产品 | 赋能中大功率音频升级!AW85805STSR&AW85807TSR,SKTune神仙®算法+PTC智能省功耗双buff!
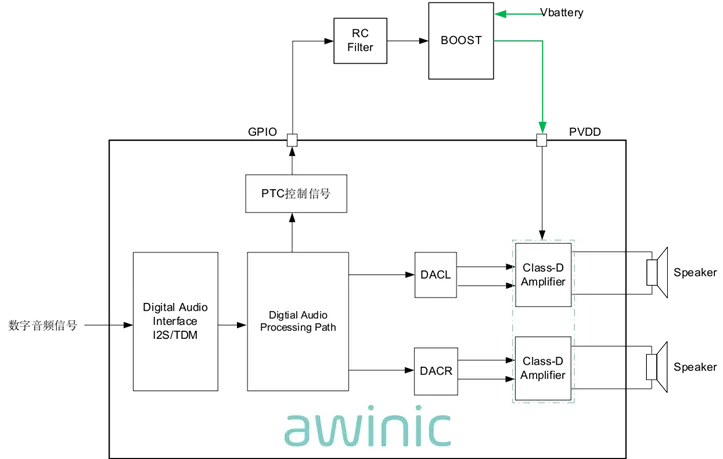
随着智能电视大屏化、家庭影音沉浸化、服务机器人智能化升级,20~30W 功率段的中大功率音频方案,已成为终端产品打造差异化竞争力的核心关键。无论是客厅里的大屏电视与 Soundbar、居家与商用的智能音箱,还是服务机器人、智能显示终端等设备,都对音频功放的大功率输出稳定性、高保真音质、能效表现与集成化设计提出了更高要求。 深耕高性能音频赛道多年,艾为电子正式推出AW85805STSR、AW85807TSR两款中大功率数字输入高效 D 类音频功放。系列产品精准聚焦 20~30W 主流中大功率音频需求,依托艾为全链路自研音频技术积淀,搭载新一代高效功放架构、高性能飞天™DSP 与 SKTune 神仙®算法,形成梯度化产品布局,全方位覆盖智能电视、家庭音箱、服务机器人、商用智能终端等核心场景,为终端产品带来澎湃稳定、高保真的沉浸式音频体验。 能效越级优化,大功率低功耗标杆 AW85807TSR 专为中大功率场景深度优化,主打同功率段行业领先的低功耗表现,搭载智能功率跟踪技术,中小音量场景能效提升 15% 以上,兼顾满功率澎湃输出与超低待机功耗,完美解决能效痛点。内置高性能飞天™DSP,集成声场环绕、AI杂音抑制,自适应功耗优化等多项艾为特色音频算法,音质更纯净、低音更饱满、声场更沉浸,全方位提升听觉体验。 核心规格: 工作电压:4.5V~20V 内置飞天™DSP+ SKTune 神仙 ® 音频算法 输出功率: · BTL:2×30W@4Ω,18V,THD+N<1% · PBTL:1X60W@2Ω,18V,THD+N<1% 超低音频失真:THD+N≤0.02%(12V, 6Ω, 1W, 1kHz) 超低失调电压:±3mV 低噪声:28uVrms @LLM PVDD=18V 支持PTC动态升压 支持扩频功能 效率高达 90%+ 封装: TSSOP28 飞天™DSP + SKTune 神仙 ® 音频算法,强强联合 AW85807TSR 搭载艾为飞天™DSP,并加持SKTune 神仙 ® 音频算法,除支持经典 DRC、EQ 功能外,更集成艾为声场环绕、低频增强、智能杂音抑制等特色音效算法,音质细腻动听、声场开阔沉浸。同时内置自适应功耗优化算法及低温、低压智能保护机制,在提升听觉体验的同时,有效增强续航表现与整机系统稳定性。 Power Tracking Control 高效能利器: 可动态调节片外DC-DC所提供的PVDD电压,保持足够的电压余量;提供足够大的音频信号动态范围,防止信号截顶失真,可以有效提高音频系统效率,整体功率优化20%+。 图1 AW85807TSR PTC功能框图 图2 AW85807TSR应用原理图 适配场景:便携音箱、具身机器人、蓝牙音箱、服务机器人、智能家居&IoT设备等 12~20V 系统专项优化,主流中大功率场景精准适配 AW85805STSR 专为行业主流 12~20V 供电系统深度定制优化,在该电压区间内实现最优的能效表现、失真控制与功率输出稳定性。 核心规格: 工作电压:4.5V~20V 内置飞天™DSP+ SKTune 神仙 ® 音频算法 输出功率: · BTL:2×25W@4Ω,18V,THD+N<1% · PBTL:1X35W@4Ω,18V,THD+N<1% 超低音频失真:THD+N≤0.02%(12V, 6Ω, 1W, 1kHz) 超低失调电压:±3mV 低噪声:30uVrms @LLM PVDD=12V 支持扩频功能 效率高达 90%+ 封装: TSSOP28 高效低耗,显著降低发热: 12V 电压下效率高达 94%,18V 下高达 91%,高效输出更节能; 整机发热量降低超 30%,长时间大功率工作依旧稳定可靠,散热压力大幅减轻。 强劲音频性能,音质全面越级 超低底噪仅 28uV,较行业同类产品降低 25%,声音更纯净通透; 失调电压低至 ±3mV,仅为友商水平的 1/2,显著抑制开关机 / 切换 POP 音,听感更顺滑; 失真表现优异,THD 低至 0.02%,较同类产品降低 30%,大音量输出依然稳定细腻。 特色 DEE 智能算法模块: 可针对特定频点杂音进行精准增益调节,不破坏整体音色,高效消除干扰杂音; 支持智能动态增益控制,小音量场景自动增强低音表现,让低频更震撼、更有层次感。 图3 AW85805STSR原理图 适配场景:智能电视、智能音箱,桌面音箱,Soundbar、商用智能显示终端、智能家居&IoT设备等 此次新品发布,进一步完善了艾为在中大功率音频赛道的产品矩阵,为各类终端提供了全自主可控的梯度化国产音频解决方案。未来,艾为将持续深耕高性能模拟与混合信号 IC 领域,以自研技术突破性能边界,助力终端音频体验持续升级。
音频
艾为官网 . 2026-03-20 427

企业 | ADI启用泰国新工厂,强化全球制造韧性
近日,全球领先的半导体公司ADI宣布公司在泰国新落成的先进制造工厂已经正式启用。此举将进一步提升ADI的先进制造与测试能力,同时推动公司在亚太地区形成更具韧性和可持续性的半导体生产布局。此次扩建基于ADI的混合制造战略,依托由内部工厂、外部代工厂与外包半导体组装和测试(OSAT)合作伙伴构成的全球网络,打造兼具韧性与高性能的解决方案。 泰国在ADI全球制造网络中发挥着至关重要的作用。通过扩大ADI在泰布局,提升制造韧性、灵活性与产能规模,为多元市场客户提供支持,从而有力支撑公司的长期发展。新工厂的定位是智能可持续工厂,融合先进自动化、数字化制造技术与完善运营体系,兼顾高效生产与绿色环保,能够更快响应市场需求,并在瞬息万变的全球环境中,持续提供客户所期望的品质、可靠性与性能。 Analog Devices首席执行官兼董事会主席Vincent Roche(左)与Analog Devices泰国董事总经理Wirat Sri-amonkitkul(右),共同出席ADI泰国先进制造工厂开业剪彩仪式。 ADI首席执行官兼董事会主席Vincent Roche表示:“泰国是ADI全球制造布局中的战略枢纽之一。此次扩建彰显了我们长期致力于将泰国及该地区打造为能够可靠且可持续地提供世界级技术的关键环节的决心。随着客户需求的不断演变,此次扩建投资将确保我们能够持续大规模交付独具优势的创新成果。” ADI全球运营与技术执行副总裁Vivek Jain指出:“新工厂极大提升了我们高效且负责任地开展测试业务的能力。凭借当地雄厚的工程人才储备、供应链优势以及支撑长期发展的产业环境,泰国已成为我们构建更加敏捷、更具韧性且面向未来的制造网络的重要一环。” 升级全球封装与测试中心 Analog Devices Thailand (ADTH)成立于2000年,是ADI最重要的后端制造基地之一,为工业、汽车、通信、消费电子与数字医疗等市场提供支持。新工厂大幅扩充了超净间与制造产能,使ADI在测试、晶圆级工艺、芯片级封装及集成电路终测等环节实现规模化运营。新工厂作为创新与自动化枢纽,融合了先进制造技术,有效提升生产效率、精度与智能化运营水平。同时,该工厂还实现了更加智能的工艺流程,强化了ADI的整体制造能力,助力团队在日常工作中创造切实价值,在保持高品质标准的同时,更快响应客户需求。 提升全球供应链韧性 通过更广泛的区域布局、更高的运营敏捷性以及增强的制造网络灵活性,ADI在泰国的扩产增能举措强化了公司的全球韧性战略。新工厂坐落于泰国东部经济走廊(EEC),得益于当地完善的基础设施、优质的工程人才储备和稳定中立的运营环境,将进一步强化ADI服务全球客户的能力。 推动半导体制造可持续发展 新工厂依照LEED标准规划建造,彰显了ADI践行绿色制造的坚定承诺,也是ADI制造网络中首个以获得LEED铂金级认证为建设目标的工厂。从搭载高效的节能系统和推行资源优化管理,到为提升员工福祉而精心设计的人性化空间,新工厂不仅为追求卓越效能而建,也承担了保护地球环境的责任。此次扩建工程为ADI践行更广泛的可持续发展承诺提供有力支撑,具体包括实现100%可再生电力供电、采用节能型设施设计、升级水循环利用系统、搭建环境绩效实时监测体系。此外,ADTH还是泰国首家采用低碳液氮的半导体制造商,此举进一步降低了测试环节的碳强度,巩固了ADI在可持续半导体制造领域的领先地位。 培育泰国半导体人才生态 ADI通过ADI泰国学院及与泰国顶尖高校开展合作,持续加码泰国半导体人才生态的建设。这些举措旨在提升测试工程、自动化、失效分析及智能工厂技术等领域的工程与技术能力。同时,通过进一步扩大实习项目规模与推进人才长期培养计划,新工厂将进一步助力培养新一代半导体人才,从而持续强化ADI在当地及全球的工程能力。
ADI
亚德诺半导体 . 2026-03-20 1540

