
产品 | 英特尔推出全新至强600系列工作站处理器
经过漫长的等待,英特尔终于推出了专用于工作站的至强600系列处理器。新系列代号为Granite Rapids-WS,主打单路工作站平台,强调高核心数、大内存容量以及丰富的I/O接口,可满足多GPU和存储密集型配置需求。 新芯片系列将取代现有的基于Sapphire Rapids的至强W-2500和W-3500系列工作站处理器,并与AMD高端工作站竞品Ryzen Threadripper Pro 9000系列展开竞争。英特尔总共为至强600系列准备了11款SKU,全部采用Redwood Cove P核,没有E核。位于顶端的是至强698X,拥有86个核心和172个线程,配备336 MB的三级缓存。该处理器基础频率为2.0 GHz,通过Turbo Boost Max 3.0可加速至4.8 GHz,或在Turbo Boost 2.0下达到4.6 GHz。英特尔确认698X完全解锁,支持超频,这在至强工作站领域仍相对罕见。 这些处理器搭配英特尔W890芯片组,CPU直连最多可提供128条PCIe 5.0通道。平台支持8通道DDR5-6400 RDIMM内存,最大系统内存容量可达4TB。与上一代至强WS 平台相比,Granite Rapids-WS拥有更大的二级和三级缓存,支持CXL 2.0以及更新的平台功能。英特尔还重点强调了vPro Enterprise支持,以及包括VNNI、AVX-512和AMX 在内的Intel Deep Learning Boost技术,面向AI推理和高级计算工作负载。 英特尔声称,与前代至强W-3500和W-2500 处理器相比,单线程性能提升高达9%,多线程性能提升高达61%。一张幻灯片还将Xeon 600系列与酷睿Ultra 5 245K进行了对比,其中酷睿处理器在单线程及部分CAD工作负载中领先,而Xeon则在3D场景渲染、照片级真实感渲染和线性代数运算中表现更优,反映了桌面级与工作站级CPU之间的典型取舍。 英特尔至强600系列工作站处理器将从2026年3月下旬,开始通过OEM/系统集成商和独立的盒装处理器发售。
英特尔
英特尔 . 2026-02-03 2072

企业 | 新思科技携手AMD荣登世界经济论坛MINDS榜单,生成式与自主式AI推动芯片设计进入全新阶段
新思科技与 AMD 合作的项目入选世界经济论坛(World Economic Forum)的 MINDS(Meaningful, Intelligent, Novel, Deployable Solutions,即“有意义、智能化、创新性、可部署的解决方案”)人工智能项目。该项认可意味着,两家公司跻身全球在人工智能领域具有领先实践的创新组织之列——这些组织不仅在技术上实现突破,更以落地应用产生了可衡量的实际成效。 MINDS 奖项与项目隶属于世界经济论坛的 AI Global Alliance(全球人工智能联盟)计划,旨在甄选能够在高复杂度、高风险挑战中引领人工智能应用落地的组织。新思科技与 AMD 是基于双方在半导体芯片设计领域将强化学习、生成式 AI 以及代理式(Agentic)AI 应用于工程流程方面的突出贡献而受到表彰——这是一个对创新速度与精度要求极高的技术领域。 在芯片设计中引入人工智能,已不再是可选项。架构复杂性快速攀升、性能目标日益激进以及人才缺口持续扩大,使传统的工程工作流面临极限压力。 AI 驱动的设计流程缓解了这些压力——它们并非取代工程师,而是提升专家知识的效能与决策质量。代理式(Agentic)与基于学习的系统能够帮助开发者更快速地探索庞大的设计空间,更有效地权衡取舍,并在问题成本最低时提前发现潜在隐患,从而实现更短的开发周期、更高质量的芯片以及更具韧性的创新链路。随着上市时间压力加剧以及高端芯片需求持续增长,这类流程正成为半导体行业未来发展的关键路径。 新思科技与 AMD 被选为 MINDS 奖项得主,凸显了在前所未有的行业压力下,AI 创新在半导体行业中的战略重要性。通过对这两家公司的认可和表彰,世界经济论坛强调:基于代理式(Agentic)和强化学习驱动的 AI 正从实验阶段迈向可规模化、可投入生产的工作流程。它们在增强人类开发者专业能力的同时,为工程团队及更广泛的科技生态体系带来实质性价值。 作为全球最具创新力企业的重要研发合作伙伴,新思科技始终致力于推动行业前行。此次入选世界经济论坛 MINDS 项目,并因 AI 在芯片设计这一极其复杂的工程领域中的突破性应用而获得认可,我们深感荣幸。 Shankar Krishnamoorthy 首席产品开发官 新思科技 从强化学习到 Copilot 辅助功能,新思科技的 AI 能力正在助力 AMD 持续缩短芯片设计周期并提升开发者的生产力。我们为与新思科技长期的合作伙伴关系感到自豪,并期待继续携手通过代理式(Agentic)AI 共同开启芯片设计的下一个前沿。 Brian Amick 技术与工程高级副总裁 AMD 新思科技与 AMD 因其在利用 AI 重塑芯片设计流程方面的突出成果而获选。世界经济论坛在《超越承诺的实证:2025 年 MINDS 组织的真实世界 AI 落地洞察》中指出:“在半导体芯片设计中,人类智慧至关重要,但人才短缺正在持续威胁行业发展。AMD 正利用新思科技的强化学习与代理式(Agentic)工作流承担更多执行任务,从而最大化发挥工程专家的知识与时间投入。他们的方法使芯片设计速度提升一倍,拓展了可行设计方案的范围,并缩短了产品上市时间。” 基于双方长期合作关系,新思科技与 AMD 已引入面向设计、验证与签核阶段的 AI 驱动流程,带来了对 AMD 极具影响力的转变性成果: 设计与验证阶段的整体生产力翻倍 设计空间探索能力扩大 25%,使团队能够评估更广泛的方案 总体设计成本降低至原来的五分之一 签核时间缩短 50%,且后期变更减少 更快的设计周期提升了可靠性并减少缺陷
AMD
新思科技 Synopsys . 2026-02-03 1008
企业 | Molex莫仕12亿增资东莞,聚焦AI服务器高速连接
项目启建:落子东莞 扩产提速 2026年1月29日下午,东莞市副市长李辉与莫仕Molex高级副总裁Aldo Lopez一行面对面座谈,共同推进莫仕在东莞石碣进一步增资扩产,拟追加投资约12亿元,同时敲定落地投产节奏,探讨未来深化合作方向。重点聚焦AI服务器高速连接线生产,加速推进高端制造与智能化升级,持续巩固其在高速互连领域的技术与产业领先地位。 产线升级:智造提效 规模生产 本次扩产将围绕AI算力基础设施快速增长带来的市场需求,提升高速互连产品在高频、高速及高可靠性方面的制造能力,推进线材加工、焊锡、注塑、测试等环节的自动化水平,同步开展线束线缆组装产品的设计与规模化生产工作,通过产线优化提升整体生产能力与运营效率。项目建成投产后,预计将实现产能结构与产品附加值的显著提升,为数据中心、AI服务器等关键应用提供更具竞争力的互连解决方案。 行业研判:锚定赛道 前瞻布局 随着人工智能AI和高性能计算持续发展,高速互连技术正成为行业竞争的核心。AI服务器需求爆发带动高速线(如 PCIe、DDR、高速背板连接器等)技术升级。此次扩产是对高速线技术趋势与市场前景的坚定判断,也体现了Molex莫仕将高速互连作为未来增长引擎的长期战略方向。 合作共赢:投资中国 共筑高地 自1988年在东莞设立生产基地以来,Molex莫仕已在当地深耕三十余年。本次再度加大投资,彰显Molex莫仕对中国电子信息产业链成熟度、制造能力及长期市场潜力的高度认可。未来,Molex莫仕将持续依托中国完善的产业生态,与合作伙伴共同推动互连技术创新与产业升级,为全球AI算力基础设施建设提供有力支撑。
molex
Molex莫仕连接器 . 2026-02-03 1904
应用 | 别再只关心快充了!你设备里的“隐形交通指挥官”才是关键!
“快充”之下 当我们谈论手机、平板、TWS耳机的充电体验时,话题总围绕着 “快充功率有多大”、“电池容量有多少毫安时”。 但你是否想过,当你边充边玩,或者连接电脑传输数据时,设备内部正上演着一场紧张有序的“功率调度”大戏? 这场大戏的总指挥,就是充电管理IC中一个至关重要的功能——路径管理。在现代电子设备中,充电管理已远远超出了简单的“给电池充电”范畴。 它需要智能管理来自适配器、USB-C接口等多种输入电源的能量,同时协调电池充电与系统供电之间的复杂关系。 如果把一个电池供电系统比作一所别墅,那么充电管理IC就像管家一样,他不仅仅负责对电池进行充电电流和电压的调节,同时还需要将输入功率进行合理的分配以及对电池进行合理的充放电控制。 在传统架构中,没有所谓的路径管理,系统的负载是直接接在电池端。这种结构简单,但是也有很多不足。 由于系统负载和电池接在一起,在电池电量较低时,充电IC会以较小的电流对电池充电,从而也限制了系统的功率,系统无法立即开机。另外充电管理IC无法区分系统电流和充电电流,无法准确判定充电截止。 另一方面,当充电截止后,充电管理IC停止工作,即使在输入有电时也是由电池供电,会导致电池频繁充放电。最后,由于系统一直接在电池上,即便在关机或者运输模式下,电池的静态功耗较大。 在众多电源管理架构中,NVDC(窄电压直流充电)和HPB(混合型升压充电) 因其不同的设计理念和适用场景,成为当今最主流的两种解决方案。 电源路径管理:能源分配的大脑 电源路径管理是现代充电芯片的核心智能,它决定了电能如何在不同组件间高效流动。 传统非电源路径管理架构存在明显缺陷: 当电池深度放电或有缺陷时,即使连接外部电源,系统也可能无法启动,因为系统输入和电池电极连接到相同的充电器输出节点。 更重要的是,这种架构下充电器只能检测到流入电池和系统的总电流,很难准确判断电池是否已充满。 现代电源路径管理通过输入动态功率管理(DPM)和功率路径管理(PPM)技术解决了这些问题。 当输入电源功率无法满足系统负载需求时,系统母线电压开始下降。当电压降至预设值时,充电芯片会自动减小充电电流,将部分功率分配给系统负载使用。如果在充电电流降为零后,系统负载需求仍超过输入电源能力,电池便会介入补充供电。 这种智能功率分配确保了系统稳定性,避免了因瞬时负载过大导致的系统崩溃或重启。 NVDC架构:系统稳定的守护者 NVDC (Narrow Voltage Direct Current,窄电压直流充电) 架构广泛应用于笔记本电脑、平板电脑等设备的锂电池管理系统中。 NVDC架构通过降压电路(也可以是其他拓扑)将适配器输入电压转换为一个窄范围的直流系统电压,而不是直接将适配器电压提供给系统。 而该直流系统电压略高于电池电压,但不低于可编程的最小系统电压。这样,即使电池完全耗尽或被移除,系统也能获得稳定的电力供应。 在NVDC架构中,系统的输出直接由电池电压影响。例如,两节锂电池的电压影响范围约为5.5V-8.4V,远比直接使用适配器电压的范围要窄得多,这大大简化了系统级电源的设计。 NVDC架构的主要优势包括: 电池耗尽或无电池情况下可即时启动系统,解决了传统架构的“死电池”问题 减少电池充放循环次数,电池充满后BFET会自动关断,系统负载直接由适配器提供,有效延长电池寿命 动态功率管理,优先保证系统功率输出,在适配器功率不足时自动减小充电电流甚至切换至补电模式 杰华特明星产品推荐 JW36433是一款支持1节电池的NVDC架构降压充电IC,集成了动态功率管理功能,可在输入电源能力较弱时自动限制输入电流并降低充电电流。 