表现。
恒温晶振,晶振,OCXO,HIFI音响设备
扬兴科技 . 2026-06-29 917

MCH3427-TL-E与VBK1240参数对比报告
N沟道功率MOSFET参数对比分析报告:MCH3427-TL-E与VBK1240 一、产品概述 MCH3427-TL-E:安森美(onsemi)N沟道硅MOSFET,耐压20V,低导通电阻,超高速开关,支持1.8V栅极驱动。封装:SANYO MCPH3 (SOT-89类似)。适用于通用开关应用。 VBK1240:VBsemi N沟道20V沟槽(Trench)功率MOSFET,低导通电阻,100%栅极电阻测试,符合RoHS及无卤标准。封装:SOT-323 (SC-70)。适用于DC/DC转换器、便携设备负载开关。 二、绝对最大额定值对比 参数 符号 MCH3427-TL-E VBK1240 单位 漏-源电压 VDSS / VDS 20 20 V 栅-源电压 VGSS / VGS ±12 ±8 V 连续漏极电流 (Tc=25°C) ID 4 5 A 脉冲漏极电流 IDP / IDM 16 20 A 最大功率耗散 (Tc=25°C) PD 1 (特定散热条件) 2.1 (Tc=25°C) W 沟道/结温 Tch / TJ 150 150 °C 存储温度范围 Tstg -55 ~ +150 -55 ~ +150 °C 雪崩能量(单脉冲) EAS 未提供 未提供 mJ 雪崩电流 IAV 未提供 未提供 A 分析:两款器件耐压等级相同(20V)。VBK1240 具有更高的连续和脉冲电流额定值(5A/20A vs 4A/16A)以及在Tc=25°C下更高的功率耗散能力(2.1W vs 1W)。MCH3427-TL-E 允许更高的栅-源电压(±12V vs ±8V)。 三、电特性参数对比 3.1 导通特性 参数 符号 MCH3427-TL-E VBK1240 单位 漏-源击穿电压 V(BR)DSS 20 (最小) 20 (最小) V 栅极阈值电压 VGS(th) 0.4 ~ 1.3 (VGS(off)) 0.45 ~ 1.0 V 导通电阻 (VGS=4.5V) RDS(on) 未提供 0.0256 (典型) @ 4A Ω 导通电阻 (VGS=4.0V) RDS(on) 40 ~ 52 mΩ @ 2A 未提供 Ω 正向跨导 yfs / gfs 2.9 ~ 4.9 S @ 2A 24 S (典型) @ 4A S 分析:在典型驱动电压下,VBK1240 的导通电阻显著更低(约25.6mΩ vs 40mΩ+),导通损耗优势明显。其跨导也远高于MCH3427-TL-E,表明其栅极控制能力更强。MCH3427-TL-E 强调了在低至1.8V栅压下的导通能力。 3.2 动态特性 参数 符号 MCH3427-TL-E VBK1240 单位 输入电容 Ciss 400 865 (典型) pF 输出电容 Coss 92 105 (典型) pF 反向传输电容 Crss 85 55 (典型) pF 总栅极电荷 (VGS=4~4.5V) Qg 6 (典型) 8.8 ~ 14 (典型~最大) nC 栅-源电荷 Qgs 0.8 (典型) 1.1 (典型) nC 栅-漏(米勒)电荷 Qgd 2.2 (典型) 0.7 (典型) nC 分析:MCH3427-TL-E 的总栅极电荷和米勒电荷都更低(6nC, 2.2nC),栅极驱动损耗和驱动难度可能更小。VBK1240 的反向传输电容Crss更低(55pF vs 85pF),有利于降低开关过程中的米勒效应,提升稳定性。 3.3 开关时间 参数 符号 MCH3427-TL-E VBK1240 单位 开通延迟时间 td(on) 11 (典型) 5 ~ 16 (最小~最大, VGEN=5V) ns 上升时间 tr 75 (典型) 13 ~ 26 (最小~最大, VGEN=5V) ns 关断延迟时间 td(off) 54 (典型) 21 ~ 47 (最小~最大, VGEN=5V) ns 下降时间 tf 60 (典型) 6 ~ 16 (最小~最大, VGEN=5V) ns 分析:在相近测试条件下(VGEN=5V),VBK1240 的开关速度参数(尤其td(on)和tf)在典型值上可能优于MCH3427-TL-E,但其参数范围较宽。MCH3427-TL-E 的数据为典型值,开关速度也属于超高速范畴。 四、体二极管特性 参数 符号 MCH3427-TL-E VBK1240 单位 二极管正向压降 VSD 0.87 ~ 1.2 @ 4A 0.75 ~ 1.2 @ 4A V 反向恢复时间 trr 未提供 12 ~ 20 ns 反向恢复电荷 Qrr 未提供 5 ~ 10 nC 峰值反向恢复电流 IRRM 未提供 未提供 A 分析:两款器件的体二极管正向压降范围相近。VBK1240 提供了明确的反向恢复参数,其trr和Qrr值非常低,这对于同步整流等需要体二极管快速关断的应用极为有利。 五、热特性 参数 符号 MCH3427-TL-E VBK1240 单位 结-壳热阻 RθJC 未提供 未提供 °C/W 结-环境热阻 RθJA 未提供 80 ~ 100 (典型~最大) °C/W 结-焊盘(漏极)热阻 RθJF 未提供 40 ~ 60 (典型~最大) °C/W 分析:MCH3427-TL-E 的数据手册未提供标准热阻参数。VBK1240 提供了完整的结到环境及结到焊盘的热阻数据,便于进行更精确的散热设计。其RθJA典型值为80°C/W,对于SOT-323封装属于常见水平。 六、总结与选型建议 MCH3427-TL-E 优势 VBK1240 优势 ◆ 支持更高栅-源电压(±12V) ◆ 超高速开关,强调1.8V驱动能力 ◆ 更低的栅极电荷(Qg=6nC),驱动损耗小 ◆ 动态参数提供典型值,一致性预期明确 ◆ 更低的导通电阻(RDS(on)),导通损耗小 ◆ 更高的连续与脉冲电流能力 ◆ 更高的功率耗散能力 ◆ 体二极管反向恢复特性优异(trr, Qrr低) ◆ 热特性参数提供完整,便于散热设计 ◆ 封装更小(SOT-323),适合高密度布局 选型建议 选择 MCH3427-TL-E:当应用对超高速开关有明确要求,特别是栅极驱动电压较低(如1.8V/2.5V系统)且需要较高栅压耐受(±12V)的场合。其低Qg特性也有助于降低驱动电路功耗。 选择 VBK1240:当应用优先考虑效率和功率处理能力,需要极低的导通损耗(低RDS(on))和优异的体二极管性能(如同步整流)。其更高的电流定额、更完整的特性数据以及SOT-323小封装,使其在空间受限的DC/DC转换器和负载开关应用中是非常可靠且高效的选择。 备注:本报告基于 MCH3427-TL-E(安森美 onsemi)和 VBK1240(VBsemi)官方数据手册生成。所有参数值均来源于原厂数据手册,设计选型请以官方最新文档为准。测试条件差异可能影响参数直接对比,建议结合实际应用电路进行评估。
微碧
微碧半导体 . 2026-06-29 707

首次亮相2026巴西EletrolarShow|德明利展示面向多元智能终端的全栈AI+存储方案
2026年6月22日至25日,德明利首次亮相巴西圣保罗EletrolarShow,围绕展会主题“All Connected”,现场展出全栈AI+存储解决方案,覆盖高性能消费终端与嵌入式智能设备,为AI时代多终端数据与消费电子应用的高效互联提供核心存储支撑。 一、拉美“芯”动向:AI与电子产业协同下的存储新需求 AI建设提速,消费电子带动终端存储升级 作为拉美消费电子、零售渠道及终端制造资源集聚的重要市场,巴西依托本地电子产业和组装制造基础,持续推动消费电子、嵌入式终端持续升级。据Omdia数据,2025年拉美智能手机出货量达1.405亿部,创历史新高。AI终端发展正推动LPDDR5X、高容量DRAM及高密度NAND等产品需求提升,为设备在性能、容量与成本之间实现更优平衡。 技术与服务协同,强化场景适配能力 面向主控、固件及NAND等存储核心环节,终端客户除关注性能、容量和功耗等基础指标外,也更加重视平台适配、固件调优、可靠性验证及后续技术支持。此次EletrolarShow上,德明利重点围绕高性能消费终端、嵌入式智能设备等多元场景,具备主控芯片、固件算法与场景适配协同能力的全栈AI+存储方案,其场景化价值更加凸显。 二、全栈自研技术匹配细分场景,适配多元终端场景 1. 聚焦高性能消费终端,展示PCIe SSD与DDR内存产品 面向电竞主机、影像设备及高性能笔记本等应用,德明利现场重点展示PCIe SSD与DDR内存模组,并呈现多接口、多形态的产品组合。 l PCIe SSD:覆盖PCIe3.0、4.0、5.0等不同性能规格,并提供M.2 2230、2242、2280等多种形态,可适配台式机、笔记本电脑及高性能AI终端在性能、容量、板级空间和结构设计等方面的差异化需求。其中,PCIe 5.0 SSD支持NVMe 2.0协议,顺序读取速度最高可达14,100MB/s,容量覆盖1TB至8TB,可满足本地模型加载、高码率内容处理及大型应用运行等需求。 l DDR内存模组:产品提供DDR4/5协议,覆盖U-DIMM与SO-DIMM两种形态,可适配笔记本电脑、Mini PC、一体机、桌面PC及工作站等不同终端。其中,SO-DIMM适用于空间受限设备,U-DIMM可面向桌面PC、工作站及相关终端提供配置支持。DDR5产品最高速率可达8000MT/s,可为本地模型加载、多任务并行及高负载运行提供内存支持。 2. 聚焦存储性能、容量与功耗优化需求,呈现完整嵌入式存储解决方案 针对平板、智能穿戴、AI眼镜、IoT设备及其他端侧智能终端,德明利提供eMMC、UFS与LPDDR等嵌入式存储产品。 其中,基于QLC NAND方案的UFS与eMMC产品,依托更高存储密度,可支持单位容量成本优化,适配容量扩展及成本平衡需求。 LPDDR产品覆盖LPDDR4、LPDDR4X、LPDDR5及LPDDR5X不同代际规格协议,可提供不同容量与性能配置,适配低功耗运行、多任务处理及数据缓存等应用需求。 三、布局全球研产与服务网络,为海外市场提供一体化交付支撑 “5+2+N”全球化布局 依托“5+2+N”全球化布局及深圳福田、光明两大智能制造基地,德明利持续完善研发、制造与服务协同网络,形成覆盖多类存储产品的制造、测试与验证能力。面向海外市场,公司已通过海关AEO高级认证,依托供应链协同与柔性交付能力,为客户提供跨境交付、产品选型、样品适配、固件调优及可靠性验证等支持,助力产品导入与项目落地。 面向持续增长的拉美智能终端市场,德明利将结合区域客户需求,持续推进产品适配、供应链协同与技术服务,携手合作伙伴探索更多终端应用机会。