应用丨海康威视×上海海思:轻智能直播摄像机,焕新直播画质再升级
近年互联网直播经济爆发式增长,全球市场规模超千亿美元,中国市场尤其火爆。 《中国网络视听发展研究报告(2025)》显示,我国网络直播用户规模为8.33亿,占网民总数的75.2%,职业主播规模已达到3880万人,日直播场次已经超过350万次。 庞大的市场体量与创作需求,正推动直播设备向专业化、智能化、场景化加速迭代。 AWE2026上海海思展台展示海康威视基于上海海思Hi3403 SoC平台打造的Master Pro直播摄像机,凭借其“高画质·超稳定·易上手”获得众多观众青睐,赋能互联网直播画质再升级。 高画质:8K原生采集 单反级影像直出 直播机采用单反机,F2.8大光圈专业级变焦镜头、1.6英寸半画幅CMOS传感器,与上海海思Hi3403主控SOC旗舰组合,可以实现8K原始超清画面采集,6K@30fps画面直出。 设备采用定制大光圈镜头,原生光学虚化精准聚焦主体;3D多维对焦,对2mm×2mm尺寸小首饰特写只需0.03秒疾速对焦,细节呈现分毫毕现;RGB24原彩直出,捕捉超1677万种颜色单元,无需采集卡即可直连电脑输出原彩画面,大幅降低专业直播搭建门槛。 超稳定:24小时不间断直播 依托20+年丰富摄像机经验积累,直播机融合了运动相机和安防相机技术,在散热与长期可靠性上实现突破。 设备通过温敏电阻 + 内置散热风扇实现精准主动控温,可支持24小时连续稳定直播,机身表面温升<10℃,彻底解决长时间直播发热、卡顿、降质等行业痛点,全天候输出稳定画面。 易上手:一键调优 专业画质轻松可得 直播机配套HIK IN Pro软件,简化调试过程,定制化调试焦距、图像、灯光等参数,一次调好终身快捷调用。 用户可自定义对焦区域,随心切换拍摄重点;更搭载莫奈调色系统,针对特定的使用场景,支持对画面色相、饱和度、亮度(HSV)进行专业级精细调节,杜绝画面偏色,零基础也能调出直播间高级质感。 丰富芯片方案加持 ,推动直播影像持续演进 上海海思提供Hi3559、Hi3403、Hi3519A、Hi3519D、Hi3516CV610等多颗芯片和直播摄像机解决方案支持直播影像持续演进。 上海海思直播摄像机方案提供了丰富的接入能力,集成多种音视频编解码协议,支持HDMI、USB3.0、网口输出,适配多种主流Sensor,支持PDAF/CDAF/ITOF等混合对焦方式,并可扩展IMU等融合感知能力。 软件SDK中,提供了优化后的单反级画质ISP配置Profile、PDAF算法调用接口,方便开发者快速集成开发。 未来直播场景从室内走向户外、从专业主播走向全民普及,上海海思将持续发挥芯片 + 系统 + 算法全栈优势,深度整合越影视觉、星闪穿戴、巴龙无线等技术能力,针对性解决移动直播、户外直播等场景痛点,推动直播设备更轻便、连接更稳定、画质更出色,以技术创新持续赋能直播影像体验升级,助力全民直播时代高质量发展。
上海海思
海思技术有限公司 . 2026-03-20 2051

企业 | “情绪黑洞”撞上AI超能力?移远通信&次元造物,搞点不一样的!
深夜emo时,你是否也曾对着手机敲下一串字,又在发送前默默删掉?人类的社交有时太复杂,而那些琐碎、突然的情绪更难被妥善安放;当你试图将它们切片,寻找一个AI作为临时容器时,它却偏偏“大脑宕机”,陷入“漫长”的沉默——延时与卡顿,让原本汹涌的情绪迅速冷却,无处可泄。 别急,有这样一对“懂灵魂”的新朋友,正从次元裂缝里悄悄钻出来。获得科大讯飞投资的次元造物推出两大“新物种”——“小鸟屁屁”与“玄猫又又”。它们不聊大道理,不给你安排KPI,而是用毛茸茸的外表和“我懂你”的回应,接住你所有说不出口的疲惫与不安。 “情感经济”正以高情绪价值、强精神寄托与个性化互动体验,成为驱动年轻群体消费增长的核心动力。作为全球领先的物联网整体解决方案供应商,移远通信前瞻洞察情感消费与AI硬件融合的趋势,基于移远4G AI陪伴整体解决方案打造的稳定网络连接,成功赋能次元造物,为其旗下AI情感陪伴IP——“小鸟屁屁”与“玄猫又又”打造了“插话式”无感延迟,助力其实现从功能到灵魂的进化,为用户创造真正懂爱的“新物种”。 “AI私宠”用稳定连接,翻译你的世界 依托移远稳定、高效、高集成度的AI硬件基石,次元造物整合阿里千问AI对话模型微调能力与自研的情感模型、人格提示词及个性化记忆系统,成功将前沿的心理学模型与AI情感算法转化为可触可感的温暖陪伴。 1. 情感依恋体“小鸟屁屁” 搭载成长式记忆引擎与情感化交互机制,可通过持续对话学习,记住用户的喜好,从普适性的萌宠形象逐步进化为用户专属的“灵魂伴侣”;同时以治愈声线和软萌粘人的性格,在交互过程中“陪伴式解忧、共情式宣泄”,成为用户的私人情绪翻译官。 2. 灵性守护者“玄猫又又” 创新推出“AI+玄学”情感陪伴萌宠!集物理互动、智能语聊、运势预测与情感记忆于一体。将性格测评与星盘逻辑植入AI底层,独创“趣味抽签+实时八卦”联动机制,并可基于对话记忆生成“猫咪日记”,成为用户身边的赛博仪式执行者! 技术的温度正通过这些“新物种”真切流淌。它们不仅是硬件与算法的结合,更是移远与次元造物对“情感可工程化”这一命题的生动回应。而这一“情感可工程化”的落地能力,也让次元造物接连斩获“2025年玉猴奖年度十佳动漫文创产品”与“2025年中国礼品创意设计大赛决赛金奖”两项行业荣誉,充分印证商业潜力与创新实力。 从“连接”到“共情”,移远如何为AI注入“灵魂”? 在情感硬 件赛道上,技术不止于“实现功能”,更在于“塑造体验”。移远通信提供 的不仅是模组,更是一套完整的低延迟、高集成、稳连接的情感交互通信基座。 “小鸟屁屁”作为一款以共情能力为核心的AI伴侣,依赖多模态情感计算体系对语音、触觉等多源数据进行融合处理,并实时反馈高情商的语音与动作,其实现难点在于对低延迟与高度集成硬件架构的双重要求。移远4G AI陪伴整体解决方案针对这一核心挑战提供了关键支撑:EC800M-CN LTE Cat 1无线通信模组,通过稳定可靠的4G连接能力,保障了端云协同的快速响应,满足了AI大模型的实时推理需求,同时实现了“高情绪价值+实时互动+稳定连接”的 一体化 体验。 体验的塑造,同时也离不开方案的另一“巧思”,次元造物这两款新产品采用了移远Animator智能机芯盒一站式解决方案,该方案机芯盒小巧灵活,尺寸仅64.5mm×53mm×23.8mm,可以轻松嵌入玩具中,以高集成架构支持本地预处理与多传感器接入,使复杂AI能力得以在有限空间内高效落地;支持双目动态表情展示及触摸互动反馈,兼顾情感交互体验与产品轻量化设计。 引领硬件创新,共筑情感科技新生态 当前,AI 情感陪伴市场已驶入快车道,硬件体验是决定产品生命力与用户粘性的关键。移远通信凭借在智能模组领域完善的产品线、深厚的技术整合能力与全球 化的技术服务支持,正逐步成为行业值得信赖的硬件伙伴。 “小鸟屁屁”与“玄猫又又”多模态沉浸式交互的推出与AI算法的稳定运行,是对移远实力的再次印证。未来,移远将继续深化在AIoT领域的创新,与生态伙伴携手,赋能更多“懂爱的新物种”诞生,让有温度的AI科技深入千家万户。
移远通信
移远通信 . 2026-03-20 1512

