重点内容速览:
1. 端侧AI背后的驱动力是什么?
2. 手机移动端:消费级端侧AI的主战场
3. PC 与计算端:生产力场景的新竞赛
4. 汽车与机器人:端侧 AI 的高价值场景
5. IoT与边缘计算:中国厂商的主场
6. 端侧AI 的真正门槛:不是算力,而是系统能力
过去两年,AI 的主舞台在云端。大模型训练、推理集群、HBM、CoWos、先进制程,构成了半导体产业最显性的增长主线。但进入 2026 年之后,另一个变化正在加速发生:AI 正在从数据中心走向手机、PC、汽车、机器人和各类 IoT 终端。
这不是简单的“把大模型塞进设备里”,而是一次计算架构的迁移。端侧 AI 的价值,不只是在于隐私保护、低延迟、离线可用和推理成本下降,更重要的是,它让 AI 从“被调用的云服务”变成“随时在设备本地运行的能力”。当 AI 完成本地能力,SoC 的竞争逻辑也随之改变。
过去评价一颗 SoC,核心指标是 CPU、GPU、制程、功耗和基带。现在,NPU 算力、内存带宽、模型压缩能力、软件栈成熟度、多模态处理能力,以及与操作系统和应用生态的结合深度,正在成为新的胜负手。
2026 年将是端侧 AI 从概念验证走向规模落地的关键窗口。虽然存储价格上涨、端侧模型体验不稳定、开发者适配成本较高等因素仍会影响节奏,但大方向已经清晰:未来的 AI 不会只存在于云端,它会被分布到每一类设备中。据弗若斯特·沙利文预测,全球端侧市场将从2025年的3219亿元,跃升至2029年的1.2万亿元,复合年均增长率(CAGR)高达39.6%。

手机移动端:消费级端侧AI的主战场
手机是端侧AI最重要的入口,竞争也最为激烈。原因很简单,它是用户使用最高频的设备;有最大的出货量,全球每年出货超过12亿部;也有最完整的传感器体系。语音、图像、相机、位置、支付、社交、办公,几乎所有个人数据都在手机上发生。谁能在手机端把 AI 做成系统级能力,谁就掌握了消费级终端 AI 的第一入口。
高通:全平台生态布局
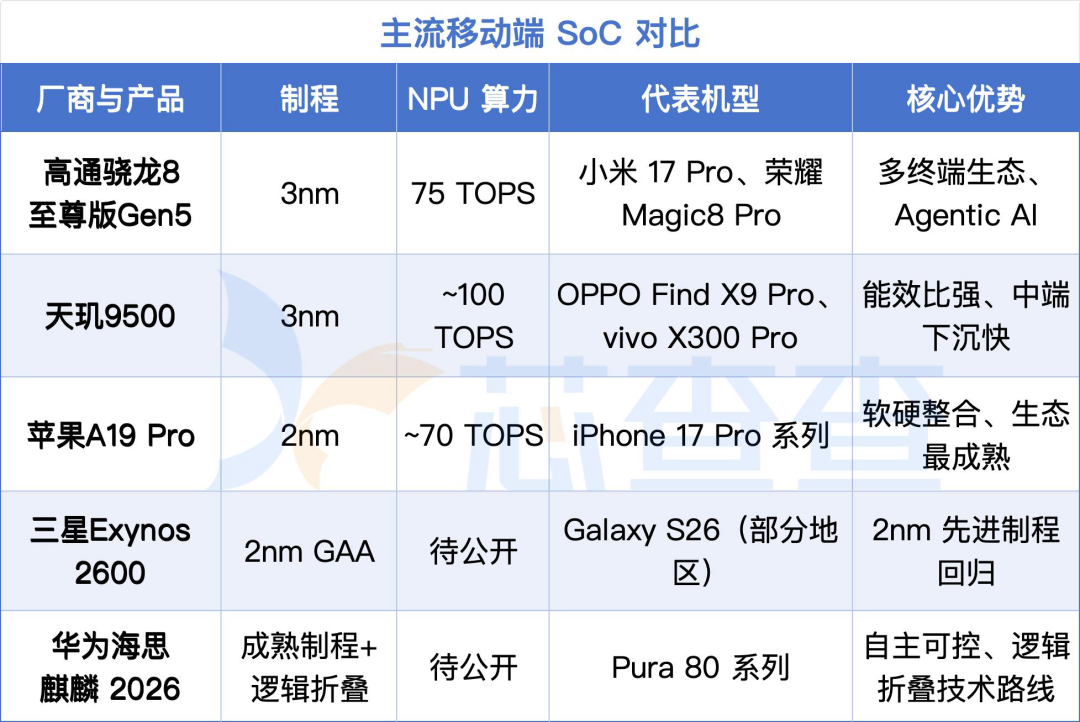
高通在安卓旗舰市场的统治地位依然稳固。2025年发布的骁龙8至尊版Gen 5(Snapdragon 8 Elite Gen 5)是其目前最强移动端芯片,搭载第三代Oryon自研 CPU架构,Hexagon NPU 算力达到75TOPS,能在本地流畅运行Llama3 8B这个量级的大模型,AI语音识别响应速度提升了约3倍。
但高通的野心不只是"手机 NPU 最快"。他们真正押注的是跨设备的AI生态:手机、PC、XR眼镜、智能手表、汽车、机器人——所有骁龙平台的设备联动,在本地网络里协同完成Agentic任务。用高通CEO安蒙的话来说:"AI的竞争将在边缘端决出胜负。"
联发科:全大核架构 + AI 算力下沉
联发科在过去两年完成了一次品牌升级——天玑9500(Dimensity 9500)搭载第九代NPU990,算力逼近100TOPS,首次在安卓平台实现了实时端侧文生图。
更值得关注的是联发科的"AI下沉"战略:天玑8400、8450、8500等中端芯片已率先支持Agentic AI,让2000–3000元价位段的手机也能用上智能体功能。只有当 Agentic AI、多模态识别、本地文生图等能力进入 2000 元至 3000 元价位段,端侧 AI 才可能从“旗舰卖点”变成“普遍体验”。这也是联发科在中国安卓市场值得关注的地方。