TWSC . 2026-06-29 1120

E2V CCD261配套整机推荐:国产CCD相机UVISI261BUG
一、 产品介绍 北京阿秒科技有限公司的UVISI261BUG是一款专为高端光谱分析和弱光成像应用设计的科学级制冷CCD相机,配备了E2VCCD261传感器,分辨率为2048×261、像元为15µm,覆盖约200–1050nm光谱范围并在800nm处具备很高的量子效率。内置TEC制冷与防结雾结构,有效抑制暗电流和热噪声,适合拉曼、荧光与高光谱等弱信号成像。USB3.0数据接口,图像输出格式支持8/16bit。UVISI261BUG相机具备高量子效率、低噪声的成像能力,适用于拉曼光谱、高光谱成像、弱光荧光等对灵敏度要求极高的科研应用。 二、 量子效率图 三、 相机参数 型号 UVISI261BUG 传感器类型 E2VCCD261 光谱范围 200nm–1050nm 像元尺寸 15μm×15μm 靶面尺寸 30.7mm×4.0mm 帧率&分辨率 12fps@2048×264 内存 512MB(4Gb) 转换增益 7.0e⁻/ADU 动态范围 86.5dB 读出噪声 22e⁻rms 满井容量 459ke⁻ 信噪比 56.6dB 灵敏度 TBD 暗电流 184e⁻/s/pixel@-35℃ 量子效率 95%@800nm 暗信号不均匀性 0.50% 光响应不均匀性 1.50% 曝光时间范围 ≤60mins 增益范围 TBD 快门模式 全局快门 Binning模式 2×2,4×4,8×8,16×16,32×32,64×64 数据接口 USB3.0/GigE 数字IO SHUTTER,TRIG 数据格式 8bit/16bit 制冷温度 -35℃(环境温度20℃) 光学接口 TBD 供电方式 12V5A电源适配器供电 功耗 TBD 尺寸 100mm×80mm×79.25mm 重量 800g 软件 AttosView及LabView,MATLAB 第三方软件包 SDK C,C++,C#,Python 操作系统 Windows,Linux 温度 工作温度–30~45℃,储藏温度–40~60℃ 湿度 工作湿度0–95%,储存湿度0–95% 认证 CE/FCC 四、 外形尺寸 五、 包装清单 序号 标配物品名称 规格 数量 A CCD相机 UVISI261BUG 1 B USB3.0数据线 长度1.5m的A公到B公镀金头数据线 1 C 外触发控制线 长度2m的7芯孔头触发线 1 D 电源线 默认国标电源线 1 E 电源适配器 输入AC100~240V50/60Hz,输出DC12V3A的电源适配器 1 F U盘 内含应用软件、驱动及说明书的U盘 1 六、 应用案例 UVISI261BUG相机非常适合用于弱光及光谱应用场景,包括拉曼光谱、光致发光/荧光成像、高光谱成像,以及其他弱信号检测场景。其卓越的灵敏度能够捕捉用于生物成像的微弱荧光信号,并支持高保真度的材料分析。 材料研究 蛋白质现分离拉曼成像 荧光/光谱显微 天文成像
https://attostek.cn/ . 2026-06-29 707

双核DSP加持的语音前端:NR2048硬件集成与驱动时序深度剖析
前言:当语音交互进入“深水区” 在2026年的嵌入式开发领域,单纯的“能响”已经无法满足市场需求。无论是智能音箱、会议平板还是车载T-Box,客户对语音唤醒率和通话清晰度的要求近乎苛刻。 最近我在负责的一个项目中,选用了Acoustic-S公司的NR2048作为语音前端处理器。这颗芯片虽然体积小(WLCSP封装),但内部集成了双核DSP和复杂的算法库。在实际画板和调试过程中,我发现很多工程师容易在电源去耦、PDM时钟匹配以及复位时序上栽跟头。 今天,我就结合NR2048的Datasheet(V1.0),和大家聊聊这颗芯片在硬件落地时的“坑”与“术”。 一、 架构透视:双核DSP是如何工作的? NR2048之所以能实现85dB的回声消除(AEC)和波束成形,核心在于其内部的双核DSP子系统。 在设计系统框图时,我们需要明确NR2048在整个音频链路中的位置。它通常位于麦克风阵列与主SoC(如高通/MTK/RK芯片)之间。 上行链路(录音/唤醒): 3路PDM麦克风信号进入NR2048 -> DSP进行降噪、AEC、波束成形 -> 输出干净的PCM/I2S数据给主SoC。 下行链路(播放): 主SoC输出参考信号(Reference Signal)给NR2048 -> DSP利用参考信号进行回声消除计算 -> 驱动扬声器。 设计启示: 由于内部运行着复杂的自适应滤波算法,NR2048对电源纹波非常敏感。Datasheet中提到的0.11um工艺虽然降低了功耗,但也意味着对噪声的容忍度在降低。 二、 PCB Layout实战:WLCSP封装的布局艺术 NR2048采用的是25-ball WLCSP (2.966mm × 2.966mm) 封装。这种芯片级封装对PCB工艺要求极高,以下是基于其引脚定义的布局建议: 1. 电源完整性的“生死线”:VDDC引脚 这是整个设计中最关键的一点! 引脚定义: C5脚(VDDC)是内核电压引脚。 Datasheet要求: 必须外接0.1uF(高频去耦)和2.2uF~10uF(储能)电容。 Layout建议: 这两个电容必须紧靠C5引脚放置,且回路面积要最小化。如果VDDC供电不稳,DSP内核可能会出现逻辑翻转,导致算法失效甚至死机。 2. 模拟与数字的“楚河汉界” 虽然NR2048主要处理数字信号(PDM/I2S),但它处理的是模拟世界的声学信号。 接地策略: 建议将VSSD(数字地)通过单点接地或磁珠连接至系统的模拟地(AGND),防止数字开关噪声串扰到敏感的音频采集端。 3. 高速PDM信号的阻抗控制 信号特性: PDM时钟频率最高可达4.096MHz。 Layout建议: PDM_CLK和PDM_DATA属于高速信号。在走线时,务必保证等长匹配,并尽量包地处理,避免跨分割,以防止信号反射导致麦克风数据丢位。 三、 驱动开发:时序与寄存器的“握手”协议 硬件搭好后,软件驱动的配置决定了芯片能否正常工作。NR2048的控制接口(SHI)兼容I2C协议,地址固定为0xC0。 1. 上电复位的严格时序 很多开发者遇到“芯片不响应I2C”的问题,90%是复位时序没对。请严格遵守以下时间轴: 上电: VDD和VDDC电压稳定。 MCLK输入: 提供3MHz~48MHz的主时钟,并等待稳定。 保持复位: RST_引脚拉低,保持至少120μs(建议给到1ms余量)。 释放复位: RST_拉高。 等待启动: 关键! 拉高后必须等待10ms,让内部DSP完成自检和初始化。 下载参数: 此时才能开始通过I2C写入配置参数。 2. 灵活的时钟配置 NR2048支持极其灵活的时钟系统,这对驱动开发提出了要求: MCLK范围: 3MHz - 48MHz。 PLL配置: 如果系统没有合适的音频时钟,可以利用内置PLL。 PDM时钟: 支持1.024/2.048/3.072/4.096MHz四档可选。在驱动中,需根据所选麦克风的规格(如是否支持3MHz以上时钟)来配置相应的寄存器位。 四、 性能压榨:如何开启“满血”模式? NR2048内置了多种工作模式,在调试阶段,我们需要根据场景进行切换: 表格 模式名称 适用场景 配置建议 VR Enhancement 语音助手唤醒 开启此模式可大幅提升信噪比,增强人声特征,但可能会略微改变音色。 Music Mode 纯音乐播放 建议旁路(Bypass)部分降噪算法,保证音频的高保真度。 Hands-free 免提通话 必须开启AEC(回声消除)和NR(降噪),利用双核DSP算力消除85dB回声。 调试技巧: 在进行AEC调试时,务必确保参考信号(Reference Signal)的同步性。如果播放的声音和麦克风录到的参考信号存在较大的时钟漂移,回声消除效果会大打折扣。此时需要检查I2S/PCM接口的时钟同步设置。 五、 总结 NR2048是一颗“小而美”的芯片。它用极小的封装(WLCSP)和极低的功耗,实现了过去需要大型DSP才能完成的语音处理任务。 对于硬件工程师而言,搞定VDDC的去耦和PDM的信号完整性是成功的关键;对于软件工程师而言,严守复位时序和正确配置时钟树则是驱动运行的基石。 在2026年这个万物互联的时代,希望这篇基于Datasheet的深度解析,能帮助大家更好地驾驭NR2048,做出更“听得清”的智能产品。 互动话题: 你在做语音前端设计时,遇到过最头疼的噪声干扰是什么?欢迎在评论区留言讨论!