产品 | 意法半导体推出响应快速的隔离式栅极驱动器,让汽车模块变得更小、更安全
意法半导体的STGAP2SA和STGAP2HSA车规级电隔离栅极驱动器的输出电流4A,响应时间仅60ns,两个驱动器之间高度匹配,支持高开关频率,从而提升功率密度与能效。 该系列驱动器适配直流电压轨高达1200V的IGBT和硅基MOSFET功率开关管,驱动电压最高可支持到26V,且可支持负压关断。灌/拉电流能力为4A。作为STGAP系列工业级与车规级电隔离栅极驱动器的新成员,这两款获得AEC Q100认证的产品适用于传统油车、混动汽车和纯电动汽车的DC/DC转换器、水泵、风扇、加热器、电动压缩机及车载充电机(OBC)。其他应用还涵盖壁挂式和立式直流充电系统,以及工业逆变器和电机驱动装置。 两款驱动器内部集成丰富的安全保护功能,能够简化产品设计,提升可靠性。这些安全功能包括欠压锁定关断(UVLO)、上电和下电期间的输出安全状态控制;防止误导通的米勒钳位电路;过温度保护/自动恢复功能防止器件超出安全工作温度范围。此外,当低压侧通信异常时,芯片内置自检看门狗确保输出安全;还有一个省电待机模式,将PWM输入同时拉高即可进入省电模式。 两款器件都满足UL 1577标准的隔离电压要求。STGAP2SA采用标准SO-8封装,瞬态隔离电压和浪涌隔离电压(VIOTM、VIOSM)为4800V。STGAP2HSA符合IEC 60747-17标准的基本绝缘要求,浪涌隔离电压(VIOSM)达到6000V,采用宽体SO-8W 封装,爬电距离与电气间隙均为 8mm。 两款器件均配有演示板,方便快速开发。其中EVALSTGAP2SAC搭载STGAP2SA芯片,而EVALSTGAP2HSAC搭载STGAP2HSA芯片,适合对隔离性能要求更高的设计。
ST
意法半导体工业电子 . 2026-03-20 1 1 1701

方案 | Supermicro推出基于NVIDIA Vera Rubin NVL72、HGX Rubin NVL8与Vera CPU系统的DCBBS®解决方案,助力客户加速项目部署与上线
Supermicro的NVIDIA Vera Rubin NVL72与HGX Rubin NVL8系统是基于DCBBS液冷架构所设计,与NVIDIA Blackwell解决方案相比,可实现最高10倍的每瓦吞吐量,并将Token成本降低至十分之一。 Supermicro的2U HGX Rubin NVL8系统为硬件灵活性最高的计算平台,可支持NVIDIA Vera与新一代x86 CPU,并能实现每机柜72个Rubin GPU的密度。此系统也可搭配DCBBS液对气(Liquid-to-Air,L2A)Sidecar冷却液分配单元,可部署于未导入液冷技术的数据中心。 全新Supermicro NVIDIA Vera CPU系统机型包括可容纳最高6个RTX PRO 4500 Blackwell服务器版本GPU的2U服务器,以及搭载NVIDIA BlueField-4 DPU的新型AI存储系统,可支持情境内存(Context Memory)的扩充。 【2026年3月16日,美国加州圣何塞讯】Super Micro Computer, Inc.(NASDAQ:SMCI)作为云端计算、AI/机器学习、存储和5G/边缘领域的全方位IT解决方案供应商,宣布推出基于NVIDIA Vera Rubin平台的系统产品组合。许多数据中心正转型为AI工厂,规模化智能计算、代理式推理、长上下文AI,以及混合专家模型(Mixture-of-Experts,MoE)等类型的工作负载,也使市场对新型计算与存储基础设施的需求持续提升。Supermicro的NVIDIA Vera Rubin NVL72、NVIDIA HGX Rubin NVL8与NVIDIA Vera CPU系统是基于其Data Center Building Block Solutions(DCBBS)架构,具有先进的液冷设计,可加速客户项目的部署与上线。 Supermicro总裁兼首席执行官梁见后表示:”我们正迈向全新的时代。在这个时代中,每个组织都需要AI工厂,才能在市场中脱颖而出。现今推理工作负载的计算需求,也正重新定义数据中心设施所必须提供的效能。Supermicro正对其DCBBS进行更佳的设计,以支持即将推出的NVIDIA Vera Rubin NVL72、HGX Rubin NVL8,以及Vera CPU系统,帮助客户更快速、更明确地实现新一代AI工厂的规模化部署。我们很高兴能率先推出这些解决方案,并通过先进的计算设施,推动产业迈向AI新时代。" 基于NVIDIA Vera Rubin与Rubin平台的Supermicro DCBBS解决方案 要规模化地提供AI工厂级的效能,除了计算组件外,也需要电力、散热与网络基础设施的无缝式整合与运行。Supermicro的模块化DCBBS架构,使数据中心营运商能部署经验证、预先工程化设计的机架解决方案,而无需为每个项目的基础设施进行客制化,从而加速项目启动与上线、最小化整合程序的风险,以及减少不同规模的AI工厂部署整体拥有成本(TCO)。 Supermicro DCBBS的设计可因应不断变化的散热、电力与网络需求,并能支持即将推出的NVIDIA Vera Rubin NVL72、NVIDIA HGX Rubin,以及NVIDIA Vera CPU架构,实现快速且稳固的部署。Vera Rubin平台自此代产品起,皆需通过完整的液冷配置进行散热,而DCBBS提供了全面、经验证的液冷基础设施。这些设施包括机架内(In-Rack)与机架列间式(In-Row)配置,相关核心组件包括冷却液分配单元(CDU)、歧管,以及液对气侧边式散热柜(Sidecar)。此外,冷却塔(Cooling Tower)、布线设计与部署服务等基础设施解决方案,也可与Supermicro新一代系统产品组合进行无缝式整合。 Supermicro NVIDIA Vera Rubin NVL72 SuperCluster Supermicro正将NVIDIA Vera Rubin NVL72与新型DCBBS液冷组件进行设计上的结合,以完整支持机架与集群规模的电力与散热需求。这也包括优化NVIDIA MGX机架、机架内或机架列间式CDU、背门式热交换器(RDHx),以及液对气Sidecar的制造,以优化机架式AI超级计算机的规模化生产与部署程序。Vera Rubin NVL72作为机架式加速计算单元,通过协同设计,整合了六组核心组件。这些组件为Rubin GPU、Vera CPU、NVIDIA NVLink 6、NVIDIA ConnectX-9 SuperNIC、NVIDIA BlueField-4 DPU,以及NVIDIA Spectrum-X Ethernet,可使该计算单元提供最高3.6 Exaflops的推理效能、75TB的高速内存,以及1.6 PB/s的HBM4带宽。相较于NVIDIA Blackwell,Vera Rubin NVL72可达到最高10倍的每瓦吞吐量,并使Token成本降低至约十分之一。 NVIDIA HGX Rubin NVL8系统 新型2U HGX Rubin NVL8系统是目前密度与硬件弹性最高的HGX平台,亦是首个在CPU搭配上提供更高灵活度的HGX系统。除了NVIDIA Vera CPU,该平台也可支持新一代AMD与Intel x86处理器。此HGX平台是基于NVIDIA MGX机架架构,并整合了Supermicro的盲插式总线(Blind Mate Busbar)与歧管,能实现免工具(Tool-Free)式的机架整合。这使客户可将八个Rubin GPU与最适合其工作负载及软件架构的CPU平台进行自由搭配。 这项设计使每组机架可支持9个HGX Rubin NVL8系统,并配备最高72个Rubin GPU,适用于大规模AI训练、推理,以及加速型HPC应用。DCBBS技术则提供机架内CDU、机架列间式CDU、背门式热交换器,并可选择性搭配液对气Sidecar,以因应客户在液冷或气冷数据中心内的部署需求。 搭载RTX PRO的NVIDIA Vera CPU系统 Supermicro的Vera CPU新一代代理式AI(Agentic AI)系统,具有多功能AI计算节点的设计,可用于企业的新型代理式AI应用部署。该系统搭载双NVIDIA Vera CPU,并可于紧凑型2U机箱内可支持最高6个RTX PRO 4500 Blackwell服务器版本GPU,为企业AI推理、代理工作负载与可视化应用提供极佳的计算密度与能效,也能加速各类企业工作负载的计算。此外,这款系统可在空间有限的环境内,发挥其高带宽LPDDR5X内存子系统与PCIe GPU加速性能的优势。 NVIDIA BlueField-4 STX情境记忆存储平台 Supermicro即将推出的情境记忆存储(Context Memory Storage,CMX)平台,是专为情境记忆打造的全新AI原生存储系统。CMX平台具有智能化Pod级情境记忆存储技术,可扩充GPU的KV Cache容量,并提供了Vera Rubin NVL72超级集群所需的数据吞吐量,能支持长上下文推理的运行。该平台搭载了NVIDIA BlueField-4处理器、NVIDIA Vera CPU、NVIDIA ConnectX-9 SuperNIC、NVIDIA Spectrum-X Ethernet、NVIDIA DOCA,以及NVIDIA Dynamo,提供高带宽、低延迟的网络架构,以及智能化数据路径卸除(Data Path Offload)技术,可因应大规模AI推理与检索增强生成(RAG)工作负载的需求。 Supermicro NVIDIA Blackwell解决方案(已上市) Supermicro在快速开发新一代系统的同时,也通过在美国与全球的制造基地产能,将NVIDIA Blackwell系统产品进行全面量产,助力客户快速打造与扩充AI基础设施。Supermicro将持续致力于Blackwell产品线的完善与新型系统的开发,进而为客户转型的各阶段,提供最合适的计算平台。 欢迎于GTC San Jose 2026大会期间莅临Supermicro展位 Supermicro正于GTC大会内率先展示其Vera Rubin平台系统,以及已上市的Blackwell产品组合。欢迎莅临1113展位,通过Supermicro专家团队深入了解目前的采购选项、产品蓝图计划,以及近期与新一代AI基础设施的部署时程。
SMCI
SMCI . 2026-03-20 1589