三星:Exynos 的2nm回归
三星自研的Exynos 2600是首款采用三星2nm GAA制程的手机SoC,搭载于部分地区版本的Galaxy S26系列。这款芯片对三星来说意义重大——它是三星对高端 SoC 主导权的一次重新争夺。先进制程、自研架构和 Galaxy 终端生态,是三星必须重新打通的闭环。但 Exynos 过去几年在性能、功耗和市场口碑上的波动,也意味着它需要用连续几代产品证明稳定性,而不是只靠单代参数反转预期。
华为海思:自主路线的新章
华为麒麟芯片选择了一条完全不同的路。受制于出口管制,华为无法使用台积电先进制程,但2026年5月正式发布的"韬(τ)定律"给出了一种替代路线:通过逻辑折叠(Logic Folding)技术,在不缩小晶体管物理尺寸的前提下,将电路垂直堆叠在多层晶圆上,实现密度提升。
搭载这一技术的麒麟2026芯片,晶体管密度比上代提升约55%,能效提升41%,目标是在2031年达到等效台积电1.4nm水平的密度。这是中国第一次在全球半导体领域提出系统性演进新原则,它的产业意义不只在一颗麒麟芯片,而在于中国半导体企业开始系统性探索“后摩尔时代”的替代路径。
手机端的竞争已经不再是单点算力竞赛,而是“芯片+操作系统+应用生态+模型能力”的综合战。苹果、高通、联发科、三星和华为,分别代表了不同的组织方式:封闭生态、平台生态、性价比普及、垂直整合,以及自主替代。
PC 与计算端:生产力场景的新竞赛
如果说手机决定端侧 AI 的普及速度,PC 则决定的是端侧 AI 的生产力价值。
在手机上,AI 摘要、修图、语音助手往往是体验增强;但在 PC 上,本地大模型、会议转写、代码辅助、离线文档处理、企业知识库检索,直接对应办公效率和数据安全。PC 是端侧 AI 从“好玩”,走向“有用”的关键场景。
NVIDIA 与微软在 5 月 30 日披露,计划在中国台北 Computex 与微软 Build 上联合发布首批以 NVIDIA 芯片作为主处理器的 Windows 电脑。这意味着 NVIDIA 正从 AI 加速卡进一步切入端侧/客户端 SoC,若正式落地,将把 Arm PC、端侧 AI Agent 与本地推理进一步绑定到新的芯片平台生态。
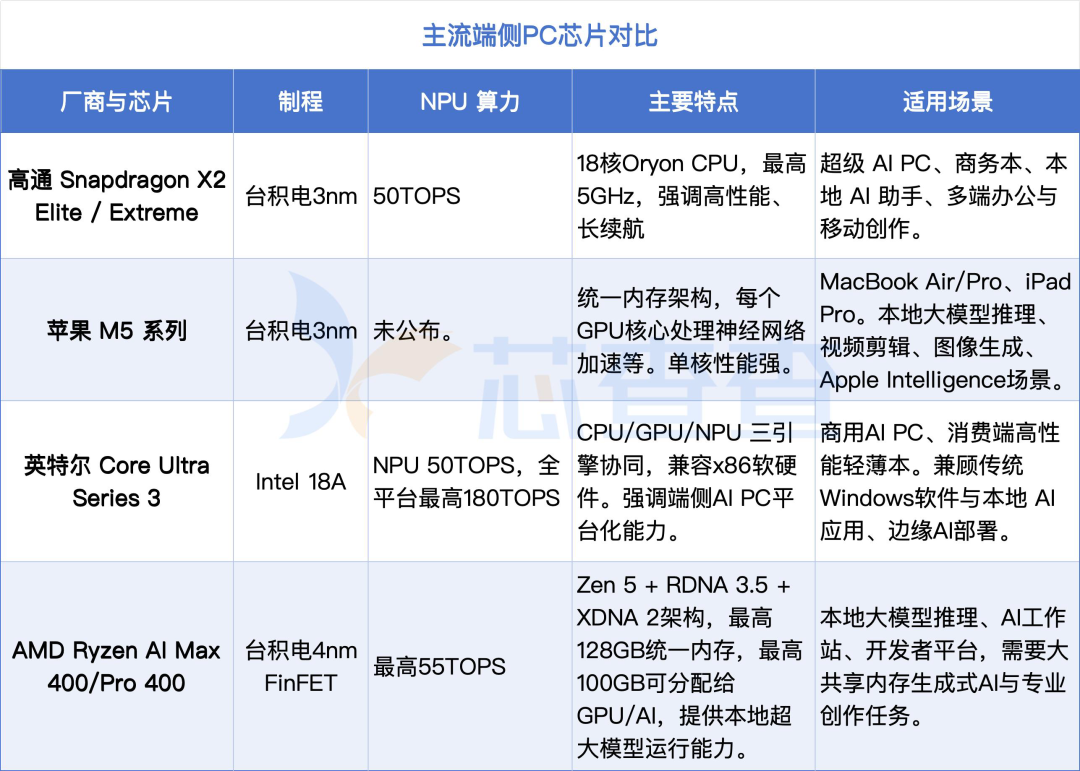
高通 Snapdragon X2 Elite Extreme(2026 年上半年)是目前 AI PC 赛道的性能标杆:3nm制程,18核Oryon CPU,NPU达到80TOPS,内存带宽最高228 GB/s,并将最大可寻址内存扩展到128GB。和第一代Snapdragon X Elite相比,NPU性能提升78%,多线程性能提升25%,同时功耗降低43%。也就是说,它的核心卖点不是极限性能,而是在较低功耗下提供足够强的 CPU、NPU 和续航表现。如果 Windows on Arm 的应用兼容性继续改善,高通有机会在轻薄本和商务移动办公市场持续扩大存在感。
