近年来,在外部环境的重重压力与内部需求的井喷式爆发双重驱动下,国产AI芯片产业正经历一场深刻的蜕变。从“点”上的突破到“面”上的铺开,一股“整体崛起”的力量正在汇聚。本文将带您深入探寻这股浪潮,并盘点那些已经崭露头角、值得我们关注的国产AI芯片产品。
国产AI芯片的崛起并非偶然,而是一场由市场需求、技术演进、外部环境和政策支持共同驱动的结果。首先,大模型竞赛引爆了对算力的指数级需求,国内云服务提供商(CSP)的AI资本支出持续提升。其次,美国对先进AI芯片的出口限制,以及NVIDIA专供中国市场芯片要么性能偏低,要么价格太过昂贵,从客观上倒逼国内客户将采购策略转向本土供应商。
更重要的是,国内产业生态日趋成熟。一方面,国产先进制程的产能与良率正逐步提升;另一方面,以DeepSeek为代表的国产大模型开始深度适配国产AI芯片,中国信通院甚至发布了专门的适配清单,涵盖了华为、寒武纪、昆仑芯、海光信息、摩尔线程等厂商,形成了软硬件协同的良性循环,例如DeepSeek在8月下旬发布的最新V3.1模型采用了UE8M0 FP8精度,能与国内AI芯片更好地系统工作;最后,国家政策的强力护航为产业发展注入了“强心剂”。国务院在8月26日发布的《关于深入实施“人工智能+”行动的意见》通知,明确了到2027年,新一代智能终端、智能体等应用普及率超70%的目标,为国产芯片的应用铺平了道路。
群雄并起:国产AI芯片全景图
在探讨国产AI芯片之前,我们需要明确一下什么是AI芯片。狭义的AI芯片指的是专门为AI算法做了特殊加速设计的芯片,主流架构包括GPU(通用性强,生态成熟)和ASIC(针对特定场景,能效比高)。例如NVIDIA最新的基于Blackwell架构的B300 GPU以其卓越的计算性能和能效比受到市场追捧,而Google的TPU芯片(一种ASIC)则以其专为机器学习优化的设计提供高速数据处理。
正是在这样的背景下,一批优秀的国产AI芯片企业脱颖而出,形成了包括云端训练、云端推理、边缘计算等在内的全场景产品矩阵。例如寒武纪、昆仑芯、平头哥、海光信息、燧原科技、摩尔线程、沐曦科技、壁仞科技、天数智芯等厂商都有推出AI芯片产品。
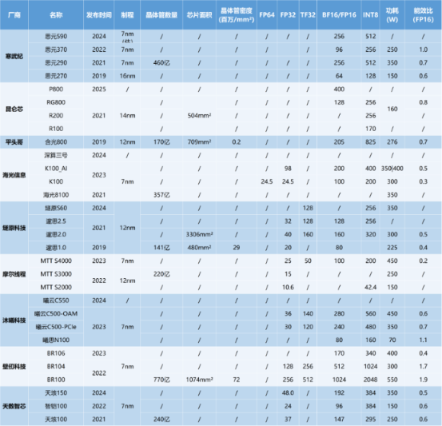
由于评判一颗AI芯片的性能离不开算力、算力精度、显存、显存带宽、卡间互联、功耗、制程等关键指标。下面芯查查梳理了目前国内主流云端AI芯片的核心参数,以期为市场选择提供参考。
算力在迅速提升,能效比仍有差距
常用的算力衡量指标包括FLOPS(每秒浮点运算次数)和OPS(每秒运算次数)。常见单位有TOPS(每秒万亿次操作)和TFLOPS(每秒万亿次浮点操作),一般用TOPS来衡量设备的推理算力,用TFLOPS来衡量设备训练算力,TFLOPS数值越高,反映了模型在训练时的效率越高。
算力精度作为可以衡量算力水平的一种方式,可分为浮点计算和整型计算。其中浮点计算可细分为半精度(2Bytes,FP16)、单精度(4Bytes,FP32)和双精度(8Bytes,FP64)浮点计算,加上整型精度(1Byte,INT8)。不同的计算精度适用于不同场景。FP32和FP16常用于训练,而FP16和INT8则在推理场景中更具效率优势。
芯查查统计了目前国内已经量产出货的国产AI芯片算力、功耗、能效比和制程方面的情况(见表1)。
表1:国产AI芯片算力、功耗、能效比与制程情况统计(来源:各公司官网,芯查查)
从芯查查统计的算力衡量指标中可以看到,国产AI芯片当中,大都公布的是FP16和INT8算力精度,其中FP16精度算力指标中超过200FLOPS的有寒武纪的思元590、思元290、昆仑芯P800、平头哥的含光800、海光信息的深算三号、沐曦科技的曦云C500、壁仞科技的BR系列等产品。已经超过了H20提供的148FLOPS FP16算力。
