
卢工爱分享
零基础理解 VLA 原理 2:机器人是如何理解环境的?
在上一篇里,我们讲到 VLA 可以粗略理解为三部分:看懂环境、理解任务、生成动作。机器人要完成一个任务,需要先知道自己面对的是什么。桌上有什么物体?目标物体在哪里?人类说的“把红色方块放到盒子里”到底指什么?这些问题,都属于感知和理解的范围。在传统机器人系统里,感知通常是一个比较工程化的模块。相机负责拍图,检测算法负责找物体,分割算法负责区分边界,位姿估计算法负责算出物体位置,然后规划和控制模块再接着往下做。这个流程很清晰,也很可靠,但它往往需要人为定义很多中间环节。VLA 里的“多模态感知”有一点不一样。它不只是让机器人看到图像,也不只是识别物体名字,而是希望模型能把视觉、语言、空间关系和任务意图放在一起理解。这里最核心的技术基础,就是 VLM,也就是 Vision-Language Model,视觉语言模型。
VLM:让模型同时理解图像和语言
VLM 的基本目标,是让模型同时处理视觉和语言信息。最简单地说,VLM 可以看一张图片,然后回答关于这张图片的问题。比如给它一张桌面图片,问:“红色方块在哪里?”模型可以回答:“在桌子的左侧,靠近蓝色圆柱。”再问:“哪个物体更适合被夹爪抓取?”它可能会结合物体形状、位置和可见区域,给出一个判断。这和普通图像分类模型不同。传统图像分类模型通常回答“这张图里有什么”,比如猫、狗、杯子、键盘。目标检测模型可以进一步给出物体框,告诉你每个物体大概在哪里。VLM 则更进一步,它可以把图像内容和自然语言问题联系起来,进行更开放的理解。在机器人任务里,这种能力非常重要。因为人类给机器人的指令,很少是严格结构化的参数。我们不会说:“抓取图像坐标 x=320, y=180 处的物体。”我们更可能说:“把桌上的红色积木拿起来。”这里面有物体类别、颜色、空间位置和任务意图,模型必须把它们连在一起。
VLM 是怎么实现看图说话的?
从工程实现上看,VLM 通常由三部分组成:视觉编码器、语言模型,以及连接视觉和语言的对齐模块。视觉编码器负责“看图”。它会把输入图像切成很多小块,或者提取成一组视觉特征。语言模型负责“理解和生成文字”。它本来擅长处理 token,也就是一个个词或子词。中间的关键问题是:图像不是文字,怎么才能送进语言模型里?所以 VLM 需要一个连接层,把视觉特征转换成语言模型可以理解的“视觉 token”。这些视觉 token 不一定对应真实的词,但在模型内部,它们可以和文字 token 放在同一个序列里处理。这样一来,模型看到的就不再只是“图片”和“句子”两类孤立输入,而是一串混合了视觉信息和语言信息的 token。可以把这个过程简单理解成:
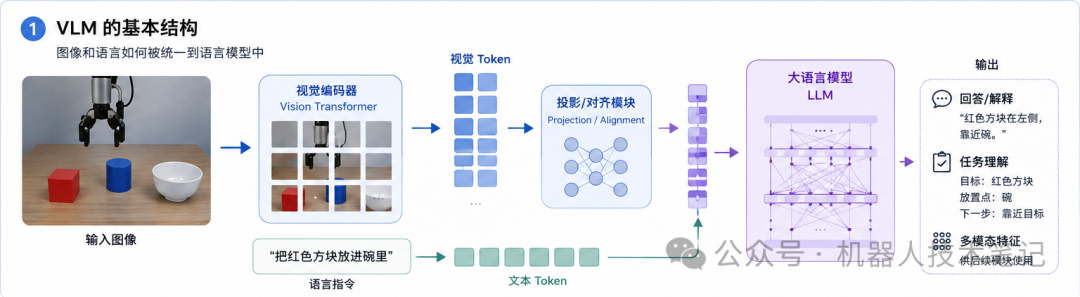
这就是很多 VLM 的基本技术路线。
第一步:把图像变成视觉 token
语言模型天然处理的是文字。比如一句话“抓起红色方块”,会被分词器变成一串 token,然后送进 Transformer。图像则不同,它本质上是像素矩阵,不能直接作为文字输入。因此,VLM 首先要用视觉编码器处理图像。常见做法是使用 ViT,也就是 Vision Transformer。ViT 会把一张图像切成许多 patch,比如 16×16 像素的小块。每个 patch 经过编码后,会变成一个向量,表示这块图像里的视觉信息。如果是一张桌面图片,这些视觉 token 里可能包含颜色、边缘、纹理、物体局部形状等信息。单个 token 未必对应一个完整物体,但很多 token 组合起来,就能表达“这里有一个红色方块”“那里有一个白色碗”这样的视觉结构。在机器人场景里,图像 token 的质量很重要。因为机器人需要知道目标物体在哪里、周围有什么障碍、夹爪应该往哪个区域移动。如果视觉编码器丢掉了过多空间细节,后面的动作生成就会受到影响。
第二步:把视觉特征接到语言模型上
视觉编码器输出的是向量,语言模型内部处理的也是向量。看起来两者形式相似,但它们并不天然处在同一个语义空间里。视觉编码器学到的是图像特征,语言模型学到的是文字语义。中间需要一个对齐模块,把视觉特征映射到语言模型可以使用的表示空间中。这个模块可以很简单,比如一个线性投影层;也可以更复杂,比如用一个小型 Transformer,专门负责从大量视觉特征中提取和语言相关的信息。这一步非常关键。它决定了语言模型能不能把图像里的区域和文字里的概念对应起来。
比如用户输入:“红色方块在哪里?”模型需要把“红色”“方块”这两个语言概念,和图像里某一组视觉 token 对齐。如果对齐做得不好,模型可能会知道图中有方块,也知道“红色”是什么意思,但无法稳定判断哪个视觉区域对应“红色方块”。所以,VLM 的核心能力之一,就是视觉-语言对齐,让视觉内容和自然语言描述之间建立对应关系。
第三步:语言模型负责综合推理
当视觉 token 和文本 token 一起进入大语言模型后,Transformer 会通过注意力机制在两类信息之间建立联系。比如输入是:图像:桌上有红色方块、蓝色圆柱、白色碗问题:把红色方块放进碗里,应该关注哪里?模型在处理“红色方块”这个词组时,会注意到图像中对应红色物体的视觉 token;处理“碗”时,会注意到另一个目标区域;处理“放进”时,则会把抓取目标和放置目标联系起来。这也是 VLM 和普通视觉模型最大的不同。普通视觉模型通常输出一个固定结果,比如分类标签、检测框或者分割掩码。VLM 的输入问题不同,关注点就可以不同。同一张图像,问“红色方块在哪里”,它会关注方块;问“哪个物体可以作为容器”,它会关注碗;问“先抓哪个物体”,它又会结合任务目标给出不同判断。
VLM 是怎么训练出来的?