4V to 15V工作电压与22V可持续耐压 5V OTG输出,电流限制高达1.2A 全集成所有功率管 无需检流电阻 基于输入电压环和输入电流环的功率管理 窄范围直流电压功率路径管理 精准的截止电流 低LSB电池充满电压配置 电池FET支持运输模式和复位模式 通过I2C接口实现灵活控制 电池FET具有低导通电阻 最高12A放电电流能力 符合JEITA标准的电池温度保护 HPB架构:性能爆发的助推器 HPB(Hybrid Power Boost,混合功率升压)架构是另一种创新的电源管理方案,专为满足现代高性能设备瞬时峰值功率需求而设计。 HPB架构的本质是一种同步双向降压充电器,在正向工作时为降压模式(充电),反向工作时为升压模式(放电)。 它能在系统负载超过适配器输出功率时,启动混合功率升压模式,让电池与适配器一起为系统提供能量。 杰华特明星产品推荐 JW3680是一款典型的HPB架构充电芯片,它支持8V到24V的宽输入范围,可实现2S到4S电池充电管理。 当系统功率需求增加时,充电电流会首先降低以保持适配器电流在安全范围内。如果系统功率继续增加,将触发混合功率升压模式补充系统功率。 支持使用8V至24V适配器为2至4节电池组充电 通过NMOS实现适配器与电池间的自动电源选择 高精度的功率与电流监测 全面的PROCHOT中断功能 可通过SMBus接口编程充电与放电参数 通过ILIM引脚实现实时系统控制,以限制充电与放电电流 针对过压保护、过流保护、短路保护的增强型安全特性 进入升压模式的超快瞬态响应 杰华特——与您携手并进 在科技日益精进的今天,充电管理已悄然演变为一场看不见的“能量调度”。 无论是保障系统随时就绪的NVDC架构,还是应对瞬时高性能需求的HPB方案,都如同设备内部的“隐形指挥官”,在安全与效率之间实现精密平衡。 未来,杰华特也将通过对产品研发的持续精进和投入,为万千用户提供不可或缺的支撑力量。
杰华特
杰华特微电子股份有限公司 . 2026-02-03 1750

产品 | 川土微电子CA-HP6802FP 3‑17串智能电池采集前端
在锂电池管理领域,如何在高可靠性、高精度与低成本、小体积之间取得完美平衡,一直是行业难题。川土微电子CA-HP6802FP 3‑ 17串智能电池采集前端凭借 “全功能硬件保护状态机”与“高精度双ADC采集系统” 两大引擎,在单颗SOC芯片内实现了从信号采集、全保护到电源管理的完整闭环。更创新性地集成高压BUCK电源,省去外部电源芯片,显著降低系统成本与布板面积。CA-HP6802FP以“保护自动化、设计简约化、成本最优化”为核心,为锂电池包管理提供了一站式的高可靠性解决方案。 产品概述 CA-HP6802FP是一款专为3到17串锂电池包设计的具有多合一功能的高可靠性、高性能的SOC级锂电池包主控芯片。 基于创新的BMS系统架构,为锂电池包BMS主板提供高可靠性、高精度、高耐压、低功耗、低PCB占板面积的集成化解决方案。 内部集成了高精度信号采集转换、全功能保护硬件状态机、高耐压低功耗电源转换,无需外部MCU 和电源转换芯片配合,就可独立监测和保护锂电池包,也可配合外部 MCU 对锂电池包监测,同时实现软件保护及电量计算,从而增加系统设计的冗余,进一步增强保护可靠性。 CA-HP6802FP的全功能保护硬件状态机及高精度数据采集单元,显著降低了对外部MCU的性能要求,减少了系统BOM成本。 特性 保护功能 – 过压/欠压保护功能 – 充电高温/低温保护功能 – 放电高温/低温保护功能 – 内部过温保护功能 – 放电过流 1/2,短路保护功能 – 充电过流保护功能 电池电压平衡功能 电池连接断线检查和保护功能 负载检测,充电器检测功能 电子锁控制功能 EDSG 控制充电管功能 I2C 接口和 ALARM 输出,与外部 MCU 通讯 通用电压数模转换器 ADC1 – 17 路电池电压采集通道 – 1 路电流采集通道 – 可选 BAT,VDDA,VCC,VBO,PACK 电压 – 1 路 PACK 电压采集通道 (可选) – 2 路 AUX 电压采集通道 (可选) – 3 路外部温度采集通道 (可选) 高精度电流采集和库仑计专用 ADC2 集成一路高压 BUCK MOSFET 驱动:低边 NMOS 驱动 独立工作或配合 MCU 工作 工作模式:正常工作模式,休眠模式 封装:QFP‑48 典型应用场景 电动自行车 储能装置 园林工具 CA-HP6802FP 典型应用电路 川土微电子持续加大高性能模拟产品线研发投入,目前在隔离采样、高精度电流传感器、BMS AFE、高精度信号链、高性能射频芯片等产品细分上,累计量产超100款芯片。未来,我们将持续在磁传感器、BMS AFE、射频、高速信号传输等方向加大投入,为客户提供高性能信号链芯片矩阵。
川土微
川土微电子chipanalog . 2026-02-03 1358
技术 | Kiwi Talks:从AI模型到智算中心视角看真正的超节点系统
英伟达凭借其 GB200、300 NVL72 机架系统,在全球多个AI技术前沿地区已实现大规模出货与应用,成为业内首家也是少数能将“超节点”概念从理论推向极致工程化实践的公司。 大摩对2025年全年GB200/300 NVL72出货量的预测在28K台左右,分别由广达、Wistron以及鸿海等公司(ODM)组装集成。 英伟达构建的“超节点”(Super Node)生态,是一个以CUDA统一软件栈为基座、以极致协同设计为灵魂、贯穿从硅物理到AI应用的全栈式体系。其核心并非单一技术突破,而在于通过端到端的深度集成,将每一层的性能与效率推向极限,从而将庞大的数据中心塑造成一台能够高效执行单一AI任务的“巨型计算机”。 更实际的来说,超节点系统的根本需求直接地来源于上层AI的应用本身。如何将AI模型的训练或者推理在计算、通信与内存访问等模式下,通过深度的软硬件协同设计,构成一个高效执行的整体,这个为特定AI负载而生的协同系统,才是真正意义的超节点。 从硬件层到模型算法,构筑全链条生态范式 AI生态是一个贯穿“硬件层→系统底层→框架工具→模型算法→推理服务→运维管理→终端应用”的全栈式技术体系。其核心在于打通从芯片算力到行业场景的完整链条,旨在实现计算资源的全局智能调度、AI模型的高效部署迭代,以及产业智能价值的全面挖掘与释放。 服务与管理层 服务与管理层是企业AI能力的“指挥中枢”与“运行平台”,它面向企业级用户提供综合服务以实现算力资源的智能化管理和服务化输出为目标。此层包括算力调度与管理平台(统一调度 GPU/NPU 资源)、高性能推理引擎(支持多模型并发)、一站式开发平台(DevOps+MLOps)、全域监控与容错系统(保障服务稳定性和可靠性)。这些服务帮助企业构建自主、高效、稳定的AI能力中台,提高工作效率。 案例:Triton推理服务平台是英伟达推出的开源推理服务软件,其核心定位是成为部署与管理生产环境中AI模型的“操作系统”。它不负责底层模型的逐层优化(属于TensorRT的工作),而是专注于解决在GPU服务器集群上,如何同时高效、稳定地服务成百上千个不同模型实例的系统级挑战。 Triton的主要功能在于多框架、多模型、多实例并发服务:它能在一个服务器上同时加载和运行来自TensorFlow、PyTorch等多个后端的模型。每个模型还可以部署多个实例并利用动态批处理等技术,让这些模型和实例并发处理请求,最大化GPU利用率,实现从单卡到多卡、多节点的横向扩展。Triton可以理解为生产服务平台,为企业级模型部署进行管理。 推理层 推理层致力于实现模型在实际业务中的高效运行,其核心目标是达到低延迟、高吞吐量、低成本的实时推理服务。它包含推理框架(如TensorRT、OpenVINO)、执行引擎(计算图编译器)、性能优化模块(内存与缓存管理 KV Cache 优化、计算加速如算子融合、低精度推理、并行与调度如连续批处理、混合并行)。这些组成部分保证了模型能够在生产环境中稳定、高效地运作。 (图:来源英伟达) 案例: TensorRT是英伟达推出的高性能深度学习推理优化引擎,专门将训练好的AI模型转化为高效的推理引擎,实现最高40倍加速。它将多个计算层合并为单个优化内核。例如将"卷积→批归一化→激活函数"三个独立操作融合成一个CUDA kernel,减少67%的内存访问次数和GPU启动开销。TensorRT实现精准与量化,最大化利用GPU Tensor Core,同时支持多精度推理包括FP16,INT8,FP8/INT4等,实现倍数性能提升和显存节省。 此外,其具备内核自动调优功能,针对不同的模型架构、输入尺寸和英伟达GPU架构(如Ampere, Hopper),TensorRT会从海量的优化内核实现中,自动为每一层操作选择或生成运行最快的那个内核。这使得同一个模型在不同代次的GPU上都能获得最优性能。 模型与算法 模型与算法层聚焦于模型本身的技术创新与优化,旨在不牺牲精度的前提下,提升模型推理速度与部署效率。该层涉及模型架构创新(如 Transformer、MoE)、模型优化技术(量化、压缩、剪枝、蒸馏)、模型算法加速与改进,以及模型 IDE/模型仓库(支持模型版本管理、共享与复用)。这些元素结合在一起,促进了模型的快速迭代和高效利用。 (图:由AI Agent生成) 案例:DeepSeek-V3在架构创新上取得了突破性进展。该模型拥有671B总参数,但每个token仅激活37B参数,激活率仅为5.5%,这极大降低了推理成本 团队引入了创新的MLA(Multi-head Latent Attention)机制,将传统MHA(Multi-head Attention)中的KV缓存压缩至原来的1/8,直接解决了长文本推理中的显存瓶颈问题。 在优化层面,DeepSeek采用了FP8混合精度训练,在不损失模型精度的前提下,将训练速度提升了2.3倍。同时,通过自研的DualPipe流水线并行算法,实现了跨节点94.6%的通信效率,远超传统方案的75-80%水平。在2048个GPU节点的超节点集群上,DeepSeek-V3的训练吞吐量达到了每秒14.8万tokens,训练总成本仅为557万美元,相比GPT-4等同级别模型降低了60%以上。这一系列数据充分证明:算法架构的精心设计与硬件基础设施的深度耦合,能够创造出远超线性叠加的系统级性能增益。 框架与工具 这一层面向算法工程师,提供了构建神经网络所需的深度学习框架、分布式训练工具包和自动化运维工具。优秀的框架层能够自动处理复杂的并行策略(数据并行、模型并行、流水线并行),极大地降低了模型开发的门槛。 (图:AI Agent生成) 举例:Megatron-LM 是由NVIDIA开发的大规模语言模型训练框架。Megatron-LM作为一个轻量级的研究框架,利用Megatron-Core以无与伦比的速度训练LLM。Megatron-Core作为主要组件,是一个开源库,包含GPU优化技术和对大规模训练至关重要的前沿系统级优化。它支持多种高级模型混合并行技术,包括张量、序列、流水线、上下文和 MoE 专家并行。