2010年代后期以来,大语言模型(LLM,Large Language Model)一直处在实验室研究阶段,直到ChatGPT的出现,LLM才走到聚光灯下。根据国家互联网信息办公室1月5日发布的深度合成服务算法备案信息公告显示,第三批境内深度合成服务算法为129个,累计280个,大模型已进入规模落地应用阶段。
国外大模型:Transformer架构取代RNN并成为主流
OpenAI、谷歌、Meta、微软等国外企业的LLM注重理解和生成文本的能力,包括语言翻译、情感分析和文本摘要等,技术研究集中在2点,第一个是预训练技术,如掩码语言建模(MLM)和下一句预测(NSP),对提高LLM的性能至关重要,涉及在大量文本数据上训练模型并学习语言中的基本模式和关系。第二个是LLM扩展和数据,涉及增加模型大小、训练数据量以及训练过程中使用的计算资源。
常见的国外大模型包括:
GPT:OpenAI生成式AI预训练模型为GPT,当前版本是GPT-3.5-turbo和GPT-4,采用Transformer架构。GPT是带有API的通用LLM,被许多企业使用,包括Microsoft、Duolingo、Stripe、Descript、Dropbox和Zapier等。
Gemini与PaLM:2个同为谷歌的大模型,Gemini是多模态基础模型,能同时理解和处理多种类型数据输入,比如文本、图像、视频等,目标是实现跨模态的理解和生成能力。PaLM则聚焦单一自然语言处理,Gemini与PaLM根据不同的使用场景和需求来部署和整合的。
Llama 2:Meta和Instagram的开源LLM,可从Github下载源代码,免费用于研究和商业用途,许多LLM以Llama 2为基础。
Vicuna:是基于Meta Llama LLM构建的开源聊天机器人,用于人工智能研究,并作为Chatbot Arena的一部分,Chatbot Arena是由LMSYS运营的聊天机器人基准测试。
Claude 2:是GPT最重要的竞争对手之一,面向诉求安全的企业客户。与所有其他专有LLM一样,Claude 2仅作为API提供,尽管它可以根据数据进行进一步训练,并进行微调以响应应用需求。
Falcon:开源LLM,在各种AI基准测试中一直表现良好,拥有多达1800亿个参数,在某些任务中可以胜过PaLM 2、Llama 2和GPT-3.5。其是在Apache2.0许可下发布,适用于商业和研究用途。
MPT:包含MPT-7B和MPT-30B LLM两个功能强大的商用LLM。与许多其他开源模型不同,MPT并不建立在Meta Llama模型之上。MPT-30B的性能优于原始GPT-3。有几个不同版本,针对聊天等内容进行了微调,7B版本可用于生成长篇小说。
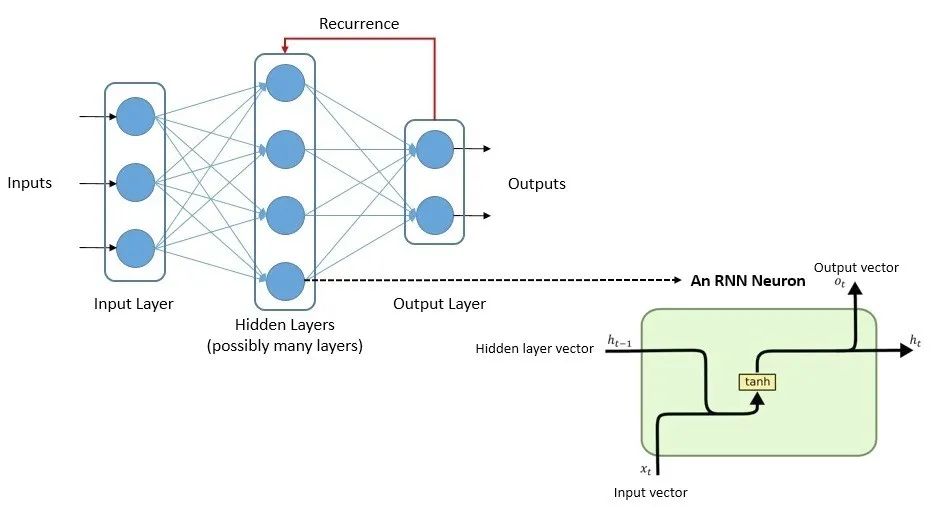
总的来看,多数现有模型采用Transformer架构,与此不同,早期LLM使用带有LSTM(Long Short-Term Memory,长短期记忆网络)和GRU(Gated Recurrent Unit)的循环神经网络(RNN)模型架构,这2种技术在大规模执行NLP(自然语言处理)任务时面临挑战,这可能是RNN逐渐式微的原因。
RNN使用其内部状态处理可变长度的输入序列,并有多种变体,比如前文提到的LSTM和GRU。LSTM帮助RNN何时记住和何时忘记重要信息,其目的是为了将内存引入RNN,但是训练速度非常慢,需要按顺序或串行方式提供数据,不允许我们并行化和使用可用的处理器内核。GRU架构不太复杂,训练所需内存更少,执行速度也比LSTM快,但GRU通常更适合较小的数据集。
在过去很长一段时间里,LSTM和GRU是构建复杂NLP系统的首选,然而这些模型也存在梯度消失(vanishing gradient)问题。
