电机控制系统,是现代自动化设备的核心“肌肉与神经”,直接决定工业机器人、AGV、家电等产品的运行精度、响应速度与稳定可靠性。
PID作为电机控制领域最经典、应用最广的闭环算法,一直是保障电机平稳精准运行的关键。但传统PID高度依赖人工经验,存在调参慢、适配差、抗扰弱、多工况难兼顾等痛点,尤其在机器人与家电场景中,长期困扰工程师。
如今,AI技术为这一难题带来全新解法。
依托意法半导体在电机控制与AI领域的双重技术优势,我们将深度强化学习(DRL)算法与高性能硬件深度融合,推出搭载AI驱动PID自整定的EtherCAT双电机伺服驱动器交钥匙方案,彻底突破传统PID调参瓶颈,让电机控制更智能、更高效、更稳定。
本文将带你全面了解:AI如何重构PID整定、方案核心亮点、实测效果,以及在机器人、家用电器等场景的落地价值。
ST EtherCAT双电机伺服驱动器:一站式交钥匙方案
这是一款带有以太网现场总线(EtherCAT)的双1kW/48V伺服电机驱动器交钥匙解决方案,集成了高性能电机控制芯片、功率器件和通信接口,能够满足机器人、家用电器等领域的双电机协同控制需求——这意味着电机一经安装调试,即可投入运行。主要特性包括:
双电机强劲性能:
该驱动器采用STSPIN32G4电机控制器,搭配STDRIVE101栅极驱动器与低压功率MOSFET,实现双电机独立控制;单路驱动通道额定电流可达20A有效值(Arms),完全满足双路1kW/48V电机的驱动需求。
精准传感与通信:
这款伺服驱动器既支持增量式编码器,也支持绝对式编码器;在工业领先的通信协议方面,同时兼容以太网现场总线(EtherCAT)和控制器局域网(CAN)。
智能化硬件设计:
印刷电路板(PCB)布局经过优化,可适应不平衡负载,因此即便其中一个电机处于高负荷运行状态,整个系统仍能保持良好性能。
此外,它还提供完整的固件栈,包括电机控制软件开发套件(MCSDK)、CiA402协议和EtherCAT协议栈,无需从零构建固件。

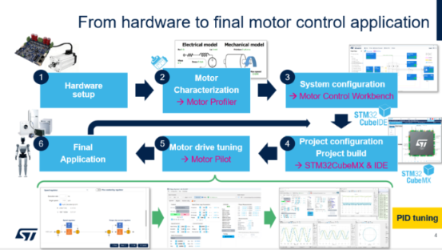
ST完整电机控制生态:从工具到落地全链路支持
意法半导体为电机控制应用打造了一站式友好型图形化工具链,助力用户从硬件搭建快速过渡到功能完备的应用开发。
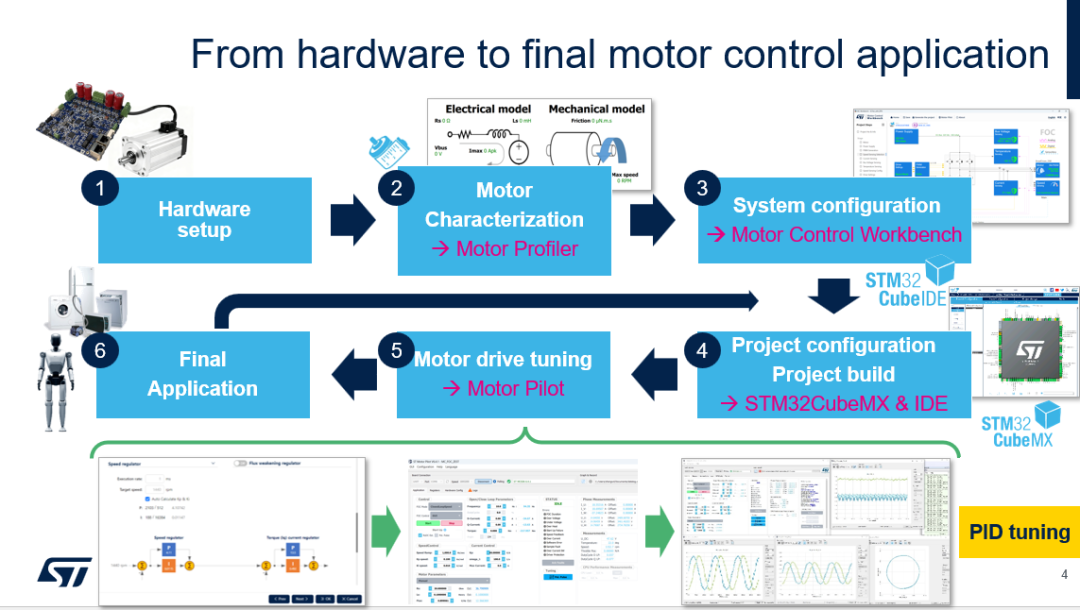
在实现PID整定之前,需要深入了解电机的基本参数特性。我们通过电机分析仪(Motor Profiler)识别电机的电气和机械参数。获得参数后进入电机控制工作台(Motor Control Workbench),该工具可以设定所需的电机控制带宽,并自动计算出PID参数,参数可靠性取决于电机模型的准确性。
