
市场 | 上半年合约价涨幅皆破100%,2H26结构性缺货将带动NOR Flash、SLC NAND价格持续上涨
根据TrendForce集邦咨询最新存储器产业研究,由于存储器大厂的产能规划持续倾向HBM、高层数3D NAND等高附加价值产品,挤压NOR Flash、SLC NAND依赖的成熟制程产能,然而因需求稳定,已推动2026上半年NOR Flash、SLC NAND累积合约价涨幅分别突破100%。由于供应商未有大规模扩产计划,预估下半年两项产品的价格将随供需紧张而继续调升。 TrendForce集邦咨询说明,NOR Flash的核心价值为实时执行(XIP)能力与高稳定性。在汽车电子领域,随着自动驾驶辅助系统、智能座舱等功能升级,车载固件容量快速膨胀,高密度NOR Flash已成关键元件。边缘AI设备部分,过去容量仅需数十MB的系统程序,因AI模型本地化运算需求增加,需求往往呈倍数增长,带动256Mb以上高容量NOR Flash需求快速提升。此外,在工控、卫星通信及航天设备等领域,NOR Flash的高可靠特性难以由其他技术取代,形成稳定且高毛利的需求基础。 SLC NAND则因高P/E寿命、极低错误率、长期数据保存能力、宽温运作特性,成为许多高可靠度系统的唯一选择。近年智能工厂、机器人、自主移动设备以及高端网通交换器等产品大量导入实时推理(Inference AI)功能,推升对高可靠度存储系统需求。企业级Server与数据中心则持续使用SLC NAND作为操作系统启动盘(Boot Drive)及高频写入缓冲区(Write-intensive Buffer)。在医疗影像设备、军工电子、航天系统等对数据错误几乎零容忍的环境,SLC NAND更有不可替代的市场地位。 TrendForce集邦咨询表示,2026上半年终端对存储器产品需求逐步恢复,加上AI相关应用快速成长,大幅消耗市场有限的供给,NOR Flash率先出现交期延长与配货(Allocation)现象,合约价平均累积涨幅将达100-120%,高容量产品涨势更显著。SLC NAND则因部分国际大厂陆续退出小容量及成熟制程产品,供给明显减少,而工控、车用及网通客户又开始建立长期安全库存,导致第二季出现明显备货潮,上半年价格平均累积涨幅将达130-150%。 分析2026下半年价格走势,由于全球主要供应商目前皆以制程微缩、提高良率及优化单位晶圆产出为主,无新增产能计划,预期下半年开始,高度依赖长生命周期产品的车用与工控市场将形成长期缺货风险。其中,高容量NOR Flash有车用电子与边缘AI需求支撑,预计下半年价格仍有60-65%以上的调涨空间。而中低容量NOR Flash则可能受供应商产能逐步释放影响,价格涨势趋缓,部分产品甚至进入高档盘整阶段。 SLC NAND虽然多数产品需求未明显增加,供应来源却持续减少,预估2026下半年价格涨势虽将收敛,但仍有70-75%的上涨空间,工业、车规级产品涨势可能更强。 TrendForce集邦咨询指出,为避免价格失控影响合作关系或促使客户寻求替代技术,主要供应商未来更可能通过长期供货合约(LTA)与选择性接单策略管理供需,意味未来市场竞争的核心将不再只是价格,而是供货稳定性与客户关系管理能力。
存储
TrendForce集邦 . 2026-06-16 3948
产品 | 芯唐南京 CM3031 系列量产,M33 内核 MCU 扬帆起航
芯唐南京重磅推出NuMicro® CM3031系列32位微控制器,搭载Arm Cortex-M33高性能内核,集成丰富的通用外设与差异化特色外设,广泛适配多行业智能终端开发,为工业控制、智慧建筑、新能源设备等场景,提供高性价比、高稳定性的核心控制解决方案。 内核焕新升级,硬件安全能力拉满 CM3031系列搭载主流Arm Cortex-M33内核,主频高达180 MHz,配置最大512KB Flash、320KB RAM,原生支持DSP指令集与FPU浮点运算单元,大幅提升数据运算与信号处理效率,可高效应对复杂算法运算、高频实时数据采集、高精度设备控制等各类复杂任务。 安全层面,标配Arm TrustZone硬件安全技术,可实现硬件级固件加密、安全启动、软硬件资源隔离防护,有效规避固件篡改、核心数据泄露、程序恶意入侵等风险,充分满足工业自动化、物联网终端等高等级安全应用需求。 差异化外设集成,简化产品开发设计 CM3031系列不仅搭载多组UART、SPI、I2C等通用通信接口,还集成多款高价值差异化外设,兼顾高速传输性能与新型场景适配能力,全方位优化产品硬件架构、降低软件开发难度。 I3C接口:兼容传统I2C协议,支持SDR、HDR-DDR双传输模式,最高传输速率可达25Mbps,适用高速传感器、智能模组等外设通信场景; CAN FD接口:原生支持2路CAN FD总线,传输速率快、容错性强,完美适配工业总线通信、车载智能设备等高可靠性通信场景; USB 2.0高速接口:内置PHY,支持HOST、DEVICE、OTG全功能模式,可满足数据传输、外设拓展等多元化需求; LLSI/ELLSI硬件灯控接口:专为ARGB灯效设计,最高可支持11通道同步输出,适配各类智能氛围灯、阵列灯效产品开发; 48路高性能PWM输出:通道资源充足、控制精度高,可广泛应用于舞台灯光多电机调速、RGBW全彩灯珠精准调光等场景。 全场景适配赋能,助力终端智能化升级 凭借Cortex-M33高性能内核、丰富差异化外设、优异的环境适应性与硬件安全能力,CM3031系列可覆盖多行业核心应用场景,助力终端产品高效完成智能化升级迭代。 工业控制领域:适配工业IO模块、小型PLC、智能传感器采集终端、工业控制面板等设备。凭借丰富的工业通信接口、宽温工作特性、强抗干扰能力与超高运行稳定性,可适配工厂复杂工况,保障设备不间断稳定运行。 智能灯光灯效产品:依托多路高精度PWM与专用LLSI灯控接口,可轻松适配RGB、ARGB、RGBW各类灯控方案,极大简化客户软硬件设计流程,缩短产品开发周期,广泛应用于舞台灯光、智能氛围灯、商用亮化设备等产品。
新唐
新唐MCU . 2026-06-16 1183

产品 | 无线协议栈“魔法师”——TL3228的多协议并发模式探秘
你是否遇到过设备需要同时连接手机(蓝牙)与网关(Zigbee/Thread)的场景?TL3228的多协议并发模式让你告别选择困难。 真正的并行处理:芯片在硬件层和协议栈层均支持多标准无线协议的同时运行(Concurrent Mode)。这意味着: 一个智能门铃可以同时作为蓝牙Mesh节点(直连手机)和Thread边界路由器(接入Matter网络)。 一个电竞手柄可以保持与接收器(2.4GHz私有协议)的低延时连接,同时周期性地广播状态或通过Bluetooth® LE连接手机App进行配置。 典型并发组合:TL3228官方SDK已支持以下组合(并可根据需求定制): Bluetooth® LE + Zigbee Bluetooth® LE + Thread Bluetooth® LE + 2.4GHz专有协议 双核RISC-V MCU的算力优势在此模式下充分发挥:一个核心可专用于运行复杂的应用或AOA/AOD算法,另一个核心负责运行底层无线协议栈,再辅以充沛的内存资源,实现真正的无缝协同。让您的产品实现更灵活的网络拓扑和用户体验。
泰凌微
泰凌微电子 . 2026-06-16 1092

产品 | 方寸之间,智启无界新生——村田中国将携四大领域创新产品亮相2026慕尼黑上海电子展
2026年7月1日至3日,行业领先的综合电子元器件制造商村田中国(以下简称“村田”)即将以“方寸之间,智启无界新生”为主题,亮相2026慕尼黑上海电子展(Electronica China 2026),展位位于上海新国际博览中心N1馆300号。本届展会上,村田将聚焦通信及计算、车载、工业及环境、健康四大核心应用领域,并系统展示面向人形机器人的元器件解决方案,呈现微小元器件驱动数智世界的无穷可能。 【参展亮点前瞻】 通信及计算:从数据中心到边缘设备,夯实算力基石 人工智能与大数据的高速发展,正推动数据中心、边缘设备及光通信基础设施等加速迭代。算力提升对电源效率、信号完整性及热管理等均提出了前所未有的挑战。村田将展出覆盖从云端到边缘的全链路产品及解决方案,包括小型化高性能的电容、电感、热敏电阻、集成封装技术、大功率电源模块、高密度POL电源模块及整机柜供电方案等,助力AI服务器及数据中心实现高效供电与高速信号传输。面向光模块市场,村田还将带来电荷泵芯片、静噪元件及硅电容解决方案,支持更紧凑、更低功耗的光电设计。此外,村田还将展示包括UWB、GNSS通信模块、均热板、射频连接器、天线等多样的高性能创新产品,覆盖从定位追踪到可穿戴等不同应用场景下的通信需求。 车载:智电融合,驱动安全与体验双升级 随着汽车产业加速向智能化和电动化转型,未来出行方式正在发生根本性改变。这一变革对各类车载电子元件性能提出了更高标准的要求——更稳定、反应更快、传输能力更强的技术支撑,特别是在高级驾驶辅助系统(ADAS)、电动动力总成、智能座舱等关键领域。在ADAS领域,村田将展示包含小型化高容电容、低ESL电容的完整电容方案、可满足严苛温度要求的高可靠性EMI静噪滤波器与功率电感,以及能够有效提高自动驾驶影像利用的车载摄像头用超声波传感器等产品。动力总成方面,村田的高压电容方案及高可靠性热敏电阻、晶体谐振器,为新能源动力系统提供稳定支持。而车载Wi-Fi™/Bluetooth®/V2X通信模组、低频天线及面向激光雷达的硅电容等产品,则从互联、自动、共享、电动(CASE)角度,全方位赋能汽车技术创新,助力提升驾驶的智能化体验。 工业及环境:感知细微,赋能绿色智造 在工业智能化升级浪潮下,现代化工厂正加速导入5G、AI、IoT等前沿技术,全面构建数字化系统。本届慕尼黑展,村田将带来振动传感器、高精度惯性传感器、AI工业相机及面向机械臂与视觉系统的静噪元件等产品,展示精密元件如何为设备安全与产线智能化提供关键支持。与此同时,面向可持续发展与循环经济转型需求,村田正积极致力于清洁能源领域的技术创新。针对太阳能发电领域,村田将展示适用于光伏逆变器与储能系统的陶瓷电容、静噪元件、电源模块及高可靠性热敏电阻,以高性能产品帮助清洁能源系统高效稳定运行。 健康:无形守护,助力医疗智慧化 植入式医疗、远程医疗、可穿戴设备及智慧医院管理的迅速发展,需要兼具微型化、高可靠与低功耗的元器件支撑。村田将展示针对医疗场景的多项解决方案:高可靠性MLCC可支持植入式设备对小型化、高可靠性和低功耗设计的需求;村田AC-DC电源及高压电阻满足大型医疗设备对稳定供电与脉冲防护的需求;微型RFID标签可附着于手术器械,实现全程追踪与院内管理;压电薄膜、气压传感器与微型风扇则为人机交互与可穿戴设备提供更多创新可能。 人形机器人:元器件集成方案,驱动灵活运动 人形机器人正从实验室走向产业化,关节驱动、姿态感知、电源管理及无线通信等环节均对元器件的集成度与动态响应提出了新要求。村田将重点展示其传感器、电容、电感、电池、通信模组等产品在人形机器人关节控制、平衡反馈和无线互联中的实际应用。现场观众可细致了解微小元器件如何赋予机器人灵活、稳定、智能的运动能力。 7月1日展会首日,村田还将携手行业媒体【AI汽车制造业】进行现场直播。届时通过村田官方视频号,或关注媒体,即可同村田的资深技术专家就行业趋势及村田的创新产品进行即时交流。 此外,经典的村田“顽童”机器人也将同步亮相展台,与现场观众进行互动。诚邀您莅临上海新国际博览中心N1馆300号村田展位,同村田共同探讨电子元器件如何于方寸之间,开启无界新生的未来。
村田
xcc . 2026-06-16 1498