回声消除
原创 . 2026-06-29 819

ROHM开发出超小安装面积的升降压电源电路板
ROHM(罗姆半导体)宣布,推出新参考板“BD83070GWL-EVK-002”,使用该参考板可更大程度地评估高效率且超低消耗电流的电源IC“BD83070GWL”的特性。 近年来,可穿戴设备、移动设备、IoT设备等电池供电的电子设备已在各种场景中得到广泛应用。为提高设计灵活性并增加新功能,这些设备中所搭载的元器件不仅要实现小型化,还需满足低功耗要求以延长电池续航时间。ROHM始终在推进满足市场需求的电源IC开发工作。在这过程中诞生的升降压电源IC“BD83070GWL”,自2019年投入市场以来,凭借其业界先进的高效率和超低消耗电流性能,为提升电池供电应用的价值做出了贡献。此次,作为更适用于尖端应用的解决方案,ROHM新开发并开始提供实现了超小型安装面积“BD83070GWL参考板”。 “BD83070GWL”是一款升降压DC-DC转换器*1IC,其开发目标是成为通过小型电池等供电的电子设备的“低功耗环保器件的标杆”,实现了高达97%的效率和2.8μA的超低静态电流。 此次开发的参考板旨在实现小型电池供电设备所要求的“升降压电源最小安装面积”而设计,由“BD83070GWL”与线圈、电容器等共5个元器件组成,实现了12.87mm²(3.3×3.9mm)的超小型安装面积。因此,与采用普通升降压电源IC(包括内置线圈型)的配置相比,该参考板在安装面积方面具备显著优势。此外,作为参考设计,ROHM还公布了包括电路图案和物料清单(BOM)等在内的设计信息,这不仅便于客户评估使用,还能轻松扩展应用于客户的量产设计。 新参考板已于2026年6月开始供应(样品价格:13,000日元/个,不含税),并已开始网售。 ROHM将通过提供性能优异的电源IC和参考板,为电池供电应用的进一步小型化和节能化提供支持。 <应用示例> ・可穿戴设备(智能手表、智能戒指、生物感测设备等) ・移动设备(AR/VR设备、智能手机等) ・物联网设备(AI传感器节点、BLE设备、智能锁、小型无人机等) ・小型电池供电设备(无线耳机、数字钥匙、电动牙刷等) <术语解说> *1) DC-DC转换器、降压、升压、升降压 电源IC的一种,具备将直流电(DC)转换为直流电(DC)的电压转换功能。通常有降低电压的“降压”和提高电压的“升压”型产品。“升降压”型产品可根据输入电压切换升压和降压。
ROHM . 2026-06-29 672

政策 | 商务部:将20家日本实体列入关注名单
中国官方6月29日扩大对日本的出口管制,宣布对40家日本实体实施新制裁,其中新增20家日本实体至出口管制管控名单,另新增20家日本实体至关注名单。中国商务部表示,新制裁措施完全正当、合理、合法,旨在坚决遏制日本新型军国主义妄动。 中国商务部星期一在官网发布出口管制管控名单,显示新增20家日本实体。这些实体被指参与提升日本军事实力。 这20家日本实体,分别是防卫研究所(National Institute for Defense Studies)、陆上装备研究所(Ground Systems Research Center)、舰艇装备研究所(Naval Systems Research Center)、航空装备研究所(Air Systems Research Center)、日钢特机株式会社(NIKKO TOKKI )、日钢YPK商事株式会社(NIKKO-YPK SHOJI)、三菱电机防卫与空间技术株式会社(Mitsubishi Electric Defense and Space Technologies)、三菱电机软件株式会社(Mitsubishi Electric Software)、三菱电机工程株式会社(Mitsubishi Electric Engineering)、三菱精密株式会社(Mitsubishi Precision)。 其它被列入的日本实体,还有三菱重工海洋技术株式会社(MHI Oceanincs)、三菱重工相模高科技株式会社(MHI Sagami High-tech)、三菱重工物流技术株式会社(MHI Logitec)、光和兴业株式会社(KOWA KOGYO)、菱重特殊车辆服务株式会社(MHI Special Vehicles Parts Supply & Technical Service)、三菱重工海事技术株式会社(MHI Maritech)、KGM株式会社(Kawajyu Gifu Manufacturing)、日本飞机株式会社(NIPPI)、福图尼奥株式会社(Fortunio)、青木精密工业株式会社(Aoki Seimitsu Kogyo)。 中国商务部公告称,禁止出口经营者向上述20家实体出口两用物项,禁止境外组织和个人将原产于中国的两用物项转移或提供给上述20家实体;正在开展的相关活动应当立即停止。特殊情况下确需出口的,出口经营者应当向商务部提出申请。公告自公布之日起正式实施。 在另一份公告中,中国商务部通报另20家日本实体列入关注名单。这些实体被指无法核实两用物项最终用户、最终用途。 这20家日本实体,分别是: 1. 三井E&S株式会社(MITSUI E&S Co., Ltd.) 地址:日本东京都中央区筑地5丁目6番4号 邮编:104-0045 2. 三井物产航空航天株式会社维修中心(Mitsui Bussan Aerospace Co., Ltd. Maintenance Center) 地址:日本东京都千代田区丸之内1丁目8番2号铁钢大厦22层 邮编:100-0005 3. 泰拉无人机株式会社(Terra Drone Corporation) 地址:日本东京都涩谷区南平台町2番17号A-PLACE涩谷南平台4层 邮编:150-0036 4. ACSL株式会社(ACSL Ltd.) 地址:日本东京都江户川区临海町3-6-4 Hulic葛西临海大厦2层 邮编:134-0086 5. 三菱原子燃料株式会社(Mitsubishi Nuclear Fuel Co., Ltd.) 地址:日本茨城县那珂郡东海村大字舟石川622-1 邮编:319-1197 6. 日本原燃株式会社(Japan Nuclear Fuel Limited) 地址:日本青森县上北郡六所村大字尾驳字冲付4番地108 邮编:039-3212 7. 富士通网络解决方案株式会社(Fujitsu Network Solutions Limited) 地址:日本神奈川县川崎市幸区大宫町1-5 JR川崎塔 邮编:212-0014 8. 日立高端系统株式会社(Hitachi Advanced Systems Corporation) 地址:日本神奈川县横滨市户冢区吉田町292番地 邮编:244-0817 9. 小松产机株式会社(Komatsu Industries Corporation) 地址:日本石川县金泽市大野町新町1番地1 邮编:920-0225 10. 小松NTC株式会社(Komatsu NTC Ltd.) 地址:日本富山县南砺市野尻641 邮编:939-1502 11. 冲电气工业株式会社(OKI Electric Industry Co., Ltd.) 地址:日本东京都港区虎之门1-7-12 邮编:105-8460 12. OKI通信回声株式会社(OKI Com-Echoes Co., Ltd.) 地址:日本静冈县沼津市大诹访字蓟原681-1 邮编:410-0873 13. OKI电路技术株式会社(OKI Circuit Technology Co., Ltd.) 地址:日本山形县鹤岗市宝田1丁目15番68号 邮编:997-0011 14. OKI奈克斯泰克株式会社(OKI Nextech Co., Ltd.) 地址:日本埼玉县所泽市上山口1番地 邮编:359-1153 15. 冲电气工程株式会社(OKI Engineering Co., Ltd.) 地址:日本东京都练马区冰川台3-20-16 邮编:179-0084 16. YDK科技株式会社(YDK Technologies Co., Ltd.) 地址:日本东京都涩谷区千驮谷5-23-13南新宿JEBL 邮编:151-0051 17. 日本电磁测器株式会社(Nihon Denji Sokki Co., Ltd) 地址:日本东京都立川市砂川町8-59-2 邮编:190-0031 18. 丰和工业株式会社(Howa Machinery, Ltd.) 地址:日本爱知县清须市须口1900番地1 邮编:452-8601 19. 细谷火工株式会社(Hosoya Pyro-Engineering Co., Ltd.) 地址:日本东京都秋留野市菅生1847 邮编:197-0801 20. 藤仓航装株式会社(The Fujikura Parachute Co., Ltd.) 地址:日本东京都品川区荏原2-4-46 邮编:142-0063 中国商务部公告称,出口经营者向上述实体出口两用物项,不得申请通用许可或者以登记填报信息方式获得出口凭证;申请单项许可时,应当提交报告,对列入关注名单实体进行评估风险,并提供书面承诺,不将两用物项用于一切有助于提升日本军事实力用途。 公告称,商务部将对关注名单中实体的两用物项出口,实施更严格的最终用户和最终用途审查,涉日本军事用户、军事用途,以及一切有助于提升日本军事实力的其他最终用户用途出口不予批准。 列入关注名单的实体根据中国两用物项出口管制条例规定,履行配合核查义务的,可申请移出关注名单。商务部核实后,可以将其移出关注名单。公告自公布之日起正式实施。 面对中日关系持续恶化,中国商务部今年1月6日公告,全面禁止所有两用物项对日本军事用户、军事用途,以及任何有助于提升日本军事情实力的最终用户出口。 之后,中国商务部2月24日再发公告,首次对日启用“两个名单”制裁,分别将20家日本实体列入管控名单”,另20家列入关注名单。 中国商务部星期一以答记者问的形式发声明称,北京2月24日将三菱造船株式会社等20家日本实体列入出口管制管控名单,斯巴鲁株式会社等20家日本实体列入关注名单,目的是制止日本再军事化和拥核企图。 声明称,2026年2月24日,中方将三菱造船株式会社等20家日本实体列入出口管制管控名单,斯巴鲁株式会社等20家日本实体列入关注名单,目的是制止日本“再军事化”和拥核企图。遗憾的是,一段时间以来,日方不思悔改,反而在错误的道路上越走越远,加紧推动“新型军国主义”步伐,加速“再军事化”,部署进攻性武器,在境外发射进攻型导弹。鉴此,根据《中华人民共和国出口管制法》和《中华人民共和国两用物项出口管制条例》等法律法规有关规定,中方决定: 一是将防卫研究所等20家参与提升日本军事实力的日本实体列入管控名单。列单后的措施主要包括两个方面,一方面是禁止出口经营者向上述实体出口两用物项。另一方面是禁止境外组织和个人将原产于中华人民共和国的两用物项转移或提供给上述实体。正在开展的相关活动应当立即停止。 二是将三井E&S株式会社等20家无法核实两用物项最终用户、最终用途的日本实体列入关注名单。列单后,出口经营者向上述实体出口两用物项,不得申请通用许可或者以登记填报信息方式获得出口凭证;申请单项许可时,应当提交对列入关注名单实体的风险评估报告,并提供不将两用物项用于一切有助于提升日本军事实力用途的书面承诺。许可审查期限不受《中华人民共和国两用物项出口管制条例》第十七条第一款规定期限的限制。商务部将对关注名单中实体的两用物项出口实施更严格的最终用户和最终用途审查,涉日本军事用户、军事用途,以及一切有助于提升日本军事实力的其他最终用户用途出口不予批准。列入关注名单的实体根据《中华人民共和国两用物项出口管制条例》第二十六条规定,履行配合核查义务的,可申请移出关注名单。商务部核实后,可以将其移出关注名单。 中方此举完全正当、合理、合法,旨在坚决遏制日本“新型军国主义”妄动。我们希望日方迷途知返,改变错误行径,真正反思并回到正确轨道。中方依法列单的行为仅针对少数日本实体,相关措施仅针对两用物项,不影响中日正常经贸往来,诚信守法的日本实体完全无需担心。
政策
芯查查资讯 . 2026-06-29 1491

市场周讯 | IBM推出全球首款0.7纳米芯片技术;大众裁员10万人;美光VS苹果,到底谁为存储涨价买单?