VLM 的训练通常是分阶段进行。第一阶段通常是图文对齐训练。模型会看到大量图像和对应文字描述,学习图像和文本之间的匹配关系。比如一张图配一句“a red cube on the table”,模型就要把图中的红色方块和文字描述联系起来。这个阶段解决的是“图像和语言能不能对上”的问题。第二阶段是视觉问答和指令微调。模型不仅要知道图文是否匹配,还要学会按照人的问题进行回答。比如给一张图片,问“桌上有几个物体?”“红色方块在什么位置?”“哪个物体更靠近机器人?”这些任务会让模型从图像描述走向图像理解。第三阶段,如果要进入机器人领域,还需要机器人数据继续微调。普通互联网图像和机器人第一视角图像差异很大。机器人看到的是夹爪、桌面、物体、遮挡和运动过程,不是普通摄影图片。为了让 VLM 适应机器人任务,需要用机器人操作数据、桌面 manipulation 数据、仿真数据或人工标注数据进行训练。这也是为什么 VLM 可以作为 VLA 的基础,但不能直接等于 VLA。通用 VLM 可能会看懂“红色方块在桌上”,但它未必知道机械臂应该从哪个角度接近,夹爪宽度是否合适,抓取之后如何避障。这些都需要机器人数据和动作学习进一步补上。
VLM 输出的是什么?
在普通视觉问答任务里,VLM 的输出通常是文字。比如:红色方块在桌子的左侧,靠近白色碗。但在 VLA 中,单纯输出文字还不够。机器人最终需要的是动作,而不是一句描述。所以 VLM 的输出可以有几种不同用法。一种方式是让 VLM 输出高层任务理解。比如模型先生成:“目标物体是红色方块,放置目标是白色碗,当前应该先靠近红色方块。”这相当于把自然语言任务变成更结构化的中间表示,再交给后面的规划或控制模块。另一种方式是直接使用 VLM 内部的隐藏特征,而不是它最终生成的文字。也就是说,模型不一定要先说出一句话,再让机器人执行;它可以把图像和语言融合后的特征向量传给 action head,由 action head 直接预测连续动作。在很多 VLA 模型里,第二种方式更常见。因为机器人控制需要连续、快速、可微分的表示。文字描述虽然直观,但中间会损失很多细节,也可能引入不稳定性。可以简单理解成: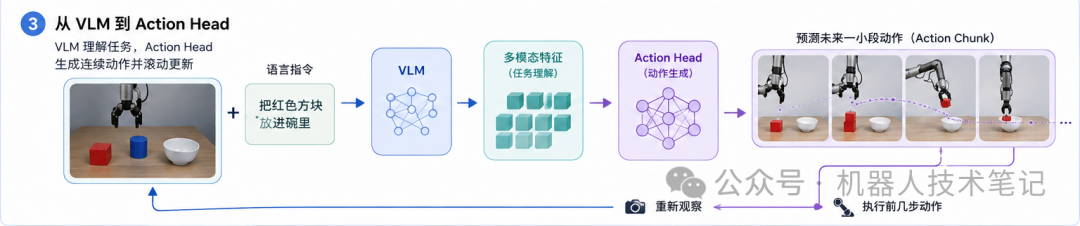
这里的 VLM 不只是聊天模型,而是动作策略的感知和理解前端。
VLM 的技术链路
从技术实现上看,VLA 中的多模态感知通常是这样工作的:视觉编码器把图像变成视觉 token,对齐模块把视觉 token 接到语言模型空间里,语言模型融合图像和指令形成任务理解,最后 action head 再把这种多模态特征转换成机器人可执行的连续动作。所以,VLM 是 VLA 理解世界的入口。没有 VLM,机器人很难自然理解“红色方块”“靠近杯子的物体”“把它放进去”这些人类语言里的开放概念;只有 VLM 也不够,因为真正让机器人动起来,还需要动作表示、机器人数据、闭环控制和真实物理约束。
相关推荐:
文章来源于公众号-机器人技术笔记,仅用于学习分享,如有侵权请私聊删除
版块:
机器人开源工坊
2026/06/05 10:52



全部评论