置顶
精华 【瑞萨AI挑战赛】智能AI网络监控摄像头实现指北
温柔的接触器Moly
一、 前言
随着边缘计算的普及,对设备的AI算力和网络传输能力提出了更高的要求。本项目旨在利用瑞萨 RA8P1 (Titan Board) 开发板,打造一款无屏化、高性能的智能AI网络监控摄像头。
系统基于 Cortex-M85 (1GHz) 强劲的性能与 Arm Ethos-U55 NPU (500MHz) 的AI加速能力,通过 MIPI 接口实时采集图像,在本地进行高帧率的人脸检测推理,并最终依托千兆以太网和 ThreadX NetX 协议栈,将带有AI检测框的视频流实时推送到PC端。
开发环境与硬件平台如下:
- Keil MDK + Renesas FSP Smart Configurator 6.4.0
- RTOS: Azure ThreadX RTOS
- DapLink
二、 系统架构设计
本项目的核心系统架构摒弃了传统的本地 LCD 显示方案,转而采用“MIPI采流 -> NPU推理 -> 内存叠加 -> NetX网络推流”的纯边缘计算架构:
- 硬件处理中枢**:瑞萨 R7KA8P1 MCU,具备 1MB MRAM 与 2MB 内部 SRAM。
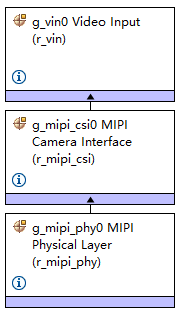
- 图像采集层 (MIPI CSI + VIN)**:通过 MIPI CSI-2 接口接收传感器的高速视频流,利用内置的 Video Input Module (VIN) 进行硬件级别的色彩转换(如 YUV422 转 RGB565)并将帧缓存通过 DMA 零拷贝写入外部 HyperRAM。
- AI 算力层 (Ethos-U55 NPU)**:专门用于执行 INT8 量化的 YOLO-Fastest 人脸检测模型。
- 网络通信层 (ESWM + RTL8211F)**:使用 RA8 内部的 Layer 3 Ethernet Switch Module (ESWM) 控制器,配合外部 RTL8211F 千兆 PHY 芯片,结合 Azure RTOS ThreadX 及 NetX 网络协议栈实现高速 UDP 数据分发。
如下图所示,本项目共划分为五个核心工作线程:
Renesas FSP Smart Configurator Stacks配置总览: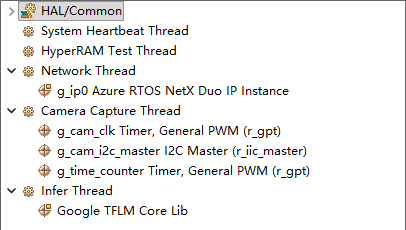
三、 核心线程实现细节
3.1 系统心跳与日志打印 & RAM测试
不同于RTThread系统自带MSH Shell,ThreadX没有打印控制台,为了在串口打印日志信息,参考Titan-Board SDK,将UART8配置为日志打印串口,并对fputc重定向
FSP配置如下: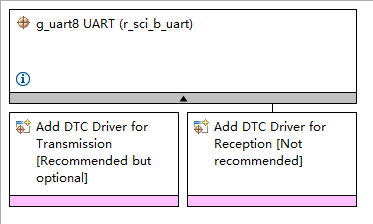
// Sys_Thread
#include "async_logger.h"
#include "sys_thread.h"
#include <stdio.h>
#if defined(__CC_ARM) || (defined(__ARMCC_VERSION) && __ARMCC_VERSION >= 6000000)
__asm(".global __use_no_semihosting\n\t");
FILE __stdout;
FILE __stdin;
FILE __stderr;
void _sys_exit(int return_code)
{
(void)return_code;
while (1)
;
}
void _ttywrch(int ch)
{
fputc(ch, &__stdout);
}
#endif
static bool g_sem_inited = false;
TX_SEMAPHORE g_uart_tx_sem;
void user_uart8_callback(uart_callback_args_t *p_args)
{
if (p_args->event == UART_EVENT_TX_COMPLETE)
{
tx_semaphore_put(&g_uart_tx_sem);
}
}
int fputc(int ch, FILE *f)
{
(void)f;
fsp_err_t err;
if (!g_sem_inited)