| 政策速览 1. 韩国:由于近期韩国半导体行业频繁发生氟气泄漏事故,韩国就业劳动部于26日宣布,对包括SK海力士在内的25家半导体制造企业进行集中安全检查。这是为了预防化学物质泄漏、火灾和爆炸等重大工业事故的先期应对措施。此前6月1日,SK海力士在清州4校园内的M15与M15X连接的气体室发生火灾,导致氟气泄漏,7名工作人员被送往医院,3600多名员工紧急疏散。韩国劳动部计划重点检查在处理易燃液体、气体和急性毒性物质等危险物质时是否采取了适当的安全措施。同时,还将检查防止危险物质泄漏、火灾和爆炸的预防措施。 2. 工信部:工信部装备工业一司负责人郭守刚表示,下一步,将深入贯彻落实党中央、国务院决策部署,稳定和扩大汽车消费。一是加强顶层设计。加快编制出台智能网联新能源汽车产业发展“十五五”规划,推动产业转型升级。二是聚力技术创新,加快新一代动力电池、车用芯片、操作系统、自动驾驶等技术攻关及产业化,让更多创新技术成果惠及广大消费者。三是着力稳定运行。落实好汽车行业稳增长工作方案,配合商务部等部门开展好汽车流通消费改革试点,扎实推进汽车以旧换新,进一步挖掘市场潜力。四是规范竞争秩序。以钉钉子精神持续巩固深化前期工作成效,坚决维护健康有序、风清气正的市场秩序。 3. 国家统计局:1—5月份,规模以上高技术制造业利润同比增长44.7%,拉动全部规模以上工业企业利润增长8.0个百分点,引领作用持续凸显。从行业看,半导体产业链条行业发展向好,电子器件制造方面,光电子器件制造、半导体分立器件制造行业利润分别增长53.8%、40.6%;电子元件及电子专用材料制造方面,电子专用材料制造、电子电路制造行业利润分别增长665.4%、19.7%。医疗设备器材相关行业利润增长较快,口腔科用设备及器具制造、卫生材料及医药用品制造行业利润分别增长26.4%、23.2%。从行业看,全球人工智能技术变革带来高端算力芯片和存储芯片需求爆发,推动电子行业利润高速增长,1—5月份,电子行业利润增长103.9%,对全部规模以上工业企业利润增长的贡献率达43.1%,是规模以上工业企业利润较快增长的重要支撑。 | 市场动态 4. 半导体制造气体:由于炼油及石化工厂开工率下降,导致二氧化碳产量大幅减少。通常情况下,半导体制造商与相关供应商各自都会储备两周二氧化碳用量,合计能维持一个月的库存量,但近期库存已经跌破一个月水平。三星电子每月的高纯度二氧化碳用量约1800至2000吨,SK海力士则需要600至700吨。知情人士透露,这两家巨头的生产尚未受到实际影响,但库存余量持续减少,正全力加紧采购。不过即便提高单价,也难以确保额外供应量。另有工业气体行业人士表示,“由于缺乏原料,我们无法按需供应产品。目前从物理条件来看,短期内没有办法扩大产量。” 5. 贵金属涨价:AI需求拉动叠加供给收紧驱动锡、钽、铟涨价潮。近期,长光华芯方面表示,公司对冲成本压力主要依靠两大路径:一是持续工艺迭代提升芯片生产良率,直接降低单位产品耗材损耗;二是扩大光芯片出货规模,摊薄单件产品分摊的固定生产成本,优化整体盈利与毛利率水平。欧莱新材工作人员表示,公司通过提前储备原材料存货平滑价格波动冲击,同时配套开展套期保值业务,双向对冲原料价格波动风险。市场数据显示,锡半年涨幅40%、钽锭年内涨幅158%、铟年初至6月中旬涨约60%。业内普遍判断,短期来看,全球供需情况并未出现根本性改变,下游市场真实需求保持旺盛,在可预见的未来价格依然会保持相对高位。 6. TrendForce: 由于成熟制程DRAM供给结构性紧缩,迫使Consumer DRAM需求方采用旧世代产品以取得较多的DRAM供应配额,带动近期产业出现新一波旧世代Consumer DRAM颗粒采购需求,使得包括DDR2、DDR3等世代的Consumer DRAM颗粒合约价将延续2026年第一季的上涨动能,预估DDR2第二季合约价涨幅将达约55-60%,第三季预估将进一步上涨35-40%。 7. Counterpoint:全球内存市场预计将在2027年上半年继续保持增长势头,但明年下半年出现价格大幅调整的可能性无法完全排除。该机构预计全球内存市场规模在今年将达到1500万亿韩元,到2027年将进一步增长40%至2100万亿韩元;同时服务器内存占比维持56~57%的高位,相较2025年的37%显著提升。 8. Sigmaintell:今年第二季度消费性DRAM与NAND价格全面走高,其中LPDDR4X 4GB价格较第一季度上涨75%,LPDDR5X 12GB价格则大涨89%,SSD价格较第一季度上涨约50%,UFS价格最高涨幅达100%,显示供需失衡情况仍未缓解。该机构预估,今年下半年DRAM价格涨势可能放缓,尤其低端产品所使用的内存需求将率先降温。 9. 摩根士丹利:预估2027年EPYC(霄龙)Venice处理器产量将达到675万颗,高于英伟达Vera的575万颗,多出约17%。在代工方面,摩根士丹利预估2027年台积电CoWoS封装产能预计升至每月20万片晶圆,英伟达依然是其先进封装的最大客户。 | 上游厂商动态 10. 海光信息:海光信息与同济大学正式签署战略合作协议,并推出国内首个国产千卡工科智算集群。这是国产算力首次以工程专用形态服务高校教育教研,标志着AI基础设施从科学智能向工程智能的关键延伸。 11. 台积电:台积电28纳米主要生产基地Fab 15A月投片量从今年初的20万片,已降至15万片,相较年初减少逾25%。台积电规划更多28纳米产能支持中间层,逐渐退出低毛利订单。 12. 美光:美光科技与Anthropic公司宣布达成协议,将扩大下一代人工智能的规模。美光科技参与了Anthropic的H轮融资。美光与Anthropic将分析内存和存储子系统在不同工作负载中的表现,以及在整个基础设施栈中的交互。该举措预计将推动Anthropic人工智能基础设施中内存和存储性能、能源效率及代币经济性的提升。 13. 三星电子:三星电子宣布,已开发出通用闪存存储(UFS)5.0产品。其基于第九代V-NAND(V9)闪存技术开发而成,特点是针对端侧AI进行了优化。其数据传输带宽为10.8 GB/s,顺序读取速度为10.8 GB/s,顺序写入速度为9.5 GB/s。与上一代UFS 4.1相比,UFS 5.0的传输带宽提升了一倍,能够快速处理海量数据。 14. 芯联集成:芯联集成称,公司与芯联先进、绍兴柯桥芯合先进集成创业投资基金合伙企业(有限合伙)签署《增资及股东协议》,产业基金拟向芯联先进增资20.04亿元,芯联集成拟增资6.62亿元。增资完成后,芯联先进注册资本增至26.75亿元,产业基金持股74.90%,芯联集成持股25.10%。本次投资用于12英寸车规级数模混合芯片制造项目,计划总投资约200亿元。 15. 台积电:台积电已陆续向客户通知调涨晶圆代工价格,涨价范围不仅涵盖市场传言的3nm制程,更扩及7nm及以下所有先进制程,整体涨幅约5%至10%,影响范围涵盖约75%的晶圆营收来源。 16. SK海力士:SK海力士正加大力度开拓通用DRAM市场,同时放缓第六代高带宽内存(HBM4)的量产步伐。该公司表示,由于HBM已占其营收的40%以上,并占据绝对优势,因此正在重新分配资源,以确保从供应严重短缺的通用DRAM市场获得更多营收,而不是盲目地进行产能扩张。 17. 长电科技:长电科技公告称,公司拟通过设立控股子公司,在上海临港新片区建设高端先进封测工厂,投资总额78亿元,其中注册资本预计40亿元。项目分两期建设,一期包括厂房建设、装修工程及设备投资等,计划2028年下半年完成。本次投资旨在加快高端先进封装产能布局,提升综合竞争力。 18. 璇相科技:上海本土企业璇相科技成功研制全球首款可产生百万级原子光镊阵列的超表面芯片,突破了长期制约中性原子量子计算规模化扩展的核心光学瓶颈,为迈向百万比特量级通用容错量子计算补齐前置硬件能力。本次成果由璇相科技与原子量子计算企业中器无量联合攻关,其中璇相科技负责芯片研发,中器无量提供中性原子实验平台及系统级验证支持。该成果为上海中性原子、光芯片与微纳制造等产业链协同攻关的里程碑。 19. 日月光:半导体封测大厂日月光投控营运长吴田玉表示,今年正同步推动15座新建及扩建厂区计划,同时全球首条具经济规模的高度自动化面板级封装(FOPLP)量产线也将于今年底正式投产。随着AI需求远超过市场原先预期,公司资本支出已由原先规划进一步提高至85亿美元,未来仍不排除再度上修。 20. 康宁:康宁推出了下一代玻璃光互连组件Glass Bridge,直接连接光子集成电路(PIC)与光纤。该技术主要面向CPO及玻璃基板半导体封装市场,为下一代AI数据中心架构提供连接。 21. IBM:IBM推出全球首款亚1纳米芯片技术,新芯片设计性能最高提升50%,能效比其2纳米节点芯片提高70%。IBM的新款亚1纳米芯片将近1000亿个晶体管封装在一颗指甲大小的芯片上,密度几乎是2021年发布的IBM2纳米芯片的两倍。该技术得益于一系列结构和材料创新,包括IBM开创性的三维纳米栈架构,展示了即使芯片特性接近原子级,性能和效率的持续提升依然可能。公布的技术结果报告显示,这款新芯片预计将在性能上实现显著飞跃——性能提升多达50%,能效提升70%,满足从生成式人工智能、云基础设施到下一代电子设备的计算能力。鉴于纳米栈技术在亚1纳米节点的早期采用,IBM预计最快五年内可实现量产。 22. 甬矽电子:甬矽电子公告称,公司拟投资建设“微电子高端集成电路IC封装测试三期项目”,计划总投资金额103亿元。项目主要生产产品线包括BUMP、2.5D、FC类、WB类等,建设地点位于浙江省宁波市余姚市,预计建设期96个月。资金来源为自有资金、银行贷款或其他自筹资金。本次投资尚需提交公司股东会审议,且存在土地使用权竞得、行政审批、市场变化等风险。 23. 景嘉微:景嘉微公告称,公司拟使用募集资金对全资子公司景美和锦之源增加借款,用于实施募投项目。其中,景美增加借款不超过2亿元用于“高性能通用GPU芯片研发及产业化项目”;锦之源增加借款不超过5亿元和2亿元分别用于“高性能通用GPU芯片研发及产业化项目”和“通用GPU先进架构研发中心建设项目”。该事项不构成募集资金用途变更,无需提交股东会审议。 24. 东韩半导体:东韩半导体广州基地正式动工建设。项目预计总投资超百亿元,一期主要生产功率半导体模块关键基础材料AMB陶瓷基板,投资约23亿元,达产后年产值将超30亿元。 25. 安森美:安森美半导体已同意以近 70 亿美元的全股票交易收购 Synaptics ,以加强其在物理人工智能技术领域的进军。 26. 尼吉康:全球铝电解电容龙头厂商之一的 Nichicon(尼吉康)向客户发出涨价通知,宣布对全系列铝电容产品实施价格调整。虽然官方并未公布具体涨幅,但市场普遍认为,此次调价将对全球铝电容产业链产生重要影响,并有望带动台系及大陆相关厂商跟进涨价。 27. 联发科:联发科于近日向客户发出“涨价通知函”,宣布将对产品进行涨价。具体涉及哪些产品线及涨价幅度并未公布。联发科表示,针对此次调整的具体内容,负责对应客户的业务经理将会尽快与之联系,会详细说明并解答相关疑问。 