该库提供可定制的构建模块、训练弹性功能(如快速分布式检查点)以及许多创新功能。 在单超节点内部(如DGX系统,通过NVLink全互联),Megatron-LM会优先将通信最密集的张量并行组部署在NVLink带宽最高、延迟最低的GPU子集内,最大化利用其数TB/s的互联带宽。对于跨超节点的流水线并行,则通过InfiniBand或Spectrum-X以太网进行通信,框架会优化通信与计算的重叠,减少跨节点通信的延迟影响。 系统与底层 (图:来源英伟达) 系统与底层负责操作系统、驱动程序及基础运行环境的构建,其核心目标是实现硬件抽象、资源统一管理和高并发处理能力。这一层的主要任务是将复杂的硬件拓扑对上层透明化,并提供高效的内存管理、设备通信和并行计算原语。它需要解决异构硬件的兼容性问题,确保算力资源的细粒度切分与调度。 具体而言,系统与底层包含以下核心组件:操作系统与驱动程序——包括各种Linux发行版(如Ubuntu、CentOS)以及国产操作系统(如麒麟OS、统信UOS),以及针对AI加速器定制的驱动程序(CUDA Driver、ROCm等);并行与通信库——如MPI(Message Passing Interface)用于跨节点进程通信,NCCL(NVIDIA Collective Communications Library)专门优化其GPU间集合通信;DeepEP是专门针对稀疏激活专家特性设计的通信库,仅按需通信,从而提升带宽和时延性能;异构计算支持——实现CPU/GPU/NPU等不同计算单元的协同工作,通过统一的运行时(如OpenCL、SYCL)屏蔽底层差异。通过这些组件,系统与底层确保了不同硬件之间的无缝协作和高效资源共享。 硬件层 硬件层作为整个算力软件生态系统的基石,旨在为上层提供强大、异构且可扩展的计算底座。这一层包括多种类型的硬件设备,如GPU、NPU、ASIC、FPGA 等。此外,还包括高速互联技术和海量数据存储解决方案,确保了底层硬件能够高效地支持大规模并行计算和数据处理需求。 计算:单卡算力 算力芯片是驱动AI大模型与推动产业发展的核心战略资源。今年1月初,英伟达正式推出新一代“Rubin”计算架构。相比前代Blackwell,Rubin在计算、互联与存储方面均实现提升,单卡算力方面,其采用Vera CPU与Rubin GPU异构集成设计。 Vera CPU 集成88个定制Olympus核心,支持176线程空间多线程,兼容Armv9.2。 通过NVLink-C2C与Rubin GPU互联,共享1.8 TB/s带宽,为上一代Blackwell 的2倍、是PCIe Gen 6的7倍。 Rubin GPU 首次搭载Transformer引擎,可动态调节各层精度,兼顾吞吐量与关键区域精度。 推理性能达50 PFLOPS(NVFP4),为Blackwell的5倍,保持精度并提升BF16/FP4性能;训练性能达35 PFLOPS,为Blackwell的3.5倍。 网络互联 在AI大规模集群超节点概念盛行的当下,计算芯片厂商们的竞争早已不在局限于单颗计算芯片的性能,还包括网络互联在内的系统性解决方案的比拼。在2020年完成对Mellanox的收购后,英伟达快速补齐了AI基础设施网络拼图,实现了片间互联(人员NVLink+ NVSwitch)和网间互联(如ConnectX 系列网卡进阶)等全栈互联优化方案,形成了极高的技术壁垒和生态粘性。 Scale out:Connect X系列超级网卡升级 英伟达ConnectX网卡是构建现代数据中心,特别是AI计算集群的底层关键技术,其通过硬件深度集成RDMA协议,以及不断创新的硬件卸载、低延迟通信和超高带宽技术,支撑着从传统数据中心到“AI工厂”的演进。 英伟达于近期推出的NVIDIA ConnectX-9 超级网卡,可处理横向扩展网络,每个 GPU 可提供 1.6 TB/s 的 RDMA 带宽,是上一代带宽2倍,实现机架外部的通讯。 ConnectX-9 与 Vera CPU 共同设计,旨在最大限度地提高数据路径效率,并引入完全软件定义、可编程的加速数据路径,使 AI 实验室能够实现针对其特定模型架构优化的自定义数据传输算法。其计划搭载于Vera Rubin NVL72机架,但尚未量产出货。 Scale up:NVLink/NVSwitch 超节点通过紧密耦合多个GPU,使其协同如单一计算单元,其核心在于实现极低延迟与超高带宽的互联。英伟达凭借其NVLink协议实现这一目标,该协议自2014年首次推出至今已迭代至第六代。在全新Rubin架构中集成的NVLink 6.0,使单GPU互联带宽达到3.6 TB/s,为上一代(NVLink 5.0)的2倍,SerDes速率达224 G。 NVLink与NVSwitch协同构成了英伟达大规模高效计算集群的基础。最新NVSwitch 6.0的端口速率提升至400 Gbps,采用SerDes技术保障高速信号传输;每颗GPU可实现3.6 TB/s的全互连带宽。每个Vera Rubin NVL72机架配备9台该交换机,总纵向扩展带宽达260 TB/s,支持高效稳定地训练与运行参数规模达10万亿级的超大模型。 能耗/液冷/供电 为了满足人工智能和高性能计算对于更强数据中心的需求,越来越多高性能的计算芯片被各大厂商相继推出。然而高性能通常与高功耗相伴,Blackwell B200 GPU单颗芯片的功耗1000W, GB200 NVL72超节点功耗超过120kw。而最新推出的Rubin NVL144和规划中的Rubin Ultra NVL576,功耗分别突破200kw和1000kw。 液冷方面,随着高性能服务器机柜功率普遍突破100kW,传统风冷方案已无法满足散热需求。对此,液冷技术成为行业主流解决方案。以英伟达最新发布的Rubin NVL72系统为例,该平台实现了全系统级液冷设计,完全取消传统风冷组件,并首次采用微通道冷板技术。优化后的冷却系统流速达60L/min以上,散热效率为上一代系统的两倍,同时仍支持高达45°C的进水温度。 供电方案方面,芯片功耗的急剧上升使电力成为制约AI规模化部署的关键因素。为突破现有供电方案瓶颈,英伟达率先推动机架电源从54V直流向800V高压直流(HVDC)升级。该方案采用边缘固态变压器(SST),直接将10kV-20kV交流电转换为800V直流,简化供电链路为“高压市电→800V DC→芯片低压”。此举显著降低了电阻损耗、释放了机架内部空间、改善了热管理效果,并具备高度可扩展性,支持单机架供电能力从100kW逐步提升至1MW。 总结 过去数十年,无论是硬件还是软件层级,在进化迭代上更多考虑单点突破带动性能狂飙。进入2025年之后,在摩尔定律及算法技术瓶颈等各方面因素推动下,产业链软硬件环节更加考虑系统层级协同,如行业也不再一味追求“超级硬件”和“超级集群”,而是强调从软件侧、互联等各方面更大程度释放硬件的潜力。2026年,系统的优化工作将会更加精细化,与进一步探索基于低成本硬件的极致性价比,其根本驱动力与最终归宿,都指向一个务实的目标:更高效地推动AI技术走出实验室与数据中心,渗透至千行百业,并以更低的总体成本创造普惠价值。
奇异摩尔
奇异摩尔 . 2026-02-02 1 3577
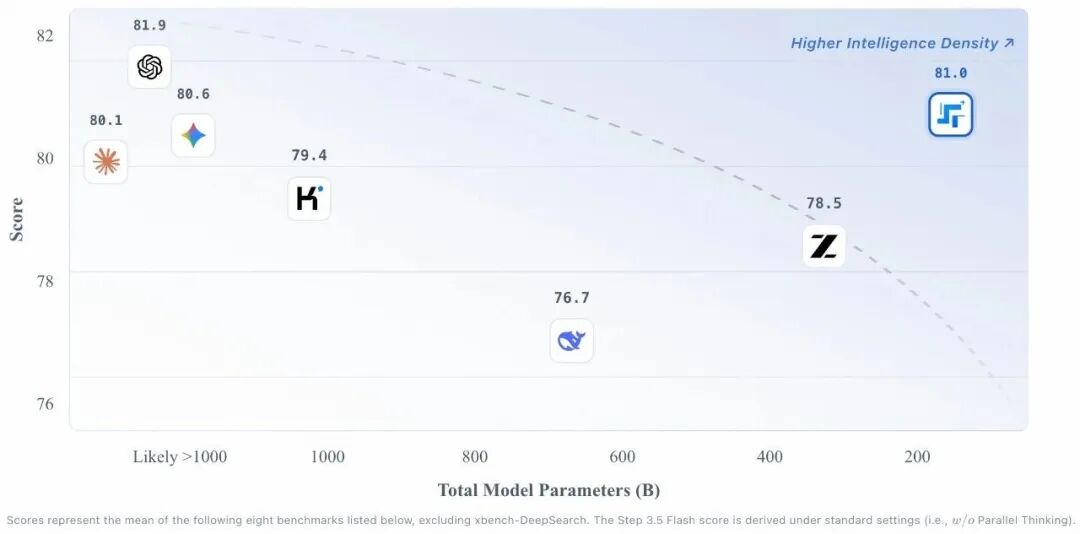
企业 | 曦云C600 Day 0 适配阶跃星辰基座模型 Step 3.5 Flash
今天,阶跃星辰技术团队发布并开源最新旗舰基座模型 Step 3.5 Flash。沐曦股份已实现曦云C600与该模型深度协同适配,为国内首先完成与该模型Day 0适配的国产算力。 曦云C600集成大容量存储与多精度混合算力,支持MetaXLink超节点扩展技术,并内置ECC/RAS多重安全防护模块,为金融、政务等关键领域提供高可靠算力基座,满足下一代生成式AI的训练和推理需求,性能强劲。 此次深度高效适配得益于沐曦全栈自研MXMACA软件栈的强大生态适配能力。作为沐曦“自主GPGPU硬件+全栈软件体系”的关键协同载体,MXMACA承担着连接硬件算力单元与上层应用生态的核心纽带作用。MXMACA软件栈原生兼容主流生态,这意味着AI应用可以几乎零成本地迁移到沐曦的平台上,基本做到“即插即用”。MXMACA软件栈于2025年2月份开源,现已拥有超过15万用户。 关于Step 3.5 Flash模型 Step 3.5 Flash模型旨在为开发者提供更稳定可靠且兼顾性价比的智能体(Agent)底层支撑,让 Agent 能够更加高效地实现规模化,真正融入日常开发工作。Step 3.5 Flash 采用了稀疏混合专家(MoE)架构,总参数量达 1960 亿,每个 Token 仅激活约 110 亿参数,实现了推理能力与运行效率的平衡,显著提升了模型在复杂 Agent 工作流中的响应速度。 随着越来越多开发者正在从单纯提示词工程转向 Agent 和 Workflow 的构建,共性瓶颈也出现了:尽管底层模型强大,但在规模化场景下往往不够稳定、响应过慢、成本过高。Step 3.5 Flash 为此进行了专项优化,可满足多步推理中的低延迟响应需求。这种高性能表现使得开发者在面对高频重试、多重验证与反思机制时,无需再通过减少推理步骤或降低验证强度来妥协性能,从而保障了 Agent 在规模化应用场景下的可靠性。 在针对智能体能力的 τ²-Bench 、BrowseComp 等测试,以及 LiveCodeBench V6 代码挑战和 AIME 2025 数学竞赛中,Step 3.5 Flash 均取得了亮眼成绩,且在 Agentic 和数学任务上极具竞争力。这意味着当其面对需要结构化输出的多步推理、复杂逻辑求解、后端自动化和长时间运行等任务时,已具备支持企业级应用落地能力,尤其适用于高频工具调用和对行为可预测性有强要求的系统环境。 在实际应用场景中,Step 3.5 Flash 展示了强大的自动编程与“端云协同”能力。比如,它不仅能基于自然语言指令自动构建复杂的可视化地理空间系统,还能作为“云端大脑”将复杂的用户需求拆解为多个子任务,协同本地设备高效完成跨平台数据分析与决策支持。此外,为了满足开发者对数据隐私和本地算力应用的需求,该模型还针对本地部署进行了性能优化。 Step 3.5 Flash 已在 OpenRouter、GitHub 及阶跃AI APP 和网页端同步上线,面向开发者提供免费试用与快速部署支持。 即刻体验Step 3.5 Flash 从GitHub下载以便快速部署:github.com/stepfun-ai/Step-3.5-Flash huggingface: https://huggingface.co/stepfun-ai/Step-3.5-Flash/tree/main 在「阶跃AI」APP 或网页端免费使用。 关于沐曦股份 沐曦股份致力于自主研发全栈高性能GPU芯片及计算平台,为智算、通用计算、云渲染等前沿领域提供高能效、高通用性的算力支撑,助力数字经济发展。
沐曦股份
沐曦股份MetaX . 2026-02-02 2261

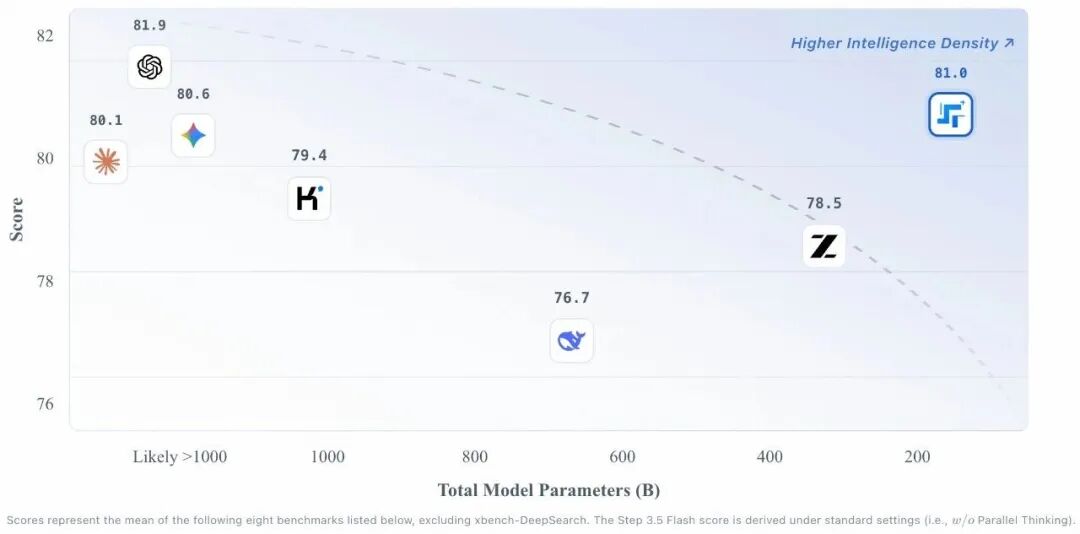
企业 | 壁仞科技Day 0适配Step 3.5 Flash,重塑Agent工作流!