企业 | 总投资1.5亿美元,泰科电子汽车事业部南通制造基地正式投入运营
连接和传感领域的全球行业技术企业泰科电子(TE Connectivity,以下简称“TE”)宣布,其汽车事业部位于南通市崇川区的全新先进制造基地(以下简称“TE 汽车事业部南通基地”)正式投入运营。该基地总投资额达1.5亿美元,是TE在华布局的又一核心制造枢纽,将进一步深化公司的本土化战略、提升其服务中国新能源汽车与智能网联汽车产业的能力。 开业仪式上,南通市委副书记、市长张彤,南通市政府副市长、崇川区委书记胡拥军,南通市崇川区委副书记、区长吴佳华,崇川区委常委、崇川经济开发区党工委书记闫静翔及市、区各部门负责同志,与TE汽车事业部亚太区高级副总裁兼总经理沈伟明、TE汽车事业部及工业与商业运输事业部中国区副总裁兼总经理孙晓光、TE中国区总经理兼亚太区人力资源副总裁张超、TE汽车事业部亚太区运营副总裁于毅等管理层代表、重要客户及合作伙伴代表共同见证了这一时刻。 南通基地总建筑面积约3.99万平方米,为当地创造上千个优质就业岗位,主要生产新能源汽车高压连接器、汽车高速高频数据连接器等核心产品。其中,南通基地是TE在中国唯一集成辅助驾驶浮动摄像头和车载Type-C数据线产品的生产基地。为实现这些前沿产品落地,南通基地集成了注塑、设备加工及全制程组装的全链路能力。同时,全面对标TE成熟的制造执行系统(MES),引入智能物流、智能追溯与自动防错等先进技术。 在可持续发展方面,南通基地按照“星级节能工厂”标准建设,配备高效光伏与雨水回收系统;同时,在生产过程中基本实现了注塑原材料的循环回收利用,做到了生产清洁化与资源高效利用。 这一系列在工程技术、先进制造及绿色低碳领域的全面布局,将大幅提升TE汽车事业部在中国的先进制造水平与供应能力,更好服务于中国新能源汽车及智能网联汽车产业的发展需求。 南通市委副书记、市长张彤在致辞中表示 南通交通区位独特、资源禀赋优越、产业基础扎实,肩负着打造全省高质量发展重要增长的职责使命。而外资企业是南通经济发展的重要力量,泰科电子南通先进制造基地的开业必将带动全市汽车及关键零部件产业链竞争力全面提升,为南通打造面向科技前沿的现代工业名城注入新的动能。 TE汽车事业部亚太区高级副总裁兼总经理沈伟明表示: “中国是TE重要的战略市场之一,也是我们全球创新和制造的关键引擎。投资南通基地,不仅体现了TE深耕中国市场的坚定决心,也标志着我们在中国乃至亚太地区的制造能力和供应链韧性迈上了新台阶。未来,这座工厂也将成为一个充满活力的人才平台,培养立足中国、走向亚洲、赋能全球的行业人才,为全球客户与产业创造长远价值。” TE汽车事业部及工业与商业运输事业部中国区副总裁兼总经理孙晓光表示: “南通基地的落成离不开南通市、崇川区各级政府的鼎力支持。南通拥有得天独厚的区位优势、人才储备和产业生态。与南通的协同发展,将使我们更好地融入长三角一体化进程,以更强大的本土先进制造能力,快速响应中国市场和客户的动态需求,进一步赋能中国汽车产业。” 随着南通基地的正式投产,TE汽车事业部在中国的战略布局进一步完善。未来,TE汽车事业部将继续秉承“扎根本土,持续投资,深度创新,互利共赢”的理念,以世界级的制造能力和工程技术实力,深度参与并推动中国乃至全球汽车产业的智电化转型。
扩产
泰科电子 TE Connectivity . 2026-06-16 1785

产品 | 极简全能、轻量化开发利器:新版GD-Link V3核心亮点解析
GD-Link V3是兆易创新专为GD32全系列MCU打造的一体化调试烧录工具,主打极简操作、全能集成、稳定高效,完美适配研发调试与量产烧录全场景,其独家单线协议功能更是区别于传统工具的核心优势,大幅降低MCU开发门槛。 核心特色:单线One-Line协议 传统调试工具依赖多线对接,接线繁琐易出错、占用硬件资源。GD-Link V3搭载专属单线(OL)烧录协议,仅需单根信号线,即可完成芯片烧录与调试工作。该功能适配GD32M531电机控制专用芯片,极大精简硬件布线,适配小型化、高精简度的产品设计,省心又高效。 一机全能,覆盖全开发场景 GD-Link V3集成多重实用功能,无需切换多款工具,一台搞定全程开发。原生兼容Keil、IAR、Eclipse等主流开发IDE,即插即用、无需复杂配置。支持在线调试、U盘拖拽烧录、离线一键量产烧录,可实现BOOT+APP多文件批量烧录,满足日常研发与批量生产需求。同时搭载UART、I2C、CAN多协议网桥及SWO日志输出功能,快速排查程序问题,调试效率大幅提升。 超低门槛,新手友好易用 工具主打轻量化极简设计,Win10/11系统免驱动直连使用,仅Win7需简易安装驱动。配备LED指示灯+蜂鸣器声光提示,设备状态、烧录结果一目了然。创新的虚拟U盘拖拽烧录,无需开启软件,拖拽固件即可完成烧录,操作零难度。同时支持1.8V/3.3V/5V多档位电压输出,适配各类规格GD32芯片,兼容性极强。 原厂适配,稳定可靠全覆盖 作为兆易创新原厂工具,GD-Link V3对全系GD32芯片无缝兼容,支持固件一键升级,持续适配新芯片、修复优化功能。设备支持工业级机器信号触发烧录,可对接自动化产线,直连电脑即可保障稳定传输,有效规避断连、烧录失败等问题,兼顾个人开发与工业量产场景。 目前,该产品配套的技术资料、上位机软件、固件资源已全部完备,且工具已正式量产出货,状态稳定。感兴趣的开发者与企业用户可随时咨询申请,快速投入项目开发使用。
兆易创新
GD32MCU . 2026-06-16 1351

企业 | 何茂军出任安森美中国区总经理
6月15日,功率半导体及图像传感器大厂安森美(onsemi)宣布,何茂军博士于6月15日加入安森美,担任中国区系统产品副总裁兼中国区总经理。 作为一位在电力电子领域深耕超过20年的行业老兵,何茂军博士在电动化出行及工业能源系统方面积累深厚。他毕业于新加坡南洋理工大学,获电气与电子工程博士学位,并拥有中国高校的电气工程硕士及学士学位。其职业生涯始于博世集团,后成功创立并推动了一家创业公司发展,因此兼具跨国企业与创新业务环境的双重管理经验。 安森美近年来在汽车电动化、工业能源、智能电源等领域的布局日益深化。何茂军在电动化出行及工业能源系统方面的深厚积累,与安森美的业务重点高度契合。 安森美表示,在新岗位上,何茂军博士将推动安森美在中国的系统级产品能力建设,促进系统创新,并深化客户合作。同时,作为中国区总经理,他将支持公司的中国战略推进,在产业及相关合作事务中发挥重要作用。 此次任命也正值安森美加速推进中国市场战略的关键时期。安森美强调,这体现了安森美的长期承诺——持续加大对中国创新生态的投入,强化本地化能力以更好服务中国客户,并推动本地创新成果走向全球。
安森美
芯智讯 . 2026-06-16 1036

涨价 | 立昂微、辉芒微、骏晔宣布涨价
近日,多家电子元器件企业发布产品价格调整通知,涉及功率芯片、8位MCU、无线射频模块等品类。相关通知显示,上游原材料价格上涨、供应链成本抬升及产能紧张,是本轮调价的主要原因。 杭州立昂微电子股份有限公司在通知中表示,近期受上游原材料价格持续上涨影响,公司综合生产成本大幅增加。尽管已通过提升运营效率、优化流程、改进生产工艺等方式降低成本,但仍难以覆盖上涨压力。经综合研判,公司决定对功率芯片业务全系列产品进行适度上调,调价幅度为10%至15%。通知显示,该价格调整自2026年6月15日起执行,当日及后续发出的货物均按新价格结算。 辉芒微电子(深圳)股份有限公司也发布通知称,受前期全球半导体上游原材料价格大幅攀升影响,近期上游产能紧张,导致成本进一步上升。公司决定即日起对8位MCU产品进行价格调整,涨价幅度为5%。 此外,深圳市骏晔科技有限公司发布的调价通知显示,自2025年9月起,电子行业各类原材料价格持续攀升,进入2026年3月以来,上游供应链成本上涨趋势进一步加剧。通知列举称,PCB线路板涨价约70%,电阻涨价约40%,电容涨价200%至300%,接插件、线圈分别上涨约30%,MOS管及单片机芯片涨价约20%,锡条、锡线等焊接材料涨价约60%。公司表示,将对全系列无线射频模块产品进行价格调整,最终下单价格以最新确认单价为准。 业内人士认为,电子元器件价格调整通常反映上游材料、制造、交付等多重成本变化。此次调价覆盖功率器件、MCU和无线模块等多个环节,说明成本压力正从原材料端向中下游产品端传导。对下游客户而言,短期内需关注库存安排、订单锁价及替代料评估;对供应商而言,如何在保障交付稳定的同时控制涨价幅度,将成为维系客户关系的重要因素。
立昂微
芯查查资讯 . 2026-06-16 4669

企业 | 英飞凌GaN产品禁止在中国境内销售
2026年6月12日晚间,国产氮化镓(GaN)大厂英诺赛科通过官方公众号宣布,当日,最高人民法院正式发出临时禁令复议裁定书,维持苏州中院针对英飞凌的销售禁令,意味着从此刻起英飞凌相关氮化镓产品被禁止在中国境内销售,英诺赛科取得了专利侵权案的最终胜利。 早在2025年初,英诺赛科就有向江苏省苏州市中级人民法院提起诉讼,指控英飞凌科技(中国)有限公司、英飞凌科技(无锡)有限公司及代理商苏州芯沃科电子科技有限公司侵犯其两项氮化镓核心发明专利。 这两项专利(专利号:202311774650.7和202211387983.X)均与氮化镓功率器件及其制备方法相关,是英诺赛科在第三代半导体领域的重要技术成果。 2026年5月27日,苏州中院作出一审判决:认定英飞凌侵权成立,判令其立即停止销售、许诺销售、进口等侵权行为,并赔偿英诺赛科经济损失合计1000万元,判决立即生效。 对此,英飞凌不服判决,向最高人民法院申请复议。 值得注意的是,在侵权诉讼推进的同时,英飞凌也在另一条战线发起反击——向中国国家知识产权局(CNIPA)请求宣告英诺赛科的两项专利无效。 2025年11月19日,CNIPA作出裁定,全面维持英诺赛科两项核心发明专利的有效性。英飞凌随即向北京知识产权法院提起行政诉讼。 2026年4月,北京知识产权法院作出判决,全面驳回英飞凌的诉讼请求,从司法层面确认了英诺赛科两项氮化镓专利的有效性。 北京知识产权法院的判决为英诺赛科后续的侵权诉讼扫清了关键障碍——专利权有效性是侵权认定的前提。 基于此,2026年6月12日,最高法正式发出临时禁令复议裁定书,驳回英飞凌全部复议请求,维持苏州中院的禁令判决。 业内分析认为,此次最高法的终局裁定将产生多重影响:对英飞凌而言,中国是其最重要的市场之一。相关氮化镓产品被禁售,意味着其在中国市场的氮化镓业务将遭受实质性冲击;对英诺赛科而言,这场胜利不仅是法律层面的突破,更意味着国内市场份额有望获得进一步的扩张空间,并巩固自身在全球氮化镓功率器件领域的领先地位。 对行业而言,此案释放了一个明确信号:中国司法体系对本土企业自主知识产权的保护力度正在加强,“专利武器化”并非跨国巨头的专属特权。 需要指出的是,英诺赛科与英飞凌的专利战并非仅限于中国,而还涉及美国和德国的专利诉讼。 2026年5月,美国国际贸易委员会(ITC)全体委员会做出最终裁决维持了其于2025年12月作出的初步裁定,确认英诺赛科(Innoscience)侵犯了英飞凌的一项氮化镓(GaN)技术专利,并下令对英诺赛科实施进口和销售禁令。不过,ITC也确认英诺赛科当前的氮化镓功率器件产品未侵犯英飞凌的相关专利,并可不受限制地继续在美国进口和销售。
英飞凌
芯查查资讯 . 2026-06-16 1 1981