企业 | 顺络电子诚邀新老客户参加美国2026 APEC(应用能源电子)展会
APEC2026展会 图片来自顺络 我们的展位 顺络展位号码:335 日期:当地时间2026年3月22日(星期日)-26日(星期四) 会场地址:亨利·B·冈萨雷斯会议中心 圣安东尼奥,得克萨斯州 (Henry B. González Convention Center San Antonio, TX) URL: https://apec-conf.org/ 展会简介 由IEEE-产业应用学会(IAS)、电力电子学会(PELS),美国电源制造商协会(PSMA)联合主办的国际电力电子应用展览会。该展会是目前全球电力电子、电源领域规模最大、水平最高的展览会议。自开办以来,该展会就为来自电力电子产品及其驱动技术和变电质量应用界的广大专业人士提供了一个专业的交流平台,使他们有机会领略电力电子产品和系统领域的最新研发成果。该展以其高质量的专业观众,成为享誉电力电子行业的专业国际性展会。 随着AI技术、汽车电子、光伏储能等新领域的蓬勃发展,在关键的电压转换、逆变器、电池管理等电源部位对磁性器件提出了更高的要求。顺络电子在这些新领域提前布局,精心耕耘,研发出了设计新颖、性能优良的磁性产品,并提供在各类电源应用的整体被动器件解决方案。本次展会将展示顺络电子应用于AI 数据中心、汽车电子、储能系统的大电流功率电感、Zero-Bias TLVR电感、聚合物钽电容 、PCBA集成式大功率平面变压器、一体冲压注塑变压器、大功率线圈等多种产品和应用解决方案,我们热烈邀请新老客户前往展台参观交流。 展览预览 AI服务器中心展区 随着全球AI服务器市场持续增长,顺络电子在800V HVDC、54V IBC 、12V/6V to core供电等领域,开发了多个新产品系列,适用于800V直流数据中心供电的高频锰锌铁氧体磁心,适用于xPU供电的低损耗合金材料,低损耗耦合电感/多相电感、高耐压的2-PH TLVR电感、基于超低压成型的4-PH TLVR电感、适用于超高频使用的IVR电感、新型电极结构钽电容、适用于Retimer芯片滤波的大电流磁珠等,为AI服务器垂直供电、电源模块助力。 AI服务器应用 图片来自Sunlord内部 汽车电子展区 顺络汽车电子产品应用广泛,涵盖电池管理系统、车载照明、智能座舱系统、智能驾驶、T-BOX & V2X、车载充电机、DC-DC转换器、48V混动系统、电机驱动、热管理系统等10大领域,主要产品包括变压器、功率电感、共模电感、射频电感等。可根据客户需求进行定制,多方面助力新能源汽车发展!顺络汽车产品在技术性能及质量管理上已得到了客户的高度认可,已经被国内外众多汽车电子企业及tier1零部件供应商批量采购。 汽车整体应用 图片来自Sunlord内部 储能系统及大功率器件展区 随着AI服务器、光伏储能、智能储能和电动汽车等行业的发展,电源和磁性器件领域迎来变革。AI服务器的高算力需求使其电源功率大幅提升,单台功率可达数千瓦,甚至更高。这推动电源向高频化、智能化、高效化方向发展,同时对散热和稳定性提出更高要求。磁性器件作为电源核心组件,需求也显著增加,如高端AI服务器主板上的一体成型电感数量大幅上升,其性能和集成度成为关键。而电动汽车和光伏储能行业的发展则对电源的稳定性和可靠性提出更高要求,系统电压提升和功率密度增加,促使磁性器件向更高效率、更低损耗方向发展。顺络电子通过材料改进、工艺创新、模拟仿真等方式,推出了各类新型的大功率器件,包括PCBA集成式大功率平面变压器、一体冲压注塑变压器、低损耗PFC线圈、电磁阀线圈等多种产品和应用解决方案。 图片来自Sunlord内部 除此之外,还会有更多的产品在展会上展示,欢迎新老客户前往顺络展台参观交流。
顺络电子
顺络Sunlord . 2026-03-20 4438

企业 | 唯捷创芯战略投资优智联 布局UWB通感一体新未来
近日,我司完成对优智联的战略投资,双方将开展深度战略合作,联合打造创新产品,共同推动UWB技术与通感一体方案在多领域的规模化落地。 通感一体,是未来无线通信的核心方向,也是科技走向生活、服务产业的必然需要。它让无线设备在实现高效通信的同时,具备精准环境感知、位置识别、状态监测等能力,将“连接”与“感知”深度融合,为智能生活与高端工业场景提供更安全、更精准、更智能的底层支撑。 优智联是国内领先的UWB芯片与方案提供商,在UWB SoC芯片设计、高精度定位算法、低功耗与高可靠性等方面拥有核心优势,是行业内公认的技术标杆企业。 UWB超宽带技术凭借厘米级定位精度、强抗干扰、高安全性等特点,正成为通感一体的关键载体,应用场景持续拓展: - 智能汽车:实现数字钥匙、车内生命监测、无感交互等核心功能; - 智能家居与消费电子:支持精准寻物、空间感知、设备智能协同; - 服务机器人与工业机器人:提供高精度定位、自主导航、动态跟随与安全避障; - 大型电力设施与工业物联网:用于关键设备状态监测、人员安全定位、资产追踪与故障预警,保障基础设施稳定运行。 我司在射频前端、无线通信系统领域拥有深厚技术积累与成熟产业经验,优智联则在SoC芯片设计,尤其是在模拟IP、基带算法与量产落地上具备核心竞争力。双方强强联合、优势互补,将以射频硬件能力与算法芯片技术深度协同,围绕通感一体方向联合研发、共同定义新一代产品方案。 本次战略合作,将进一步强化公司在无线连接与智能感知领域的布局,助力UWB技术在智能汽车、机器人、智能家居、大型电力及工业设施等场景快速普及。未来,我司将持续聚焦射频与物联网前沿赛道,以技术创新与生态协同为驱动,携手优智联共拓通感一体新蓝海,为行业数字化升级注入更强动力。
唯捷创芯
唯捷创芯Vanchip . 2026-03-20 1897

产品 | AMD准备推出锐龙7 9750X和锐龙5 9650X桌面处理器,配备120W TDP
AMD正准备更新其锐龙9000系列桌面处理器产品线,推出两款新型号:锐龙7 9750X和锐龙5 9650X,以应对英特尔最新的酷睿Ultra 200S Plus(代号Arrow Lake Refresh)系列竞争。 这两款芯片均为非X3D版本(不带3D V-Cache),采用标准的"Zen 5" CCD设计,配备32MB片上L3缓存,120W TDP。 锐龙7 9750X是一款8核16线程芯片,基础频率4.20 GHz,最高睿频5.60 GHz,相比锐龙7 9700X的3.80 GHz基础和5.50 GHz最高睿频有显著提升。9750X出厂即配备120W TDP。相比之下,9700X出厂TDP为65W,AMD允许主板厂商提供基于BIOS的105W TDP模式且不影响保修,旨在提升睿频持续时间。9750X不仅提高了频率,还将TDP进一步提升至120W,超过了BIOS模式的105W。 锐龙5 9650X是一款6核12线程芯片,基础频率4.30 GHz,最高睿频5.50 GHz,相比当前锐龙5 9600X的3.90 GHz基础和5.40 GHz最高睿频有所提升。该芯片为6个核心配备了完整的32MB片上L3缓存,与9600X相同。 目前尚无定价信息,但这两款新处理器很可能会分别取代9700X和9600X的现有价格定位。
AMD
奇谱智慧科技 . 2026-03-20 1 1764

