重点内容速览:
| Arm Ethos NPU:已推出第三代,有20家合作伙伴
| 安谋科技:周易NPU系列
| Ceva:可提供一整套边缘AI处理器解决方案
| Cadence:Tensilica Neo NPU IP
| 芯原:采用其NPU IP的AI类芯片出货量超过1亿颗
| Synopsys:ARC NPX6 NPU IP 系列
| 英业达:为低性能MCU量身定制的NPU
云端AI发展如火如荼的时候,边缘AI的发展也开始步入快车道,边缘AI芯片的需求日益增长。边缘AI芯片不仅需要具备低功耗、高性能、安全可靠的特性,同时还需要易于集成和部署。
而将AI加速器,也就是NPU集成在MCU上,可以更好地满足不同的应用场景需求。前一篇文章我们谈到了一些MCU厂商已经在其产品中集成了NPU内核,其中有些厂商,比如ST,NXP等都是采用自研的NPU IP内核,那么市场上有没有第三方的NPU IP产品可供MCU厂商选择呢?答案是有的,下面是芯查查统计的市面上可供选择的NPU IP产品。
Arm Ethos NPU:已推出第三代,有20家合作伙伴
Arm比较早就注意到了边缘AI的市场需求,并在2020年初正式推出微神经网络处理器(Micro Neural Network Processing Unit)Ethos-U55,正式开启MCU AI时代来临,不过由于新冠疫情影响,直到2022年底,其合作伙伴ALIF Semiconductor才推出第一颗实体芯片Ensemble系列(E1/E3/E5/E7)及配套开发板。
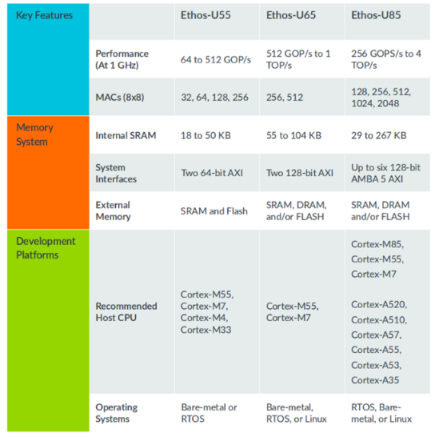
如今,Arm的NPU产品已经推出三代了,除了此前推出的Ethos-U55与Ethos-U65,今年4月份还推出了Ethos-U85。其中,Ethos-U85 是 Arm Ethos-U 产品线中的第三代 NPU,也是迄今为止性能和能效最强的 Ethos NPU。与上一代产品Ethos-U65相比,该 NPU 的性能提升了4倍,能效提高了 20%,并且可在主流网络上实现高达 85% 的利用率。全新 Ethos-U85 可满足诸如工厂自动化和商用或智能家居摄像头等物联网应用不断攀升的性能需求。此外,其专为搭配基于 Cortex-M 或 Cortex-A的系统一同运行而设计,并容忍高 DRAM 延迟。
图:Arm Ethos-U85支持Transformer架构和卷积神经网络(来源:Arm)
Ethos-U85 的主要特性包括:
- 单周期支持从 128 到 2048 个 MAC单元的配置——在 1GHz 时,算力可支持从 256 GOPS 到 4 TOPS。
- 支持 int8 权重和 int8 或 int16 激活。
- 支持 Transformer 架构网络,以及 CNN 和 RNN。
- 硬件原生支持 2/4 稀疏性,使吞吐量翻倍。
- 内部 SRAM 为 29 至 267 KB,多达六个 128 位 AXI5 接口。
- 支持权重压缩,采用标准和快速权重编码器。
- 支持扩展压缩。
图:Arm推出的三代NPU IP规格对比(来源:Arm)
除了 Ethos-U55 和 Ethos-U65 目前支持的算子,通过支持 TRANSPOSE、GATHER、MATMUL、RESIZE BILINEAR 和 ARGMAX 等运算,Ethos-U85 涵盖了对 Transformer 模型和 DeeplabV3 语义分割网络的原生硬件支持。
Ethos-U85 也支持元素级算子链化。通过链化将元素级运算与先前的运算相结合,使 SRAM 不必先写入再读取中间张量。由此可凭借 NPU 和内存之间数据传输量的减少,提高 NPU 的效率。相比于 Ethos-U65,链化是 Ethos-U85 在效率提升上的新功能之一,其余还包括快速的权重编码器、优化的 MAC 阵列能效,以及提升的元素效率。
到今年已经有ALIF、Himax(奇景)、Nuvoton(新唐)、Infineon(英飞凌)推出了基于Cortex-M55+Ethos-U55组合的产品。据悉,Arm Ethos NPU系列产品已经有超过20家授权许可合作伙伴,其中ALIF和英飞凌是全新的Arm Ethos-U85 NPU的早期采用者。
安谋科技:周易NPU系列
2023年3月份,安谋科技发布了自研新一代AI处理器“周易”X2 NPU。据其官网介绍,该NPU采用了第三代“周易”架构,支持多核Cluster,最高可达320TOPS子系统。实时的硬件任务管理使得“周易”X2 NPU可实现最高千万次/秒的任务调度,将各个计算单元的效能发挥到最佳。