28. 扬杰科技:国内功率半导体龙头扬杰科技发布价格调整通知函:决定自2026年7月1日起,全系列产品价格上调10%-15%。本次涨价已是扬杰科技年内第二轮调价。据此前报道,公司于2026年3月下旬通过经销商渠道对内调整新订单报价,主要涉及部分产品。而最新涨价将覆盖全部品类。 29. 高通:高通正就收购美国AI基础设施软件公司Modular进行深入谈判,这笔交易对这家公司的估值约为40亿美元(约合人民币271亿元)。知情人士称,交易最早可能在未来几周内宣布,不能保证最终协议的达成,细节仍有可能发生变化。 30. 瑞萨:全球半导体解决方案供应商瑞萨电子宣布,已完成对软件开发商Pictorus的收购。此次收购为瑞萨带来可加速嵌入式系统开发的云端行为建模平台,将提升Renesas 365平台的价值,助力构建完整数字化流程,推动瑞萨与Altium共同打造电子系统设计与全生命周期管理平台的数字化愿景落地。 | 应用端动态 31.苹果&美光:苹果公司上调Mac、iPad、Vision Pro、HomePod等14款产品的价格,其中MacBook Air的起售价从8499元人民币上调至9999元人民币,涨价1500元;iPad Pro的起售价从8999元上调至10799元,涨价1800元。苹果CEO蒂姆·库克指出,内存行业正在将巨额成本转嫁给消费者,苹果公司不得不提高零售价格,因为(苹果公司独自消化增加的成本)这种情况已难以为继。对于苹果的涨价理由,美光并不买单。美光首席商务官苏米特·萨达纳接受采访时,暗指苹果当前因存储芯片供应紧缺而涨价的主要原因是它自己。 32. penAI:OpenAI和博通发布AI芯片Jalapeño,旨在更快、更经济地运行模型。博通预计将比预期更快地部署OpenAI芯片,博通CEO称,OpenAI的新芯片可节省50%的成本。OpenAI称,Jalapeño从最初设计到生产的量产化,仅用了九个月时间就完成了联合开发,而定制的AI加速器项目代表了我们认为是高性能先进半导体有史以来最快的ASIC开发周期。 33. 大众:大众汽车集团被曝拟把裁员规模扩大至10万人,并关闭四家德国工厂,本次调整或将创下企业成立以来最大规模重组纪录。
芯片
芯查查资讯 . 2026-06-29 1 2 1190
企业 | 以“In Everything, Better”赋能AI生态,TDK将携最新方案亮相2026慕尼黑上海电子展
TDK株式会社(东京证券交易所代码:6762)6月25日宣布,将以全新品牌“In Everything, Better”亮相于2026年7月1日到3日举办的2026慕尼黑上海电子展,全面展示面向AI生态、汽车电子、信息通信技术(ICT)、工业与能源等领域的创新产品,以及系统级解决方案。 TDK长期深耕材料科学、无源元件、传感器、电源、磁性技术、软件与AI等领域,借助此次展会的契机,TDK将整合展示其最新解决方案,助力客户打造更高效、更可靠、更可持续的下一代电子系统,赋能客户,实现“In Everything, Better”。 面向AI与物理AI,连接数字智能与现实世界 AI正从云端走向终端和物理世界。TDK将展示一系列面向物理AI、智能眼镜、XR/AR/VR、人机交互和智能感知的解决方案,基于TDK AI智能眼镜相关技术,客户可打造能捕捉周围环境并提供即时生成式AI洞察的终端产品。 在人机交互方面,TDK将展示触觉反馈与触觉控制技术,包括触觉缩放控制、全身触觉手套体验、运动感知IMU等方案,助力XR/AR/VR、智能眼镜和可穿戴设备获得更自然的交互体验。 在具身机器人方面,高精度、高可靠性的传感器必不可少。TDK将展示超小封装尺寸的TMR传感器、仿人机器人的“内耳”MEMS IMU,以及精准测温的NTC温度传感器。 此外,在工业AI领域,TDK将展示边缘智能驱动的工业设备状态监测与预测性维护方案,由工业机理+轻量化工业 AI 小模型结合构建的智能专家系统,依托边缘端超低时延 AI 推理能力,全域捕捉设备极细微振动、温度等多维体征信号,挖掘人工无法识别的隐性故障特征,构建 7×24 小时不间断在线数字运维大脑,帮助工业设备实现异常提前识别,减少非计划停机频次与时长,持续提升设备综合稼动率与工厂整体运营效能。 TDK紧凑型超声波传感器模块集成了生成器和处理信号的信号处理器及驱动器,并采用超紧凑型封装设计,将一个超声波传感器模块打造成一个具有机械隔离解耦元件和优异EMC特性的坚固且通用的组件。 从电网到核心,支撑AI数据中心高密度供电 面向AI数据中心快速增长的算力与功率需求,TDK提出“从电网到芯片核心”的系统化方案,覆盖AI服务器电源、UPS不间断电源、电池储能系统(BESS)、固态变压器(SST),以及处理器近端负载点供电等关键环节。 相关展品包括超紧凑型焊针型铝电解电容器、MKP DC-link薄膜电容器、贴片型NTC热敏电阻等。并且,TDK将展示合作伙伴基于TDK产品开发的12kW高功率密度高频AI服务器电源PSU。 汽车电子:支持电动化、智能化与座舱体验升级 面向新能源汽车和智能汽车,TDK将展示覆盖电驱、电池、充电、热管理、安全控制和智能座舱的完整产品组合。展品包括定制化CeraLink电容器、CarXield EMC滤波器、电池管理磁性元件、InsuGate变压器,以及用于温度、压力、电流、转子位置检测和稳定控制的温度传感器、压力传感器、霍尔传感器、TMR磁传感器和电流传感器等产品。 此外,TDK还将展示用于制动和热管理的抗杂散磁场霍尔位置传感器和 TMR 位置传感器,以及用于前照灯水平调节和稳定性控制的新一代 MEMS 惯性测量单元(IMU)。 工业与能源:提升高功率系统效率与可靠性 针对工业、能源和基础设施市场,TDK将重点展示EV快充和电源解决方案。重点展品包括薄膜电容器、输入保护器件高压接触器、AC-DC / AC-AC电源、DC-DC电源模块等。 ICT与智能终端:实现更小型、更节能、更智能的设计 面向智能手机、IoT设备、TWS耳机、游戏外设、可穿戴设备和辅助科技应用,TDK将展示用于游戏外设的高精度TMR传感器,用于键盘和声学检测的超低功耗MEMS麦克风,以及结合ToF传感技术、运动传感器以及MEMS麦克风的增强使用便捷性的应用方案。 EMC与系统工程服务,助力复杂电子系统开发 随着汽车、工业、AI数据中心和高功率系统向高频化、高压化和高集成度发展,电磁兼容设计变得日益重要。TDK将展示其EMC解决方案, 介绍其上海C-PAC EMC实验室的工程支持和EMC测试服务能力。 诚邀您莅临2026慕尼黑上海电子展TDK展台(展位号:N1-205),近距离了解TDK全系列创新成果,体验TDK如何以 “In Everything, Better”的理念,从内而外赋能更智能、更高效、更可持续的未来。
机器人
芯查查资讯 . 2026-06-28 1022

日本、委内瑞拉突发强震,美国发布海啸预警
据新华社报道,日本气象厅25日说,当地时间25日7时30分左右,日本岩手县附近海域发生6.9级地震,震中位于北纬40.2度、东经142.3度,震源深度约50公里。 据日本气象厅消息,该国东北地区多地有强烈震感,不过目前无需担心发生海啸灾害。 委内瑞拉发生7级左右地震,美国发布海啸预警 地震发生后,委内瑞拉首都加拉加斯街头 当地时间6月24日,委内瑞拉北部海岸附近发生7.5级地震。委内瑞拉首都加拉加斯有明显震感。 根据哥伦比亚地质局发布的最新地震通报,地震发生的具体时间为格林尼治时间24日22时4分(北京时间25日6时4分),震中位于北纬10.89度、西经67.74度,震源深度小于30公里。目前,相关部门正持续监测地震影响,暂无人员伤亡和财产损失的官方报告。 地震发生后,委内瑞拉首都加拉加斯街头 地时间6月24日,美国地质调查局表示,委内瑞拉莫龙地区发生7.1级地震。美国海啸预警系统在地震后发布海啸威胁警报,委内瑞拉地震震中300公里范围内的沿海地区可能遭受海啸袭击。 据新华社援引美国地质调查局地震信息网消息,委内瑞拉24日傍晚再次发生强震,震级7.5级,震中位于北纬10.40度、西经68.32度,震源深度10公里。距离该国此前发生的7.1级地震,仅仅过去不到一分钟
光明日报 . 2026-06-26 1603

企业 | 安森美官宣收购Synaptics
安森美半导体已同意以近 70 亿美元的全股票交易收购 Synaptics ,以加强其在物理人工智能技术领域的进军。 这家总部位于亚利桑那州的公司表示,到2030年,该交易将使其潜在市场规模增加300亿美元,达到2430亿美元,并增强其智能系统产品组合。这也是该公司迄今为止规模最大的一笔交易。安森美半导体(On Semi)股价盘后下跌约6%,而Synaptics股价上涨约 13%。 “此次交易将立即增加互联计算能力,扩大我们的软件和生态系统覆盖范围,并使安森美半导体能够为客户日益增长的智能系统需求提供更大的价值,”安森美半导体首席执行官哈桑·埃尔-库里表示。 科技公司正竞相收购,以增强自身的人工智能能力。 高通本周收购了基础设施初创公司 Modular,以增强其软件能力。本月,Salesforce 宣布将以约 36 亿美元收购人工智能客户服务平台 Fin 。 安森美半导体 (On Semiconductor) 收购 Synaptics 的交易预计将于 2027 年年中完成。作为收购的一部分,Synaptics 的股东每持有 1 股 Synaptics 股票,将获得 1.350 股安森美半导体的普通股。 Onsemi 将收购 Synaptics,以推动下一代物理人工智能智能系统的开发 安森美半导体和Synaptics今日宣布,双方已达成最终协议,安森美半导体将以全股票交易方式收购新锐科技,交易总企业价值约为70亿美元。该交易采用固定换股比例,每股新锐科技股票可换取1.350股安森美半导体普通股,较安森美半导体和新锐科技过去10个交易日的成交量加权平均收盘价溢价约19%。 此次合并将加速安森美半导体向智能系统领域全球领先地位迈进。通过整合 Synaptics 差异化的边缘人工智能计算产品线以及强大的人机交互和无线连接解决方案组合,安森美半导体有望将其业务能力从电源和传感扩展到智能系统领域,从而为更广泛的终端市场创造更大价值。凭借安森美半导体在汽车、工业和人工智能数据中心领域的专业技术,合并后的平台旨在将安森美半导体定位为物理人工智能领域的中心,并有望在 2030 年前将其市场规模扩大 300 亿美元,达到 2430 亿美元。 “随着人工智能从云端走向物理世界,包括汽车和工业领域,下一阶段的创新将依赖于能够实时感知、决策、行动和适应的系统,”安森美半导体总裁兼首席执行官哈桑·埃尔-库里表示。“向物理人工智能的转变需要强大的计算能力、感知能力、互联计算能力和控制系统无缝协作。收购 Synaptics 有助于安森美半导体在这四大支柱的交汇点上占据有利地位,使我们能够抓住更大的人工智能机遇,并将业务范围从人工智能数据中心扩展到边缘应用。