产品 | 欧姆龙G9KJ:不止于小,更为高电压设备而生
在EV充电、蓄电系统等领域中,高电压化设计需求强劲: DC1000V 整合光伏发电的蓄电系统直流电路常见设计要求。 DC1500V 当前EV充电桩的较大电压设计标准。 然而传统的高电压继电器,虽性能强劲,却“身宽体胖”,挤占基板空间,与设备小型化、集成化的设计趋势相左。 本期,欧姆龙器件与模块解决方案给出解决方案——兼顾高电压适配与小型化的预充电专用功率继电器G9KJ(新品) 预充电专用功率继电器G9KJ G9KJ型是一款印刷基板用继电器,可适配高电压,实现小型轻量化,并兼顾低功耗与高安全性能。 空间做减法 相较传统的螺丝固定式继电器,实现了尺寸大幅缩小和轻量化。 体积小巧 尺寸仅为37.2×17.0×25.5mm,重量约16g。线圈与触点间空间距离 ≥14mm、沿面距离 ≥25mm。 设计精巧 采用PCB端子设计,省去了继电器螺丝固定,大幅减少了布线工时和布线空间。 普通螺丝固定式继电器与G9KJ型的性能比较 螺丝固定式继电器 (DC1500V性能的普通螺丝固定式继电器) G9KJ 安装 面积 3100mm² 600mm² 体积 143520mm³ 16126mm³ 重量 约160g 约16g *截止2025年7月本公司调查结果 应用做加法 针对DC1000V~1500V高电压的蓄电系统、EV快速充电桩、光伏逆变器以及V2H预充电电路等高电压预充场景优化。 应用场景 随着电压标准向DC800V乃至DC1500V范围过渡,G9KJ可帮助实现较安全的充电环境。 G9KJ可帮助在高电压的环境中,实现较高的能源转换效率。 不止于小,更为高电压设备而生 选择G9KJ 助您在高压化的发展浪潮中抢占先机 共同推进绿色、智能、可持续的能源未来!
欧姆龙
欧姆龙器件与模块解决方案 . 2026-03-20 1 1400
方案 | 一颗芯片搞定BLDC驱动:NSUC1610高度集成电机控制方案解析
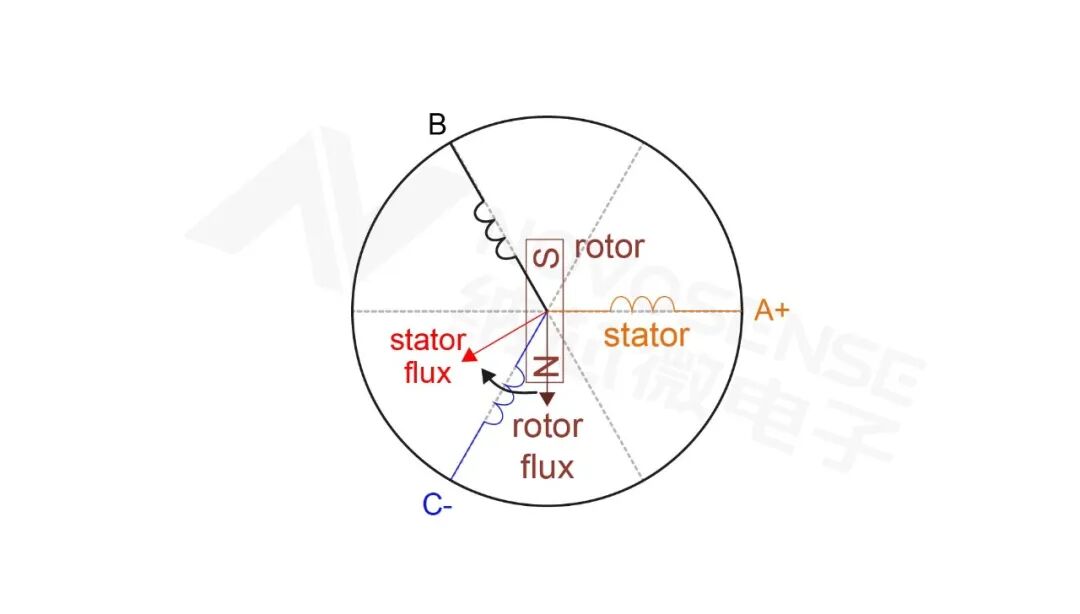
三相BLDC电机在汽车电子中应用十分广泛,例如座椅风扇、充电小门执行机构、主动进气格栅以及空调出风口等场景。对于这类车载小型执行机构,工程师通常希望在满足可靠性的同时,实现系统的低成本、小型化和轻量化设计。 针对这一需求,纳芯微推出了专用小型电机驱动芯片 NSUC1610。该芯片在单器件中集成了车载高压LDO、LIN PHY、Gate Driver、MOSFET以及基于ARM内核的MCU,可为三相BLDC电机提供高度集成的控制方案,从而简化系统设计并提升车载电机控制的可靠性。 本文将从BLDC电机的工作原理出发,介绍无感控制的基本方法,并结合NSUC1610的硬件架构解析其三相BLDC驱动方案的实现方式。 BLDC工作原理 无刷直流电机(BLDC)通过电子换向取代传统有刷直流电机的机械换向,因此具有寿命长、效率高以及功率密度高等优势。BLDC电机通常由三相定子绕组和永磁体转子构成。当定子绕组通电后,根据电磁感应原理会产生定子磁链;转子永磁体则形成固定的转子磁链。当两者之间存在一定角度差时,磁场会趋向于对齐,从而产生电磁转矩驱动转子旋转。 电机产生的电磁转矩可表示为: 是产生的转矩 为线圈内的电流 为电机转矩常数 为定子磁链和转子磁链的角度 图1.1 三相无刷电机磁链简图 如图1.1所示,当定子 A 相与 C 相绕组导通时,两相电流根据右手螺旋定则产生磁场,其磁链矢量叠加后形成定子磁链(红色)。转子永磁体则产生固定方向的转子磁链(深红色)。当定子磁链与转子磁链之间存在一定角度差时,磁场会趋向于对齐,从而产生电磁转矩,使转子产生顺时针旋转趋势(黑色)。 无感控制的基本原理是通过检测六步换相过程中悬空相的反电动势变化来判断转子位置,从而确定合适的换相时刻。在电机旋转过程中,转子永磁体产生的磁场会切割定子绕组,根据电磁感应原理,绕组中会产生感应电动势,即反电动势。 如图1.2所示,以 A、C 两相施加 12V 电压为例,此时 B 相处于悬空状态,其反电动势 会经历由负到正的变化过程。由于三相电机的虚拟中性点电压约为母线电压的一半(约6V),因此 B 相的相电压可表示为 。 当检测到 B 相电压等于 6V 时,说明反电动势发生过零,此时转子位于两个换相点之间。通过延迟约 30° 电角度进行换相,即可实现正确的六步换相控制,其余扇区的换相过程同理。 图1.2 BLDC感应电动势 三相BLDC需要三个半桥驱动,其拓扑图1.3所示。 图1.3 三相半桥逆变驱动结构 NSUC1610 介绍 NSUC1610内部集成了丰富的电机控制外设,包括 3路捕获比较模块(CAPCOM)、3路反电动势比较器(BEMFC)、模数转换器(ADC)、PWM控制模块、温度传感器、4路MOSFET半桥输出(MOUT)以及LIN通信接口(LIN PHY) 等。 其中,片上的 4路MOUT半桥驱动可直接驱动小功率直流有刷电机、三相无刷直流电机以及两相四线步进电机,并可通过不同控制算法实现多种电机控制应用。 此外,芯片内置的 BEMFC反电动势比较器支持BLDC电机反电动势过零检测,可用于实现BLDC电机的无感六步方波控制。 图2.1展示了NSUC1610的内部资源框图。 图2.1 NSUC1610内部资源框图 基于NSUC1610的BLDC方波控制 BLDC常见的控制方式为六步方波控制。在每个换相周期中,三相绕组中两相导通,一相悬空,通过按照特定的导通顺序切换各相绕组的通断状态,即可驱动电机实现顺时针旋转(CW)或逆时针旋转(CCW)。 在 CW(顺时针)模式下,扇区切换顺序为: SECTOR0➝1➝2➝3➝4➝5➝0 图3.1展示了扇区0~5对应的三相电流与反电动势波形,其中绿色曲线表示相电流,蓝色虚线表示相电压(反电动势)。 图3.1 CW 模式下不同扇区对应的反电动势波形 在 CCW(逆时针)模式下,扇区切换顺序为: SECTOR0➝5➝4➝3➝2➝1➝0 扇区0~扇区5的三相电流和反电动势波形如图3.2所示。 图3.2 CCW 模式下不同扇区对应的反电动势波形 在一个电角度旋转周期内,BLDC三相绕组的相电压变化如图3.3所示。当发生换相时,原本导通的绕组会进入浮空状态,但由于线圈中仍然存在电流,电感电流无法瞬间降为零,因此会产生一段退磁时间(Demagnetization Time)。 在这一阶段,绕组中的续流电流仍然存在,使得相电压主要由续流电流产生的电压分量决定,此时测得的反电动势信号尚不能准确反映转子位置。待绕组中的能量逐渐释放完毕后,绕组电压重新由切割磁力线产生的反电动势主导,此时的反电动势信号才可作为转子位置检测和换相控制的依据。 图3.3 电机绕组三相电压波形 在续流结束后,使能反电动势过零检测。当检测到反电动势过零点时,通过CAPCOM模块捕获该时刻,并设置比较值用于实现 30°电角度延时换相。 下一次换相比较值计算如下: 图3.4展示了各变量对应的时间关系。 为了避免在某些扇区未检测到反电动势过零点的情况,在每次换相后还会设置 强制换相点(Forced Commutation)。当系统未检测到过零信号时,电机会在该强制换相点执行换相,从而避免因过零检测失败导致电机运行异常。 其中 LastStepAvrg 表示最近六个扇区时间的平均值。 图3.4 电机换相逻辑图 BLDC无感六步方波控制的核心在于反电动势(BEMF)的过零检测。通过检测反电动势信号的上升沿或下降沿,可以确定转子的电角度位置,并进一步实现换相控制。 下面介绍 NSUC1610 中反电动势过零检测的硬件实现方式。 NSUC1610内部集成了 三个反电动势比较器(BEMFC0、BEMFC1、BEMFC2),用于实现三相反电动势的过零检测。比较器的输出结果可作为 虚拟三相 Hall 信号,用于驱动三相BLDC无感六步方波控制算法。 具体实现方式如下:三相电压的虚拟中性点(Virtual Star Point)连接至BEMFC0、BEMFC1、BEMFC2 的正向输入端;各相桥臂电压分别连接至比较器的反向输入端,其中: mout0 连接至 BEMFC0 的反向输入端 mout2 连接至 BEMFC1 的反向输入端 mout1 连接至 BEMFC2 的反向输入端 其硬件连接关系如 图3.5 所示。 图3.5 反电动势比较器的输入通道连接方式 反电动势比较BEMFC模块的配置代码如下: BEMFC->CR2_b.BRM = 0; // 0:虚拟星点参考 1:相位电压参考 BEMFC->CR2_b.BIS0 = 0; // 0:电压传感输入 1:电流传感输入 BEMFC->CR2_b.BIS1 = 0; // 0:电压传感输入 1:电流传感输入 BEMFC->CR2_b.BIS2 = 0; // 0:电压传感输入 1:电流传感输入 BEMFC0、BEMFC1 和 BEMFC2 的比较输出分别连接至 CAPCOM0、CAPCOM1 和 CAPCOM2,用于实现反电动势过零点的捕获。其中: CAPCOM0 用于捕获 mout0 的过零点 CAPCOM1 用于捕获 mout2 的过零点 CAPCOM2 用于捕获 mout1 的过零点 通过将 CAPCOM 的输入源配置为 BEMFC 比较器输出,即可在反电动势过零时触发捕获事件。配置代码如下: CAPCOM->CCR_b.CIS0 = 1; // CAPCOM source:0:GPIO 1:BEMFC CAPCOM->CCR_b.CIS1 = 1; // CAPCOM source:0:GPIO 1:BEMFC CAPCOM->CCR_b.CIS2 = 1; // CAPCOM source:0:GPIO 1:BEMFC 当电机以 CW 或 CCW 方向旋转时,在同一扇区内浮空相的反电动势变化趋势保持一致,即呈现 递增或递减的特性。 以 扇区0 为例,无论电机以 CW 还是 CCW 方向旋转,浮空相 MOUT2 的反电动势均呈 递增趋势(↗),因此需要检测其上升过零点。 六个扇区中需要检测的通道及对应的反电动势变化趋势总结如 表3.6 所示。 表3.6不同扇区对应的检测通道 CAPCOM在不同扇区的配置如表3.7所示。 表3.7不同扇区CAPCOM配置 通过上述配置,利用 NSUC1610 的片上资源即可实现对 BLDC 浮空相反电动势的检测与捕获。 在 NSUC1610 的硬件模块与控制算法协同作用下,可实现 BLDC 从 电机启动到速度闭环运行的完整控制流程。图3.8展示了 NSUC1610 驱动下的 BLDC 三相电压与电流波形。 从测试结果可以看出,电机启动及运行过程中三相电流过渡平滑,未出现明显电流尖峰,验证了该方案能够实现 稳定可靠的 BLDC 启动及闭环控制。 图3.8 NSUC1610 驱动下的 BLDC 三相电压与电流波形 联系我们 通过将MCU、LIN通信、电机驱动以及功率MOSFET等功能高度集成在单芯片中,NSUC1610能够显著简化BLDC电机控制系统的硬件设计。结合内置反电动势比较器和CAPCOM模块,可实现稳定可靠的无感六步控制方案。 该方案非常适用于汽车小型执行机构应用,例如主动进气格栅、充电小门以及座椅风扇等场景,为汽车电子系统提供了一种高集成度、低成本且易于开发的电机控制解决方案。
纳芯微电子
纳芯微电子 . 2026-03-20 1 1 1820