在实际应用场景中,电机模型并非始终在理想条件下运行——它们会承载不同的负载,工作在不同的环境中。这就是电机调试导航仪(Motor Pilot)的用武之地。借助这款工具可以在真实的测试环境下对PID参数进行微调,最终完成应用开发。整个整定过程要求工程师具备扎实的电机控制知识,所以PID整定仍是行业内极具挑战性的工作。
机器人与家电电机控制:传统PID面临的核心痛点

机器人与家用电器的电机控制,对响应速度、运行稳定性、长期可靠性有严苛要求,而传统PID调优存在诸多难以破解的痛点:
参数耦合与动态响应:
PID三个参数(Kp、Ki、Kd)相互关联,改动其中一个,其他参数就会受到影响。例如,增大Kp可以加快系统响应速度,但容易导致超调和振荡;增大Ki可以消除稳态误差,但可能加剧超调;增大Kd可以抑制振荡,但会降低系统的抗干扰能力。同时,积分环节的累积作用易引发积分饱和,进一步加剧系统超调;最终形成“提升响应速度易引发振荡、增强稳定性会导致响应滞后”的矛盾,难以通过固定参数实现二者的兼顾。
◆ 在机器人控制中,难以找到一组参数同时满足“快速响应”和“稳定运行”的需求:追求快速响应可能导致机器人运动振荡,影响定位精度;注重稳定性则会导致响应滞后,影响作业效率。
◆ 在家用电器中,参数耦合同样会导致能耗增加、噪声变大,例如洗衣机脱水时因参数不当出现机身抖动。这些问题都会集中体现出来,而且PID参数调整非常耗时。
外部扰动与设备维护:
机械间隙、轴承磨损与轴承游隙变化会产生微小且不可预测的机械偏差,这会导致原本精细整定好的PID参数在长期运行中失效,需要重新整定。即使更换电机也要重新整定,整个过程非常复杂。
而人工智能技术将彻底改变这一局面,让整个整定过程更顺畅,电机控制系统更可靠、响应更迅速。
AI驱动PID智能整定:基于深度强化学习
本方案利用深度强化学习实现PID参数的静态调优,它的独特之处是拥有一个始终与环境交互的AI智能体(Agent)。强化学习是一种基于“试错”的算法,核心思想是让智能体通过与环境的交互,根据环境反馈的奖励信号(Reward),不断调整自身的行为策略(Policy),最终学习到最优的行为方式,实现奖励折扣总和最大化。
AI智能体的控制策略(Policy)是根据观察状态(State)来生成动作(Action)的,学习算法通过从环境中获取奖励,并尝试更新策略,最大化期望。可以通过利用当前Action及其Reward对策略神经网络(Policy Network)进行迭代更新,从而生成使其向最佳策略方向靠近。
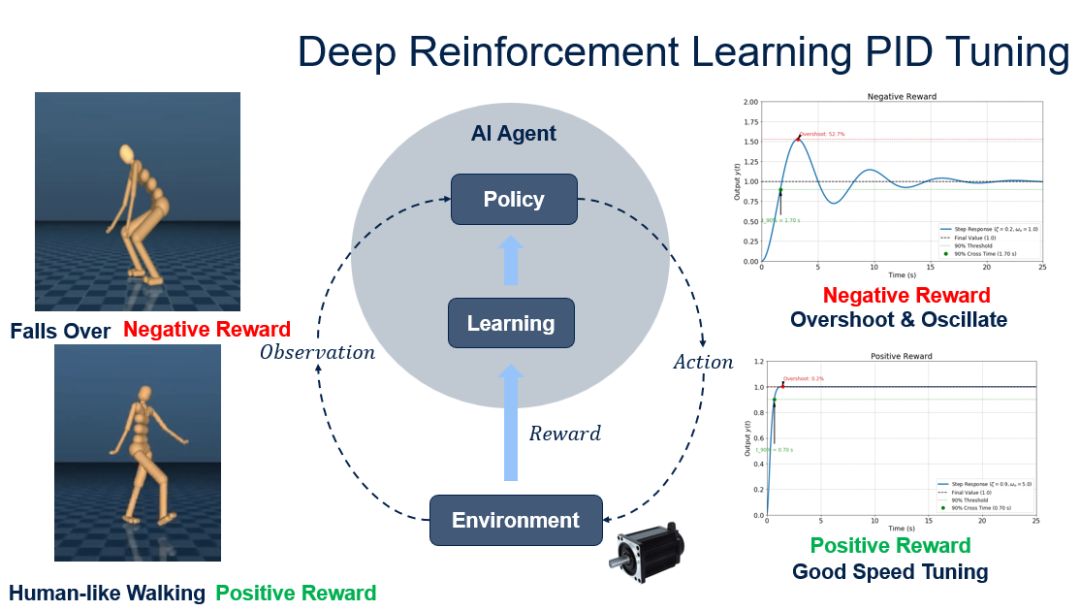
以Google DeepMind人形机器人行走训练为例:Google DeepMind通过使用深度强化学习,在仿真中训练了一个人形机器人行走,当人形机器人摔倒时,会给智能体一个负奖励(Negative Reward)。当人形机器人稳定走了一段距离,就给予一个正奖励(Positive Reward)。