市场 | 台系被动元件厂商,营收集体创新高
在AI服务器需求持续增温下,让被动元件产业迎来新一轮成长周期,进一步带动许多厂商近几个月营收持续创历史新高纪录。 台系被动元件营收创新高 以中国台湾为例,包含国巨、台庆科、天二科技、立隆电、立敦等公司,营收皆已连续三个月创历史新高纪录。展望下半年,各厂皆认为客户需求有望延续,对接下来营运呈乐观看待。 国巨5月营收150.58亿元新台币,环比增7.3%、同比增47.5%,创历史新高纪录;前5月营收672.63亿元新台币、同比增27.4%。主要受惠AI应用需求持续强劲,标准品及特殊品亦呈现稳定成长。国巨指出,公司B/B Ratio(订单出货比)已达1.3,其中AI相关产品更高达1.4,而标准品稼动率已达75%至80%,特殊品则提升至85%至90%,显示市场需求持续增强,公司预估产能利用率将持续提升。 台庆科5月营收站稳7亿元之上,达7.09亿元新台币,环比增0.75%、同比增37.77%;前5月营收31.49亿元新台币、年增17.31%。台庆科表示,主要受惠AI及车用成长,其中,GB200/GB300用耦合电感持续提升营收,其他AI服务器及ASIC相关应用预期Q3起将逐季放量,AI电源供应目前也持续和电源大厂合作开发800V HVDC,相关效益将于明年发酵。车用电子则受惠欧美OEM客户需求回升及新能源車市场放量所带动,后续在AI、车用两大领域成长贡献下,营运乐观看待。 天二科技5月营收1.9亿元新台币,环比增5.9%、同比增58.67%;前5月营收7.89亿元新台币、同比增30.2%。天二科技表示,主要受惠AI需求畅旺,客户拉货力道强劲,目前公司产能满载,且B/B Ratio(订单出货比)达1.2-1.3,代表客户需求延续,Q3-Q4订单也都已陆续洽谈中。 立隆电5月营收12.1亿元新台币,环比增1.17%、同比增29.96%;前5月营收53.49亿元新台币、同比增14.56%。立隆电表示,主要受惠AI、车用产品需求延续,推升公司营收维持高档表现,随着AI产品出货量持续增温,且公司新设计之AI产品也将在6-7月放量出货,后续有望再增温,估后续营运将逐季向上。 立敦5月营收4.73亿元新台币,环比增3.14%、同比增25.03%;前5月营收20.49亿元新台币、同比增11.02%。立敦表示,下游应用以铝电容为主,受惠AI、车用等高阶需求增温,带动铝电容出货成长,公司出货量需求同步提升,进一步推升营收持创历史高。 兴勤5月营收8.68亿元新台币,环比增0.62%、同比增29.74%;前5月营收37.84亿元新台币、同比增15.12%。兴勤表示,受惠AI应用发酵,加上车用电子化趋势明确,推升公司5月营收续创历史新高纪录,现阶段B/B Ratio(订单出货比)来到1.5,稼动率也几乎是满载,后续在AI、车用领域增温下,看好今年营收有望缴出双位数成长表现。 被动元件涨价潮 被动元件涵盖多层陶瓷电容器(MLCC)、电感器、电阻器、薄膜电容等核心品类,广泛应用于消费电子、新能源汽车、5G通信、AI服务器等终端领域。 据开源证券统计,2025年以来,多家被动元件头部企业宣布调涨产品价格,推动全球被动元件市场进入新一轮上行周期,其中国巨旗下基美、松下、风华高科、村田等都针对不同品类发布了涨价函。 本轮涨价函均有供给和需求端推动。在供应端,上游原材料价格持续上涨并向下传导,行业稼动率维持提升趋势以银、钯、钌、锡、铜等为代表的上游金属原材料价格持续上涨是本轮被动元件涨价的主要推动力。从国巨、华新科、风华高科等厂商调价函中可以看到,人力、电力以及白银、钌、钯、锡、铜等金属原材料价格大幅攀升导致的生产成本显著上升,是被动元件厂商涨价的主要原因。上 从下游需求端看,消费电子等传统需求保持稳定水平,而下游AI服务器/新能源汽车/工业等新兴领域需求旺盛、强劲增长。以AI服务器为例,Trendforce指出,每台AI服务器大约配备1.5至2.5万颗MLCC,村田预计AI服务器中MLCC市场空间将以每年30%的增速提升,2030年将达到2025年的3.3倍。 产能紧张之余,厂商也将扩产提上日程。 被动组件厂华新科总经理曾明灿近期表示,AI需求强劲,接单出货比(BBRatio)持续上升,供需紧俏的情况可能不只到明年,公司也积极扩产,今年产能估增10-15%,明年进一步增加。 曾明灿表示,BBRatio已经从先前1.2-1.3到目前的1.3-1.4,后续持续看升,虽然一部分是产品涨价、客户积极追料,但并没有看到Overbooking情况,主要还是AI需求强劲,加上过去2-3年客户比较没有在囤库存、水位相对较低。 其余应用来看,曾明灿认为,AIPC起来也会带动被动组件用量;汽车方面,虽然市场普遍预估今年销量衰退10%,但华新科本身来看,车用相关成长20%,主要是受惠车用电子需求增加。 产能方面,曾明灿表示,目前电容稼动率80-85%、电阻85-90%,今年电阻产能扩产10%、电容则可望增加15%,明年持续投资,产能增幅可能会超过今年。
被动器件
芯查查资讯 . 2026-06-16 1071