苹果 M5 系列走的是另一条路:通过在GPU每个核心内嵌Neural Accelerator,M5 Max的AI峰值算力比M4提升超4倍,546 GB/s的内存带宽让本地运行70B量级大模型成为可能——这是目前消费级设备里最强的端侧大模型运行能力。苹果的封闭生态在这里成了优势:Core ML统一API让开发者几乎不需要操心NPU适配问题。
英特尔Core Ultra Series3(Panther Lake)于 2025 年 10 月公布架构,2026 年 1 月随 CES 2026 正式进入市场。该芯片采用了英特尔 18A 工艺、多芯粒架构、最高 16 核 CPU、最多 12 Xe 核显,其总算力可达180TOPS。据芯查查了解,目前采用 Core Ultra Series3平台的 OEM 厂商包括联想、惠普、微星和华硕等。
AMD Ryzen AI Max 400/300 系列(2026年1月)则走双线策略:AI Max 400配合40CU的强力集成GPU,瞄准创意专业人士;AI Max 300从700欧元左右起价,把AI PC推向主流消费市场。XDNA 2架构的50 TOPS NPU在大参数量模型推理上具有高带宽内存协同优势,适合AI开发者本地调试大模型。
总的来看,PC端的竞争逻辑是:高通和苹果以Arm架构拼效率,Intel和AMD以x86生态拼兼容性和软件深度。两条路线各有受众,短期内不会分出绝对胜负。
汽车与机器人:端侧 AI 的高价值场景
汽车和机器人是端侧 AI 最复杂、也是商业价值最高的场景。它们与手机、PC 的最大不同在于:这里的 AI 不只是交互体验,而是感知、决策和控制系统的一部分。
自动驾驶芯片需要实时性、安全冗余、车规认证和长生命周期供货。NVIDIA Drive Orin 已经量产,Thor 则面向更高阶的集中式计算架构。英伟达的优势在于,它把数据中心和机器人领域的软件生态延伸到汽车端,形成从训练、仿真到部署的完整闭环。
高通的汽车路线更偏“智能座舱 + 辅助驾驶 + 连接能力”的融合。它不一定在单颗智驾芯片算力上追求极限,但在座舱、通信、娱乐和多屏交互方面具备天然优势。随着座舱和智驾域逐步融合,高通的系统级平台能力会继续放大。
中国本土企业的机会在于速度、成本和场景协同。地平线、黑芝麻智能、芯擎科技等厂商,依托国内新能源汽车市场的快速迭代,正在形成自己的客户基础和工具链生态。国内车企的开发节奏快、场景复杂、成本敏感,这反而给本土芯片公司提供了难得的训练场。
机器人则是另一个正在打开的市场。与汽车相比,机器人对芯片的要求更分散:人形机器人需要高算力和多传感器融合,四足机器人强调实时控制和环境感知,扫地机器人则更看重成本、功耗和视觉算法。瑞芯微、全志、地平线等公司能够切入不同层级的机器人市场,关键就在于它们能把芯片、算法和客户场景绑定得更紧。
汽车和机器人共同说明了一点:端侧 AI 越往高价值场景走,越不是通用芯片单独取胜,而是“芯片 + 工具链 + 算法 + 场景数据 + 客户联合开发”的系统竞争。
IoT与边缘计算:中国厂商的主场
IoT边缘侧是中国芯片厂商最密集、最有优势的战场。这个领域对"极致性价比""垂直场景适配"和"低功耗部署"的要求,恰好是中国厂商的传统强项。
芯查查整理了几家值得重点关注的厂商:
瑞芯微(Rockchip)的 RK3588 是目前 AIoT 领域的标杆产品,6 TOPS NPU配合强大的CPU/GPU,以极高的性价比横扫NVR、工业网关、边缘服务器等场景;2025年发布的 RK3576则以更低功耗瞄准中端AIoT市场。
晶晨股份(Amlogic)深耕流媒体盒子、智能电视等消费IoT场景,在全球流媒体芯片市场份额领先,正向AI图像处理升级迭代。
爱芯元智(Axera)专注于AI视觉芯片,主要面向端侧/边缘侧视觉应用,强项在于多路视频分析、暗光成像、Transformer 视觉模型部署等,例如,AX650N等产品主打安防IPC和智能摄像头,在低功耗端侧推理上表现突出,已进入海康威视、大华等头部安防品牌的供应链。
乐鑫科技(Espressif)的ESP32系列芯片几乎是全球Wi-Fi +蓝牙物联网设备的标准配置,面向对成本极度敏感的低端IoT市场拥有近乎垄断的地位,正在向更高算力的AIoT芯片延伸。
此外,星宸科技、全志科技、北京君正等公司,也都在各自细分市场形成稳定客户基础。它们的特点不是横扫所有场景,而是在一个个垂直市场里做深、做稳、做便宜。
这类市场看似不如 AI GPU 和 HBM 那样耀眼,却可能是端侧 AI 最早规模化变现的地方。原因很现实:摄像头、网关、门锁、机器人、工业终端、家电设备,都需要本地识别、本地决策和低成本部署。云端 AI 再强,也无法替代这些场景对实时性、成本和离线能力的要求。
端侧 AI 的真正门槛:不是算力,而是系统能力
讨论端侧 AI,最容易陷入 TOPS 军备竞赛。但 TOPS 只是纸面指标,不能直接等同于用户体验。真正重要的是在有限功耗、有限内存、有限散热条件下,设备能不能稳定运行有用的模型,并且被开发者和应用真正调用起来。
因此,端侧 AI 的竞争会围绕三个维度展开。
第一是算力效率。手机有功耗墙,PC 有续航约束,汽车有安全冗余,IoT 有极低成本和待机要求。端侧 AI 不是把算力堆得越高越好,而是在每一瓦功耗里跑出足够有价值的推理能力。
第二是软件生态。苹果有 Core ML,高通有 AI Stack,英特尔有 OpenVINO,英伟达有 CUDA 和 Isaac。芯片厂商如果只提供硬件,不解决模型部署、算子优化、开发工具和系统调用问题,就很难让开发者真正用起来。这也是中国端侧 AI 芯片公司未来必须补强的部分。
第三是垂直场景适配。汽车要功能安全认证,安防要多路视频和暗光识别,工业要长期稳定和抗干扰,医疗要数据合规。越到行业深水区,通用 AI 芯片越不够用,快速理解客户场景、共同定义产品,才是形成护城河的关键。
2026 年的端侧 AI,不是云端 AI 的缩小版,而是一次新的产业分工。云端负责大模型训练、复杂推理和跨场景知识能力,端侧负责实时响应、隐私保护、个性化执行和低成本常态化运行。未来主流架构大概率不是纯云端,也不是纯端侧,而是端云协同。
手机会推动端侧 AI 普及,PC 会验证生产力价值,汽车和机器人会打开高单价市场,IoT 和边缘计算会带来最广泛的碎片化落地。不同场景会产生不同赢家,没有一家公司能够通吃所有市场。
端侧 AI 的本质,不是让每台设备都拥有一个“小号 ChatGPT”,而是让智能成为终端设备的基础能力。谁能在算力、效率、生态和场景之间找到最优解,谁就能在这场从云到端的迁移中占据更长期的位置。



全部评论