企业 | TI 携手 NVIDIA 推出面向下一代 AI 数据中心的完整 800 VDC 电源架构
TI 与 NVIDIA 合作,为下一代 AI 数据中心开发了完整的 800 VDC 电源解决方案。 作为此次合作的一部分,TI 展示了一种从 800V 到处理器供电仅需两级转换的电源架构。 TI在 NVIDIA GTC 2026 上展示了该 800 VDC 电源解决方案。 德州仪器 (TI)近期推出完整的 800V 直流 (DC) 电源架构,该架构基于 NVIDIA 800 VDC 参考设计,用于了下一代 AI数据中心。该解决方案于 2026 年 3 月 16 日至 19 日在NVIDIA GTC的功率架构大会和 TI 的 169 号展位上亮相,展示 TI 的模拟和嵌入式处理技术如何助力 NVIDIA 推动 AI 数据中心高压系统革新的愿景。 “AI 算力的指数级增长,正推动数据中心供电方式发生根本性变革。我们推出的这款先进的 800 VDC 架构是一项具有重要意义的突破,它不仅能帮助数据中心运营商应对当前的电力挑战,更能为未来的 AI 工作负载需求做好准备。通过与 NVIDIA 的合作,我们正加速推动高效、可靠的 AI 基础设施部署。” ——TI 高压电源副总裁兼总经理 Kannan Soundarapandian 解决 AI 基础设施中的关键电力问题 随着 AI 工作负载的激增,数据中心的电力需求达到了前所未有的水平,传统的配电架构正接近其极限。TI 的 800VDC 架构通过在整个电力路径上最大限度地提高转换效率和功率密度来应对这些挑战,简化了配电架构,并使 AI 数据中心能够实现更高可扩展性和可靠性。 TI 这一突破性方案仅需要两个功率转换级,即可将 800V 转换为 GPU 核心电源:首先通过高峰值效率的紧凑型800V 至 6V 隔离式母线转换器,其后再通过高电流密度的 6V 至 1V 以下多相降压解决方案。这种简化架构符合 NVIDIA 的参考设计要求。 完整的电源解决方案 TI 在 NVIDIA GTC 上展示全面的 800 VDC 电源架构解决方案,其中包含了多个具有行业领先规格的突破性参考设计: 800V 热插拔控制器:可扩展的热插拔解决方案,用于 800V 电源轨的输入电源保护。 800V 至 6V 直流/直流转换器:高密度解决方案,集成了 GaN 功率级,峰值效率可达 97.6%,功率密度超过 2000W/in3,适用于计算托盘应用。 6V 至 1V 以下多相降压转换器:先进 GPU 内核的高电流解决方案,功率密度远超 12V 设计,并具有双相功率级设计。 除此之外,TI 展示了一款适用于 AI 服务器的 30kW、800V 高功率密度的交流/直流电源,以及采用 EDLC 超级电容器单元 (CBU) 的 800V 电容器组,其功率密度为 40W/in3。同时,TI 还展示了一款 800V 至 12V 的直流/直流母线转换器,用于计算托盘的功率转换。 加快未来一代 AI 数据中心的发展 随着 AI 与边缘计算驱动数据中心持续增长,TI 的模拟与嵌入式处理技术为高效供电与系统管理提供关键支持。从固态变压器到服务器机架与配电单元,再到冷却分配系统,TI 可扩展的半导体解决方案正助力构建面向未来的 AI 基础设施。
TI
德州仪器 . 2026-03-20 1 2198

企业 | 铠侠电子停产用于MLC NAND “薄型小尺寸封装”产品
3月19日消息,NAND Flash大厂铠侠电子(中国)有限公司近日向客户发布停产通知,宣布“薄型小尺寸封装”(Thin Small Outline Package,简称TSOP)相关产品停产。而该TSOP封装主要用于低容量MLC NAND(每个存储单元中存储 2bit 数据的NAND闪存类型),这也意味着铠侠的低容量MLC NAND可能将停产。 铠侠表示,由于生产能力和基材限制,公司无法生产8Gb-64Gb的TSOP封装产品。希望收到最后采购预测(即客户最后一次下单数量)期限为2026年5月30日,以确定铠侠的支持计划。最后采购订单截止日为2026年9月15日,最后出货时间为2027年3月15日。 近年NAND Flash技术快速演进,由于无尘室空间有限,相较主流TLC与QLC构架,MLC的单位产值最低,不符合NAND原厂追求规模经济与资本效率的策略,因此原厂正积极集中资源于TLC、QLC与DRAM,并逐步将MLC产品停产(EOL)。 目前不确定铠侠中国TSOP停产相关产品,是否和该公司逐步减少MLC供应量有关,但预期铠侠在MLC的供应量,很可能在2027年后至2028年归零。 由于国际大厂逐步退出MLC市场,促使低容量eMMC价格不断飙涨。研调机构TrendForce指出,2026年全球MLC NAND Flash产能将年减41.7%,供需失衡加剧。由于供给急缩且短期未有具规模、可快速承接的产能,从2025年第一季底开始,MLC NAND Flash市场出现明显追货、提前锁量现象,价格上涨至今。 TrendForce指出,MLC NAND Flash终端需求持稳,主要来自工控、车用电子、医疗设备和网通等,皆对产品可靠度、写入寿命、长期供货承诺要求较严格,但以上需求的长期成长幅度有限,且若部分应用加速导入强化版TLC解决方案,或整体NAND Flash市场景气明显反转,MLC产品价格仍可能间接承压。 若铠侠停产低容量MLC,那么旺宏或将将成为2028年后唯一低容量eMMC供应商,预期其2025-2027年MLC/TLC位出货将增长36倍,ASP/Gb增长7.5倍。
铠侠电子
芯查查资讯 . 2026-03-20 1400