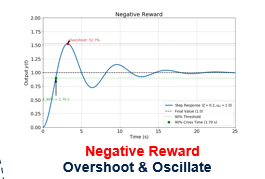
这一逻辑可完美迁移至BLDC电机PID调参场景。BLDC电机的主要目标是实现理想的阶跃响应。即当电机切换速度时,能多快达到目标速度。例如,一个劣质的PID参数会导致较差的阶跃响应,响应速度过慢,这意味着达到目标速度要花很长时间,且超调百分比非常高,振荡也会很严重。当学习算法观测到这个状态时,会获得负奖励,而在下一步动作中,策略会尝试更新PI参数,以规避这组参数。
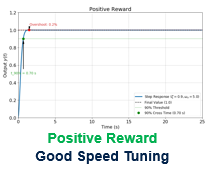
下图是一个近乎完美的阶跃响应。它的响应速度快,且几乎没有超调。因此这个阶跃响应会计算出一个较高的reward,策略网络就会更倾向于输出此Action。
下图展示了一个典型的电机控制环路:电机把位置、速度、扭矩等反馈给PID算法,生成下一个时间切片的相电流,然后将这三个参数作为策略网络输出的Action,通过观察到的阶跃响应计算Reward,从而更新价值网络。图中绿色的部分是最重要的AI智能体,包括两个关键部分:Actor和Critic。
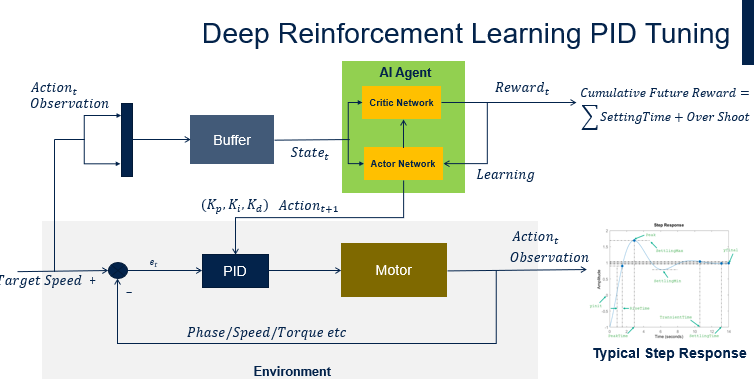
Actor网络会根据观察到的状态生成下一步Action,也就是P、I和D参数。Critics网络会接收下一时刻观察,并利用奖励来更新Actor。所以Actor类似之前提到的策略网络,而Critics更像是价值网络。
从图中还可以看到我们使用的奖励为达速时间和超调百分比的加权平均。这也是传统意义上的电机控制工程师调节PID参数的方法,我们也将这一概念引入AI领域。
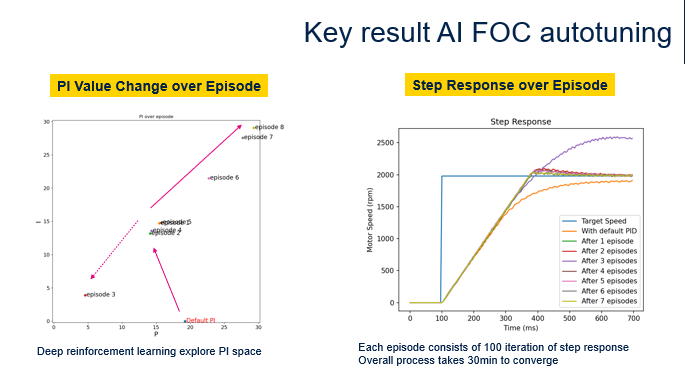
上图展示了通过该算法实现的关键结果。图左展示了在不同的训练回合(Episode)中AI是如何探索PI空间的。首先默认的PI在(20,1),然后它探索中间区域,最后移动到原点,最终找到了更新PI参数的正确方向。图右展示不同回合中的阶跃响应,可以看到后面回合的阶跃响应正在变得越来越好。
结语
AI驱动PID整定方案相较传统手动整定,在调节速度、超调控制、稳态精度与抗扰动能力上实现全方位跃升,成功破解参数耦合、积分饱和、动态负载适配等行业长期难题,让电机控制真正迈入全自主、自优化的智能新阶段。
意法半导体EtherCAT双电机伺服驱动系统,以高功率密度、高精度控制、同步任务调度等硬核特性,为AI智能调参提供坚实可靠的硬件底座;当强大硬件遇上自适应AI算法,二者深度协同,形成开箱即用的完整交钥匙方案,可高效满足机器人、家用电器等场景的高端电机控制需求,以AI创新驱动机电控制领域全面智能化升级。





全部评论