此次交易将立即增强我们的互联计算能力,扩展我们的软件和生态系统覆盖范围,并使安森美半导体能够为客户创造更大的价值,满足他们日益增长的智能系统需求。” Synaptics总裁兼首席执行官Rahul Patel表示:“今天的公告标志着Synaptics在边缘人工智能和物理人工智能领域加速增长并巩固其领先地位的重要一步。我们将与安森美半导体(onsemi)携手,结合Synaptics在人工智能原生计算、连接和人机交互方面的优势,以及安森美半导体在智能电源和传感领域的领先地位,为客户提供涵盖边缘人工智能堆栈每一层的集成解决方案和开发平台,从而深化客户互动并拓展更广泛的潜在市场。全股票交易结构使我们的股东能够参与到未来令人瞩目的增长和价值创造机遇中,我期待与安森美半导体的领导团队合作,共同实现此次合并的全部价值。” 令人信服的战略和财务理由 预计此次合并将带来巨大价值: 从人工智能基础设施到物理人工智能,安森美半导体(Onsemi)已在人工智能基础设施生态系统中占据稳固地位,业务范围涵盖能源网络到数据中心核心。此次交易有望将安森美半导体的业务拓展至智能边缘,使其能够开拓更多终端市场,并提升自身能力,成为电力、感知、互联计算和控制领域集成系统级解决方案的提供商。这一强强联合将助力构建可在物理人工智能应用(包括自动驾驶、机器人和增强现实/虚拟现实)中实时感知、决策、行动和适应的系统。 Synaptics为安森美半导体增加了一个经过验证、可扩展的边缘 AI 连接计算平台: Synaptics 的 Astra 平台结合了专用 AI 处理器和 NPU,可实现多模态智能,并拥有业界领先的无线连接产品组合,涵盖 Wi-Fi、蓝牙和 GPS,以及完整的开源软件栈,可实现快速部署。 互补型产品组合旨在通过规模效应释放显著的收入增长:两个高度互补的产品组合的合并将使安森美能够加速其创新和产品路线图,从而提高每个平台的单价,同时加强与客户的长期合作关系。预计这将增加安森美在高价值、差异化系统解决方案(包括嵌入式知识产权和软件)方面的投入,从而优化产品组合、提升利润率并实现可持续增长。 极具吸引力的财务前景:预计该交易将在完成后的18个月内提升非GAAP每股收益,预计每年可产生2亿美元的协同效应,且毛利率符合安森美(Onsemi)的长期财务模型。安森美(Onsemi)承诺在交易完成期间维持其现有的资本回报政策。 交易详情 根据双方公司董事会一致批准的协议条款,Synaptics 股东在交易完成时每持有 1 股 Synaptics 普通股,将获得 1.350 股 Onsemi 普通股,这意味着 Synaptics 股东在完全稀释的基础上,将持有约 12% 的股份。 作为交易的一部分,Synaptics 董事会的一名成员预计将加入 Onsemi 的董事会。 该交易预计将于 2027 年年中完成,但需获得 Synaptics 股东的批准、必要的监管批准以及其他惯例条件。 安森美半导体和Synaptics重申此前发布的财务展望 作为今日公告的一部分,安森美半导体重申了其于2026年5月4日发布的2026财年第二季度财务展望。Synaptics重申了其于2026年5月7日发布的2026财年第四季度财务展望。
安森美
安森美 . 2026-06-26 2394

面向网络安全场景,德明利工业级存储方案强化数据处理与安全防护能力
AI应用加速落地,数据安全如何保障? 随着AI Agent、企业知识库、智能客服等应用加速落地,数据交互、日志记录及安全审计需求持续增长,网络安全设备的重要性不断提升。 防火墙、入侵检测系统(IDS)、入侵防御系统(IPS)及边缘安全网关等设备需承担数据安全任务,存储系统正成为支撑设备稳定运行的重要基础。 01 系统盘&日志盘方案 满足网络安全设备数据保护需求 针对网络安全设备长期运行需求,德明利提供NS1300系统盘与ES1020日志盘组合方案,具备底层数据恢复能力,可满足系统启动、配置存储、策略加载及安全日志记录等应用场景需求。 Ø 工业级mSATA NS1300系统,pSLC保障关键系统稳定运行 产品采用8GB-32GB pSLC方案,擦写次数超过3万次,平均无故障时间(MTBF)超过300万小时,支持-40℃~85℃宽温运行,可提升关键系统数据的存储稳定性与长期可靠性。 Ø 工业级ES1020系列,稳定写入能力适配持续日志记录场景 产品采用3D TLC颗粒并搭载自研固件,容量覆盖32GB~4TB,并提供2.5寸、M.2 2280、M.2 2242及mSATA等多种形态,可适配不同设备在空间、接口及容量方面的部署需求。 02工业级DDR5/DDR4内存条 满足网络安全设备高可靠内存需求 网络安全设备需要持续完成流量分析、安全策略匹配及数据处理任务,对内存带宽、稳定性与可靠性提出较高要求。德明利推出DDR5/DDR4 UDIMM、SODIMM工业级内存模组,为设备高效运行提供可靠支撑。 Ø 覆盖DDR5与DDR4平台 工业级DDR5内存条速率可达5600MT/s,可适配新一代高性能防火墙和IDS/IPS设备;工业级DDR4内存条速率可达3200MT/s,可满足现有设备升级及多类平台部署需求。 Ø 抗硫化设计,提升复杂环境适应能力 产品采用30μ金手指及抗硫化设计,有助于提升产品在复杂环境下的可靠性与使用寿命。 随着AI应用规模化落地 数据流量与日志记录需求持续增长 网络安全体系对底层基础设施提出更高要求 德明利将持续围绕稳定性、可靠性与场景适配 持续完善工业级存储方案 助力数据安全场景下设备长期稳定运行
TWSC . 2026-06-26 1 1498

罗姆将携多元解决方案亮相electronica Shanghai 2026
全球知名半导体制造商罗姆(总部位于日本京都市)宣布,将于7月1日~3日参加2026慕尼黑上海电子展(electronica Shanghai 2026)。届时,罗姆将在上海新国际博览中心N4馆500号展位,集中展示其面向AI服务器、车载及工业设备等领域的多元化产品与解决方案,以及丰富的应用案例。 当前,AI算力基础设施、新能源汽车和工业智能化正在推动电子系统向更高功率密度、更高能效和更高可靠性方向演进。尤其是在AI服务器和数据中心领域,电源架构正面临大功率、高效率和系统级优化的多重挑战;在汽车电子领域,智能座舱、ADAS和车载高速通信对电源管理与信号传输提出了更高要求;在工业设备领域,小型化、高效率和稳定运行同样成为电源系统升级的重要方向。 面对这些产业趋势,罗姆依托功率半导体和模拟半导体领域的技术积累,不仅提供丰富的硅功率元器件,还持续推进SiC、GaN等宽禁带半导体产品布局,为AI服务器、汽车电子和工业设备等应用提供高效率、高可靠性的产品支持。 在本次electronica Shanghai 2026上,罗姆将设立AI服务器、车载、工业设备及应用案例四大展区,通过展示以下产品和解决方案,全方位呈现在半导体领域的综合技术实力。 AI服务器:面向下一代数据中心电源架构提供高效支持 ·下一代AI服务器的配置 涵盖Si MOSFET、SiC MOSFET、GaN及模块产品在高压直流(HVDC)与50V电源机架中的应用。 ·适用于AI服务器48V电源热插拔电路的100V功率MOSFET 采用8mm×8mm小型封装,兼具更宽SOA范围和更低导通电阻,可满足AI服务器电源热插拔电路对可靠性和低损耗的要求,并已被全球知名云平台企业认证为推荐器件。 ·第5代SiC MOSFET 采用优化的器件结构与制造工艺,在高温(Tj=175℃)下,导通电阻比第4代降低约30%,适用于xEV牵引逆变器及AI服务器电源等大功率应用,计划2026年7月起提供样品。 ·具备业界超低损耗和超高短路耐受能力的1200V IGBT 实现业界超低开关损耗和10µsec超高短路耐受能力,助力车载电动压缩机和工业设备逆变器等应用提升效率与可靠性。 车载应用:助力智能座舱与ADAS系统发展 ·面向SoC的PMIC 罗姆与芯驰联合开发的车载SoC“X9SP”参考设计。该参考设计配备罗姆的PMIC,符合ISO 26262及ASIL-B功能安全等级,可为中高端智能座舱系统提供稳定、高效的电源管理支持。 ·用于汽车多屏显示器的SerDes IC 支持成对双向高速长距离通信,适用于车载信息娱乐系统和ADAS的高速通信需求。 ·搭载SiC模块的三相逆变器参考设计 覆盖5kW~100kW输出功率,提供完整设计数据,可大幅缩减实际设备评估周期。 工业设备:以GaN与AC/DC转换器推动高效电源升级 ·650V 耐压GaN HEMT 罗姆的EcoGaN™系列产品——650V耐压GaN HEMT,已被应用于AI服务器电源等领域,推动工业设备更广泛领域的电源小型化和效率提升。 ·AC/DC用PWM方式DC/DC转换器 面向各类带AC输入接口的工业设备提供可靠的电源解决方案,支持绝缘/非绝缘设计,可帮助客户轻松实现低功耗、高效率、低EMI的电源设计。 此外,罗姆还将设立应用案例展区,集中展示先进产品在实际场景中的应用成果,通过系统化的方案演示,让观众更直观地了解罗姆技术从器件到系统的落地价值。 【展会信息】 时间:2026年7月1日(周三)~3日(周五)09:00~17:00 (3日观众开放时间截止到16:00) 会场:上海新国际博览中心N4馆 展位号:N4馆500号 地 址:上海市浦东新区龙阳路2345号
罗姆 . 2026-06-26 1 1477

Littelfuse推出超低功耗全极TMR开关传感器
TX00AS314TRA可实现高灵敏度磁场感应,电流消耗为1.5 μA,适用于持续运行的电池供电设计 Littelfuse公司 ,今天宣布推出TX00AS314TRA全极TMR开关传感器,这是一款专为紧凑型、电池供电及实现快速响应、高灵敏度和超低功耗运行而设计的高性能磁感应传感器。 该TX00AS314TRA将高精度隧道磁阻(TMR)传感单元与CMOS信号处理电路集成于一体,其中包括片上电压发生器、低噪声放大器、比较器以及施密特触发器,从而实现精准的开关特性、优异的抗噪声能力以及出色的温度稳定性。 器件采用X轴(面内)磁场感应方式,可感知与传感器表面平行的磁场分量,显著提升机械设计的灵活性。其典型工作电流仅为1.5 µA,同时支持高达1 kHz的高速检测能力,非常适用于动态运行且需要长期在线工作的系统,实现可靠的磁场检测(观看视频)。 与传统霍尔效应传感器不同,TX00AS314TRA采用全极性(Omnipolar)检测机制,可同时响应磁铁的N极与S极,从而简化磁体对准要求,降低机械设计约束,并加快系统开发进程。 其精确的动作阈值(Operate Point)与释放阈值(Release Point),结合内建迟滞特性,可在电气噪声较大的环境中仍然实现干净、无抖动的开关输出。 “TX00AS314TRA在磁感应效率方面取得了重大进步,”Littelfuse传感器全球产品经理Julius Venckus表示,“通过全极传感与1.5 μA超低功耗的特性,它使工程师能够设计出更小、更持久的系统,同时也简化了结构设计和电路设计的复杂度。” 