涨价 | MPS宣布涨价
知名模拟芯片厂商MPS(芯源系统)疑似发布涨价函。函中表示,由于从原材料到制造工序的各个环节成本上升,MPS将对部分产品进行价格调整。更新后的价格将自 2026 年 5 月 1 日起生效。 网传涨价函如下: 原文翻译如下 : 日期:2026 年 3 月 17 日 客户信息 尊敬的分销合作伙伴: 目前整个行业对各类半导体产品的需求正在增加,这导致我们的供应商在半导体生产过程中从原材料到制造工序的各个环节成本上升。 我们在此通知您,Monolithic Power Systems(MPS)将对部分产品进行价格调整。这些调整是为了确保我们在生产能力、供应可靠性以及合作伙伴期望的高质量和服务水平上继续保持投资。 更新后的价格将自 2026 年 5 月 1 日起生效。所有在此日期或之后发货的订单,将按调整后的价格执行。 我们非常重视与分销网络的紧密合作,并感谢您在此次过渡期间给予的支持。MPS 销售团队及客户服务代表(CSR)将与您紧密沟通,解释价格调整,并协助解答您关于新价格的任何疑问。 关于受影响产品的具体信息及更新后的价格细节,将通过适当的销售渠道另行提供。 感谢您一如既往的合作与支持。 此致 Monolithic Power Systems
MPS
芯查查资讯 . 2026-03-19 3633
企业 | 万物互联的“隐形翅膀”:一文读懂Molex全场景天线产品布局
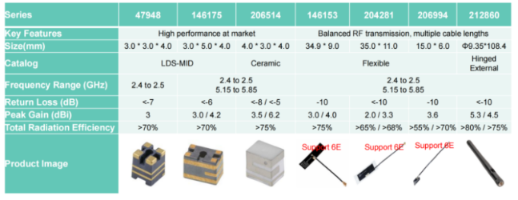
在当今高度数字化的世界里,无线通信技术已经从单纯的人际沟通工具,演变为支撑全球基础设施、工业自动化、智能出行和数字医疗等应用的“中枢神经”。随着5G网络的深度普及,Wi-Fi 6E,Wi-Fi7的商用落地,以及卫星通信技术的异军突起,万物互联(IoT)正以前所未有的速度在发展。 从路上行驶的汽车,到人手一部的手机,再到工厂高速运转的自动化设备,以及智能电网传感器和智慧农业用的传感器等等,无处不在的无线信号正在重构我们的生活。然而,这一切的背后,有一个经常被忽视,但却至关重要的硬件产品——天线。天线的性能直接决定了信号的覆盖范围、连接到稳定性和整机的功耗表现等。 无线通信的多元化挑战 在我们的生活中,无线通信可以说无处不在,应用场景非常多元。而不同的应用场景对天线提出了非常多的要求,有的要求极为苛刻,有的甚至相互矛盾。例如,物联网与智能家居产品要求天线在极小的体积内实现全向覆盖,同时必须具备极高的性价比和易于集成的特性;汽车电子应用中,要求天线能够经受极端温度和振动的考验,且在复杂的金属车身环境中依然保持高增益和极低的信号衰减;医疗健康与便携设备中的天线则要求具备优秀的抗失谐能力,以保证患者数据的实时无误传输。 面对这些挑战,以及设备日益小型化,应用环境越来越复杂的挑战,Molex针对不同的应用场景痛点,打造了高度定制化和系列化的产品矩阵。其全场景天线产品矩阵包括Wi-Fi、蓝牙、蜂窝网络、GNSS、ISM及NFC等天线产品。接下来,随芯查查一起,看看Molex全场景天线产品的布局。 2.4/5 GHz蓝牙与Wi-Fi 天线:突破速率瓶颈 随着高清视频流媒体、AR/VR,以及海量IoT设备的接入,传统的2.5GHz和5GHz频段已经拥挤不堪。因此,高性能的天线在这里显得尤为重要。Molex在2.5/5GHz蓝牙与Wi-Fi天线系列的7款产品(47948、146175、206514、146153、204281、206994、212860)堪称“高性能标杆”。 图注:图片来源来源molex,下同 在小型化方面,其47948系列尺寸仅为3.0×3.0×4.0mm,LDS-MID工艺,完美嵌入穿戴设备。 另一款206514,不仅支持Wi-Fi、蓝牙、ZigBee等多种射频协议,还具有高稳定性与良好的信号增益表现,适用于对空间和性能要求较高的无线设备中。配合平衡传输设计,有效降低PCB接地层对天线性能的干扰,无需额外调试即可实现良好射频匹配,加快产品开发周期。 随着Wi-Fi 6E的引入,带来了全新的6GHz频段,也带来了更宽的通道和更低的延迟。Molex的2.4/5GHz蓝牙WiFi天线中的146153、204281及206994系列天线就是为此而生的。该柔性天线覆盖2.4-2.5GHz与5.15-5.85GHz,回波损耗低至-10dB,峰值增益最高6.2dBi,总辐射效率>75%。 蜂窝天线:5G IoT与车联网的可靠保障 5G时代,蜂窝连接是远程监控、资产追踪、自动驾驶等应用的核心。Molex的蜂窝天线产品阵列,105263、207235、212570、204774、206760、146200等6大系列覆盖了824-960MHz、790-960MHz、698-960MHz、1.71-2.7GHz主流LTE/5G频段。 Molex的蜂窝天线具有超宽频覆盖、高性能、小尺寸、MIMO技术支持等特性。例如,146200系列天线提供MIMO配对设计,而在现代高速数据传输中,MIMO技术是成倍提升吞吐量和抗干扰能力的关键。 此外,尽管体积小巧,例如207235系列的尺寸仅为40.40x15.40mm,这些柔性和陶瓷蜂窝天线依然能够保持小于-4dB至-6dB的优异回波损耗(Return Loss),以及超过60%乃至70%的辐射效率,确保了设备即便在偏远地区或信号死角也能保持稳定的在线状态。 GNSS全球导航卫星系统天线 在资产追踪、无人机作业,以及自动驾驶等应用场景中,离不开多星座高精度GNSS。Molex的5款天线产品中,204286、206640、213499、206560、213353涵盖了从单馈针陶瓷贴片,到带有双级低噪声放大器(LNA)的有源贴片天线。 陶瓷贴片:204286 系列,尺寸仅为25×25×4mm,椭圆极化,效率>70%。 有源LNA版:206640/213499系列,带双级LNA+长电缆,磁吸外置,抗干扰强。 宽频柔性:213353系列同时支持698-8500MHz与GNSS,双端口设计,一天线多用。 在V2X和精准农业场景中,这些天线保障了厘米级定位。比如206640和213499系列采用了自带双级LNA的有源设计,能够在其极佳的右旋圆极化(RHCP)特性下,对微弱的1561/1575/1602 MHz卫星信号进行低噪声的高效放大。其出色的轴比(Axial Ratio)表现,有效过滤了城市高楼间复杂的反射多径信号,使得定位精度实现了质的飞跃。 而对于需要更广阔频段覆盖的客户,其213353等柔性GNSS天线支持698至8500 MHz的超宽频范围,并提供双端口配置,为集成多种通信协议的复合型设备提供了“一站式”解决方案。 ISM与NFC近场天线 无线通信应用,除了大众熟悉的Wi-Fi和蜂窝网络,还包含了许多在工业和特定领域起着关键作用的频段。例如工业科学医疗(Industrial Scientific Medical,ISM)和NFC近场通信应用等。 工业物联网与医疗设备对863-928MHz ISM频段需求巨大。Molex 105262/211140两款柔性天线:尺寸小至38×10mm,效率>55-66%,多长度可选,完美用于智能传感器、病人监护仪等设备中。 在移动支付、医疗设备身份验证和门禁系统中,13.56MHz的NFC技术至关重要 。Molex提供了极其丰富的尺寸选择(从15x15mm到45x55mm)和电感值匹配(1.4 µH至4.2 µH)。特别是“带铁氧体”及“带双绞线缆”的版本,完美解决了金属背板环境下的磁场涡流效应,使得NFC天线即使紧贴金属外壳或电池也能顺畅读取,极大简化了终端产品的结构设计难度。 结语 我们处于无线通信技术大爆发的黄金年代,设备形态在变、应用场景在变,但人们对更稳定、更快速、更无缝连接的追求没有变。Molex全场景天线产品具有小型化、高性能、安装灵活、易集成,而且大部分的产品都已经过了市场的验证,在物联网、智能家居、汽车、医疗、零售、农业,以及智能电网等领域均有成功案例,可为万物互联提供强有力的硬件支撑。
molex
芯查查资讯 . 2026-03-19 1 2233

市场 | TI第二次全面涨价,中微爱芯近千款信号链芯片提供稳定国产解决方案
近日,全球模拟芯片巨头德州仪器(TI)将于2026年4月1日启动第二次全面涨价,涨幅预计在15%至85%之间,涉及数字隔离器、隔离驱动、电源管理IC等多款核心产品。这是继2025年8月TI针对工业、汽车等领域调价10%-30%后的又一次大规模价格调整。 多家半导体巨头涨价,集中于4月1日起生效 根据渠道商透露的安森美最新涨价函可知,为应对原材料、制造、能源及基础设施成本的持续上涨,安森美将于2026年4月1日起,对部分产品实施价格调整。值得注意的是,安森美并非近期唯一宣布涨价的半导体厂商。进入2026年以来,全球半导体行业已迎来新一轮涨价潮:恩智浦(NXP)传出涨价消息,涉及汽车电子及工业控制等核心产品线。此外,意法半导体(ST)、英飞凌(Infineon)等厂商也在近期陆续释放涨价信号。——文章来源:国际电子商情 在此背景下,寻求成熟、可靠且供应与价格长期稳定的国产解决方案,已成为工业控制、汽车电子、消费电子等领域客户保障供应链安全、控制成本的关键策略。 中微爱芯作为国内领先的平台型芯片设计企业,深耕信号链芯片领域多年,已建立起多元、成熟的产品矩阵,覆盖11大类、近千款料号,为多领域提供国产信号链芯片解决方案。
涨价
中微爱芯官网 . 2026-03-19 2051
产品 | 500MHz高速引擎!AiP806X系列轨到轨输出运放解锁信号处理新速度—AiP8061/2/3/4/9
01 简介 随着对信号处理速度的要求不断提升,高速运算放大器已成为信号处理、数据采集等众多领域不可或缺的关键组件。近期,中微爱芯推出AiP806X系列电路采用2.5~5.5V电源供电,单个通道静态电流7.5mA,单位增益带宽高达500MHz,以卓越高频响应与优异信号保真能力,为高速信号链路提供强劲支撑,轻松应对ADC驱动、DVD、基带处理、精密滤波等关键场景,助力消费电子与工业控制领域实现高性能、高可靠性设计升级。 02产品优势 高速与高摆率:拥有500MHz单位增益带宽与420V/us的压摆率,能够快速响应输入信号的变化,适用于对速度要求极高的应用场景。 宽适配性:2.5V~5.5V宽电源范围,轨到轨输出,输入共模电压覆盖-0.2~3.8V,兼容多系统设计。 建立时间快:仅需十几纳秒就能达到0.1%的建立精度,使得它在数据采集系统等对响应速度要求较高的应用中表现出色。 关键场景精准适配:完美覆盖ADC、滤波器、基带处理等高频信号处理场景,助力产品实现高性能升级。 03主要特点 -3dB带宽(G=+1):500MHz 压摆率:420V/us 输入失调电压:8mV(最大) 轨到轨输出 电源电压范围:2.5~5.5V 输入共模电压范围:-0.2V~3.8V(Vs=5V) 静态电流/放大器:7.5mA/单通道(典型) 关断电流(AiP8063/AiP8069):0.1uA 工作温度范围:-40°C~+125°C 封装形式: -AiP8061:SOT23-5/SOP8 -AiP8062:MSOP8/SOP8 -AiP8063:SOT23-6/SOP8 -AiP8064:SOP14/TSSOP14 -AiP8069:MSOP10 04引脚排列图 Pin Arrangement Diagram 05关键参数 06应用领域 07结语 除此之外,中微爱芯还提供其他系列不同带宽的高速运算放大器供客户选择,包括静态电流更低的AiP805X、AiP803X以及AiP809X系列产品,想要获取更多技术支持,欢迎联系我们!
运算放大器
中微爱芯官网 . 2026-03-19 777