在制程方面,目前国外的AI芯片制程已经到了3nm制程,但国内的AI芯片仍然以7nm为主。例如Google最新的TPU Ironwood(TPU v7p)和亚马逊的Trainium3都使用了最先进的3nm制程;NVIDIA最新的Blackwell系列GPU产品采用的是台积电的4NP制程(相当于4nm的高性能版本);AMD、英特尔、Meta及微软均采用了5nm制程。国内厂商中,寒武纪、海光信息、壁仞科技和摩尔线程等均被美国列入了“实体清单”,其晶圆代工产能供应受限,智能采用国内最为先进的工艺。燧原科技的所有产品则主要采用了GlabalFoundries的12nm制程进行制造。
在能效方面,目前NVIDAI的Blackwell系列GPU能效比在所有架构里面最高,比如GB200在功耗为2,700W的情况下,能效比可达到1.9。而国产AI芯片的功耗绝大多数都在500W以下,能效比基本都低于1.0。
芯片间互联大都采用自研互联技术AI算力的比拼已经进入了“集群”时代,单颗芯片的性能提升虽然很重要,但多卡、多节点的高效互联则更为关键。NVIDIA凭借其成熟的NVLink和NVSwitch技术构建了强大的护城河。相比之下,国内AI芯片厂商大多采用私有互联方案,尚未形成统一开放的标准,这在一定程度上限制了大规模集群的扩展性和效率。
表2:国产AI芯片Scale-up互联技术(来源:各公司官网,芯查查)
2022年,寒武纪被美国列入实体清单,禁止与台积电合作,寒武纪遭受第二次大挫折。随后,寒武纪转向与中芯国际合作,生产制造被局限于更成熟的工艺节点。
例如寒武纪目前主要采用其自研的MLU-Link技术、昆仑芯采用K-Link、壁仞科技采用B-Link、摩尔线程采用MT-Link等。根据摩尔线程招股书的信息,其自研的MT-Link最开始在其曲院架构中实现,通信速率为56Gbps,通信带宽为240GB/s。随后在其平湖架构中升级到了MT-Link2.0,通信速率提升至112Gbps,通信带宽提升至800GB/s。目前已经完成了MT-Link3.0的研发,通信带宽提升到了1.3TB/s,达到了行业领先水平。
国产AI芯片也大都采用HBM,但以HBM2e为主显存是GPU用于存储数据和纹理的专用内存,与系统内存(DRAM)不同,显存具有更高的带宽和更快的访问速度。显存的大小和性能将直接影响GPU处理大规模数据的能力。而显存带宽则是GPU与显存之间数据传输的桥梁。其计算方式是显存带宽=显存位宽X显存频率。
表3:国产AI芯片显存及显存带宽参数(来源:各公司官网,芯查查)
目前国际厂商的显存以HBM3和HBM3e为主,国内AI芯片厂商虽然也大都采用了HBM存储,但以HBM2e为主,显存容量最高已经达到64GB。
可以看到,这几年国产AI芯片厂商在芯片微架构、制程、生态等方面不断追赶海外头部供应商,这里列举的都是已经量产的,其实还有一些最新的产品目前并没有公开的数据,但其实已经得到了很大的提升。特别是卡间互联的性能提升相比前几年有了很大的进步。
未来展望:从“可用”到“好用”
国产AI芯片的崛起之路,注定充满挑战,但也充满希望。展望未来,我们有理由相信随着技术不断成熟、生态逐步完善、应用场景持续深化,国产AI芯片将不仅在国内市场站稳脚跟,更有望在全球AI算力的版图中占据一席之地。
这其中,生态建设是关键。因为一颗芯片的成功离不开软件、工具链和开发者社区的支持,只有构建起繁荣的生态建设,才能将硬件的算力真正转化为用户的生产力。未来国产AI芯片厂商必须加大在软件生态上的投入,吸引更多开发者,打造“中国的CUDA”。
另外,软硬协同,系统优化也很重要。因为AI算力的比拼早已不是单纯的芯片性能竞赛,而是包括芯片、服务器、高速互联、集群管理和AI框架在内的系统工程。UALink等开放互联标准的兴起为国产AI芯片提供了新机遇,底层的SerDes等高速接口技术是实现自主可控的关键环节。
最后,拥抱开源,合作共赢,让国产AI芯片从“可用”实现“好用”的跨越。AI技术的发展离不开全球协作。在自主可控的前提下,积极拥抱开源社区,与全球开发者共同推动技术进步,是中国AI芯片产业融入世界、提升竞争力的必由之路。



全部评论