市场周讯 | SK海力士园区又失火;3个月车规级存储芯片价格暴涨180%;美国国防部发布2026年1260H清单,长存和长鑫被重新列入
| 政策速览 1. 工信部:工业和信息化部印发《“人工智能+信息通信”创新发展实施意见(2026—2028年)》。其中提到,加强高端光电芯片和器件研发。加强高速光电芯片、高速转发/交换芯片、全光交换器件、光电共封装器件等技术和产品研发验证,开展光电混合组网技术试验,加速技术方案成熟。加强智算超节点光电互联技术攻关,开展智算网络技术与产品验证。 2. 中国海南:海南省人民政府办公厅印发《海南省“十五五”高新技术产业发展规划》,其中提到,加快构建“芯片设计带动、先进封测突破、维修制造延伸”协同发展的电子信息制造产业生态。上游夯实集成电路设计,招引高端显示、智能传感、智能算力等领域芯片设计企业,衔接本地封测产能,谋划建设集成电路设计公共服务平台,提升EDA工具、IP设计、AI辅助等基础服务能力。中游做强先进封装测试,扩大半导体器件与功率模组制造产能,发展智能功率模块、高端传感器等高附加值产品。支持企业积极应用2.5D/3D、晶圆级、系统级等先进封装技术,引进封装测试设备制造企业和第三方检测机构,提升本地化封装、测试、验证能力,匹配上游芯片设计和下游终端制造。以市场需求为驱动,积极布局第三代半导体,深化碳化硅、氮化镓、磷化铟等半导体材料的研究应用,谋划开拓高速存储、光通信、AI运算等领域封测新赛道。下游拓展产品维修制造,着力保障高性能服务器、信创整机、显示终端、数字能源等制造产线达产扩产,支持企业开展智能化、柔性化升级改造,逐步形成本地化产能协同。依托海南自由贸易港开放政策优势,面向国际市场拓展半导体装备、存储产品、手机终端等维修、检测、再制造业态。 3. 中国无锡:无锡市委书记杜小刚主持召开全市集成电路(人工智能)产业发展专题推进会。会议强调,要夯实项目支撑。紧盯设计、制造、封测和装备材料等重点环节,聚焦AIDC、Token等前沿赛道,分层分类梳理项目清单、建立推进机制,强化对重点项目特别是标杆项目的常态调度、挂钩服务、精准支持。同时,密切与上市公司、龙头企业、科研院所、投资机构等对接,把握行业趋势、精准切入赛道,共同落地更多优质增量项目。 4. 美国:美国防部发布了所谓的在美国直接或间接运营的“中国军事企业”清单(CMC清单或1260H清单)的更新版本;该名单已在美国《联邦公报》的“公众查阅”版块正式公布。美国国防部认定有188家实体符合列入最新1260H清单的法定标准,并将10家中国企业移除。与早些时候2月13日发布后又迅速撤回的版本相比,本次更新将“长江存储和长鑫存储”重新列入了1260H清单。 | 市场动态 5. 六氟化钨:六氟化钨是半导体CVD制程中沉积钨膜唯一商用前驱体气体,暂无替代产品。海关总署数据显示,2026年4月我国六氟化钨出口均价达149.79美元/千克,同比上涨28.33%,环比更是大涨203.83%,价格波动幅度惊人。2025年6月,65%品位黑钨精矿市场价仅17万元/吨左右,而今年3月价格一度冲高至百万元/吨以上,后续虽回落至46万-47万元/吨区间,但整体仍属于阶段性异常行情。 6. 服务器:美国银行分析师最新预测,服务器CPU的总潜在市场规模(TAM)将从2025年的350亿美元激增4倍至2030年的1700亿美元以上。代理式AI的崛起是一个强大的需求加速器,它不仅扩大了CPU的市场机遇,也为英特尔、AMD以及基于Arm架构的挑战者们带来了利好。 7. SEMI:2026年第一季度,全球半导体设备销售额达到365.5亿美元,环比增长1%、同比增长14%,创下单季历史新高。从区域排名来看,韩国超越中国台湾,位居全球第二。SEMI表示,今年一季度半导体设备市场持续受益于人工智能领域的投资热潮,全球半导体企业纷纷加码扩产、推进技术升级。相关投资主要投向先进逻辑工艺、动态随机存取存储器(DRAM)以及先进封装领域,持续拉动设备市场规模走高。 8. TrendForce:受到AI Agent服务普及与CSP(云端服务提供商)强劲订单带动,2026年第一季全球前五大Enterprise SSD品牌厂营收再度创下新高,单季营收较前一季度成长86.1%,突破184.6亿美元。TrendForce集邦咨询指出,第一季市场陷入供需失衡,由于各大供应商库存水位已降至历史低点,产出速度远远赶不上订单增长,供应商为实现获利极大化,积极推升价格,使得第一季合约价狂飙80%。 9. Omdia:2026年第一季度的半导体营收较2025年第四季度环比增长27%,达到3190亿美元。存储器营收是推动这一增长的主要动力,其在2026年第一季度的环比增幅超过80%。随着存储器营收继续引领半导体市场向前发展,预计2026年第二季度将延续强劲的增长势头。虽然第二季度的环比增速可能较第一季度有所放缓,但仍足以使半导体市场实现超过20%的环比增长。 10. TrendForce:英伟达下调Vera CPU搭载容量,凸显LPDRAM供给缺口难以缓解,且中长期需求呈上扬趋势。鉴于三星、SK海力士及美光初步规划给予英伟达的LPDRAM供应仅能满足该品牌约60%的需求,且上调空间有限,英伟达近期决议调整Vera Rubin Superchip模组搭载的SOCAMM模组容量,以满足更多Vera CPU的出货需求,并提前应对后续货源持续紧张的风险。 11. TrendForce:SpaceX除持续扩大卫星宽带服务版图外,也积极布局手机直连卫星、AI太空运算及太空太阳能(Space-Based Solar Power, SBSP)等新兴领域,并通过扩建自有太空AI运算芯片厂Terafab,强化垂直整合能力,推动低轨卫星产业由通信服务迈向运算服务新阶段。随着卫星网络、AI基础设施与太空应用加速融合,全球太空经济正进入新一轮成长周期,预估2027年全球卫星产业产值将达4,470亿美元,年成长率达14%。 12. 车规级存储:近一段时间,国内新能源汽车市场迎来较为集中的价格调整,市面上有多款新能源车型,先后出现了售价上调或优惠变化。车企公告显示,选装包价格调整,主要是受到全球存储硬件成本大幅上涨的影响。有数据显示,近三个月,车规级存储芯片整体价格涨幅约在180%。据不完全统计,近期国内共有十余家新能源车企上调售价或收紧优惠,幅度一般在2000元到6000元不等。在新能源车价格出现变化的时候,不少燃油车在调低价格,加大优惠力度。截至今年4月,燃油车促销力度已连续9个月维持在23%左右的高位。 13. QYResearch:全球固态断路器市场规模预计将由2025年的245.65百万美元增长至2032年的2,366.43百万美元,CAGR为38.21%。主要驱动因素:直流电力系统扩张、新能源发电、电动车充电、数据中心、工业自动化以及电气安全要求提升,推动固态断路器在快速保护和智能配电场景中的应用增加。 | 上游厂商动态 14. 中科曙光:中科曙光将于近期发布新一代国产高性能通用计算平台,重点面向科学计算、工业仿真等高精度计算场景。消息人士指出,该平台以新一代国产通用CPU为核心,关键性能指标实现重大突破,有望对标国际厂商同类旗舰产品。 15. 银河微电:银河微电发布公告,公司正筹划通过发行股份购买恒泰柯半导体(上海)有限公司100%的股权,同时募集配套资金。恒泰柯半导体是一家功率半导体设计生产商,致力于中高压的半导体电源管理器件、功率半导体MOSFET(三极管)的设计、制造及销售,为用户提供充电器开关、半导体充电器同步整流等产品。 16. 台积电:下半年台积电先进制程为因应上游价格调涨,将适度调涨代工价,预期最为紧俏之3纳米制程将有15%之涨幅,芯片业者指出,客户排队状况未明显缓解,尽管台积电持续拉升晶圆产能,第二季月产能将达16万至17.5万片水准,但AI需求成长速度仍远超市场预期。 17. 三星:三星电子考虑在韩国光州建设先进半导体封装工厂,以满足全球芯片需求。三星正扩大HBM市场布局,以加强其在AI芯片供应链中的地位。预计三星将在6月29日韩国总统与企业集团负责人会议上公布投资计划。 18. 澜起科技:澜起科技宣布,已成功向客户送样其DDR5第六子代寄存时钟驱动器芯片 (RCD06)。该芯片应用于新一代DDR5寄存式双列直插内存模组 (RDIMM),将有力推动下一代计算平台性能升级。RCD06芯片支持高达9200 MT/s的数据传输速率,较上一代产品提升15%。 19. 紫光国芯:西安紫光国芯半导体股份有限公司及其辅导券商中信建投向陕西证监局提交《辅导工作完成报告》。公司于2026年1月6日提交辅导备案,辅导工作历时5个月。 20. 三星:三星电子芯片部门负责人JUN表示,与英伟达CEO黄仁勋就HBM4、晶圆厂领域的短期合作事宜进行了讨论。JUN表示,我们正在合作研发4纳米和8纳米节点所需的自动驾驶芯片,以及NVIDIA的加速器芯片;我们还就长期合作进行了广泛讨论,包括HBM4E、代工业务、HBM5以及其他未来技术。双方还讨论了下一代芯片的代工合作。 21. NXP:GaN功率器件公司CGD宣布与恩智浦半导体达成合作,共同加速数据中心和汽车市场的产品开发与上市进程。 22. Arm:亚马逊云科技(AWS)正式宣布,基于其去年12月发布的第五代自研Arm处理器——Graviton5的Amazon EC2 M9g和M9gd实例正式上线。Graviton5采用了台积电3nm制程工艺,在同样功耗下封装了更多晶体管,实现了更高的电路密度与能效比。Graviton5所搭载的Neoverse V3内核由Arm与AWS Annapurna Labs联合定义。其一级缓存(64 KB)、二级缓存(2 MB)虽非最大亮点,但三级缓存(L3 Cache)暴增5倍,达到192 MB,能够将海量热点数据留在离核心更近的地方。同时,其分支预测能力大幅提升,使得运行真实数据库等复杂代码时的性能提升高达30%。在核心数量方面,Graviton5从Graviton4的96核一举提升至192核,实现了100%的增长。但更重要的是,AWS放弃了此前的单一计算核心芯片(Die)架构,转而采用了一套先进的4芯片组(Chiplet)设计。这意味着192个核心被均匀分布在4个独立的芯片组上,每个芯片组包含48个核心,并集成了专属的DRAM内存控制器和PCIe 6.0 I/O控制器。 23. 兆易创新:兆易创新GigaDevice宣布推出全新GD32E512和GD32E252系列光模块专用MCU,精准覆盖从传统低速到新一代高速光模块的多元应用场景。这两款新品的发布,将进一步拓宽兆易创新在光通信领域的产品矩阵,并将为AI算力中心及下一代网络基础设施的高速光互联产业升级提供强有力的底层硬件支撑。 24. 盈方微电子:元器件分销商盈方微电子8.97亿并购同行肖克利。 25. SK海力士:韩国SK海力士清州第四园区爆发火情。对于最新情况和影响,SK海力士方面表示,已完成初步控制,正调查具体情况。目前生产设备运行正常。 26. SK海力士:SK海力士计划到2034年将晶圆产能提高两倍,以满足人工智能推动下不断增长的存储芯片需求,崔泰源还预计晶圆产能将在5年内翻一番。此外,SK集团还计划与英伟达合作,到2028年至2029年间在日本建设一座AI数据中心。 | 应用端动态 27. 比亚迪:比亚迪股份有限公司召开2025年度股东会。围绕智能驾驶,王传福在会上表示,整车智能就是具身智能,比亚迪率先提出全民智驾,就是希望AI的技术成果能够在汽车上快速落地。比亚迪现在有315万台智驾车型在全球落地,每天有两亿公里行驶里程的数据,为比亚迪未来更高级别智能驾驶落地提供了很好的基础。“根据现在AI技术的发展,大家可以看到,未来L3、L4一定会提前落地。” 28. 北京人形机器人创新中心:北京人形机器人创新中心与地瓜机器人宣布,双方协同打造的全尺寸通用人形机器人天工3.0,将2026年下半年开启规模化量产交付。据悉,该机型搭载地瓜机器人旭日S600具身智能大算力芯片,应用于工业制造、商业服务及3D复杂场景作业。据披露,依托技术架构与规模化量产优势,天工3.0整机综合成本预计降幅超50%。量产落地后的天工3.0,将投入产线作业、仓储物流、智能服务、特殊环境运维等实景应用。 29. 优必选:沐曦股份与优必选6月11日在南京市正式签订战略合作协议,合资成立曦选创智科技(无锡)有限公司(简称“曦选创智”)布局具身智能芯片研发与量产。曦选创智注册资本1亿元,由沐曦股份、优必选、锋龙股份等上市企业联合成立,其中沐曦股份与优必选分别持股35.01%,并列第一大股东,锋龙股份持股4.7%。 30. 谷歌:由于芯片制造产能持续紧张,各大芯片企业纷纷寻求台积电以外的合作供应商。谷歌正考虑让三星电子承接其一款尖端新一代人工智能芯片的部分组件生产工作。知情人士表示,谷歌计划由三星采用2纳米制程工艺,代工生产新一代张量处理器的部分芯片。张量处理器是谷歌专为云数据中心打造的人工智能专用芯片。该芯片代号为 “冰鱼”,目前规划为谷歌第十代张量处理器。两位知情人士表示,对于代号为 “冰鱼” 的新一代张量处理器,谷歌计划仍由台积电采用1.4 纳米先进制程,负责制造芯片核心的计算引擎部分;而三星或将代工内存输入输出裸片。
芯片
芯查查资讯 . 2026-06-15 4914

产品 | 车规级新品!艾为 216 路车规级 LED 驱动,重塑车载光影美学
深耕 LED 驱动领域 16 年,艾为电子打造了覆盖 3~216 路的全场景 “艾为灯语”产品矩阵,广泛应用于消费电子、工业互联与汽车电子领域。凭借自主呼吸、蒙赛尔变色呼吸、音随我动等核心技术,艾为灯为客户提供差异化的高端灯效解决方案。 图1 应用场景图 随着汽车智能化发展,高品质氛围灯已成为内饰设计的核心元素。艾为电子正式推出车规级 216 路 LED 矩阵驱动芯片 AW20216EQPY-Q1,单芯片可驱动 216 颗 LED 或 72 组 RGB,为汽车内饰氛围灯、面光源、格栅灯、ISD 交互尾灯、星空顶等应用提供高效集成方案。 四大核心优势,重新定义车载灯效体验: 1. 高度集成,显著降低系统成本 采用 18×12 恒流矩阵架构,单芯片实现 216 路 LED 驱动能力。相比传统多颗少路数驱动芯片方案,大幅简化 PCB 设计,减少元器件数量,显著降低系统 BOM 成本与装配复杂度。 图2 AW20216EQPY-Q1 典型应用图 2. 内置自动呼吸引擎,释放主控资源 集成 3 组独立自动呼吸引擎,可实现平滑细腻的渐亮渐灭灯效,完全无需主控 MCU 干预。既节省了宝贵的主控资源,又降低了系统整体功耗。 图3 AW20216EQPY-Q1 内置自动呼吸灯效引擎 3. 多档可调负压消鬼影,保护灯珠寿命 针对矩阵驱动常见的鬼影问题 (非点亮LED出现暗亮),AW20216 创新采用多档负压调节技术。相比行业通用的固定负压方案,可精准控制 LED 两端反向电压,在彻底消除鬼影的同时,避免因负压过大导致的灯珠损坏,大幅提升产品可靠性与使用寿命。 4. 硬件级开短路诊断,提升生产效率 内置全通道开短路异常诊断功能,SMT 焊接完成后,芯片可自动检测每一路 LED 的连接状态,并将结果存储在寄存器中供上位机读取。完全替代人工目视检查,消除人眼疲劳导致的误检,大幅降低人力成本,提升生产良率。 图4 快速诊断LED开短路异常 芯片的关键特性 • AEC-Q100 Grade 1 • 18 x 12矩阵,216路 LED 驱动 Ø 256级全局电流 Ø 256级独立DC恒流调光 Ø 256级独立PWM调光 Ø Imax 100mA,通过Rext可调 • 3组自动呼吸引擎,无需主控控制 • 低EMI & 啸叫抑制 • 开短路异常诊断 • 多档负压消鬼影,避免损坏灯珠 • 1MHz I2C / 10MHz SPI • 工作温度 -40°C to +125°C • QFP 7mm×7mm-48L封装 图5 封装图 表1 艾为车载灯语选型表
艾为
艾为官网 . 2026-06-15 1008