产品 | 15MSPS高速采样,16bit高精度模数转换器让采样细节无处可藏!——AiP8342
01简介 AiP8342是中微爱芯推出的一款16bit、15MSPS、单电源、单通道的完整高速模数转换器。主要用于CCD成像应用设计。 AiP8342的单通道架构专为三线性彩色CCD阵列的输出采样和处理而设计。该通道包含输入钳位电路、相关双采样器(CDS)、偏移DAC、可编程增益放大器(PGA)以及高性能16位ADC。CDS放大器可禁用以适配无需CDS的接触式图像传感器(CIS)和CMOS有源像素传感器。16位数字输出以4位宽的多路复用格式提供。通过4线串行接口编程内部寄存器,可调整增益、偏移和工作模式。 02产品优势 简化开发流程,设计灵活性高:AiP8342内部集成了可编程增益放大器,可编程偏移与可编程基准电压。这种编程灵活性使它可轻松适配不同成像系统的信号调理。 高速传输保障,低功耗优化设计:AiP8342功耗仅为116mW(3.3V电源),但最高支持15MSPS速率,实现了低功耗与高速完美兼容。 多种采样模式,灵活时钟控制:AiP8342共有四种工作模式MODE1-MODE4,可满足多种输入采样要求,适配更多的应用场景。 紧凑型小封装,节省PCB空间:AiP8342采用SSOP20封装,可节省PCB空间,适合紧凑型设备设计。 03主要特点 16位15MSPS ADC 8位可编程增益 相关双采样模式(CDS) ±315mV可编程偏移 内部可编程基准电压 可编程4线串行接口 3.3V单电源供电 低功耗设计:116mW 封装形式:SSOP20 04引脚排列图 05典型应用图 06关键参数 07应用领域 08结语 中微爱芯还提供16bit 6通道120MSPS带信号预处理的高速模数转换器AiP8348/AiP8348B供客户选择。如需了解更多产品信息或获取技术支持,欢迎与我们联系。
模数转换器
中微爱芯官网 . 2026-03-19 658

方案 | 以光为刃,破暗驱雾!JWQ11880恒流驱动方案,提升车载照明感知能力
极夜环境,视野大幅受限,盲区风险骤增;雨雪天气,后视镜起雾挂水,视线模糊不清。为了全方位守护行车安全,智能汽车正构建一套完整的“视觉与照明矩阵”——从穿透雨雾的雾灯、彰显品牌标识的logo灯,到驾驶员监控系统(DMS)、舱内摄像头、夜视辅助及后视镜加热技术——让每一处光都更精准,让每一次出行都更安全。 功能再强大,也需“芯”脏强健。实现这些精准控制的背后,离不开一颗稳定可靠的驱动芯片。杰华特JWQ11880高频同步降压LED恒流驱动器应运而生。 后视镜 加热前 后视镜 加热后 车外后视镜加热恒流驱动 产品方案 JWQ11880典型应用框图 JWQ11880是一款集高频、同步整流与降压恒流于一体的车规级芯片。其具备双模调光能力:支持PWM调光,适用于驾驶员监测系统(DMS)、舱内监控、夜视补光及汽车logo灯、雾灯等大电流车载照明场景;也支持模拟调光,适用于车外后视镜加热等恒流驱动场景。凭借紧凑高效的核心设计,直击汽车红外照明与恒流驱动场景的技术痛点。 特性亮点 驾驶员监测系统场景/夜视补光 为应对严苛的汽车电子环境,JWQ11880 集成了多项先进特性,核心亮点如下: ● 高效同步整流:采用同步整流技术,能够显著降低导通损耗,实现高转换效率的电源输出,适配汽车场景的低功耗需求。 ● 宽频无闪调光:支持低至10Hz的PWM调光频率,可完美兼容30fps、60fps、120fps车载摄像头帧率,实现红外补光的无闪烁同步照明,保障视觉感知精准度。 ● 高频紧凑设计:默认2.2MHz高开关频率,可匹配更小体积的外部电感与电容,大幅节省PCB布局空间,适配车载场景的小型化需求。 ● 低EMI电磁优化:集成展频功能,有效抑制高频开关带来的电磁辐射,助力系统轻松通过严苛的汽车电磁兼容性测试。 性能参数 汽车LOGO灯应用 JWQ11880的性能参数,尽显其在汽车环境下的广泛适应性与强大驱动能力,核心优势如下: ● 宽压直驱设计:支持4V至36V宽输入电压范围,可直接对接汽车电池电源,无需额外搭建复杂预稳压电路,简化系统设计。 ● 高功率驱动能力:可提供1.5A的连续LED驱动电流,并支持高达3A峰值电流,足以驱动大功率红外LED。 ● 车规级宽温耐受:工作环境温度覆盖-40°C至125°C,完全符合汽车级电子产品对极端温度环境的要求,全工况稳定运行。 ● 低阻高效低耗:极低的功率MOSFET导通电阻(高压侧70mΩ,低压侧40mΩ),确保了在高负载下的低发热和高效率,保障高效运行。 杰华特车灯芯方案 通过对车灯领域的深度洞察,杰华特逐步推出丰富的车规级LED线性驱动芯片产品矩阵,如单通道JWQ11711,3通道JWQ11730/31,12通道JWQ11712,24通道JWQ11724,矩阵大灯解决方案JWQ1184+JWQ1182+JWQ11816,单级升压恒流控制器JWQ11886,DMS恒流驱动器JWQ11880等,将逐渐覆盖车内小灯、动态贯穿式尾灯、汽车前照灯等场景,为车身照明市场提供高集成度、高性能与高可靠性的一站式系统解决方案。 杰华特车灯芯片照明方案 杰华特汽车应用图谱
杰华特
杰华特微电子股份有限公司 . 2026-03-19 1449

企业 | 因不满薪资,三星6.6万余名员工将于5月举行18天罢工
3月18日消息,三星电子韩国工会正式宣布,罢工授权投票已高票通过,93%的参与员工赞成罢工计划,这意味着若劳资双方无法达成共识,三星或将面临大规模生产中断,全球半导体供应也将再添变数。 据悉,此次罢工授权投票共有66019名三星员工参与,超高赞成率被工会称为对管理层的"强烈警告"。工会明确表示,若双方未能在后续协商中达成一致,将先于4月23日举行集会,随后从5月21日起启动为期18天的罢工,核心诉求直指薪资与奖金机制改革。 作为韩国科技巨头,三星电子在韩员工总数约12.5万人,此次发起罢工的工会代表着近9万名员工,占比超70%。这场劳资冲突的导火索,是去年底陷入破裂的薪资协商,而竞争对手SK海力士的薪酬改革,进一步加剧了三星员工的不满。 据了解,SK海力士去年9月已同意工会提出的薪酬改革要求,取消奖金上限并将奖金与公司营运利润挂钩,这让三星员工对两者间的薪资差距愈发不满。为此,三星工会明确呼吁公司效仿SK海力士,取消目前设定为年薪50%的奖金上限,同时建立奖金与营运利润联动的机制。 面对工会的强硬诉求,三星电子发布声明回应,称将"全力以赴,友善地结束2026年薪资协商",但明确表示反对取消奖金上限。三星方面解释,半导体行业属于资本密集型且具有周期性,取消奖金上限将难以兼顾未来投资与股东回报,不利于企业长期发展。 分析指出,当前全球AI数据中心需求强劲,半导体供应本就处于紧张状态,若三星发生大规模罢工,将进一步恶化供应瓶颈,波及汽车、电脑、智能手机等多个依赖半导体的产业。据调研机构Counterpoint数据显示,三星在韩国本土生产100%的DRAM芯片和三分之二的NAND芯片,其生产中断的影响将辐射全球。 Heungkuk Securities分析师Sohn In-joon表示,取消奖金上限是此次劳资协商的棘手问题,双方达成协议面临巨大挑战。他进一步分析,取消上限可能会拉大芯片业务与手机、电视等其他业务的薪酬差距,后者受市场竞争激烈和芯片价格上涨影响,获利相对疲弱,难以支撑高额奖金。
三星
芯查查资讯 . 2026-03-19 1995
- 1
- 31
- 32
- 33
- 34
- 35
- 500