在算力大幅提升的同时,“周易”X2 NPU还具有更高的精度和灵活性。在精度方面,“周易”X2 NPU支持int4 / int8 / int12 / int16 / int32,fp16 / bf16 / fp32多精度融合计算,计算效率与计算密度得到显著提升。
图:安谋科技的NPU架构(来源:芯查查拍摄)
在灵活性方面,“周易”X2 NPU在支持自定义算子、满足各种模型部署需求的基础上,还面向各类应用场景提供定制化AI解决方案,以进一步满足客户在智能驾驶、手机影像AI处理、人机交互等场景中的差异化需求。
“周易”X2 NPU特别针对ADAS、智能座舱、平板电脑、台式机和手机等细分应用场景进行了大量性能优化,可大幅提升手机拍照、录像中的高分辨率图像处理能力,以及车载中常用的Transformer等应用的性能,同时采用i-Tiling技术大幅减少带宽需求,进一步提升计算效率,让客户能更轻松地应对不断迭代的多样化计算需求。
图:周易Z系列NPU特性(来源:安谋科技)
此外,安谋科技还有“周易”Z系列NPU,采用为神经网络运行及相应的前后处理设计的专用指令集,具有均衡的可编程能力和优化的标准处理能力,满足不同人工智能算法需求。融合了多种执行粒度的指令,可以为人工智能提供能效比高的运算能力。"周易" Z 系列 NPU 也支持配合 Arm Cortex CPU、Arm Mali GPU 以及第三方硬件的异构计算,能够大大提高人工智能应用开发的生产效率。目前,“周易”Z 系列已经推出了 Z1、Z2 和 Z3 三代产品。
Ceva:可提供一整套边缘AI处理器解决方案
Ceva有一整套专为边缘AI和传感应用而定制的可扩展处理器解决方案,算力从10GOPS到1000TOPS的NPU到DSP可供选择。
具体产品包括Ceva-NeuPro-Nano、Ceva-NeuPro-M、Ceva-NeuPro Studio等。其中,Ceva-NeuPro-Nano 是一款高效自给式边缘 NPU,专为 TinyML 应用设计,适用于 AIoT 设备。其性能范围从 10 GOPS 到 200 GOPS,支持电池供电设备的常时开启应用,如可听设备、可穿戴设备、家庭音频、智能家居和智能工厂。无需主CPU/DSP,即可独立运行,包括代码执行和内存管理。它支持 4、8、16 和 32 位数据类型,具有原生 Transformer 计算、稀疏性加速和快速量化功能。通过 Ceva-NetSqueeze 技术,内存占用减少 80%。提供 Ceva NeuPro-Studio AI SDK,与 TFLM 和 µTVM 等开源 AI 推理框架无缝协作,涵盖语音、视觉和传感用例。Ceva-NPN32 和 Ceva-NPN64 两种配置满足广泛的应用需求,提供最佳功耗效率和小巧硅面积。
Cadence:Tensilica Neo NPU IP
Cadence推出的Neo NPU IP扩展能力很强,可为低功耗应用提供广泛的AI功能。Neo NPU单核配置的性能高达 80 TOPS,支持经典 AI 模型和最新的生成式 AI 模型,配有简单易用的可扩展 AMBA AXI 互联,可处理来自任何处理器的 AI/ML 负载,包括应用处理器、通用型微处理器和 DSP。NeuroWeave Software Development Kit(SDK)是对 AI 硬件的补充,为开发人员提供了一站式 AI 软件解决方案,涵盖 Cadence AI 和 Tensilica IP 产品,用于实现“零代码”AI 开发。
其主要特性包括:
- 可扩展性:单核解决方案可从 8 GOPS 扩展到 80 TOPS,多核可进一步扩展到数百 TOPS。
- 广泛的配置范围:每个周期支持 256 到 32K 个 MAC,允许 SoC 架构师优化其嵌入式 AI 解决方案,以满足功耗、性能和面积(PPA)权衡的要求。
- 集成支持各种网络拓扑结构和运营商:可高效运行来自任何主处理器(包括 DSP、通用型微控制器或应用处理器)的推理任务,从而显著提高系统性能,降低功耗。
- 易于部署:加快产品上市,满足日新月异的新一代视觉、音频、雷达、自然语言处理(NLP)和生成式 AI 流水线的需求。
- 灵活性:支持 Int4、Int8、Int16 和 FP16 数据类型,涵盖构成 CNN、RNN 和基于 Transformer 的网络基础的各种操作,可灵活权衡神经网络的性能和准确性。