中电港:打造工程师“星光大道” 构筑集成电路应用创新生态平台
6月5日,深圳中电港技术股份有限公司(以下简称“中电港”)上线了一款自研AI应用产品“数字FAE”,该产品依托垂直产业大模型重构传统现场应用工程师服务模式,是电子元器件分销行业数智化升级的重要落地成果。 当前人工智能技术不断在各行各业纵深发展,中电港将在这场产业变革中扮演怎样的角色?带着这些问题,近日《证券日报》记者走访了位于深圳南山区的中电港总部。 AI赋能服务升级 作为国内领先的电子元器件应用创新与供应链服务平台,中电港长期连接集成电路原厂、方案商、制造企业及终端客户等产业链上下游资源。 目前,该公司拥有百余家国内外集成电路原厂授权,产品覆盖CPU、GPU、MCU、存储器、射频、无线通信、模拟器件、传感器及分立器件等核心品类,服务网络延伸至汽车电子、AI算力、工业制造、消费电子、低空经济、医疗设备等多个重点领域。 近年来,依托多年积累的技术服务、供应链管理及产业数据能力,该公司正持续推动人工智能技术与产业服务深度融合。 “电子产业的产品和技术迭代非常迅速,尤其是在人工智能时代,每个季度,甚至每个月都会有新的产品形态不断冒出来,这依赖于中国庞大的优秀工程师群体的研发效率与创新速度,也对集成电路原厂、IDH和分销商的技术支持团队提出了更高要求。”中电港相关业务负责人对记者表示。 因此,针对行业普遍存在的技术咨询烦琐、型号检索低效、FAE服务覆盖范围有限等痛点,中电港立足产业深耕积累,依托通用大模型技术,结合自建海量产业知识库、产品参数库、实操案例库专项训练,推出垂直行业专属数字FAE应用。 据介绍,该数字FAE AI应用具备元器件型号智能匹配、场景化方案精准推荐两大核心能力,能够快速响应各类研发咨询需求,大幅压缩项目技术对接周期。 依托该智能工具,平台可实现7×24小时全天候线上技术赋能,打破传统服务的时空壁垒。一方面,可有效解放FAE工程师重复性基础工作,助力团队聚焦高端方案研发、核心技术攻坚;另一方面,面向广大国内电子工程师开放高效、专业的智能化技术服务,为一线研发工作减负增效。 该负责人表示,中电港将持续迭代升级数字FAE AI应用,逐步落地方案仿真辅助、选型风险预警、定制化研发赋能等进阶功能,持续深化大模型与集成电路产业场景的深度融合。 机器人打开成长空间 事实上,随着人工智能技术快速演进,尤其是具身智能逐渐成为全球科技产业竞争的新高地,中电港也从中敏锐捕捉到了新的发展机遇。 “我们服务机器人相关企业已超过10年,服务机器人产业链客户超过百家,在核心器件选型、方案设计、供应链保障以及产业协同方面积累了丰富经验。”中电港相关业务负责人向记者介绍,“机器人并不是一个单一终端产品,而是电子信息产业技术能力的集中体现。从端侧AI芯片到存储器,从视觉传感器到运动控制系统,从电源管理到通信连接,机器人几乎集成了电子产业链最核心的技术环节。” 资本市场同样对这一赛道寄予厚望。多份研报预计,到2030年前后,全球人形机器人市场规模有望达到万亿元级别。与此同时,机器人产业的发展将持续带动AI芯片、MEMS传感器、功率半导体、存储器、电机驱动等关键元器件需求增长。 在此背景下,中电港积累多年的资源优势开始显现。“一方面,公司拥有130余家国内外集成电路品牌授权资源、10万余家客户资源以及5000余家年度交易客户;另一方面,芯查查、萤火工场、iCEasy等平台已经形成产业数据、技术服务、在线交易和供应链管理能力。”上述负责人表示。 以芯查查为例。在平台上,一个芯片型号背后不仅能够查询规格参数、封装信息和替代方案,还能够追溯供应情况、价格走势、应用案例以及产业链上下游关系。目前,该平台已拥有超过150万活跃用户和300万月访问量,数据服务覆盖电子行业90%以上的业务场景。 “这种基于产业数据、技术知识和供应链资源构建的服务能力,已经在消费电子、工业控制等领域得到验证。随着机器人产业快速发展,公司也希望将相关经验迁移至机器人赛道,为客户提供从器件选型、方案设计到供应链协同的全链条支持。”该负责人表示。 近年来,中电港已与多家原厂围绕机器人、机械臂和无人车领域推出应用创新方案,如与成都阿加犀智能科技有限公司联合推出基于高通平台的低功耗AI机器人解决方案;携手ADI、兆易创新科技集团股份有限公司等企业,共同打造智慧视觉、灵巧手、运动控制、电源管理等细分领域解决方案。 打造工程师的“星光大道” 在调研中记者发现,无论是数字FAE的推出,还是机器人领域的持续布局,都只是中电港转型探索的一部分。相比于单纯销售电子元器件,该公司更希望成为连接技术创新与产业化落地的重要枢纽,在新一轮产业变革中支撑更多创新成果加速走向市场。 为此,2025年以来,中电港围绕应用创新生态建设展开了一系列布局。该公司陆续推出数字FAE、方案中心、智能BOM管家、参考设计库等工具平台,尝试将过去高度依赖资深工程师经验的工作流程数字化、标准化和智能化。 “我们希望扮演的角色,不是单纯的元器件供应商,而是连接创新与产业化的桥梁。”中电港相关业务负责人表示,公司致力于为产业提供从创意构思到产品量产的一站式综合服务,打造工程师的“星光大道”,让创新团队能够更加专注于技术突破,将产业化过程中的复杂环节交由我们完成。 谈及未来规划,中电港方面表示,将逐步建设行业领先的集成电路应用创新生态平台。依托数据平台、数字FAE、方案数据库、产业社区以及供应链资源网络,高效连接工程师、创新团队、芯片原厂、IDH企业、制造资源和终端客户,重点布局AI算力、智能汽车、低空经济、机器人、工业电子等新兴产业方向。 “未来,每一个产品、器件、方案和应用场景都将实现标签化、结构化、数据化管理,沉淀为可复用、可持续增值的产业资产。”中电港相关业务负责人表示,在商业模式上,中电港也将从单一元器件分销向多元化服务延伸,形成元器件销售、技术方案服务、数字FAE服务、数据服务、供应链监测、SaaS订阅和生态运营等多元收入结构。
中电港
证券日报 . 2026-06-15 1 1827

方案 | 光储充下半场,系统级能力才是终极答案
光储充产业正迎来一场意义深远的技术变革:光储融合成为标配,兆瓦级超充正加速落地,同时也把系统功率密度推向全新的高度。而功率的大幅提升同时带来了直流拉弧安全隐患加剧、多模块协同控制难度陡增、主控芯片算力需求增加等一系列棘手问题,通用MCU在系统级优化上已显得力不从心。 作为全球半导体设计领域的领军企业,兆易创新在SNEC 2026展会上向业界释放出一个强烈信号:在光储充向高功率、高安全、高协同发展的今天,分散的元器件供应已无法满足系统级需求,兆易创新的应对之策是从“芯片供应商”向“系统能力输出者”转变。 展会期间,兆易创新 MCU事业部市场经理毛明歌接受了维科网光伏的专访,她用3个关键词概括了公司的数字能源战略——协同、算力、全场景,并详细拆解了每个关键词背后的技术逻辑和产业思考。 BMS系统级协同:MCU与AFE深度配合 “今年储能市场不仅是在增长,更是在爆发。”毛明歌开门见山地说。 光伏发电量的不断攀升,使得储能消纳成为必选项。电化学储能系统的核心是电芯,电芯的SOC(荷电状态)、SOH(健康状态)的估算精度,直接决定系统的寿命与安全。 但这些估算并非孤立算法,而是一个“采集—计算—存储—控制”的闭环。其中,AFE负责高精度采样,MCU负责实时算法与控制逻辑。二者高度协同,才能够打造完整的BMS系统方案,满足从小型便携储能到大型储能系统全场景的需求。 毛明歌进一步指出,兆易创新的差异化在于拥有完整的产品线,从阳台便携储能、户用储能、工商业储能到大型储能等各种场景都有对应的AFE产品;MCU方面,从通用型到专为数字能源优化的高性能实时控制MCU,已形成梯度覆盖;加之存储产品的传统优势,整套BMS方案可以做到“采—算—存”底层协同,无需客户跨厂商搭建。 AI加持MCU:直流拉弧检测从“软肋”变“铠甲” 直流拉弧是光伏与储能系统长期未解的安全痛点。与交流电不同,直流没有过零点,一旦拉弧便持续燃烧,极易引发火灾,而电芯起火后常规手段无法扑灭。更棘手的是,随着组件功率攀升,PV侧电流从过去的10安培以内跃升至20安培、40安培甚至更高,传统的频域判断法已基本失效。 “传统方案在10安培以下勉强可用,再往上就无能为力了。这不是参数微调能解决的。”毛明歌坦言。 ▲基于GD32H7系列MCU的AI拉弧检测方案 兆易创新的方案是将轻量化AI模型直接部署在GD32H7系列MCU上,用边缘智能取代传统频域判断。技术指标上,支持250k/500k 采样率,支持14通道同步推理,单次推理耗时小于1ms,实测准确率超过99.9%。 1ms意味着系统可在电弧尚未发展成灾害时完成检测并发出指令。且所有推理均在本地完成,不依赖网络,无时延波动,也无数据上传的安全隐患。 毛明歌指出一个产业趋势:“拉弧检测正在从区域性政策要求,变成全球市场的刚性需求。尤其在欧洲,很多项目招标已明确把AI拉弧检测写入技术规范。”换言之,它不再是加分项,而是入场券。 除拉弧检测外,兆易创新已将AI算法延伸至设备预测性维护、故障超前诊断等场景。 两大新方案:架构创新让算力“减负” 今年的展会上,兆易创新还展出了两款全新的方案:1kW一拖二单级微型逆变器方案和10kW三相维也纳PFC方案,这两套方案均基于GD32G5系列高性能MCU开发。 (1)1kW一拖二单级微型逆变器方案,采用“单级DAB+一拖二”拓扑架构。相较于传统Flyback结构,该方案有效解决了无功功率支持的问题,这在大规模光储应用密集的欧洲市场尤为关键。对比两级架构,BOM更加精简,无需使用大容量电解电容,成本更优,系统寿命更加可控。 方案中采用了氮化镓器件,有效提升了功率密度,在同等尺寸下可实现更高功率,或在同等功率下体积更小,从而降低客户的安装及外壳成本。该方案效率达到约97%,主要针对阳台光伏应用场景,支持组件级关断和优化功能,可满足不同坡面屋顶的安装需求。该方案支持两路独立MPPT,支持接入两块光伏板,较去年500W方案功率更大,适用场景更广。 (2)10kW三相维也纳PFC方案,采用中点电流法节省MCU控制算力,三电平拓扑结构可降低器件应力。方案效率可达到98%,兼顾高效率和高功率密度,适用于直流充电桩、AI数据中心电源等应用场景。 兆瓦超充时代:算力、通信、热管理三重挑战 当前,光伏、储能、充电产业正加速走向“光储充融合”与“兆瓦超充”的新阶段,而2026年更被业界视为“兆瓦超充元年”。两大趋势的核心在于追求更高功率与更精细复杂的协同控制,这对主控芯片与功率芯片间的协同效能提出了前所未有的挑战。毛明歌将其归纳为三大维度: 第一,算力维度。 碳化硅正快速替代硅MOS。以逆变器为例,当前硅MOS方案的控制频率通常在16-20kHz,而碳化硅方案要发挥其高频优势,控制频率需要提升。这意味着对MCU的实时控制算力要求提升。 第二,通信维度。 光储充融合的本质是多模块联动,即光伏、储能、充电桩、电网之间需要实时数据交换与协同。对MCU的通信接口丰富度、协议兼容性、实时性要求远超以往。 “兆易创新从通用MCU起家,丰富的外设资源一直是我们的传统强项。”毛明歌介绍说,“下一代产品将围绕更高算力与更丰富通信接口布局。” 第三,热管理维度。 这并非MCU单点能解决的问题,磁性元器件、容性元器件、功率器件、整机散热结构需要系统级设计。在芯片层面,推进先进封装以降低芯片自身热功耗。 技术护城河:产品、生态、方案三位一体 面对大型储能BMS、V2G车网互动等前沿领域,兆易创新的技术护城河如何构建呢?毛明歌给出了三角框架:产品、生态协同、方案开发。 产品层面:兆易创新依托MCU、模拟产品、存储产品等多元产品线的融合,针对光储充、AI数据中心等场景,持续布局更多满足未来需求的新产品。 生态协同层面:公司与功率器件厂商开展战略合作,共建联合研发实验室,通过深入了解功率器件特性,进一步优化产品与方案设计。 方案开发层面:公司目前已建立数字电源实验室,面向光伏、储能、充电桩、AI数据中心等数字能源全领域提供解决方案,覆盖从芯片功能验证到系统级闭环测试的全周期。“这有助于我们更深入地理解客户需求,反哺下一代产品定义,同时更好地发挥MCU特性,为客户提供更具针对性的应用方案。”她补充说道。 而在规划方面,毛明歌还给出一个相对清晰的时间表:未来三至五年,公司产品将覆盖光伏、储能、充电桩、数据中心等各场景领域。 可以看到,数字能源芯片的护城河,从来不是单点技术有多强,而是能不能在正确的时间,为整个系统提供最合适的‘采—算—控—存’闭环。 终极逻辑:从元器件供应商到系统定义者 几年前,行业论坛上曾有嘉宾感慨:“光伏逆变器里的MCU,以前就是个廉价执行者,谁便宜用谁。”然而,在今年的SNEC展会上,兆易创新展出的产品表明,那个时代已经是过去式了。 在光储充走向高功率、高安全、高协同的今天,MCU、模拟、存储不再是无足轻重的配角,而是决定系统性能天花板的“芯”力量。 兆易创新的路径提供了一种范式:不靠单点参数炫技,而用系统级思维将芯片深度融合;不追逐短期风口,而在技术深水区构建产品、生态、方案三位一体的长期壁垒。 毛明歌的阐述,恰恰印证了兆易创新在数字能源领域的理念:“让每一毫安电流、每一个比特数据、每一兆赫兹算力,都用在它该用的地方。”这或许就是数字能源芯片的终极逻辑。
兆易创新
兆易创新GigaDevice . 2026-06-15 1400