2月2日,阶跃星辰发布并开源最新旗舰基座模型Step 3.5 Flash。壁仞科技(06082.HK)作为国产GPGPU领域的先进技术领导者,壁砺™ 166系列产品在模型发布当日快速完成适配,成为国内首批适配Step 3.5 Flash的国产GPU厂商之一。开发者后续可通过开发者云体验Step 3.5 Flash强悍性能,以及如何以高稳定性重塑Agent(智能体)工作流。 Step 3.5 Flash模型面向Agent工作流场景打造,兼顾推理速度、智能水平与使用成本。Step 3.5 Flash为开发者提供了一个“更快更强更稳”的Agent底层模型选项,能够真正融入日常开发,成为大家可靠、高效、易用的“Agent 搭子”。 Step 3.5 Flash采用稀疏混合专家架构(MoE),总参数规模1960亿,每token实际激活参数约110亿,在保证模型能力的同时显著提升推理效率,为Agent类应用提供更高效、可负担的底层模型选择。 Step 3.5 Flash模型在壁砺™166服务器上基于壁仞科技适配的vllm推理框架进行推理。 壁砺™166系列为数据中心大算力训推一体芯片,可满足万亿参数模型需求,广泛应用于大语言模型、多模态AIGC、图像与语音、推荐系统等。 本次Day 0适配充分展现了壁仞科技BIRENSUPA™卓越的生态兼容性与高效的迁移能力。BIRENSUPA™是基于自研GPGPU指令集与芯片架构打造的统一、可扩展并行计算编程模型与软件栈,支持开发者在壁仞科技GPGPU上高效构建多样化应用。壁仞科技在数小时内即完成对Step 3.5 Flash模型的支持,进一步印证了壁砺™系列产品的技术成熟度与出色的开箱即用特性——开发者和企业依托壁砺™系列GPGPU可快速构建大模型服务,极大降低迁移成本,为国产大模型与芯片协同设计树立了行业新标杆。 目前,壁仞科技已与阶跃星辰、上海仪电智算服务形成“芯片研发-大模型创新-算力服务”的战略合作。Day 0适配是打通“芯片-模型-平台-应用”全链路的关键一环,将为构建国产算力调度平台和行业解决方案奠定坚实基础。 【关于Step 3.5 Flash】 在针对智能体能力的τ²-Bench、BrowseComp等测试,以及LiveCodeBench V6代码挑战和AIME 2025数学竞赛中,Step 3.5 Flash均取得了亮眼成绩,且在Agent和数学任务上极具竞争力。这意味着当其面对需要结构化输出的多步推理、复杂逻辑求解、后端自动化和长时间运行等任务时,已具备支持企业级应用落地能力,尤其适用于高频工具调用和对行为可预测性有强要求的系统环境。 在实际应用场景中,Step 3.5 Flash展示了强大的自动编程与“端云协同”能力。比如,它不仅能基于自然语言指令自动构建复杂的可视化地理空间系统,还能作为“云端大脑”将复杂的用户需求拆解为多个子任务,协同本地设备高效完成跨平台数据分析与决策支持。此外,为了满足开发者对数据隐私和本地算力应用的需求,该模型还针对本地部署进行了性能优化,支持在主流个人工作站上流畅运行。 Step 3.5 Flash已在OpenRouter、GitHub及阶跃AI APP和网页端同步上线,面向开发者提供免费试用与快速部署支持。
壁仞科技
壁仞科技Birentech . 2026-02-02 1 2674

企业 | TE 与汇川技术签署战略合作协议,双向赋能共筑智能制造新生态
1月26日,TE Connectivity(以下简称“TE”)与汇川技术,在汇川技术苏州总部正式签署战略合作协议。此次合作旨在深化双方在工业自动化领域的协同发展,通过优势互补与资源整合,实现双向赋能,共同推动智能制造生态体系建设。 本次战略合作不仅实现了工控技术和连接与传感技术的深度融合,也通过资源协同推动全球化布局与本土化深耕的协同发展,成为国际技术资源与本土产业实力融合的行业合作典范。 TE 高级副总裁兼总经理Carlo Ghirardo、 TE 战略采购总监陈厚义、 TE 亚太区产品管理总监徐翊、中国/东南亚销售总监宋湘辉,以及汇川技术联合创始人张卫江、汇川技术工业自动化事业群海外销售副总裁朱本、汇川技术运动控制产品线总监薛斌峰、汇川技术工业自动化事业群汽车行业总经理倪高峰等双方代表出席签约仪式,共同见证这一重要时刻。 双向赋能,协同推进智能制造升级 以技术创新为纽带,此次战略合作将重点聚焦三大核心方向: 深化技术协同创新,共建数智发展新动能 双方将建立常态化技术协同机制,整合优势资源,联合打造OT/IT融合智能解决方案,重点探索产线预测性维护、推动工厂数智转型、加快AI工业场景落地,赋能生产管控,提升核心技术竞争力与市场影响力。 深耕本土应用场景,践行“研发在中国、服务为中国”理念 立足本土制造需求,双方将构建本土化研发、服务、适配体系,精准对接企业个性化需求,强化本土服务团队建设,助力本土制造企业转型升级,彰显服务本土、赋能实业的责任担当。 携手开拓国际市场,构建协同出海新模式 依托TE全球网络、国际运营经验及认证优势,结合汇川技术自动化产品实力,汇川技术与TE将搭建协同出海平台,精准对接全球市场需求与标准,优化推广策略,共拓国际市场,推动自动化产品规模化出海,提升中国自动化产品国际影响力,实现双方互利共赢。 合作基础稳固,战略升级水到渠成 汇川技术深耕工业自动化领域多年,以“工控+工艺”整体解决方案为核心,凭借深厚的技术积淀成长为中国工控行业龙头,产品与服务广泛覆盖汽车、锂电、光伏等多个关键行业。TE作为拥有八十余年技术沉淀的全球技术领先企业,其广泛的连接和传感解决方案持续助力全球工厂自动化与智能化发展。 在此之前,双方合作基础已然稳固:TE创新解决方案已成功应用于汇川MSG系列伺服电机等产品,汇川PLC、伺服、机器人也批量入驻TE工厂,“双向供应商”的合作基础,为此次战略升级筑牢根基。 此次战略合作的达成,不仅开启了汇川技术与TE的战略合作新征程,更树立了“双向供应商+协同创新”的行业新合作模式。未来,双方将以技术创新为内核、本土布局为根基、全球视野为导向,持续释放合作价值,共推工业 “智” 造高质量发展!
TE
泰科电子 TE Connectivity . 2026-02-02 3052
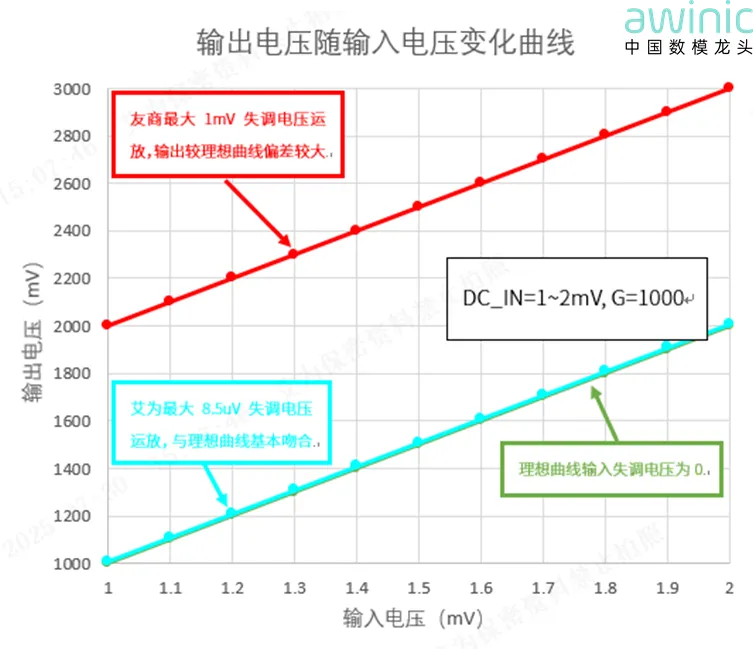
产品 | 艾为推出双通道零漂移运算放大器AWS796X2系列产品
近年来,随着储能产业兴起,精密电源的市场需求越来越高,运放作为电流检测的重要器件,对精度、响应时间、工作电压阈、带宽及压摆率等指标提出了更高标准,为响应市场需求,艾为推出双通道零漂移运算放大器AWS796X2系列产品。 AWS796X2系列超高精度低噪声CMOS运算放大器包括AWS79632和AWS79652两个系列产品,拥有超低输入失调电压、低电压工作、轨到轨输入和输出、出色的带宽和压摆率以及超低失真度的优异性能。该运算放大器的单位增益稳定,并具有超低的输入偏置电流,非常适合高精度信号采样、传感器等应用。 精密电源、模组在小电流模式下,采样电阻反馈信号微弱(1mA=68uV,R=68mΩ), 要求采样运放精度高,温漂小。 产品优势:超低输入失调电压 输入失调电压 VOS是为了让运放的输出为零,需要额外在输入端补偿的电压值,VOS大小影响整个系统输出的精度与误差,AWS796X2输入失调电压最大值8.5uV,非常适合高精度应用。 图1 输出电压随输入电压变化曲线 产品优势:超低等效输入噪声 等效输入噪声又称为1/f噪声,噪声是一种非周期性信号,无法校准,因此,对于需要高精度的应用,需要考虑噪声。1/f噪声是低频下的主要噪声因素,在电路增益较大情况下会导致显著的输出电压偏移, 由于AWS796X2斩波器架构,可以抑制1/f噪声,因此,该芯片成为直流高精度应用的理想选择。在噪声0.1-10 Hz时间内,0.1 Hz至10 Hz放大器电压噪声仅为250 nVpp@VCC=5V,下图可以AWS796X2用作ADC数据采集时输出值比较稳定。 图2 AWS796X2用作ADC数据采集时输出值比较稳定 主要功能特性 宽工作电压范围:1.8V~5.5V 低输入失调电压:8.5uV(最大值) dVOS/dT:0.03μV/℃@typ 压摆率:AWS79632:2.5V/μS,AWS79652:5.5V/μs 低输入偏置电流:1pA 轨到轨输入和输出 低输入噪声密度:AWS79632:13.5nV/√Hz,AWS79652:12nV/√Hz 低静态电流:AWS79632:600μA per channel,AWS79652:1100μA per channel 增益带宽积:AWS79632:4MHz,AWS79652:6MHz 灌电流和源电流能力:AWS79632:±65mA,AWS79652:±87mA 艾为信号链产品线运算放大器系列经过不断技术升级和架构创新,已形成性能优异系列化丰富的产品,涵盖通用运放、高精度运放、低功耗运放、高压比较器、高速比较器等。
艾为
艾为官网 . 2026-02-02 742

市场周讯 | 英伟达、微软、亚马逊就向OpenAI投资高达600亿美元开展谈判;阿里自研AI芯片”真武“亮相;ASML裁员约1700人
| 政策速览 1. 工信部:工信部发布数据,2025年,信息技术服务收入106366亿元,同比增长14.7%,占全行业收入的68.7%。其中,云计算、大数据服务共实现收入16230亿元,同比增长13.6%,占信息技术服务收入的15.3%;集成电路设计收入4421亿元,同比增长18.9%;电子商务平台技术服务收入14855亿元,同比增长12.7%。 2. 深圳:深圳市市场监督管理局等五部门印发《深圳市优化消费环境三年行动计划(2026—2028年)》。其中提出,大力促进家居消费。完善智能家居产业发展生态,打造智能家居消费体验中心,构建“大家居”生态体系。鼓励智能家居企业加快适配国产操作系统和芯片,推动家具、电视、影音娱乐、门锁、厨具、照明、扫地机器人、健身器材等全面接入AI,打造智能家居“拳头产品”。大力促进家装消费品“焕新”,开展家居消费季、家纺消费节、家装消费节等促消费活动,鼓励旧房装修、局部改造和居家适老化改造。推动“开源鸿蒙+全屋智能”深度融合,建设智能家居展示区,打造以人为本的智慧生活空间。 | 市场动态 3. 市场:近期半导体全产业链涨价潮全面深化,存储、模拟、MCU、封测等环节集体提价,可考虑“长单锁定+阶梯备货”策略,重点保障AI、汽车电子领域供应链稳定,同时通过多品牌组合分散单一厂商涨价风险。 4. AI:今年全球AI服务器出货量同比增长28.3%,整体服务器出货量增12.8%;ASIC架构AI服务器出货占比将逼近28%,GPU架构则降至70%。 5. 洛图科技:2025年全球XR设备的出货量为608万台,同比下降16.8%;AR眼镜的出货量为106万台,同比上涨35.9%;全球智能眼镜(包含AR眼镜)市场的出货量为681万台,同比大涨156%;关键推动力量来自Meta与雷朋(Ray-Ban)的联名可拍摄智能眼镜。 