RNN的问题可以通过添加注意力机制(attention mechanism)得到解决。具体而言,在LSTM递归体系结构中,可以传播的信息量是有限的,并且保留信息的窗口更短,通过注意力机制,这个信息窗口可以显着增加。注意力是一种增强输入数据的某些部分而减少其他部分的技术,让系统更多地关注数据的重要部分。但是这仅仅缓解梯度消失的问题。
谷歌Brain团队在2017年推出的Transformer可能是LLM历史上最重要的转折点之一,作为一种深度学习模型,Transformer采用自注意力机制并一次性处理整个输入。使用Transformer模型的另一个显著优势是它们更具并行化性,需要的训练时间要少得多,这正是可用资源有限,并且在大量基于文本的数据语料库上构建LLM所需要的。因此现在无论是学术研究,还是工业应用中,Transformer架构已经成为构建大规模预训练模型的标准选择,如BERT、GPT系列、T5等知名模型均基于Transformer设计。
国内大模型:研究早于ChatGPT流行,落地应用或更多元化
凭借本土企业和研发人员对深度学习技术的深入理解与创新,国内AI大模型发展迅速。在ChatGPT流行之前,部分国内企业已经研究AI大模型技术:2021年4月,华为云联合循环智能发布盘古超大规模预训练语言模型,参数规模达1000亿;2021年6月,北京智源人工智能研究院发布超大规模智能模型“悟道2.0”,参数规模达到1.75万亿;2021年12月,百度推出ERNIE 3.0 Titan模型,参数规模达2600亿,同期,阿里巴巴达摩院M6模型参数达到10万亿。
我国大模型可以划分为通用类与垂直类,两者在参数级别和应用场景等方面不同。通用类大模型可在多个领域和应用中表现出良好的效能;垂直类大模型针对特地行业,在解决细分领域的问题更高效。
以下介绍几种常见的通用类大模型:
通义千问 2.0 :由阿里云研发的超大规模语言模型,具备多轮对话、文案创作、逻辑推理、多模态理解、多语言支持等功能,在复杂指令理解、文学创作、通用数学、知识记忆、幻觉抵御等能力上均比上代有显著提升。
昆仑万维天工大模型 :AI搜索引擎、对话式AI助手。拥有强大的自然语言处理和智能交互能力,能够实现个性化AI搜索、智能问答、聊天互动、文本生成、编写代码、语言翻译等多种应用场景,涵盖科学、技术、文化、艺术、历史等领域。
书生浦语开源大模型 :由上海人工智能实验室研发,包括几个版本,70亿参数的轻量级版本InternLM-7B、200亿参数的中量级版本、InternLM-20B,以及完整的开源工具链体系。InternLM-7B在包含40个评测集的全维度评测中展现出卓越且平衡的性能。
言犀基础大模型 :由京东科技研发,融合70%通用数据和30%数智供应链原生数据,具有更高产业属性。
此外,国内也有部分访问受限的大模型,这类大模型通常是私有大模型或企业级大模型,专门为某个组织或机构定制并且仅限于该组织内部使用。
我国大模型发展有着庞大的市场规模和丰富的应用场景,显而易见的是,我国拥有世界上最大的互联网用户群体,这为大模型提供了海量的数据资源和多样化的应用场景。
针对不同行业和领域的需求,本土企业积极研发垂直领域的专用大模型,如医疗、教育、金融等,这些模型经过特定场景下的优化,能够提供更为精准的服务。再加上产业生态健全、技术创新活跃等因素,我国大模型产业正加速发展。
小 结
国外大模型技术积累较多,OpenAI GPT系列和谷歌Transformer架构等在全球范围内产生深远影响。我国在大模型的研究有很多贡献,持续发展过程面临的挑战之一是算力资源,高性能计算基础设施的整体规模与先进程度上仍存在差距,这可能限制大模型训练的速度和效率。在核心竞争力上,我国的大模型或许还要更多模型架构、算法优化等方面的研究,好的一面是,在处理中文语料、理解中国文化背景以及适应中国特有的应用场景时具有显著优势,此外文中提到的我国在市场和应用丰富也是我国大模型产业的优势。



全部评论