return ch;
do
{
err = R_SCI_B_UART_Write(&g_uart8_ctrl, (uint8_t *)&ch, 1);
if (err == FSP_ERR_IN_USE)
{
tx_thread_sleep(1);
}
} while (err == FSP_ERR_IN_USE);
if (err == FSP_SUCCESS)
{
tx_semaphore_get(&g_uart_tx_sem, 100);
}
return ch;
}
extern TX_QUEUE g_log_queue;
TX_TIMER g_led_timer;
static bool g_led_state = false;
void led_timer_callback(ULONG input)
{
(void)input;
g_led_state = !g_led_state;
R_IOPORT_PinWrite(&g_ioport_ctrl, BSP_IO_PORT_00_PIN_12, g_led_state ? BSP_IO_LEVEL_HIGH : BSP_IO_LEVEL_LOW);
}
/* System Heartbeat Thread entry function */
void sys_thread_entry(void)
{
async_logger_init();
char *log_msg = NULL;
tx_semaphore_create(&g_uart_tx_sem, "UART TX Sem", 0);
g_sem_inited = true;
/* 初始化 UART8 */
R_SCI_B_UART_Open(&g_uart8_ctrl, &g_uart8_cfg);
tx_timer_create(&g_led_timer, "LED Heartbeat Timer", led_timer_callback, 0, 500, 500, TX_AUTO_ACTIVATE);
printf("\r\n======================================\r\n");
printf("Azure RTOS ThreadX is running on RA8P1!\r\n");
printf("======================================\r\n");
while (1)
{
if (tx_queue_receive(&g_log_queue, &log_msg, TX_WAIT_FOREVER) == TX_SUCCESS)
{
printf("%s", log_msg);
tx_block_release(log_msg);
}
}
}
同样的,依样画葫芦,参考Titan-Board SDK 文档 /HyperRAM 使用说明,也可以很快对HyperRAM
进行配置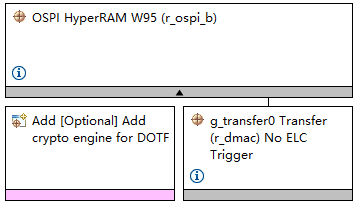
注意:在FSP 6.4中,可以直接选择 OSPI HyperRAM W95 Stack,该stack集成了W95 command code,故可以不必如文档教程配置相应参数3.2 使用MIPI CSI 与 VIN 的采集图像
不同于传统的 CEU DVP 接口,本项目采用了带宽更高的 MIPI CSI 协议。在 FSP (Flexible Software Package) 配置中,启用了 r_mipi_csi 和 r_vin 栈。
由于图像数据庞大,在 FSP 中通过配置 OSPI 接口的 r_ospi_b 栈,将图像双缓冲(Frame Buffer)分配在了外部的高速 HyperRAM 中。
注意:为了保障 DMA 写入不发生瓶颈,需要将 OSPI 和 HyperRAM 相关引脚的驱动能力(Drive Capacity)全部配置为 H (高驱动)。1. 相机 时钟配置
使用通用PWM 6 gpt作为24M相机时钟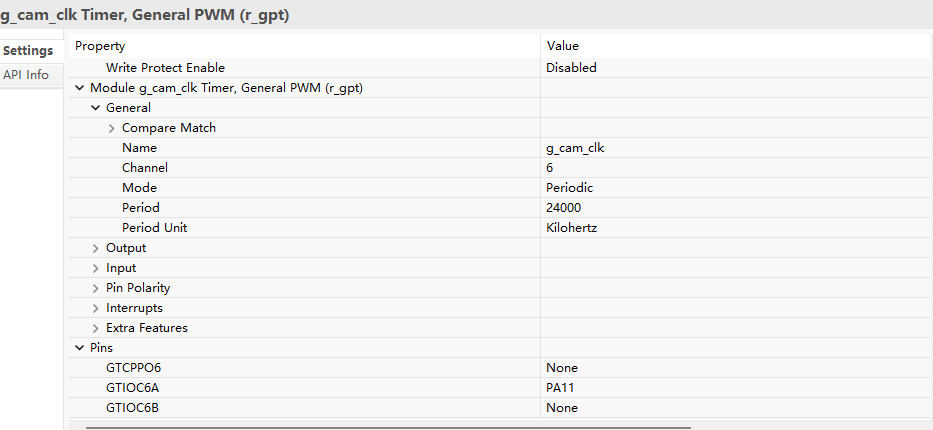
2. 相机SCCB(I2C)接口配置
使用I2C0配置相机SCCB
3. 相机MIPI CSI-PHY配置,参考Titan-Board SDK 文档/MIPI CSI 摄像头使用说明