主要功能与特色: 超低功耗(1.5 μA典型值):延长持续运行系统的电池寿命 高灵敏度(~14高斯):可对小型磁铁进行可靠检测 全极传感:简化了设计并降低了对准要求 快速响应(高达1 kHz):支持动态和旋转感应 集成的信号调理和迟滞功能:可提高抗扰度和开关稳定性 紧凑型SOT-23-3封装:支持空间受限的设计 市场与应用: TX00AS314TRA针对低功耗、高可靠性和紧凑型的应用进行了优化,适用于以下场景: 楼宇和智能家居自动化(如具备防篡改检测功能、位置检测和限位感应的智能电表) 工业自动化(接近检测) 消费电子产品(如家电、电动工具、电池供电的物联网设备和可穿戴设备) 公用事业领域(包括燃气、水务和热计量系统) 该器件能够以极低功耗实现高精度磁场检测,可帮助工程师设计出体积更小、更智能、更耐用的产品,同时降低了维护需求并提升了系统整体的可靠性。 TX00AS314TRA的推出进一步丰富了Littelfuse TMR传感器产品组合,巩固了其在面向下一代电子产品的高能效传感解决方案领域的市场地位。 TX00AS314TRA全极TMR开关传感器常见问答 TMR技术相比霍尔效应传感器的优势是什么? 与霍尔效应器件相比,TMR传感器具有更高的灵敏度和更低的功耗。这样就可以使用更小的磁铁进行可靠检测,同时在需要持续工作的应用中有效地延长了电池的寿命。 全极感应对设计有什么意义? 全极传感器可检测南北磁极,无需对磁铁进行精确的方向匹配。从而简化了机械结构设计并降低了装配复杂性。 TX00AS314TRA如何延长电池寿命? 该器件的典型工作电流仅为1.5 μA,可在持续检测应用中最大限度地降低功耗。尤其适用于物联网设备、智能电表和可穿戴设备等对续航要求较高的场景。 哪些类型的应用最能体现该传感器的优势? 对于需要连续运行、结构紧凑小型化设计及高可靠性的应用(如智能电表、接近开关和便携式电子设备),该器件能够显著提升系统的性能。 该器件在噪声环境下如何确保开关的可靠性? 器件内部集成的施密特触发器和精确的迟滞特性,可确保稳定的开关行为。这样可以有效地避免误触发,并在电气噪声环境下也能输出干净的数字信号。 相较于传统的磁性开关解决方案,其核心优势是什么? TX00AS314TRA将全极性检测、高灵敏度及超低功耗集成于一体。与传统解决方案相比,这降低了设计复杂性,同时提高了性能。 全球制造业多元化如何支持供应链韧性? 多元化制造减少了对单一地区的依赖,有效应对物流中断、关税变化及区域限制等风险。从而确保更稳定的交付周期、更高的供货可得性和更灵活的全球采购能力。 供货情况 TX00AS314TRA TMR开关提供管状或卷带封装。通过全球任何一家Littelfuse授权经销商索取样品。如需了解Littelfuse授权经销商名单,请访问Littelfuse.com。 更多信息 可通过以下方式查看更多信息:TX00AS314TRA全极TMR开关传感器产品页面。
Littelfuse . 2026-06-26 1463

FCH47N60-F133与VBP16R47S参数对比报告
N沟道功率MOSFET参数对比分析报告:FCH47N60-F133与VBP16R47S 一、产品概述 FCH47N60-F133:安森美(onsemi)N沟道超级结第二代(SuperFET II)功率MOSFET,采用电荷平衡技术,实现低导通电阻和低栅极电荷。耐压600V,连续电流47A,典型导通电阻58mΩ。封装:TO-247。适用于PFC、服务器/通信电源、工业电源等开关电源应用。 VBP16R47S:VBsemi N沟道600V超级结(Super Junction)功率MOSFET,具有低FOM(Ron×Qg)和低输入电容,旨在降低开关和导通损耗。封装:TO-247AC。适用于服务器/通信电源、开关电源、PFC、照明及工业应用。 二、绝对最大额定值对比 参数 符号 FCH47N60-F133 VBP16R47S 单位 漏-源电压 VDSS 600 600 V 栅-源电压 VGSS ±30 ±30 V 连续漏极电流 (Tc=25°C) ID 47 46 A 连续漏极电流 (Tc=100°C) ID 29.7 29 A 脉冲漏极电流 IDM 141 139 A 最大功率耗散 (Tc=25°C) PD 417 417 W 沟道/结温 Tch/TJ 150 150 °C 存储温度范围 Tstg -55 ~ +150 -55 ~ +150 °C 雪崩能量(单脉冲) EAS 1800 1410 mJ 雪崩电流 IAR/IAV 47 未提供 A 峰值二极管恢复 dv/dt dv/dt 4.5 9 V/ns 分析:两款器件在电压、电流和功率耗散等核心最大额定值上非常接近。FCH47N60-F133 标注了更高的单脉冲雪崩能量(1800mJ vs 1410mJ)和雪崩电流额定值,表明其在抗感性负载冲击方面可能具有更强的鲁棒性。VBP16R47S 的二极管反向恢复dv/dt额定值更高(9V/ns vs 4.5V/ns)。 三、电特性参数对比 3.1 导通特性 参数 符号 FCH47N60-F133 VBP16R47S 单位 漏-源击穿电压 V(BR)DSS 600 (最小) 650 (典型) V 栅极阈值电压 VGS(th) 3 ~ 5 2 ~ 4 V 导通电阻 (VGS=10V) RDS(on) 0.058典型/0.070最大 @ ID=23.5A 0.07典型 @ ID=24A Ω 正向跨导 gfs 40 (典型) @ ID=23.5A 16.7 (典型) @ ID=24A S 分析:两款器件的标称导通电阻(RDS(on))处于同一水平(约60-70mΩ),是此类大电流超结MOSFET的典型值。FCH47N60-F133 的阈值电压范围略高,而 VBP16R47S 的阈值范围更宽且下限更低,可能在低栅极驱动电压下更容易开启。FCH47N60-F133 的跨导显著更高。 3.2 动态特性 参数 符号 FCH47N60-F133 VBP16R47S 单位 输入电容 Ciss 5900 (典型) @ VDS=25V 5182 (典型) @ VDS=100V pF 输出电容 Coss 3200 (典型) @ VDS=25V 251 (典型) @ VDS=100V pF 反向传输电容 Crss 250 (典型) @ VDS=25V 1 (典型) @ VDS=100V pF 有效输出电容 (能量相关) Coss(eff)/Co(er) 420 (典型) @ VDS=0-400V 192 (典型) @ VDS=0-520V pF 总栅极电荷 Qg 210典型/270最大 @ VDS=480V,ID=47A 172典型/263最大 @ VDS=520V,ID=24A nC 栅-源电荷 Qgs 38 (典型) 41 (典型) nC 栅-漏(米勒)电荷 Qgd 110 (典型) 72 (典型) nC 分析:VBP16R47S 展现出超结技术的典型优势:在相近的电压条件下,其输出电容(Coss)和反向传输电容(Crss)极低,尤其是 Crss 仅为1pF,远低于 FCH47N60-F133 的250pF。这通常意味着更低的开关损耗和更小的米勒效应,有利于高频应用。VBP16R47S 的总栅极电荷和米勒电荷的典型值也更低,有助于降低驱动损耗。注意:两者测试条件(VDS, ID)不同,直接比较需谨慎。 3.3 开关时间 参数 符号 FCH47N60-F133 VBP16R47S 单位 开通延迟时间 td(on) 185 (典型) @ VDD=300V, ID=47A, Rg=25Ω 37 (典型) @ VDD=520V, ID=6A, Rg=9.1Ω ns 上升时间 tr 210 (典型) 77 (典型) ns 关断延迟时间 td(off) 520 (典型) 156 (典型) ns 下降时间 tf 75 (典型) 93 (典型) ns 分析:VBP16R47S 提供的开关时间参数在更温和的测试电流(6A vs 47A)和不同的驱动电阻下,其开通与关断延迟时间显著更短。FCH47N60-F133 的开关时间数据是在更严苛的满电流条件下测得,更具实际参考价值。此对比受测试条件差异影响极大,仅供参考,实际性能需在相同条件下评估。 四、体二极管特性 参数 符号 FCH47N60-F133 VBP16R47S 单位 二极管正向压降 VSD 1.4最大 @ ISD=47A 0.9典型/1.2最大 @ IS=24A V 反向恢复时间 trr 590 (典型) @ ISD=47A 753 (典型) @ IF=24A ns 反向恢复电荷 Qrr 25 (典型) @ ISD=47A 14 (典型) @ IF=24A μC 峰值反向恢复电流 IRRM 未提供 28 (典型) @ IF=24A A 分析:VBP16R47S 的体二极管正向压降典型值更低(0.9V vs >1.4V)。在反向恢复特性上,FCH47N60-F133 的恢复时间更短但恢复电荷更大;VBP16R47S 恢复时间更长但恢复电荷更小。注意:两者测试电流不同(47A vs 24A),特性差异部分源于此。 五、热特性 参数 符号 FCH47N60-F133 VBP16R47S 单位 结-壳热阻 RθJC 0.3 (最大) 0.3 (最大) °C/W 结-环境热阻 RθJA 41.7 (最大) 40 (最大) °C/W 分析:两款器件的热阻参数基本相同,均具备优异的导热能力,这与它们采用TO-247大封装和相似的芯片技术有关,都能支持高达400W以上的功率耗散。 六、总结与选型建议 FCH47N60-F133 优势 VBP16R47S 优势 ◆ 更高的单脉冲雪崩能量(1800mJ) ◆ 在严苛测试条件(47A)下提供了开关时间数据,参考价值高 ◆ 更高的正向跨导(gfs) ◆ 品牌知名度高,供应链成熟 ◆ 极低的反向传输电容(Crss=1pF),米勒效应小 ◆ 更低的典型总栅极电荷(Qg)和米勒电荷(Qgd) ◆ 更低的体二极管正向压降典型值 ◆ 阈值电压范围下限低(2V),易于驱动 ◆ 作为VBsemi产品,可能具备成本与供货优势 选型建议 选择 FCH47N60-F133:当应用对器件的雪崩耐量和在极限电流下的开关特性有明确的高要求时,或倾向于选择具有长期应用记录的国际品牌方案时。 选择 VBP16R47S:当设计追求极致的高频开关性能(低Crss、低Qg),关注驱动损耗和导通压降,且在成本与供应链灵活性方面有较高要求时。其优异的电容特性使其在LLC、有源钳位等软硬开关拓扑中可能表现更佳。 备注: 1. 参数可比性:本报告中的部分参数(如RDS(on)、开关时间、体二极管特性)测试条件存在差异,直接数值对比可能无法完全反映实际应用中的性能排序。选型时应结合实际工作条件进行评估。 2. 所有参数值均来源于安森美(onsemi)FCH47N60-F133 与 VBsemi VBP16R47S 官方数据手册,设计选型请以最新版官方文档为准。
微碧
微碧半导体 . 2026-06-26 931

锂电保护IC选型要点:小芯片如何影响产品性能与安全