6. 笔记本电脑:预估1Q26全球笔电出货季减14.8%,2Q26有望温和季增;存储器、CPU、PCB、电池、电源管理IC等零部件同步涨价,笔电成本压力扩大;考虑供给端瓶颈与品牌策略未明,将下修2026年全年笔电出货为年减9.4%。 | 上游厂商动态 7. Broadcom:服务器配件、AI相关产品持续溢价,常规物料价格倒挂。 8. Onsemi:作为安世替代后,二极管、MOSFET等现货持续趋紧,面临上涨压力。 9. Infineon:功率MOSFET(IPW/IPB/IKW系列)、IGBT等汽车与工业功率器件供应紧 10. Samsung:Q1 NAND价格上调100%,涨幅超市场预期,反映内存市场供需失衡。 11. 天数智芯:发布四代芯片架构路线图,目标2027年超越英伟达Rubin架构;推出“彤央”边端算力产品,性能超英伟达AGX Orin。 12. 沐曦: 沐曦股份发布曦索X系列科学智能旗舰GPU。沐曦股份联合创始人、CTO兼首席硬件架构师彭莉表示,这将赋能AI4S(AI for Science)创新生态。 13. 中微半导: MCU、NOR Flash等涨价15%-50%,后续价格将随成本波动跟进调整。 14. 富满电子: LED产品本月19日涨价10%起。 15. 英集芯:上调部分芯片产品价格,新订单按调整后价格执行。 16. 寒武纪:预计2025年归属于上市公司股东的净利润为18.50亿元至21.50亿元,同比扭亏为盈。报告期内,受益于人工智能行业算力需求的持续攀升,公司凭借产品的优异竞争力持续拓展市场,积极推动人工智能应用场景落地,本期营业收入较上年同期大幅增长,进而带动公司整体经营业绩提升,净利润实现扭亏为盈。Q3净利润5.67亿,据此计算,Q4净利润预计2.45亿-5.45亿,环比变动-56%至-3%。第四季度净利润分析师一致预测是6.13亿,Q4业绩低于预期。 17. ST:意法半导体公布2025年第四季度及全年财报。2025年第四季度净营收为33.3亿美元,同比增长0.2%;毛利率为35.2%;营业利润1.25亿美元,净亏损3000万美元。2025年全年营收118亿美元,下降11.1%;毛利率33.9%;营业利润1.75亿美元,净利润1.66亿美元。公司预计2026年第一季度净营收为30.4亿美元,环比降低8.7%,上下浮动350个基点;毛利率为33.7%,上下浮动200个基点。 18. 存储:美光、SK海力士和三星电子三大内存芯片制造商已加强对客户订单的审查,防止蓄意囤积库存。这三家公司要求客户披露最终客户和订单量,以确保需求真实可靠,并防止超额预订或过度囤货,以免进一步扰乱市场。 19. 新紫光:作为今年天津市重点建设项目,新紫光新计算架构项目传来关键进展——第一代芯片已投入紧锣密鼓生产中,设计数据已分批次交付下游生产商投片生产。 20. 美芯晟:美芯晟 宣布,拟使用自有资金按照投前估值 12,500 万元收购上海鑫雁微电子股份有限公司(以下简称“标的公司”或“鑫雁微”)现有全部 1,000 万元注册资本,并以同等投前估值增资3,500 万元认购标的公司新增 280 万元注册资本,交易完成后合计取得标的公司100%股权,本次交易金额合计为人民币 16,000 万元。 21. 极海:纳思达公告披露,旗下核心芯片平台极海中国拟通过间接全资附属公司,以总计1.68亿港元(约合1.5亿元人民币)收购香港上市公司美佳音控股50.56%股权,交易完成后将成为其绝对控股股东。 22. 台积电:台积电计划到 2028 年将 Fab14 工厂的 12 英寸成熟制程产能削减 15%-20%。 23. 乐鑫:乐鑫科技正式推出业内首个运行于 RTOS 的 MCU 级 Matter 摄像头解决方案。该方案基于 ,助力品牌商与开发者打造可在 Matter 生态中无缝互通的智能家居摄像头产品。 24. 紫光国微:紫光国微表示,公司的存储产品主要应用于特种领域,受限于客户端的压力,短期内难以调整存储芯片价格。针对存储芯片价格的波动,公司持续的通过优化产品结构、提升运营效率、拓展应用场景等方式积极应对客户需求波动,并结合特种领域的技术要求与市场动态,制定适宜的产品定价策略。 25. 三星:三星电子表示,将专注于高带宽内存(HBM)市场的高端领域。目前正处于完成HBM4认证程序的阶段,计划2月投产。高带宽内存(HBM)订单今年已全部订满,预计2026年高带宽内存(HBM)营收将增长逾三倍。 26. 台积电:台积电未来2年将全面拉升CoWoS产能。除了英伟达已成最大客户,谷歌等ASIC芯片客户也频释急单抢产能,台积电近期已拍板全面上调2026~2027年CoWoS产能目标,重新检视原有的先进封装扩产蓝图。据供应链透露,台积电南科AP8厂区将再新增P2厂,2座厂均以CoWoS为主,而原以WMCM、SoIC及CoPoS为主的嘉义AP7,SoIC改为CoWoS。 27. ASML:荷兰芯片设备制造商阿斯麦控股公司(ASML Holding NV)首席执行官克里斯托夫·富凯在一份声明中表示,公司计划裁员约1700人,裁员主要集中在技术部门与信息技术部门。此次裁员对象主要位于荷兰,部分在美国,且主要涉及管理层,裁员人数约占公司员工总数的4%。 28. 曦望:发布新一代推理GPU芯片启望S3,并同步发布了面向大模型推理的寰望 SC3-256 超节点方案,可适配千亿、万亿级参数的多模态 MoE 推理场景。此外,曦望还联合商汤科技、第四范式等生态伙伴,共同发起“百万Token 一分钱”推理成本计划。曦望与浙江大学签署战略合作协议,联合成立“智能计算联合研发中心”。曦望前身是商汤科技大芯片部门,不久前宣布在一年内完成了近30亿元战略融资。 | 应用端动态 29. OpenAI:OpenAI正从其部分大型科技合作伙伴处筹集巨额资金,因其寻求筹集高达1000亿美元资金,以满足其人工智能业务不断增长的需求。英伟达、亚马逊与微软正在商讨向OpenAI投资高达600亿美元。英伟达作为现有投资者,其芯片为OpenAI的人工智能模型提供算力支持,目前正就投资高达300亿美元事宜进行谈判。 30. 苹果:为分散供应链风险,苹果计划2028年与英特尔重启合作,由其代工小部分iPhone A22芯片,台积电仍为芯片代工主力。 31. 小鹏:小鹏与大众合作CEA电子电气架构落地,首搭车型与众07正式下线,该架构使ECU数量减少约 30%,显著降低系统复杂度。 32. 阿里:阿里自研真武810E高端AI芯片上线平头哥官网,历经17年战略投入,“通云哥”黄金三角正式亮相。 33. 欧盟:欧盟启动卫星通信计划,汇集27个欧盟成员国,据称是欧洲天基通信实现本土供应的第一步。 34. 机器人:北京“具身天工”人形机器人实现全球首次直连卫星,小米手机在其中扮演“信号中继站”角色,助攻其稳定连接。
半导体
芯查查资讯 . 2026-02-02 3 3 3136

新品推荐 | 峰岹科技第2代ME+32位RISC-V双核MCU产品FU75xx系列
峰岹科技在2025年11月底推出了基于其第2代ME内核和32位RISC-V内核的双核架构电机驱动专用MCU产品FU75xx系列。该系列MCU不仅融合了高性能计算与实时控制能力,还通过ME内核解决了复杂应用场景中的诸多挑战。可应用于工业伺服驱动器、机器人关节、智能家电、新能源汽车等多种电机控制应用场景。 F U 75xx主要特性 FU75xx具有双核架构,其中ME内核是峰岹科技自主研发的电机控制引擎,第2代ME内核集成了专用、灵活的算法模块,用户可以直接调用,或自主软件替换,效率远超纯软件实现。相比第1代ME性能显著提升,功能模块增加了100%。 图片来源:峰岹科技,下同另一个RISC-V内核则主要用来处理系统通信、应用逻辑,以及用户界面等功能。 核心参数亮点:32位RISC-V双核(含ME电机控制内核),支持双电机驱动; 高精度配置:24M/48M高精度振荡器、3个12bit 1MSPS ADC,控制更精准; 丰富接口:集成CAN2.0/CANFD协议、2个SPI/2个UART,支持LIN2.X通信,可全面实现EtherCAT、CANopen、Modbus等主流工业总线协议; 多种接口支持:集成了Biss-C、串行编码器接口,结合强大的Timer模块,可灵活支持增量式编码器、多摩川绝对式编码器、Biss-C编码器。支持多种脉冲输入指令、支持编码器模拟输出。同时具备探针输入、比较输出功能接口。可支持机器人和工业伺服应用; 进阶功能:电机控制环路硬件化、振动抑制模块、运行中载波扫频(提升EMC性能),优化PFC与弱磁控制算法; 全面故障保护:支持多种故障保护功能,例如过流保护、堵转保护、缺相保护、过欠压保护、速度过超保护、速度超差保护、电流基准异常保护等。 强大的控制算法:增加了磁链观测器、优化PLL(SMO、AO保留),优化低速启动算法;优化PFC(双桥最高6kW);升级高频注入方案;升级弱磁控制算法;单电阻采样方案优化(用于优化单电阻低速噪音,单电阻方案噪音基本可以做到与双电阻一致);支持运行中载波扫频(提升过EMC的性能)。 图:FU75xx系列芯片型号及应用场景 主要应用场景 峰岹科技FU75xx系列有多种型号可以选择,包括FU7512L、FU7512P、FU7512Q1、FU7541Q、FU7561Q、FU7562L、FU7562Q、FU7564Q1等,不同型号有不同的使用场景,主要可以应用于工业与机器人、汽车电子和消费电子等场景。具体为: 工业与机器人:单编/双编机器人关节模组、并联机器人、灵巧手、ZR轴电机、伺服一体机等。 汽车电子:天窗、遮阳帘、车窗、雨刮、座椅通风、座椅滑轨、旋转屏、吸顶屏、电子扇、水泵、油泵、热泵、压缩机等。 消费电子:洗衣机、干衣机、空调、冰箱、吸尘器、散热风扇等。
峰岹科技
芯查查资讯 . 2026-02-02 4760
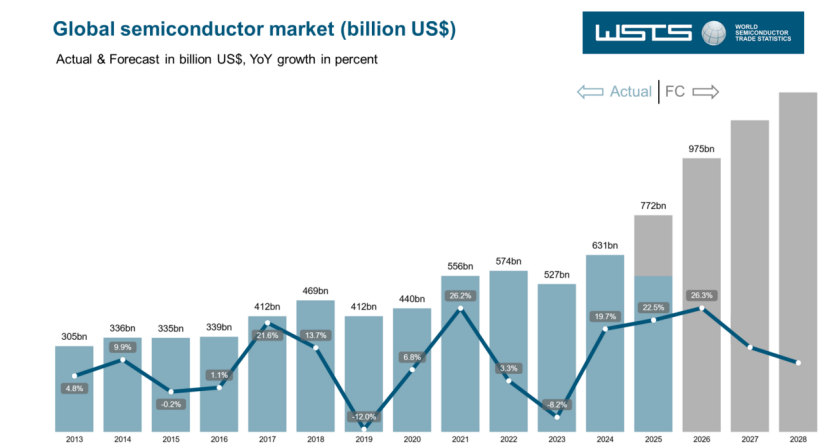
年终采访 | 半导体市场冲刺万亿美元规模,中国力量不可或缺