新品推荐 | 领慧立芯16位5MSPS SAR型ADC芯片LHA6961
在工业自动化、新能源、医疗仪器和汽车电子等领域,多通道高精度数据采集正成为系统设计的核心挑战。工程师不仅要应对严苛的精度与速度要求,还要在板卡面积、功耗和成本之间寻求平衡。苏州领慧立芯推出的新一代16位高性能SAR型ADC芯片——LHA6961就是为应对此挑战而设计的。 图:LHA6961实物图(来源:领慧立芯,下同) LHA6961 主要特性 LHA6961芯片采用了先进工艺设计,实现了16位高分辨率、5MSPS高速采样与超低功耗的平衡。其核心特性主要体现在一下几个方面。 图:LHA6961结构框图 高分辨率与高线性度 零温度系数点(ZTC)是MOSFET设计中的一个关键参数,它决定了器件在不同工作状态下的热稳定性。 LHA6961是一款16位分辨率、无失码的SAR型ADC,吞吐速率高达5MSPS。芯片具备优异的非线性性能:积分非线性(INL)1LSB、微分非线性(DNL)0.3LSB,确保了极高的转换精度。动态性能指标同样突出:动态范围95dB、SNR 93.7dB、THD -109dB。这些特性使LHA6961在处理复杂模拟信号时表现出色,能够满足高端成像和精密测量系统的严苛要求。 全差分模拟输入与灵活基准电压 芯片支持全差分模拟输入,输入电压范围可选±4.096V或±5V。基准电压采用外部输入方式,支持2.048V(内部缓冲升压至4.096V)、4.096V或5V等多种配置,提升了系统设计的灵活性。 超低功耗设计 功耗控制是高性能ADC的核心竞争力之一。LHA6961在多种模式下实现极致低功耗: 回波时钟模式、5MSPS、外置基准缓冲:38.0mW 回波时钟模式、5MSPS、内置基准缓冲:58.5mW 自时钟模式、CNV± CMOS模式、5MSPS、外置基准缓冲:29.0mW 这一低功耗特性显著降低了系统整体能耗,特别适合便携式医疗设备和电池供电的高速采集系统。 简化的接口配置 LHA6961配备串行LVDS接口,支持自时钟模式和回波时钟模式,CNV±信号可选LVDS或CMOS模式,提供高速、可靠的数据传输解决方案。该接口简化了与FPGA/DSP等数字后端的连接,优化了PCB布局和系统集成复杂度。 高可靠性和宽温特性 芯片在全温度范围内保持稳定性能,结合高集成度与小型封装,为终端产品的小型化、轻量化与高可靠性提供了坚实保障。 此外,LHA6961采用32引脚5mm×5mm QFN封装,工作温度范围为-40℃~+125℃,适合工业级、医疗级及严苛环境应用。 主要应用场景 LHA6961凭借高精度、高速度、低功耗和高可靠性的综合优势,广泛应用于数字成像系统、数字X射线机、医学数字断层扫描(CT)、红外摄像头、核磁共振检查(MRI)梯度控制高速数据采集、光谱分析等应用场景。
领慧立芯
芯查查资讯 . 2026-06-15 1540
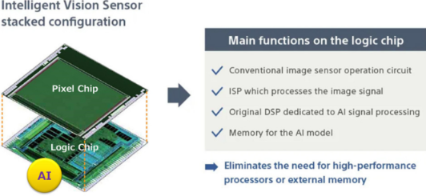
端侧AI | 传感器选型指南:四大核心能力与典型产品对比
重点内容速览: 1. 端侧AI 需要什么样的传感器? 2. 端侧AI时代,传感器会如何发展 过去二十多年,传感器与处理器之间一直存在着明确的分工,即传感器负责采集图像、声音、运动、振动和环境等原始数据,MCU、处理器或云端负责分析与决策。但随着AI推理向终端设备迁移,端侧AI的逐渐兴起,传统感知方式开始遇到挑战。例如摄像头 、毫米波雷达和高频振动传感器会持续产生大量数据;主处理器需要频繁唤醒;数据传输与处理增加了功耗和响应延迟;而且图像与声音数据如果上传云端的话会涉及隐私风险等等。 为了应对这些挑战,在新的端侧AI架构中,部分传感器开始承担数据筛选、特征提取、事件检测和轻量的AI推理任务。也就是说,传感器不再只是原始数据的生产者,而是开始承担初步判断的职责。 端侧AI需要什么样的传感器? 前面有提到,在端侧AI的系统架构中,开始将部分计算任务向感知端前移,例如简单的运动检测、语音活动监测和事件唤醒可以直接在传感器内部完成。更复杂的异常识别、目标分类,则可以由传感器中的可编程处理单元,或者紧邻传感器的AI MCU来执行。这种变化意味着感知、处理和推理之间的边界正在被重新划分。而且对传感器也提出了新的要求。 永远在线(Always-On) 低功耗感知虽然低功耗一直都传感器的重要指标,但端侧AI需要的低功耗,不只是降低采样时的工作电流,还要求传感器能够在主处理器休眠时持续感知环境,并判断什么时候该唤醒系统。 ADI的三轴MEMS加速度传感器ADXL367就是这一方向的典型代表。据芯查查提供的数据手册显示,ADXL367在100Hz输出数据速率下功耗为 0.89μA,运动触发唤醒模式功耗为 180nA,待机电流仅为 40nA。它还集成了可调阈值休眠与唤醒功能、敲击检测、状态机以及512个样本深度的FIFO。虽然这些功能不属于复杂的AI推理,却可以让系统在绝大多数时间内关闭主处理器,只在检测到有效动作后再启动后续分析,从而节省总系统功耗。 博世的BMI423是另一个方向。这颗IMU产品是CES 2026器件推出的,加速度量程达±32g、陀螺仪量程达±4000dps,加速度模式下电流仅25μA。更值得关注的是,BMI423集成了基于骨传导的语音活动检测(VAD),可以在麦克风休眠状态下判断是否有人说话,只在检测到语音时才唤醒主系统。这个功能本身就是一种轻量级感知分类。 由此可见,在端侧AI应用中,传感器不仅需要持续感知,还需要承担第一层判断,让系统只为有效时间消耗算力与能量。 从输出原始数据转向输出有效信息 传统传感器通常都追求更高的分辨率、更快的采样率和更大的数据吞吐量,但端侧AI则提出了另一个问题,系统是否真的需要处理传感器收集到的全部数据? 图:索尼IMX500系列AI传感器架构(来源:索尼) 索尼的IMX500系列传感器提供了一种不同的思路。该系列CMOS图像传感器采用堆叠架构,将1230万有效像素的像素芯片与逻辑芯片集成在一起。逻辑芯片中包含ISP、AI处理DSP和模型存储器,可以在图像传感器内部完成AI处理。IMX500可以不输出完整的图像数据,而是直接输出AI推理产生的元数据——例如画面中检测到的目标数量、位置坐标或事件标签。图像数据在传感器内部处理后不对外传输,从根本上解决了图像类应用的隐私问题。索尼已将IMX500应用于便利店客流分析场景,终端系统只收到统计数据,不接触任何人脸图像。 TI的IWRL6432是60GHz毫米波雷达领域类似方向的产品。这颗单芯片雷达传感器集成射频收发前端和信号处理核心,可以直接输出人体存在检测结果或点云数据,而非原始雷达回波。TI为其配套了Edge AI Studio工具链,支持工程师在IWRL6432上部署基于PyTorch训练的轻量级分类模型,实现人体与非人体目标分类、手势识别等功能,将传感器的输出从物理量提升为语义信息。 在芯查查看来,端侧AI应用中的传感器的价值衡量标准,正在从“采集了多少数据”,转向“过滤掉多少无效数据,输出了多少有效信息”。 从固定功能转向可编程AI 在传统智能传感器中,计步、倾斜检测、敲击检测等功能通常由厂商预先设计。终端厂商可以配置阈值和参数,却很难改变传感器内部运行的算法。端侧AI的发展,正在推动传感器从固定功能器件转变为可编程计算节点,允许工程师在传感器内部部署自定义信号处理算法或机器学习模型。 图:博世BHI385概述(来源:博世) 博世的BHI385就是这样一款产品。该传感器是一款可完全编程的六轴智能IMU,集成运动传感器、可编程处理器、AI软件和 256KB片上SRAM。其加速度计量程最高达到约±28g,陀螺仪输出数据速率最高达到6.4kHz,待机电流为8μA。配合Motion AI Studio,开发者可以针对运动追踪、冲击检测和体育动作识别等场景部署自定义机器学习模型。与只提供固定动作识别功能的IMU相比,可编程架构能够让同一颗传感器适应更多终端产品。此外,Bosch还推出了BMI5平台,延续了对可编程惯性感知的系统性布局。 图:ST的IIS3DWB10IS传感器(来源:ST) ST的ISPU系列也是这一路线比较成熟的一个产品系列。早期产品LSM6DSO16IS和ISM330IS搭载第一代ISPU,包含32位RISC处理器、8KB数据RAM和32KB程序RAM,支持C语言编程,可运行信号处理和AI算法,并带浮点运算单元(FPU)。ISM330ISN则支持通过ST的NanoEdge AI Studio生成机器学习库并部署至传感器。IIS3DWB10IS搭载的ISPU 2.0在第一代基础上新增硬件加速器,处理能力达40 MIPS/40 MFLOPS,是前代的最高4倍,MEMS接口速度提升最高6倍。 这意味着,传感器开始具备一定的软件定义能力,同一颗传感器产品,可以根据不同设备、工况和应用需求运行不同的算法。当然,您给所有的智能传感器都支持用于部署模型,但传感器从固定功能向可编程能力演进的趋势开始显现。 从单颗传感器转向分层协同 将算法放进传感器内部,虽然可以缩短响应时间、降低数据传输量,但也会受到芯片面积、功耗、存储容量和散热等条件的限制。因此,端侧AI系统将计算分布在了传感器、MCU、NPU和云端的不同层级上。 对于复杂的视觉识别、多传感器融合和工业异常检测任务,将传感器与邻近的AI MCU配合使用,往往更加灵活。 ADI的 Voyager4 无线设备健康监测平台便采用了这种架构。Voyager4集成ADXL382、ADXL367 MEMS加速度传感器、MAX78000 AI MCU以及 MAX32666 蓝牙MCU。在正常AI工作模式下,系统在本地完成异常检测,只向主机发送异常告警;如果需要进一步分析,用户再获取更多高带宽振动数据。 国内厂商也在采用类似路线。据芯查查了解,思特威旗下的飞凌微推出的A1 Camera AI SoC 集成自研NPU、Arm Cortex-A7和ISP,NPU算力为 0.8TOPS@INT8,支持双路图像传感器输入和最高120fps输入帧率。A1并不是图像传感器,而是紧邻图像传感器的视觉处理芯片。其作用是在摄像头端完成图像处理和AI推理,体现了典型的近传感器AI架构。 因此,端侧AI传感系统可以分为三个层级: 传感器内AI:算法直接在传感器芯片内部运行; 近传感器AI:算法运行在紧邻传感器的MCU、视觉SoC或专用处理器中; 设备端AI:算法运行在终端设备的主处理器或独立NPU中。 图:针对端侧AI应用的传感器新产品对比(来源:各公司官网,芯查查) 端侧AI时代,传感器会如何发展 过去几十年,传感器产品的主要关注点都集中在分辨率、精度、噪声密度、量程和功耗等几个维度,那么在端侧AI时代,传感器会如何发展呢?根据芯查查的总结,未来传感器的发展趋势主要有以下三个方向。 一是事件驱动会逐渐取代持续传输。端侧AI时代的传感器,并不一定持续输出完整数据,而是会优先判断环境是否发生变化。摄像头可以只输出运动目标,雷达可以只上报人员存在状态,振动传感器可以只在检测到异常频谱时唤醒系统等等。也就是说,事件驱动会逐渐取代持续传输。 二是AI能力将成为传感器的重要功能。过去,工程师选择传感器主要关注精度、量程、噪声、采样率、接口和功耗。随着AI进入感知端,选型维度还将包括: 是否支持自定义算法或模型; 可以运行哪些类型的模型; 片上处理与存储资源有多少; 能否直接输出事件或语义信息; 单次判断需要消耗多少能量; 是否提供数据采集、训练与部署工具; 是否可以与外部传感器进行数据融合。 三是工具链将成为标配。当传感器支持可编程算法后,硬件参数只是产品能力的一部分。索尼围绕智能视觉传感器推出AITRIOS平台;博世通过Motion AI Studio帮助开发者训练和部署运动识别模型;ST为ISPU提供开发工具与算法生态;TI也在通过Edge AI Studio扩展毫米波雷达和处理器的AI开发能力。也就是说,未来传感器厂商不仅要提供芯片,还需要提供算法库、训练工具、模型部署流程和参考方案。 结语 端侧AI时代的传感器不只负责看见、听见和测量,还需要决定哪些信息值得交给系统。面对集成ISPU、DSP、硬件加速器和可编程处理单元的新型传感器,工程师的选型工作也变得更加复杂。除基础电气参数外,还需要综合评估算法支持、片上资源、功耗模式和开发生态。 通过芯查查可以快速查找到所需芯片的数据手册,再加上中电港芯查查新推出的【数字FAE】,工程师可以快速生成参考方案,对比关键参数、寻找可替代型号,并辅助评估传感器与MCU、边缘AI处理器的组合方案,助力方案快速落地。
端侧AI
芯查查资讯 . 2026-06-15 1267

