瑞萨电子面向语音AI,基于VK-RA8M1开发套件,集成多种智能语音处理功能,实现了无需云端的高性能语音控制的应用。
功能介绍
目前语音控制技术已广泛应用于家电、车载、智能家居等领域,但仍面临两个核心问题:
环境噪声干扰。当嘈杂环境或多人讲话时,语音识别准确率会大幅下降。
对云连接的依赖。离线状态下,通常只能识别少量、固定顺序的关键词,实现功能有限。
瑞萨推出的集成式语音应用场景,将多种语音控制功能集成一体,以应对这些问题。
基于RA8M1的语音应用包括如下功能:
APF(Audio Processing Front)。音频处理前端,可将语音与背景噪音分离,提高语音识别准确率。
NLU(Natural Language Understanding)。自然语言理解,允许用户用自然口语发出指令,系统自动提取关键词识别命令。
CNSV(Cyberon Speaker Verification )。Cyberon语音验证,将关键词检测提升到更高层次,将语音识别升级为语音身份验证。
VAS(Voice Anti-Spoofing)。语音防伪技术,使系统能够区分真人语音和录音。
功能演示
APF噪声抑制演示
A8M1开发板已预先加载语音组合程序,通过USB 连接电脑,作为立体声麦克风使用。
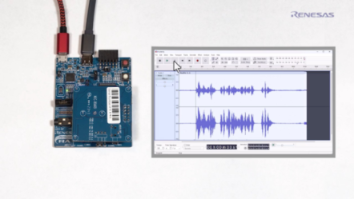
通常,我们会在理想安静的环境中录制视频,但为了演示降噪的功能,在演示用例中,刻意引入了环境噪音。如图2所示。
在演示用例中,采用立体声轨来直观呈现APF的处理效果。其中,左声道显示的是未处理音频,右声道显示的是经过APF处理后的音频。如图3所示。
从图3中可以看到:
上方的左声道展现了未经过APF处理的原始音频波形。噪音和语音混杂,语音信号不明显。
下方的右声道展现了经过APF处理后的音频波形。背景噪音被明显抑制,语音信号更加清晰。
NLU、CNSV、VAS综合演示
在演示用例中,可以同时实现识别关键词、语音身份认证、真人语音识别的功能,通过下述操作,可逐个演示功能:
注册说话人的语音信息。根据系统提示,重复说三遍“Hi Renesas”,用于创建准确的声纹识别模型。注册时的显示信息如图4所示。
使用说话人的声音发出“Hi Renesas”的指令。系统显示“Accepted”,表明成功识别说话人声音。如图5所示。
用手机录制“Hi Renesas”的指令,如图6所示。
用录音发出“Hi Renesas”的指令让系统识别。系统显示“Dropped”,表明识别失败并拒绝执行,成功区分真人语音和录音。如图7所示。
总结
实现这些实时语音的AI功能,对MCU的性能要求非常高,而RA8M1搭载的Cortex-M85内核支持Helium DSP加速技术,能够大幅提升语音算法的本地运行性能,从而在无需接入云端的情况下完成这些处理。
相关资源
RA8M1 Voice User Demonstration Kit
https://www.renesas.com/en/design-resources/boards-kits/vk-ra8m1
AI Voice
https://www.renesas.com/en/key-technologies/artificial-intelligence/ai-voice
Cyberon DSpotterNLU
https://www.renesas.com/en/products/microcontrollers-microprocessors/ra-cortex-m-mcus/ra-partners/cyberon-dspotternlu
Cyberon Speaker Verification CNSV
https://www.renesas.com/en/products/microcontrollers-microprocessors/ra-cortex-m-mcus/ra-partners/cyberon-dspotternlu




全部评论