重点内容速览: 1. 2025年半导体市场的关键词:智能化、国产化与理性增长 2. 2025年成绩斐然:产品突破与市场扩张 3. 2026年增长核心:端侧AI、机器人和绿色能源 全球半导体行业在经历了前两年的周期性低谷后,2025年迎来了强劲复苏。根据世界半导体贸易组织(WSTS)的最新数据,2025年全球半导体市场规模预计将增长22%达到7720亿美元,并有希望在2026年冲刺1万亿美元规模。这一增长主要得益于人工智能、高性能计算、汽车电子和工业数字化的强劲需求推动。库存压力明显放缓,产业链运行回归理性,但地缘政治、供应链重构和人才短缺仍然构成挑战。 图:WSTS对全球半导体市场规模的统计与预测(来源:WSTS) 回顾2025年,在周期波动的背景下,半导体行业正逐步显现出由应用结构、技术路径和供应链安全驱动的结构性发展特征。 这一转变不仅体现在市场规模的扩张上,还反映在技术创新和生态构建的深化。德勤报告指出,芯片销售在生成式AI和数据中心建设的拉动下飙升,而PC和移动市场需求相对平淡。麦肯锡分析显示,半导体市场实际规模可能被低估,2025年已接近7750亿美元,并预计到2030年达到1.6万亿美元。 在这一背景下,芯查查采访了国内5家具有代表性的半导体公司高管,他们的观点为我们提供了宝贵的行业洞见。这些公司涵盖模拟芯片、存储、MCU等领域,代表了中国半导体企业的崛起和韧性。 2025年半导体市场的关键词:智能化、国产化与理性增长 如果用3个关键词概括2025年的半导体市场,受访者们有一定的共识,同时又各有侧重,这反映了半导体行业的多维动态发展。 纳芯微副总裁姚迪在交流中提到,应用需求、技术路径和供应链环境等因素正在共同影响半导体行业节奏,企业需要不断提升战略判断力和长期投入能力。 图: 纳芯微副总裁姚迪 匠芯创HMI市场总监陈钧选择“工业智能化”、“国产化加速”和“生态融合”。他的解释是,“工业4.0、机器人、智能装备等领域的芯片需求持续释放,推动半导体向高可靠、低功耗、高实时性方向发展。在供应链安全与自主可控的背景下,国内企业在工控、车载、能源等关键领域的芯片自主化进程显著加快。同时,AIoT、边缘计算、智能显示等场景催生芯片架构与集成能力的创新,竞争从单一产品转向‘芯片+系统+算法+方案’的全栈比拼。“ 图:匠芯创HMI市场总监陈钧 东芯半导体副总经理潘惠忠从存储芯片视角出发,突出“AI技术浪潮”、“市场需求变化”和“产业链自主化”。他表示,存储行业逐步向好,受AI浪潮驱动,市场供求关系变化和国产替代需求巨大。 图:东芯半导体副总经理潘惠忠 武汉芯源半导体总经理助理&营销副总经理陈巧则选用“边缘智能化”、“国产深化”和“增长理性化”。她指出:“AI计算从云端下沉至终端设备的结构性转变,国内半导体国产化进程迈向更深层次,产业从‘规模竞赛’转向‘精准布局’。” 图:武汉芯源半导体总经理助理&营销副总经理陈巧 艾为电子营销总监谭文广的观点则聚焦“AI算力”、“存储超级周期”和“产业链重构”。他认为,AI算力驱动定义了2025年市场的增长逻辑,存储超级周期重构了行业盈利格局,产业链重构奠定了未来竞争框架。 图: 艾为电子营销总监谭文广 从2025年半导体行业市场的发展情况,以及这些受访公司的总结来看,2025年半导体增长的核心脉络为,AI是增长引擎,国产化加速应对地缘风险,理性化调整确保可持续性。另外,根据KPMG全球半导体展望报告,AI首次成为推动半导体营收的最重要应用,云/数据中心升至第二位。 2025年成绩斐然:产品突破与市场扩张 市场的增长离不开行业内企业的贡献,受访的几家企业在2025年均取得了不错的成绩,这体现了国内半导体企业的韧性和创新能力。 例如纳芯微在汽车与泛能源领域推出了多款重磅产品,包括车规级SerDes芯片组、AK2超声波雷达套片、基于AMR技术的轮速传感器、四通道数字输入D类音频功率放大器,以及车规级SBC系统基础芯片等。姚迪对芯查查表示,这些产品部分已经获得了全球头部客户定点,NSSine实时控制MCU系列在光伏、储能、新能源汽车车载充电机、工业电机驱动应用中实现了量产突破,标志着纳芯微具备了在复杂系统中交付高可靠产品的能力。此外,纳芯微在2025年12月成功在香港联交所主板挂牌,构建“A+H”双资本平台,加快全球布局。 匠芯创在2025年取得了不少新的突破,在产品方面,其新一代工业级高性能DSP实时处理器M7000系列已经在国内近50家上市公司与知名企业规模化应用,公司核心SoC芯片年出货量均突破100万颗;方案方面,可针对垂直场景定制“芯片-系统-算法”一体化方案,解决通用芯片性能瓶颈;工具链与生态方面,提供从开发框架(Luban、Luban-lite、Luban-mini等SDK)、UI图形设计工具UIBuilder到点调屏工具的全栈工具链,降低开发门槛;开源协调方面,匠芯创通过建立和支持开源社区(例如围绕RISC-V、Linux、RT-Thread),汇聚生态力量,加速创新。 东芯半导体作为存储芯片供应商,坚持深耕NAND Flash、NOR Flash、DRAM。潘惠忠提到,“1xnm闪存产品研发及产业化项目”实现量产,2xnm制程优化可靠性;NOR Flash推进48nm、55nm中高容量产品;DRAM拓宽产品线;MCP提供多种组合,满足多样需求。公司在车规级存储上推进AEC-Q100验证,向Tier1供应商销售。 武汉芯源半导体的陈巧表示,现阶段我们更多关注消费电子和电机这两个领域,主推的明星产品CW32L010在消费电子领域已经获得了大量的订单,2025年累计出货量已经达到了1.4亿颗。而电机领域,我们有新推出的CW32L012去导入。 艾为电子随着管理优化和产品升级,归母净利润2.76亿元,同比增长54.89%,毛利率升至35.72%。他们优化产品结构,向工业互联、汽车电子渗透,推出高压压电微泵液冷驱动芯片、车规级音频功放等,与Meta、Google、Amazon、Samsung等建立深度合作。研发投入4.27亿元,占营收19.62%,COT工艺实现突破。 这些成绩并非一帆风顺。挑战包括上游原材料价格波动、研发复杂度加大、市场不确定性增多等。但各家企业根据自身的特点都取得了不错的成绩。匠芯创应对通过深耕RISC-V和战略合作;东芯半导体坚持“本土深度、全球广度”供应链;武汉芯源半导体加强生态建设和合规审查;艾为通过平台化布局和全球研发中心增强韧性;纳芯微坚持长期价值,夯实技术能力。 同时,芯查查也发现受访企业普遍向高价值场景延伸。例如纳芯微聚焦汽车电子和泛能源,在汽车领域,纳芯微的产品已覆盖新能源车主驱逆变器、车载充电机、电池管理与热管理等关键系统,并持续向车身电子、车载照明、智能座舱、底盘控制及安全系统等领域延展 。在泛能源覆盖新能源发电、输配电,构建隔离、电源管理、传感与实时控制布局。对于具身智能,提出“泛机器人”概念,进行技术储备。 匠芯创业务向“显示+控制+AI感知”融合深化,在RISC-V打造闭环生态,聚焦多模态HMI、RISC-V工业应用(PLC、运动控制)和新能源(逆变、数字电源)。这些市场呈现稳健增长,工业控制与机器人需求提升,车载智能座舱渗透加快。东芯半导体主要关注汽车、物联网、AI与边缘计算。在车规级存储构建高附加值矩阵,多料号通过AEC-Q100验证。子公司推进Wi-Fi7芯片,战略投资上海砺算布局高性能GPU。 武汉芯源半导体在工业控制、智能表计、消费电子等优势领域继续做深做透。例如,在智能水表/燃气表/电表、电动工具、电机控制(BLDC)、温控器、BMS(电池管理系统)等工业与表计细分领域,客户的核心诉求是高可靠性(十年以上稳定运行)、强抗干扰(EFT/ESD)、超低功耗、高性价比;在小家电、个护健康(电动牙刷、美容仪、雾化器)、智能照明等消费电子与智能家居细分领域,客户的核心诉求是低功耗(电池续航)、丰富外设接口、快速上市、成本敏感。通过市场调研分析这些应用的实际需求,设计出更适合这些客户应用的产品。 艾为关注工业自动化、汽车电动化、端侧AI。车规级芯片量产,应用于智能座舱;推出高压多路半桥马达驱动;布局MCU+NPU等端侧AI芯片。海外收入显著增长,成为营收支柱。 2026年增长核心:端侧AI、机器人绿色能源 展望2026年,受访者认为增长的核心将围绕端侧AI、机器人、智慧出行、工业数字化和绿色能源展开。 陈钧表示:“芯片将更强调‘场景融合’与‘系统级效能’,高算力、低功耗、高集成度SoC成焦点。” 潘惠忠期待深化“差异化+国产替代”,突破技术瓶颈,拥抱AI需求。 陈巧认为半导体增长核心在汽车电子,国内终端在消费电子;根据各方面预测来看2026年整个MCU市场有望超500亿元,通用MCU占比最大。 谭文广指出AI从云端扩散至边缘,模拟芯片复苏源于汽车、工业、AI基础设施;先进制程与封装并行突破。 姚迪强调坚持长期价值,围绕核心赛道夯实能力,为客户创造可持续价值。 WSTS预测2026年市场达9750亿美元,增长25%以上;PwC预计CAGR 8.6%,2030年超1万亿美元。麦肯锡中位情景为1.6万亿美元。增长结构性,集中于高性能计算、高端存储、模拟芯片。设备市场SEM I预计达1380亿美元,WFE增长10%。 当然,挑战也依然不少,包括AI泡沫、经济不确定性、产能瓶颈、供应链安全、区域重构等因素。 结语:拥抱变革迈向万亿时代 2025年是半导体行业修复与调整的关键一年,2026年将是新一轮竞争与分化的起点。AI将继续主导,端侧渗透加速;国产化深化,生态融合成趋势。基于采访和数据,芯查查对2026年持乐观展望:市场接近1万亿美元,增长25-30%,这其中中国力量不可或缺。 芯查查将会深入剖析榜单背后的五大核心趋势,带您一同探寻驱动行业变革的深层逻辑,洞见2026年的机遇与挑战。
半导体
芯查查 . 2026-02-02 6 6804

泰矽微TClux系列:专用驱动芯片如何引领汽车动态氛围灯高性价比未来
随着汽车向移动智能终端演进,车内座舱体验成为竞争焦点。动态流水氛围灯作为提升科技感与个性化体验的关键配置,正从中高端车型快速渗透至更广泛的车型市场。在这一趋势下,如何在强化视觉交互的同时控制成本,成为产业链共同面对的核心课题。泰矽微电子推出的TClux系列多通道LED驱动芯片,凭借“专用驱动芯片+普通LED灯珠”架构,为行业提供了高性能、高灵活性与显著降本的优选方案。 图1 动态流水氛围灯效果图 一、动态氛围灯发展趋势驱动芯片升级 当前,汽车氛围灯正向“场景化联动、个性化定制、集成化设计”三大方向发展: l 场景化联动:氛围灯不再只是装饰,而是与导航、音乐、驾驶模式、安全提示等深度联动,这对控制的实时性、精度与多通道协同提出了更高要求。 l 个性化定制:超70%的消费者愿为灯光定制付费,已从基础调色延伸到光效编程与轨迹自定义,要求芯片支持高度灵活的参数配置。 l 集成化与成本控制:随着灯光覆盖区域扩展至门板、中控、座椅乃至顶棚,如何在有限空间和预算内实现更丰富的灯光效果,成为系统设计的重要挑战。 在此背景下,芯片方案的选择直接决定了整套灯光系统的性能天花板、成本结构与开发效率。 二、为什么专用驱动芯片方案更具优势? 与集成化的Smart LED方案相比,“专用驱动芯片+普通LED灯珠”架构在多个维度展现出明显优势: 泰矽微TClux系列正是在专用驱动芯片架构上进一步整合与优化,实现了“一芯多驱、高集成、强性能、低成本”的全面突破。 三、泰矽微TClux系列:高集成、高性能的驱动芯片方案 (一)高度集成的单芯片架构 TClux系列创新性地将MCU内核、Flash存储器、LIN/CAN收发器、同步整流Buck控制器、多通道恒流驱动模块 等关键功能集成于单颗芯片中,形成真正意义上的“主控+驱动+通信”一体化解决方案。一颗芯片即可驱动多达48路RGB LED,极大简化了外围电路设计,降低BOM成本与PCB布局难度。 图2 泰矽微TClux系列芯片架构 (二)核心优势:成本、性能与安全的平衡 (1)显著降本 l TClux通过“一芯多驱”架构,大幅降低单灯珠驱动成本。