展会 | IICIE国际集成电路创新博览会赋能半导体产业,直击产业前沿 ——三展联动34万展示面积,链接全球优质资源
2026年9月9—11日,IICIE国际集成电路创新博览会(简称IC创新博览会)将在深圳国际会展中心(宝安)盛大举办。展会构建芯片及芯片设计、晶圆制造、封装测试、核心设备、关键材料及核心零部件的全链条生态布局,打造集产品展示、技术交流、商贸洽谈、创新研讨于一体的半导体制造产业综合型展会平台,为全球半导体产业高质量发展注入新动能。 热点技术齐聚,精准锚定产业前沿。本届展会紧扣2026年半导体行业发展趋势,聚焦AI算力、HBM、光刻技术、先进制程、先进封装、设备材料国产化突破、第三代半导体、光电子融合等行业核心热点,集中呈现全球半导体领域的前沿技术与创新成果,助力参展企业精准把握技术迭代节奏,抢占国产替代战略机遇,破解行业发展瓶颈。 三展联动发力,规模效应凸显。IC创新博览会将与CIOE中国光博会、elexcon深圳电子展同期举办,总展示面积达34万平方米,汇聚超5000家参展企业,预计吸引专业观众超24万人次,深度联动半导体制造、集成电路、光电、电子嵌入式等核心领域,实现多产业协同赋能,构建全方位、多层次的产业交流合作体系。 全球资源汇聚,国际买家精准覆盖 依托三展强强联动的平台优势,本届展会重磅打造全球化高端买家矩阵,精准覆盖美国、德国、英国、印度、印尼、马来西亚、日本、韩国、新加坡等多个国家及地区的专业观众,实现海外优质采购资源的全面触达,助力参展企业高效链接全球市场,拓宽国际合作渠道。 众多海外知名企业观众将齐聚现场,包括但不限于:AGC、ASM International、ASMPT、DENSO、GlobalFoundries、Marvell、Tower Semiconductor、OSI 电子、尼康、佳能、应用材料、东京电子、科磊、泛林、爱德万测试、迪斯科、陶氏化学、霍尼韦尔、巴斯夫、三星半导体、联电、联合科技、英特尔、索尔思、英伟达、德州仪器、英飞凌、意法半导体等。(仅部分企业,排名不分先后) 全链对接赋能,覆盖多元化产业及应用群体 依托三展联动的专业平台,展会实现上下游资源一站式高效对接,全面打通“芯片-器件-模块-方案-应用”全产业链生态。参展企业不仅能精准对接IDM、Fabless、Fab、OSAT等半导体核心领域观展观众,还能直面人工智能、消费电子、汽车、通信及计算、显示、光电、新能源等下游应用领域的专业群体,一站式高效赋能下游关键领域发展。同时,参展企业可与同台亮相的优质展商深度交流,共探产业未来发展趋势、共谋合作机遇,大幅提升参展价值;对于观众而言,展会推出一证通逛三展便捷服务,可大幅提升参观效率,实现一次参观、全链收获。 产学研深度融合,加速创新成果转化 本届展会深度联动国内外顶尖科研院所、高校及重点实验室,集中展示半导体领域前沿研发成果,构建“研发—转化—落地”全链条一体化创新生态,推动技术成果快速产业化,助力产业创新能力提升。部分参展机构及高校包括:广东中科半导体微纳制造技术研究院、香港科技大学霍英东研究院、中山大学集成电路学院、广东省大湾区集成电路与系统应用研究院、深理工算力微电子学院、清华大学集成电路学院、香港科技大学、北京理工大学集成电路学院、上海交大无锡光子芯片研究院、深圳职业技术大学集成电路学院、华南师范大学微电子学院、深圳技术大学集成电路学院、深圳先进电子材料国际创新研究院等。 形成半导体制造完整矩阵 龙头企业同台发力 展会搭建“制造 —封装 —设备 —材料 —零部件” 半导体完整产业矩阵,汇聚海内外行业龙头,全方位展示产业核心实力: 晶圆制造及封装测试:上海华力、东方晶源、晶合集成、比亚迪半导体、通富微电、时代民芯、云天半导体、华进半导体、佰维存储、天芯互联等企业齐聚亮相,集中展示核心技术与综合服务彰显硬实力; 半导体设备:北方华创、中微半导体、盛美上海、拓荆科技、沈阳和研、御渡半导体、华海清科、微崇半导体、华煜半导体、隆友德、精测电子、中电科、华卓精科等企业聚焦光刻、刻蚀、量检测等关键环节,展示半导体设备核心技术与创新; 半导体材料:沪硅产业、江丰电子、安集科技、中船特气、上海新阳、上海集成电路材料研究院、清溢微等企业,将带来硅片、靶材、特种气体等关键材料,支撑产业链自主可控升级; 半导体核心零部件:中科仪、新松半导体、万瑞冷电、上银科技、新莱集团等企业将展示半导体核心零部件及智能制造解决方案; 三展联动,同期汇聚半导体制造及封测优质参展商:如GlobalFoundries、Tower Semiconductor、ASMPT、日月光、环旭电子、施密科、润华全芯微、琦升、京创先进、和研、猎奇、普莱信、纬迪、诺顶、触点、世禹、翼龙、大成、众望赛米控、中科精工、中科光智、镭神、尚进、驿天诺、智立方、柯泰光芯、普赛斯、ISMC、骏河精机、鼎企、德瑞精工、三英精控、恩纳基、博众半导体、创世杰、微见智能、牛津仪器、吉永商事等。(仅部分代表企业,排名不分先后) 芯片展区发力,全品类覆盖引领行业发展 芯片作为产业核心,展会将集中呈现AI 芯片、通信芯片、存储芯片、CPU、传感器、模拟/数字芯片、电源管理、射频、驱动芯片等全品类产品。展会目前吸引中兴微电子、北京君正、澜起科技、华大九天、广立微、兆芯集成等企业集中亮相,全面展示国产芯片在高性能、高可靠、车规级、工规级领域的技术突破,打通“芯片—方案—终端”落地路径。 三展联动,ARM、瑞萨、玄铁、灵动、国民技术、光羽芯辰、德明利、东芯、朗科、康盈、上海贝岭、扬杰、科达嘉、信维、信安半导体、芯控源、 台懋半导体、研华、飞凌、创龙科技、星宸、艾迈斯欧司朗、Coherent高意 、索尔思、兆易创新、三菱电机、三安光电、瑞识、睿熙科技、焜腾、海思、海信、芯思杰、奇芯、铌奥光电、长光华芯、国科光芯、仕佳、鼎芯、剑桥科技、云岭、光森、纵慧芯光、优迅股份、明夷科技、工研拓芯、橙科微、米硅、LUXIC功芯科技、光梓、贝岭等众多优质企业也将同期参展,共筑芯片发展新格局。(仅部分代表企业,排名不分先后) 高规格论坛同期举办,海内外大咖共话产业 本届展会的同期会有论坛将突出高端化、国际化、专业化,打造全球半导体“思想高地”。超20场专业论坛聚焦半导体制造、先进封装及测试、化合物半导体、智能制造、芯片及芯片应用等主题,精准破解核心技术瓶颈与供应链协同难题。 如国际集成电路创新高峰论坛将邀请行业内顶尖院士专家、龙头企业负责人,围绕“AI 赋能”“芯云协同”“半导体产业链供应链韧性”等核心议题展开巅峰对话,探讨切实可行的解决方案;第十届国际先进光刻技术研讨会(IWAPS2026)覆盖光刻机、量测到光刻胶材料的全链条生态,美国KLA、德国Siemens、日本Fujifilm等国际巨头及全芯智造、东方晶源等国内领军企业将深度参与;全球集成电路产业分析师大会将汇聚25个国家的行业智库,预判2026-2030年半导体市场周期与产能布局。 此外,半导体制造及先进封装与测试主题会议,深耕产业链核心环节,聚焦HPC封装技术突破、异构集成、AI异质整合封装之关键材料、核心零部件国产突破等,致力破解行业“卡脖子”难题;芯片设计及应用系列论坛聚焦AI、消费电子、汽车、RISC-V、工业、智能终端等热门应用领域,搭建“芯片技术与终端需求”的对接桥梁。 三展联动,同期更多半导体产业相关会议,如光电融合技术与产业发展论坛、光学半导体检测技术论坛、超精微/纳米光学制造技术论坛、纳米压印制造技术论坛、激光技术赋能半导体制造论坛等。 扫码预定展位! 目前,展会展位预定已超过80%,正火热进行中,即刻预订及咨询展位,可快人一步链接半导体产业链优质资源。为方便观众参观,展会推出一证通逛三展便捷服务,点击此处一键报名观众完成登记即可一次性参观 IICIE、CIOE、elexcon 三大展会。诚邀各界人士于9月齐聚深圳,共赴这场半导体产业盛会,携手共筑产业新生态。 展会官网:www.iicieexpo.com
展会
IICIE国际集成电路创新博览会 . 2026-06-12 1806