- 高性能和高效率:与第一代 Cadence AI IP 相比,性能最多可提高 20 倍,每面积每秒推理次数(IPS/mm2)提高 2-5 倍,每瓦每秒推理次数(IPS/W)提高 5-10 倍。
芯原:采用其NPU IP的AI类芯片出货量超过1亿颗
芯原在今年年初的时候发布新闻稿宣称,集成了其NPU IP的AI芯片在全球范围内出货量超过了1亿颗,主要应用在物联网、可穿戴、智能家居、安防监控、服务器、汽车电子、智能手机、平板电脑等市场。据悉,其NPU IP已被72家客户用在了128款AI芯片当中。
其最新推出的VIP9000系列NPU IP提供了可扩展和高性能的处理能力,适用于Transformer和卷积神经网络(CNN)。结合芯原的Acuity工具包,这款强大的IP支持含PyTorch、ONNX和TensorFlow在内的所有主流框架。
此外,它还具备4位量化和压缩技术,以解决带宽限制问题,便于在嵌入式设备上部署生成式人工智能(AIGC)和大型语言模型(LLM)算法,如Stable Diffusion和Llama 2。
VIP9000系列支持从0.5TOPS到20TOPS的性能范围,适用于从可穿戴设备、物联网、智能家居到汽车和边缘服务器等广泛应用。
Synopsys:ARC NPX6 NPU IP 系列
Synopsys ARC NPX6 NPU IP 系列是业内性能最高的神经处理单元(NPU)IP,专为满足AI应用的实时计算需求而设计,具备超低功耗。该系列包含ARC NPX6和NPX6FS,支持最新的复杂神经网络模型,包括生成式AI,并提供高达3,500 TOPS的性能,适用于智能SoC设计。
ARC NPX6 NPU IP单实例在5nm工艺下能提供高达250 TOPS的性能,通过稀疏特性可提升至440 TOPS。集成多个NPU实例后,性能可达3,500 TOPS。ARC NPX6支持从1K到96K MACs,兼容CNN、RNN/LSTM及新兴网络如Transformer。它支持INT 4/8/16位分辨率,并可选BF16和FP16。
ARC NPX6FS NPU IP专为功能安全设计,符合ISO 26262 ASIL D标准,适用于汽车和其他需要高安全性的应用。它具备双核锁步处理器和自检安全监控,满足混合关键性和虚拟化需求。
Synopsys提供的ARC MetaWare MX开发工具包包含编译器、调试器、神经网络软件开发工具包(SDK)、虚拟平台SDK、运行时和库以及高级仿真模型。该工具包能自动将算法划分到MAC资源上,实现高效处理,简化了开发流程。
ARC NPX6 NPU IP系列广泛应用于智能相机、传感器融合、工业自动化、汽车电子和高性能嵌入式系统等领域,助力实现智能SoC设计中的AI创新。
英业达:为低性能MCU量身定制的NPU
英业达正积极发力各种边缘AI运算应用领域,该公司在2023年Q1推出了完整的一站式AI IP导入服务,以及“VectorMesh” AI 加速器。为满足MCU领域的AI需求,英业达还推出了定位于超低逻辑门数 (Gate Count) 的NPU (neural processing unit) IP—— Minima 系列。
Minima 系列为满足终端算力需求在 32 GOPS以下的应用,从8051 MCU到各家 32/64位RISC CPU都可以搭配使用,没有整合限制。
实际应用则可用于物体检测、特征检测、人脸检测、人脸识别、姿态识别、图像分割、图像美化、信号过滤等应用。对MCU市场的少量多样特性,英业达除了陆续推出各种低算力要求的 NN 模型库供客户选择使用,也接受客户提案,提供 turnkey 定制化设计服务。
据悉,除了Minima系列外,英业达还将推出复杂度更高,以及终端算力更大的Parva和Magna系列,同样都具备低功耗、高效能、高弹性架构等3大特点,应用于边缘端 AI推理,力求满足多元化市场需求。
结语
随着数据量的爆炸式增长,如何有效利用这些数据成为了新的挑战。边缘AI的出现解决了这个问题,它允许设计人员利用现有的数据创建更优的应用。边缘AI的核心在于能够在云端设计和训练模型,然后在嵌入式设备上运行这些模型,实现数据处理的本地化。
当然,除了上面提到的可供第三方选择的NPU IP可以用于MCU,其实最近几年也涌现出了不少基于RISC-V内核的NPU IP也是值得关注的,如果对这块感兴趣可以关注我们的后续文章。




全部评论