在48路氛围灯方案中,相较Smart LED可节省40元以上系统成本,其“一替多”特性也减少了芯片使用数量,进一步优化整体成本。 (2)高性能输出 l 搭载72MHz Cortex-M0内核,支持高刷新率控制,确保动态效果流畅同步。 l 电流调节精度高,可实现256色以上细腻平滑的色彩渐变。 l 内置高精度温度检测电路,实时补偿RGB色彩,避免因温升导致的光色偏差。 (3)低功耗与高可靠性 l 采用主动式降功耗技术与高效电源架构,芯片功耗较同类产品降低50%以上,温升控制出色,可靠性更高。 l 通过AEC-Q100 Grade 1认证,具备完善的诊断功能和Limp Home模式。芯片可实时检测LED开路、短路、过温等故障,并及时反馈给主控系统,确保在故障情况下灯光系统仍能维持基础照明功能,符合ASIL B功能安全要求。 四、TClux系列赋能未来氛围灯智能化发展 随着Mini LED、柔性LED等新技术落地,以及智能座舱对交互体验要求的提升,专用驱动芯片将持续向更高集成、更强驱动、更智能控制演进。泰矽微TClux系列不仅满足当前高性价比需求,更具备与AI算法、传感器深度融合的潜力,支持车企实现: l 场景化光效的深度可编程 l 多系统联动与控制优化 l 全车灯光智能管理与交互升级 五、专用驱动芯片是未来主流,泰矽微TClux系列引领性价比革新 在汽车动态氛围灯持续向“场景联动、个性定制、集成降本”演进的大趋势下,专用驱动芯片方案凭借其卓越的性能扩展性、显著的降本空间和高度的软硬件灵活性,已成为行业主流选择。 图3 TClux系列芯片的具体型号及基本参数参照表 泰矽微TClux系列通过“高集成、多通道、低功耗、车规安全”的综合产品力,不仅在成本上超越Smart LED方案,也在同类驱动芯片中展现出更强的系统整合能力和性价比竞争力。未来,泰矽微将持续与整车厂及产业链伙伴协同创新,共同推动车内氛围灯向更智能、更沉浸、更高性价比的未来持续演进。
泰矽微 . 2026-02-02 1442

合科泰工业级MOSFET的关键参数解读与选型陷阱
前言 在工业电源、电机驱动及照明等应用中,功率MOSFET的选型直接影响系统的效率、温升与长期可靠性。一个常见的误区是仅依据单一参数进行选择,而忽略了参数间的相互制约及其在实际工作条件下的变化。合科泰旨在分析Vds、Rds(on)、栅极电荷Qg及安全工作区SOA等关键参数在工业应用中的综合影响,并提供系统的选型考量要点。 关键参数的综合影响分析 功率MOSFET的参数并非独立,需在具体应用背景下权衡。 1. 耐压Vds与动态性能的权衡 较高的Vds额定值提供了电压应力余量,但通常伴随着更大的寄生电容和栅极电荷Qg,这会导致开关损耗增加。例如,在一个300VDC母线电压的PFC电路中,选择如合科泰HKTD4N50的500V器件,通常已满足1.6倍安全裕量的要求。若为“保险”而选用650V或更高耐压器件,其增加的Qg可能会在不必要地降低系统效率。 2. 导通电阻Rds(on)的温度系数与实效损耗 数据手册中标称的Rds(on)通常是在结温等于25℃下测得。在工业应用中,器件实际结温可能持续运行在100℃以上。此时,Rds(on)会显著增加,这意味着在150℃结温时,导通损耗可能比基于25℃参数的计算值高出约80%。因此,评估损耗时必须使用实际工作结温下的Rds(on)值。合科泰在其产品数据手册中提供了典型的高温Rds(on)曲线,有助于进行更准确的热设计和损耗计算。 3. 栅极电荷Qg对开关损耗与驱动设计的影响 开关损耗与开关频率及总栅极电荷Qg成正比。对于如大于100kHz的开关电源高频应用,选择低Qg器件至关重要。然而,低Qg器件通常要求驱动源具备更低的输出阻抗和更强的瞬态电流能力,以维持快速的开关边沿。例如,驱动Qg=20nC的MOSFET在200kHz频率下,栅极驱动器的峰值电流能力建议不低于40mA。 4. 安全工作区SOA与瞬态应力 SOA定义了器件在特定脉冲宽度内能够安全承受的电流与电压组合。在存在浪涌电流的应用中,如电机启动、电容充电等,必须确保瞬态工作点落在SOA曲线以内。例如,合科泰HKTD5N50在10ms脉冲宽度下,于200V漏源电压时可承受约15A电流。设计时应检查启动或故障条件下的最大I-V轨迹,并留有足够裕量。 典型工业应用场景的设计要点 1. 工业开关电源 在PFC或LLC拓扑中,需同时优化导通损耗与开关损耗。 PFC级:重点关注Vds电压裕量及高温下的Rds(on)。可计算在最高工作结温下的导通损耗。 LLC谐振级:由于工作于软开关条件,开关损耗降低,但Qg影响仍然存在,因其关系到谐振腔能量的建立与传递速度。需选择Coss及Qg特性与谐振参数匹配的器件。 2. LED工业照明驱动 恒流驱动、长期连续工作及可能的高环境温度是主要特点。设计的核心是热管理。需根据热阻RθJA和总损耗准确估算结温Tj,确保其在最大允许值以下。合科泰针对此类应用提供了从SOT-23封装的AO3400到SOP-8封装的50N03等多款产品,其数据手册包含详细的热参数。 3. 电机驱动 电机驱动需承受高启动电流。选型时,除持续电流下的Rds(on)外,必须复核短时脉冲SOA能否覆盖启动或堵转电流。此外,桥式拓扑中体二极管的反向恢复特性也影响换流损耗与可靠性。 总结 工业级功率MOSFET的可靠选型,需基于系统工作条件,对关键参数进行综合考量。电压选型中在足够安全裕量与开关性能之间取得平衡,避免过度裕量;损耗计算必须计入高温对Rds(on)的影响,并准确估算开关损耗;动态性能需要根据开关频率评估Qg的影响,并设计与之匹配的驱动电路;针对应用中可能出现的浪涌,核查SOA曲线以确保瞬态应力在安全范围内。在实际工程中,建议通过双脉冲测试等平台验证器件的开关特性与损耗,并结合供应商提供的完整数据手册进行最终定案,如合科泰提供的包含高温参数与SOA曲线的文档。
MOSFET
厂商投稿 . 2026-02-02 1 1708

车规级合金电阻的技术优势与汽车电流采样设计指南
引言 在新能源汽车BMS、电机驱动等关键系统中,电流采样的精度与长期可靠性直接影响电池安全管理、扭矩控制精度及系统效率。此类应用对采样电阻提出了严苛要求:在宽温范围(-40℃至150℃)内保持极低的阻值漂移,耐受高脉冲电流与恶劣化学环境,并具备优异的长期稳定性。基于镍铬铜锰等材料的合金电阻,因其固有的低温度系数(TCR)和稳定的薄膜结构,成为应对这些挑战的优先选择。 一、车规级合金电阻的核心技术特性分析 与常规厚膜电阻相比,合金电阻在以下关键参数上为汽车应用提供了优化解决方案。 1. 低温度系数(TCR)与宽温区稳定性 电流采样误差的一个重要来源是电阻值随温度的变化。传统厚膜电阻的TCR通常在±100至±500 ppm/℃范围内,在汽车电子的工作温度区间内,可能引起显著的阻值漂移。通过优化的合金材料配方与薄膜制备工艺(如磁控溅射),车规级合金电阻可将TCR控制在±50 ppm/℃以内,高性能型号可达±25 ppm/℃或更低。 例如,合科泰HKT-AR25系列合金电阻的TCR为±15 ppm/℃,这意味着在-40℃至150℃的全温区内,其理论最大阻值变化仅约0.285%,为高精度采样提供了基础。 2. 高功率密度与散热能力 在BMS主回路等大电流场合,采样电阻需在毫欧级阻值下耗散可观功率。合金电阻由于材料导电性好、热导率较高,加之优化的电极设计和封装散热路径,可在紧凑封装内实现更高的额定功率。例如,5931封装(合科泰HKT-AS59系列)的合金分流器额定功率可达9W以上,能够满足持续数百安培电流的采样需求。 选型时必须进行功率降额计算:在实际工作环境温度下,电阻的允许功耗需高于由P = I_rms² × R 计算的实际功耗,并留足裕量。 3. 抗硫化与高可靠性 汽车环境中存在的硫、氯等腐蚀性气体会与电阻的银质端电极发生反应,导致失效。车规级合金电阻通过采用贵金属合金端电极(如Ag-Pd)及施加保护涂层(如ALD氧化铝)来提升抗硫化能力。相关的可靠性测试(如85℃/85%RH, H2S环境测试)是确保其满足ISO 16750-5等汽车标准的关键。 此外,通过HTOL(高温工作寿命)测试可评估其长期稳定性。合科泰的车规合金电阻在70℃额定功率下1000小时测试的阻值漂移率可小于±0.05%,优于常规厚膜电阻。 二、电流采样电路设计要点 1. 电阻选型与参数计算 阻值选择:需在采样电压幅度(便于信号链处理)与功耗之间折中。通常采样压降控制在10mV至100mV之间。阻值 R ≈ V_sample / I_max。 精度与TCR:根据系统总体精度预算分配电阻的误差份额。注意标称精度(如±0.1%)通常指25℃下的初始精度,而实际运行误差主要由TCR和长期漂移决定。 封装与散热:大电流应用应优先考虑大面积封装(如2512、5931),并在PCB上设计足够的散热铜箔。合科泰HKT-AS59系列产品资料中提供了建议的焊盘和散热铜箔布局。 2. PCB布局与抗干扰设计 开尔文连接(四线制):对于毫欧级电阻,必须使用开尔文接法以消除采样点与电阻端子之间走线寄生电阻的影响。Sense走线应精细、对称且尽量短。 最小化采样回路面积:将电阻靠近采样放大器放置,并保持差分走线平行、紧邻,以降低磁场耦合干扰。 噪声滤波与屏蔽:在采样放大器输入端可配置RC低通滤波器(需注意不影响动态响应)。必要时对敏感采样线路进行包地或置于内层。 3. 温度漂移的软件补偿 为达到更高精度,可通过软件对电阻的温漂进行补偿。这需要: 获取精确的TCR数据:供应商应提供电阻在应用温度范围内的TCR特性曲线或数据点。例如,合科泰可为客户提供关键型号的详细TCR测试数据。 测量电阻温度:在电阻附近放置温度传感器(如NTC),或利用其自身TCR特性(若支持)进行间接温度估计。 建立补偿模型:在代码中实现基于温度的阻值修正算法:R_actual = R_25℃ × [1 + TCR × (T - 25)]。 三、选型验证与供应商考量 1. 关键验证测试 除常规电性能测试外,针对车规应用建议进行: 全温区精度测试:在-40℃、25℃、85℃、125℃等温度点测量阻值,验证TCR一致性。 脉冲负载能力测试:验证电阻在短时大电流(如电机启动电流)下的承受能力,确保工作点在其SOA内。 环境可靠性测试:依据AEC-Q200要求进行温度循环、高温高湿、耐硫化等测试,或审查供应商的完整测试报告。 2. 供应商评估要点 选择车规级电阻供应商时,应重点关注: 质量体系认证:是否通过IATF 16949认证,生产过程是否具备完整的可追溯性。 产品认证与数据完备性:电阻是否通过AEC-Q200认证,数据手册是否提供详尽的TCR曲线、功率降额曲线、长期稳定性数据等。 技术支持能力:能否提供针对应用的设计支持、失效分析及可靠的技术数据。合科泰电子基于其IATF16949体系及车规产品线,可提供相应的技术文档与支持。 总结 在汽车电流采样设计中,选用车规级合金电阻的核心优势在于其卓越的温漂特性与长期可靠性。有效的设计不仅需要精确计算阻值、功率等基本参数,更需通过优化的PCB布局(特别是开尔文连接)来保证采样准确性,并考虑结合软件温度补偿以进一步提升全温区精度。在选择供应商时,其质量体系、产品认证数据完备度及技术支持能力是与器件本身性能同等重要的考量因素。