企业 | SK海力士再发生火灾
当地时间6月12日上午9时50分左右,SK海力士位于韩国忠清北道清州市的四号园区M15X工厂二楼燃气房发生火灾,约4000名员工紧急疏散。 这是该厂区本月发生的第二起火灾事故,距6月1日首次火灾仅隔11天。 据SK海力士及消防部门通报,工厂内部自动喷水灭火系统及时启动,火势得到有效控制,未发生气体泄漏,也未造成人员伤亡。公司方面表示,正在调查起火的确切原因,以及是否对生产设施造成影响。 前序事故频发,安全管理受质疑 6月1日上午,同一园区连接M15与M15X厂房的六楼气体室也曾发生火灾,当时约3600名员工疏散,自动喷淋系统虽控制了明火,但约5–6ppm的氟气体泄漏,导致7名工人送医治疗。两次火灾的起火点均为气体室——芯片制造中用于存储和输送特种工艺气体的关键区域。 此外,6月10日该厂区还发生了一起化学品相关事故,两名工人住院。11天内三起安全事件,已使外界对SK海力士清州园区的安全管理体系产生严重关切。 M15X:HBM与先进DRAM的核心产能基地 M15X是SK海力士专门面向AI芯片需求打造的核心产能基地,主要用于生产高带宽内存(HBM)及先进DRAM。据公开信息,SK海力士在M15X工厂及配套设备上的投资约20万亿韩元,工厂于2025年竣工并逐步投入运营,旨在巩固其在全球HBM市场的领先地位。 据Counterpoint Research数据,作为英伟达HBM核心供应商,SK海力士一季度全球HBM市场收入份额高达58%。SK集团会长崔泰源6月初亦透露,公司计划五年内将晶圆产能翻番。 HBM是AI算力的核心咽喉。目前全球能量产高端HBM的仅有三家公司:SK海力士、三星电子、美光。其中,SK海力士清州M15X产线正是其HBM4扩产的核心阵地。 当前全球HBM产能已处于极度紧张状态。据行业数据,HBM产能缺口已达到40%–60%,2026年全球HBM产能已被头部客户全部预订。SK海力士及美光2026年的HBM产能,早已被英伟达等巨头以长单锁定。在此供需格局下,任何产能波动都不再是“虚惊一场”。 尤其值得关注的是,据年初韩媒报道,SK海力士已拿下英伟达HBM4超过三分之二的供应订单,且双方已于2026年6月7日宣布建立多年期技术合作伙伴关系。SK海力士的任何交付节奏变化,都将直接传导至英伟达下一代AI加速器Vera Rubin的出货计划。若安全审查导致交付延期,三星和美光虽已获得HBM4供货资质,但能否在短期内填补订单缺口仍是未知数。
存储
芯查查资讯 . 2026-06-12 1 1 1435

企业|中微爱芯五款车规芯片成功入选《国产车规芯片可靠性分级目录(2026)》
近日,第十三届汽车电子创新大会(AEIF 2026) 在上海成功召开。同期,《国产车规芯片可靠性分级目录(2026)》(以下简称“目录”)正式公布,中微爱芯五款车规级产品通过评定并列入目录! 该目录旨在加速突破车规芯片国产替代,保障汽车产业链、供应链安全稳定,并协助整车企业和零部件厂商快速掌握国内车规级芯片产品信息及应用状况。 入编产品一览 中微爱芯聚焦汽车电子行业国产化需求,持续打磨车规级芯片的性能与可靠性,不断推出高质量、高可靠性的国产化芯片方案,为汽车智能化、电气化、绿色化发展提供核心支撑。未来,中微爱芯将继续坚持创新驱动,深耕芯片领域,迭代优化产品与解决方案,携手更多汽车行业伙伴,共同推动国产汽车电子产业高质量发展。
车规芯片
中微爱芯官网 . 2026-06-12 511

产品 | 超低噪・高保真,中微爱芯低噪声运放新品
无锡中微爱芯专注高性能模拟芯片研发,打造覆盖通用、高精度、轨到轨、宽压、抗浪涌全场景的低噪声运算放大器矩阵。产品可满足微弱信号放大、低失真、低噪声、高稳定等核心需求,广泛适配消费电子、工业仪器、音频 HiFi、精密传感等领域,是性能对标国际品牌、供货稳定、成本更优的国产替代优选方案。 【产品特点】 (一)AiP4580 系列:经典音频级低噪声双运放 音频级低噪声高保真:典型噪声低至 6.5nV/√Hz@1kHz,总谐波失真≤0.0005%,完美还原音频信号细节 宽电压高抗扰:支持 ±2~±18V(4~36V)宽电源电压,CMRR/PSRR 最高 110dB,工业 / 消费级场景通吃 抗浪涌专属防护:升级版电路可直接承受 220V 交流浪涌冲击,适配严苛信号处理场景 经典型号完全兼容:Pin-to-Pin 直接兼容 NJM4580 主力型号:AiP4580、AiP4580S、AiP4580P(抗浪涌升级版) (二)AiP4558 系列:经典通用低噪声双运放 成本优选 极致性价比:性能对标行业经典通用型号,批量采购成本优势显著,是成本敏感型产品的首选 宽电压高适配:支持 ±1.5~±18V(3~36V)宽电源电压,静态电流仅 2mA/CH,低功耗设计适配电池供电场景 抗浪涌防护升级:专属电路可直接承受 220V 交流浪涌冲击,适配工业级严苛环境 经典型号完全兼容:Pin-to-Pin 直接兼容 NJM4558 主力型号:AiP4558、AiP4558S、AiP4558P(抗浪涌升级版)、AiP4558L(低电压优化版) (三)AiP24580 系列:四通道低噪声运放 高集成度专用 四通道高集成设计:单芯片集成 4 路独立低噪声运放,集成度高 性能无衰减:每通道典型噪声 6.5nV/√Hz@1kHz,带宽 12MHz,多通道无串扰 工业级高可靠:CMRR/PSRR 100dB,抗干扰能力强,完美适配工业多通道采集场景 主力型号:AiP24580 (四)AiP553x 系列:高性能音频低噪声运放 经典平替 全系列超低噪声:典型噪声低至 5nV/√Hz@1kHz,人声/乐器细节还原拉满,HiFi 级听感 高带宽高动态响应:增益带宽积最高 24MHz,压摆率 6V/μs,大动态信号无失真,适配专业音频前级、耳机放大场景 经典型号完全兼容:Pin-to-Pin 直接兼容 NE5532/NE5534 主力型号:AiP5532(双声道)、AiP5534(单声道高性能版) (五)AiP871x 系列:低压低功耗轨到轨低噪声运放 便携专用 极致低压低功耗适配:支持 ±1.1~±2.75 (2.2~5.5V)单/双电源工作,单通道静态电流仅 0.7mA,关断电流低至 μA 级,大幅延长电池续航 轨到轨输入输出:单电源下信号摆幅拉满,无需负压电源,大幅简化便携设备电路设计 超小封装灵活适配:覆盖 SOT23-5/SOP8/MSOP8 等超小封装,完美适配便携设备紧凑型 PCB 设计 主力型号:AiP8711(单通道)、AiP8712(双通道)、AiP8714(四通道)、AiP8713/19(带使能关断版) (六)AiP872x 系列:中带宽低压轨到轨低噪声运放 性能功耗平衡 性能功耗黄金平衡:单通道静态电流仅 1.3mA,带宽提升至 10MHz,比同功耗竞品带宽高 60%,兼顾续航与信号处理速度 全场景灵活适配:±1.1~±2.75 (2.2~5.5V)单/双电源工作,轨到轨输入输出,适配绝大多数低压模拟场景 高抗干扰高稳定:CMRR/PSRR 100dB,适配消费类与工业级低压场景 主力型号:AiP8721(单通道)、AiP8722(双通道)、AiP8724(四通道)、AiP8723/29(带使能关断版) (七)AiP873x 系列:高速低噪声低压轨到轨运放 精密传感专用 高速低噪声双优性能:典型噪声低至 7.3nV/√Hz@1kHz,带宽高达 20MHz,是同电压等级下噪声最低、带宽最高的国产运放之一 精密信号无失真:轨到轨输入输出,压摆率高,高频小信号无失真,完美适配精密传感器的高频信号放大 主力型号:AiP8731(单通道)、AiP8732(双通道)、AiP8734(四通道)、AiP8733/39(带使能关断版) (八)AiP877x 系列:低失调轨到轨低噪声运放 精密通用 低失调高精度:典型输入失调电压仅 300μV,比通用运放失调低 50%,高精度信号放大无偏移,无需额外调零电路 单双电源通用:支持 ±2.2~±8V 双电源、2.2~16V 单电源工作,轨到轨输入输出,适配绝大多数通用模拟电路设计 高集成度低成本:覆盖双 / 四通道,封装覆盖 DIP8/SOP8/TSSOP8,Pin-to-Pin 兼容国际主流型号,成本优势突出 主力型号:AiP8772(双通道)、AiP8774(四通道) 【产品优势】 极致低噪声,微弱信号无失真 全系列噪声最低可至 5nV/√Hz,音频底噪干净通透,传感器小信号清晰还原,高阻抗源信号处理更纯净。 2. 带宽与压摆率全场景覆盖 带宽覆盖 2.2MHz–24MHz,从低速通用到高速采集全覆盖;压摆率覆盖 1.7V/μs–12V/μs,大信号瞬态响应干净利落。 3. 宽压兼容,单 / 双电源灵活适配 低压轨到轨系列支持 2.2~5.5V 单电源,是便携设备首选;宽压音频 / 工业系列支持 ±2V~±18V,兼容工业与车载环境;全系列支持单电源 / 双电源,设计无需改架构。 4. 高精度直流特性,系统运行更稳 输入失调电压最低可至 0.25mV,温漂小、零点稳;CMRR/PSRR 高达 110dB,可强效抑制共模干扰与电源纹波;AiP87XX 系列输入偏置电流达 pA 级,可直接驱动高阻抗传感器。 5. 封装齐全,量产落地更省心 覆盖 SOT23-5/6、SOP8、MSOP8、DIP8、SOP14、DIP14、TSSOP14 全主流封装,贴片/直插齐全,小体积适配便携设备、大封装散热优异,满足不同结构需求。 6. 全温稳定,工业级高可靠 工作温度覆盖 -40℃~85℃(部分型号支持-40℃~125℃),内置过温保护、ESD防护,长期运行稳定可靠。 【应用领域】 音频/音响/HiFi设备 精密传感/仪器仪表/数据采集 便携/穿戴/电池供电智能设备 工业控制/通用信号放大/严苛环境工控 【结语】 中微爱芯低噪声运算放大器家族,以低噪声、高精度、宽适配、高可靠,重新定义国产运放价值。无论是追求极致音质的音频设备,还是需要精准采集的工业仪器,或是严苛环境的便携产品,都能提供高性能、低成本、易量产的一站式信号链解决方案。 选择中微爱芯,选择稳定、高效、高性价比的国产芯力量! 中微爱芯低噪声运放选型表:
低噪声运放
中微爱芯官网 . 2026-06-12 700
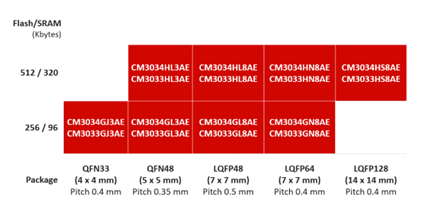
- 1
- 14
- 15
- 16
- 17
- 18
- 500