一颗不起眼的芯片,可能会让产品的续航“打骨折”,甚至埋下安全隐患。这样的案例在电子设计中并不少见:某技术论坛上,一位工程师反映其设计的TWS耳机放电时间比标称值少了将近一半,电池容量检测却完全正常。最终排查的结果指向电池保护电路里那颗锂电保护IC,其静态功耗远超合理范围。 这恰好提醒我们,锂电保护IC虽然藏身于电池包深处,但选型上一旦疏忽,轻则续航严重缩水,重则引发安全事故。以下梳理单节锂电池(标称电压3.7 V,满电4.2 V)保护IC的关键技术要点,帮助避开常见误区。 功耗才是续航的隐形杀手 很多开发者选择保护IC时,目光首先落在过充、过放电压阈值上,却忽略了静态功耗和休眠功耗这两个关键参数。 静态功耗(ICC) 是指保护IC正常工作状态下自身消耗的电流,通常在数微安量级。由于它全天候存在,对容量本就紧张的便携设备影响显著。以一个500 mAh的TWS耳机电池为例: 若保护IC静态功耗为10 μA,理论消耗仅占电池容量的极小部分,影响微弱; 但当静态功耗升至50 μA时,仅IC自身每年就多消耗掉数十毫安时电量,加上主控、蓝牙等器件的待机功耗,用户可感知的待机时间会明显缩短。 休眠功耗(IPD) 是电池电压低于过放保护点后,保护IC进入休眠状态时的消耗电流,通常要求低于1 μA。过放后保护IC并未彻底断电,仍需维持监测功能。若休眠功耗过高,会与电池自放电叠加,造成电池进一步过放甚至永久损坏。 选型准则:拿到规格书后,应首先审视静态功耗和休眠功耗,确保它们与产品的续航目标匹配,之后再核实电压阈值等参数。功耗指标不满足要求,可以直接淘汰。 过流保护阈值并非越大越好 过流保护的逻辑是:当放电电流超过设定阈值并持续一定时间后,保护IC切断放电回路。它包含两个核心参数: 过流保护电流阈值(IOV):触发保护的最小电流值; 过流保护延迟时间(tOV):电流超限后需持续的时间,才会真正切断电路。 常见的误区是,把阈值设定得远高于最大工作电流,认为这样就不会误触发。但过大的阈值可能导致保护缺失:假如电池内部出现微短路,电流在未触及过高阈值的情况下持续流动,会让电芯过热、胀气甚至起火。合理的做法是,将过流保护阈值设定为最大持续放电电流的1.2 倍至1.5 倍,为正常瞬态电流留出余量,同时仍能起到保护作用。 延迟时间也要与负载特性匹配。感性负载(如电机)启动瞬间电流大,若延迟时间过短,可能频繁误触发;延迟时间过长,又无法及时阻断持续的过流。通常,过流保护延迟设置在10 ms~50 ms之间,而短路保护的响应则由硬件固定,一般在数百微秒以内。 分清钴酸锂与磷酸铁锂,参数不可混用 锂电池存在多种化学体系,电压特性各异。以常见的钴酸锂(LCO)和磷酸铁锂(LFP)为例,两者满电电压分别为4.2 V和3.6 V左右。若将适用于钴酸锂的保护IC(过充保护阈值通常为4.25 V~4.35 V)直接套用在磷酸铁锂电池上,电池永远无法被充满,容量利用率可能下降10%以上。反之,若给钴酸锂电池匹配磷酸铁锂的参数,过充保护点可能错误地下调,导致充电提前终止或保护失效。 两种体系的关键保护参数大致范围如下: 钴酸锂(LCO):过充保护约4.28 V,过充恢复约4.08 V;过放保护约2.8 V,过放恢复约3.1 V; 磷酸铁锂(LFP):过充保护约3.65 V,过充恢复约3.3 V;过放保护约2.2 V,过放恢复约2.6 V。 选型前,必须明确所用电池的化学体系,并选用参数与之匹配的保护IC。部分器件支持通过引脚或外接电阻适配不同体系,开发时可加以利用。 外接MOSFET的选型同样关键 保护IC本身不直接执行大电流开关,它通过控制外接的MOSFET来导通或关断电路。因此,MOSFET的选型直接关系到效率、发热和可靠性。主要关注点包括: 耐压(VDS):应大于电池最高电压,单节电池通常选20 V或30 V规格; 导通电阻(RDS(on)):直接影响放电损耗。以3.7 V电池、2 A放电为例,20 mΩ的导通电阻会产生约0.08 W热损耗;若改用5 mΩ,损耗降至0.02 W,效率显著提升,发热也更易于处理; 持续电流能力(ID):需大于过流保护阈值,一般留有1.5~2倍裕量; 封装与散热:大电流场景须考虑热阻和PCB散热设计,避免MOSFET过热烧毁。 为节约成本而选用导通电阻偏大的MOSFET,往往会牺牲效率并带来散热难题,得不偿失。
锂电保护IC
厂商投稿 . 2026-06-26 1162
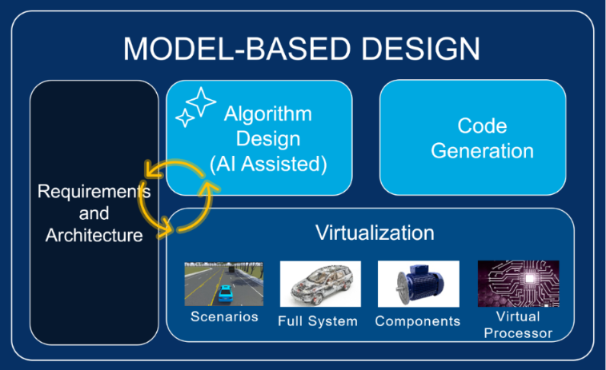
如何构建可信的 Agentic AI:系统优先的方法
随着 Agentic AI 从辅助工具逐步走向流程中的执行角色,“信任”成为无法回避的问题。此类系统能够跨多领域进行推理、调用工程工具,并在满足严格安全、性能和验证要求的复杂系统中不断迭代。当 AI 同时承担规划、执行与迭代职责时,即便单个输出看似正确,在整体系统中也可能引发意外行为——这是由于系统组件之间的交互会带来新的失效模式。 在软件定义产品中,这类风险并非源自 AI 的自主行为,而更多源于工程流程缺乏可执行的系统级行为表达。目前,软件相关问题已占汽车召回的五分之一以上,类似的集成问题在其他软件定义系统中同样普遍存在。例如,一个通过单元测试的时序调整,在集成到依赖原始行为的控制回路后仍可能导致系统异常。这些问题的根本原因在于,系统级行为在演进过程中未能持续、一致地进行评估。 系统模型将需求、设计、虚拟化与代码连接起来,实现贯穿整个开发流程的执行能力 为什么系统上下文对 Agentic AI 至关重要 工程团队通过采用“系统优先工程”来构建对 Agentic AI 的信任。这一理念强调在开发早期就关注系统级行为,并以基于模型设计(Model-Based Design)为基础。通过使用可执行系统模型作为共通载体,取代基于假设的信息传递,工程师与 Agentic AI 能够共享统一的系统级参考。这些模型贯穿机械、电气与软件领域,提供一致的行为基准,使 AI 不仅依赖抽象需求,而是扎根于成熟的工程流程中,从而在团队扩展与功能迭代过程中保持行为一致性的理解。 系统优先工程为 Agentic AI 提供了结构化的运行环境,同时降低了意外风险。领先团队通常在硬件实现之前就对系统进行虚拟化,并通过自动化流程持续评估系统模型,这些流程通常依托 CI/CD 管道和闭环仿真实现。Agentic AI 通过协调并主动执行模型、测试与验证活动,加速整个开发流程。它通过调用基于模型设计中可自动化的部分,遵循既定流程模型来完成各项工程步骤。在这一环境中,能够在早期就针对系统行为对由智能代理驱动的变更进行评估,从而避免在后期集成阶段暴露问题。工程师依然负责监督代理过程与结果,并承担最终验证与确认(V&V)的审核职责,确保 AI 执行过程始终以系统级证据为依据,而非孤立输出。 确定性验证构建信任基础 对 Agentic AI 的信任源于可重复性,其核心在于确定性验证,即能够提供一致、可审计的证据,用于追溯与安全评审。系统优先工程团队以可执行规范取代易产生理解偏差的文档,这些规范贯穿系统架构与设计、代码生成到测试全过程,确保每一项由代理驱动的变更都能依据同一系统行为进行评估。 在软件可以日更迭代、而硬件开发周期以周甚至月计的背景下,依赖硬件进行验证已不可行。团队通过持续仿真已建立的系统模型,减少对昂贵硬件测试的依赖。所有软件、架构及控制逻辑的变更,都在完整系统表示下进行确定性验证。这使团队能够在问题进入硬件阶段之前,就发现系统级故障,例如时序未达标或内存占用异常。基于这种可重复的验证证据,团队能够在任务复杂度不断提升的情况下,对 Agentic AI 的输出进行审查与认证。 系统优先工作流连接模型、代码与验证,实现从设计到部署的持续执行 Agentic AI 在可验证系统中的执行 在通过确定性验证建立信任之后,下一步要解决的是 Agentic AI 如何在该环境中运行。在工程流程中,Agentic AI 主要作用于系统模型、组件模型、测试用例及场景变体等工程资产,其中部分内容可能由生成式 AI 生成。虽然 Agentic AI 也可以参与这些资产的生成,但其核心价值在于在工作流中对这些资产进行操作,并通过独立验证来确保其正确性。例如,一个代理可能调整了某个通过测试的时序参数,但却导致下游控制器误读原本按既定频率接收的信号。 为避免此类问题,Agentic AI 必须运行在明确区分“生成”与“执行”的工程流程中。它本质上是在既有基于模型设计流程中的自动化程度提升,这些流程涵盖仿真、代码生成、分析与测试,并可通过如 Simulink® Agentic Toolkit 等工具实现。系统优先工程定义了哪些内容可执行、可验证;而 Agentic AI 则决定在何时以及如何执行这些自动化步骤。 System-First Engineering 奠定基础 基于系统优先工程引入 Agentic AI 是一个渐进过程。工程团队通常从单一功能和小规模团队入手,通过自动化仿真与测试流程验证系统模型,再逐步推广至相关团队。Agentic AI 负责生成并评估变更,而验证流程确保每一项变更在推进前都经过测试。许多团队会构建统一的初始环境,使各团队共享相同的 CI 流程与验证约束,从而避免碎片化应用,例如某些模型仅存在于单一团队且缺乏持续集成或跨学科应用。 这一统一环境也确保 Agentic AI 从一开始就运行在一致的系统级上下文中,而非孤立引入。其结果是在不割裂工作流程的前提下实现可靠扩展,并为建立对 AI 驱动执行的信任奠定基础。 当团队将单一领域误当作“系统”的全部时,软件定义产品开发的规模化便会失败。Agentic AI 的信任同样在这种情况下崩塌。构建可靠产品始终依赖一系列不可妥协的原则,而这些原则同样适用于 Agentic AI: 如果不是可执行模型,那只是观点。代码可以定义单个组件的行为,而可执行系统模型则提供组件在系统层面如何交互的统一参照。 如果某项变更在完整系统中验证失败,就不能交付。局部测试通过的改动,依然可能在系统其他部分引入退化问题。 如果行为未通过真实工况仿真验证,那只是猜测。故障模式将被推迟到硬件测试或实际部署阶段才被发现,代价高昂。 如果需求没有与模型、测试和数据建立关联,就会与系统实现脱节。这使得难以追溯哪些模型或测试验证了特定需求,从而导致实现偏离最初设计意图。 如果代理驱动的变更无法通过可执行模型、确定性分析以及人工审查验证,就必须被拒绝。缺乏这些验证,团队无法在审查与审批过程中说明变更内容、变更原因以及其是否满足系统级要求。 工程师始终掌控代理驱动的变更,通过审查结果并基于系统级证据进行最终确认。一旦出现问题,将其视为常规工程问题,通过模型与测试进行追溯、诊断并修正,然后再继续推进。 具备合适工具、流程与方法来构建系统的团队,能够交付可靠的软件定义产品,并在不丢失系统级信心的前提下引入 Agentic AI。而缺乏这些基础的团队,则将在系统集成、认证或召回阶段遭遇 Agentic AI 能力的限制。 作者:朱天一,MathWorks 高级产品经理
MathWorks . 2026-06-26 833
- 1
- 10
- 11
- 12
- 13
- 14
- 500