电阻
厂商投稿 . 2026-02-02 1 1414

液位检测芯片在加湿器中的应用
加湿器能够调节环境湿度,有效缓解因空气干燥引起的皮肤干燥、喉咙不适等问题,守护家庭健康,不愧是品质家居的理想选择。那么,厦门晶尊微电子(ICman)液位检测芯片在加湿器中发挥着怎样的作用呢? 加湿器液位检测的难点问题 加湿器液位检测方案实施过程中可能遇到的问题: 1) 加湿器的水箱设计是不透明或者使用过程中没有注意到水量使用情况,可能遇到缺水干烧损耗零部件的问题。这就对液位检测芯片的检测精度和抗干扰能力要求比较高; 2) 加湿器所用的液位检测芯片长时间使用,加上受到电源或其他电子部件的电磁干扰,判断液位变化的准确度降低。这就对液位检测芯片的稳定性和一致性要求比较高。 可行的加湿器液位检测方案 ICman液位检测芯片能够很好地实现加湿器液位检测提醒方案,解决液位检测不准确不灵敏的问题,主要体现在: 技术指标: ESD接触式8KV 空间放电15KV,EFT为4KV,CS为动态 10V。 高性能: 1) ICman液位检测芯片基于双通道比较电容式液位检测原理,来判断容器中是否有液体或者液体是否达到一定高度,从而实现加湿器的液位提醒(缺水提醒),起到安全保护的作用,优化加湿器的性能和使用体验; 2) ICman液位检测芯片液位精度控制高,超强抗干扰,受环境影响小,实现更精细的水位控制,让使用过程更加安全可靠高效。 所以,在加湿器的液位检测中,ICman液位检测芯片可以很好地发挥液位检测优势。ICman液位检测芯片还广泛应用于工业控制、洗地机、扫地机器人、净水器等健康家电的液位检测中。 芯片型号 ICman液位检测芯片型号: SC01F和SC01B。 应用优势 ICman液位检测芯片实现的加湿器方案优势在于: 1) 按照工业级设计,有超强稳定性和抗干扰能力,安全耐用,可以适应复杂多变的环境; 2) 液位检测精度高达1mm,液体里面有杂质、污垢、沉淀物等不会影响检测结果,适用于不同液体,稳定性和可靠性好; 3) 体积小重量轻,安装方便,外围电路少,更容易实现集成化智能化液位检测功能,性价比高。 总之,在液位检测精度稳定性和抗干扰方面有着优秀表现的ICman液位检测芯片,可以有效地提升产品差异化和品牌附加值。 【END】
创新
原创 . 2026-02-02 1022

东芝开始提供面向大电流车载直流有刷电机桥式电路的栅极驱动IC
东芝电子元件及存储装置株式会社(“东芝”)今日宣布,开始提供适用于大电流车载直流有刷电机桥式电路的栅极驱动IC[1]——“TB9104FTG”。该器件适用于电动尾门、电动滑门和电动座椅等车身系统应用。 随着车辆可移动部件电气化进程的加速,车载电机尤其是车身系统应用的电机数量在持续增加。这一趋势进一步推动电机驱动IC需求的增加,也对高集成度和系统小型化提出了更高的要求。同时,为了满足汽车轻量化的要求,减少线束已成为必然选择。 TB9104FTG采用5.0mm×5.0mm(典型值)的小型VQFN32封装。封装底部的裸露散热焊盘可以有效提升散热性能,通过与外部MOSFET配合使用,可实现紧凑的驱动电路,适用于车身系统应用中的大电流直流有刷电机。 新产品具有串行外围设备接口(SPI)[2],可连接微控制器进行通信,支持多种配置选项及状态信息读取。值得注意的是,电机的旋转命令不仅可以通过专用引脚输入,还可以通过SPI发送。通过将多个栅极驱动IC连接到同一SPI总线,可以实现线束共用,从而减少线束数量。 TB9104FTG还集成了PWM驱动电路。该电路设计用于通过SPI连接的多设备环境,仅需微控制器发送一次旋转指令,即可根据预设的PWM驱动周期实现连续的电机运行。这有助于降低微控制器的负载并缓解SPI总线上的通信负荷。 作为一款面向大电流应用的器件,TB9104FTG通过集成高精度电流检测放大器来监测电机驱动电流,从而确保安全性。通过将放大器的输出反馈给微控制器,当出现异常电流时,可以执行精确的驱动停止控制。该产品还具有多种异常检测和驱动停止功能。 未来,东芝将继续扩充车载电机驱动IC的产品线,为车载设备的电气化及安全性的提高做出贡献。 应用: 汽车车身系统 用于驱动电动尾门、电动滑门、电动车窗和电动座椅等应用的大电流直流有刷电机 特性: 小尺寸、高散热性能的VQFN32封装 支持与微控制器通信的SPI接口 内置PWM驱动电路 多种异常检测功能 主要规格: 注: [1] 栅极驱动IC(Gate Driver):用于驱动MOSFET的驱动IC [2] 串行外围设备接口(SPI):一种用于发送和接收数据的同步串行通信协议。 如需了解有关新产品的更多信息,请访问以下网址: TB9104FTG https://toshiba-semicon-storage.com/cn/semiconductor/product/automotive-devices/detail.TB9104FTG.html 如需了解相关东芝车载直流有刷电机驱动IC的更多信息,请访问以下网址: 车载直流有刷电机驱动IC https://toshiba-semicon-storage.com/cn/semiconductor/product/automotive-devices/automotive-brushed-dc-motor-driver-ics.html *本文提及的公司名称、产品名称和服务名称可能是其各自公司的商标。 *本文档中的产品价格和规格、服务内容和联系方式等信息,在公告之日仍为最新信息,但如有变更,恕不另行通知。
东芝电子 . 2026-02-02 1120

OCXO恒温晶振 | GNSS接收机高精度定位与授时的核心时序基准
GNSS接收机的核心性能取决于授时精度与定位准确度,而纳秒级的时钟偏差就可能导致米级甚至十米级的定位误差。 在户外温变剧烈、电磁干扰较强、卫星信号遮挡等复杂工况下,传统温补晶振(TCXO)难以维持长期稳定,恒温晶振(OCXO)凭借极致的频率稳定性与抗干扰能力,成为GNSS接收机实现高精度授时、精准定位的核心时序基准。 三大核心应用场景:恒温晶振(OCXO)赋能GNSS接收机全领域升级 1、高精度定位场景 在需要厘米级甚至更高精度定位的场景,恒温晶振的高频率稳定性和低相位噪声特性,能够显著提升GNSS接收机在信号跟踪、定位解算的精度,减少因时钟漂移导致的误差。 自动驾驶车辆对GNSS定位精度要求达厘米级,需依托精准时序实现路径规划与安全避险。扬兴科技恒温晶振具备超高稳定性,±0.1ppb的超高稳定性可精准匹配车载GNSS接收机需求,为自动驾驶提供实时、稳定的授时支撑。 2、高精度授时应用场景 在对时间同步精度要求极高的授时应用场景,恒温晶振(OCXO)不仅是持续输出高纯度时钟信号的源头,更是在卫星信号受干扰或中断时,提供可靠的短期守时能力。 在电力调度、金融交易、通信网络等领域的NTP/PTP授时服务器,需依托GNSS接收机实现全域时间同步,对时钟源长期稳定性要求极高。恒温晶振作为核心时序基准,可复现UTC时间基准,确保跨区域设备时间同步精度达纳秒级,支撑电力调度协同、高频交易时效管控等关键场景。 3、恶劣环境应用场景 当GNSS接收机工作在野外勘探、军事应用等户外温变强烈的复杂环境中,OCXO通过恒温控制技术可有效抑制温度对频率的影响,确保接收机在不同环境条件下保持稳定的性能,减少信号解调误码率和定位偏差。 在国土测绘、矿产勘探、海事导航等场景的GNSS接收机,需维持毫米级定位精度与长期时序稳定性。恒温晶振(OCXO)能够抵御野外极端温变与强电磁干扰,确保测绘数据的精准性与一致性,为地理信息采集提供可靠时序保障。 YXC专属解决方案:全系列恒温晶振(OCXO)适配GNSS接收机需求 针对GNSS接收机不同场景的个性化需求,扬兴科技构建全系列OCXO产品矩阵,兼顾精度、尺寸与功耗平衡,主要产品系列及核心配置如下: 高精确&高可靠:频率稳定性可达10^-9量级,低老化率,直接保障GNSS接收机定位精度从米级向厘米级、毫米级突破 抗振&抗冲击:确保GNSS接收机在恶劣环境下仍能维持稳定的频率输出 低相位噪声:1KHz相噪≤-165dBc/Hz,适用于对信号纯净度要求极高的应用 多尺寸封装可选,可提供0907/1409超小尺寸封装 可提供全国产材料恒温晶振(OCXO),自主可控 扬兴科技配备专业技术团队提供从样品测试、兼容性调试到批量供货的全流程支持,助力GNSS接收机厂商实现产品精度升级,推动核心元器件国产化替代。
恒温晶振,OCXO,OCXO恒温晶振,晶振
扬兴科技 . 2026-02-02 994

纳祥科技电动搅拌杯方案:45秒延时重启,安全防护电路设计思路
速溶咖啡、蛋白粉等即饮饮品普及后,传统手动搅拌存在效率低、易结块、手腕累等问题,且现有产品多采用低速电机,对老年人和健身人群不友好,难以满足快速溶解与安全需求。 对此,纳祥科技针对性地推出电动搅拌杯方案,几秒即可搅匀,解决了传统搅拌工具效率低下与安全隐患两大痛点,兼顾高效能与安全性。 (一)方案概述 本方案采用低功耗单片机智能控制,通过Type-C接口输入5V/1A电源,经二极管为500mAh锂电池充电;工作时由3.7V锂电池供电,单片机驱动MOS管精准调控7000转微型马达实现高效启停;同时,单片机实时监测电流和温度,遇过载或过热自动断电,触发LED红灯闪烁45秒警示,需手动复位后恢复运行,确保安全可靠。 方案的核心部件包括:单片机、马达、物理按键、500mAh电池、MOS管、简易二极管充电,结合精准的电源管理系统与多重安全防护机制,确保搅拌效率提升90%以上。 核心优势包括: ① 智能交互:一键式操作,高效便捷,老人都能轻松掌握。 ② 多重防护:集成过载保护、自动断电及LED状态提示功能。 ③ 长效续航:支持TYPE-C充电,内置锂电池,续航满足20+次搅拌需求。 (二)功能模块 ① 电源管理:Type-C充电+锂电池稳压输出,具备充电保护 ② 驱动单元:MOS管驱动7000转马达,PWM调速(默认全速) ③ 控制核心:单片机采集按键信号,执行过流/过热保护逻辑 ④ 安全系统:电流检测+45秒延时重启,防止连续过载 ⑤ 人机交互:单键操作+红绿双色LED状态指示(绿-工作/红-故障或充电) (三)方案演示 我们将以豆浆粉为例,为您演示本方案—— ①将清水、豆浆粉先后倒入杯中 ②点击开关工作,搅匀后即可关机 (四) 方案总结 本方案以"高效+安全"为核心,通过集成化电路设计,将快速搅拌、智能防护和便携体验融为一体,满足上班族、健身人群、学生及老年人冲泡咖啡、蛋白粉、豆粉等多种饮品的需求。 我们现将提供完整的方案技术支持与迭代,欢迎您与我们深入交流与探讨。
搅拌杯方案
深圳市纳祥科技有限公司微信公众号 . 2026-02-02 1 1463
- 1
- 47
- 48
- 49
- 50
- 51
- 500