将r_vin stack的buffer配置到HyperRAM中,减小内存压力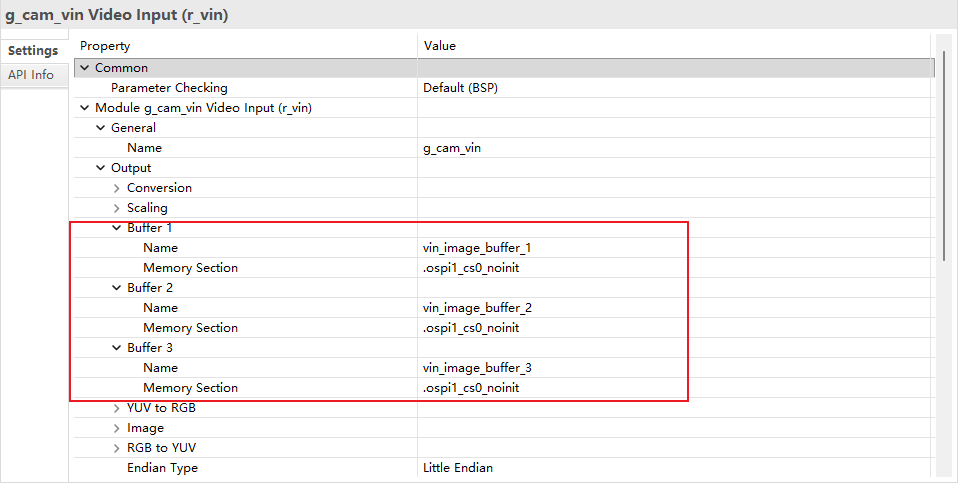
camera_thread代码实现如下:
#include "async_logger.h"
#include "cam_thread.h"
#include "camera_layer.h"
#include "camera_layer_config.h"
#include <stdio.h>
TX_SEMAPHORE g_vin_capture_sem;
/* ai thread */
TX_SEMAPHORE g_ai_start_sem;
TX_SEMAPHORE g_ai_done_sem;
/* Camera Capture Thread entry function */
void cam_thread_entry(void)
{
tx_semaphore_create(&g_vin_capture_sem, "VIN Capture Sem", 0);
tx_semaphore_create(&g_ai_start_sem, "AI Start Sem", 0);
tx_semaphore_create(&g_ai_done_sem, "AI Done Sem", 0);
fsp_err_t err = FSP_SUCCESS;
// Clear camera image buffer
camera_image_buffer_initialize();
// Initialize the camera capture peripheral module and connected camera
err = camera_init(false);
if (err != FSP_SUCCESS)
{
APP_PRINT("\r\n[Cam] MIPI camera_init failed! Power-cycling in 1s...\r\n");
tx_thread_sleep(100);
tx_thread_suspend(tx_thread_identify());
}
// Initialize timers for measuring each processing time
TimeCounter_Init();
TimeCounter_CountReset();
// Start camera capture
camera_capture_start();
APP_PRINT("\r\n[Cam] MIPI Camera Init Success! Starting pipeline...\r\n");
/* Main loop */
while (true)
{
if (tx_semaphore_get(&g_vin_capture_sem, TX_WAIT_FOREVER) == TX_SUCCESS)
{
camera_capture_post_process();
uint8_t *ready_image_ptr = camera_capture_image_rgb565;
uint32_t image_size = camera_capture_image_rgb565_size;
tx_semaphore_put(&g_ai_start_sem);
tx_semaphore_get(&g_ai_done_sem, TX_WAIT_FOREVER);
#if (BSP_CFG_DCACHE_ENABLED == 1)
SCB_CleanDCache_by_Addr((uint8_t *)ready_image_ptr, camera_capture_image_rgb565_size);
#endif
send_rgb565_via_udp(ready_image_ptr, image_size);
}
tx_thread_sleep(30 * 2);
}
}
3.3 Ethos-U55 驱动的边缘AI推理
系统的视觉核心在于 NPU 加速。Ethos-U55 能够与 Cortex-M85 CPU 异步协同工作。在系统启动后,CPU 仅负责前处理与后处理的调度,而繁重复杂的卷积与矩阵运算交由 NPU 执行。
实际测试中,运行分辨率为 192x192 的 YOLO-Fastest INT8 人脸检测模型时,NPU 的单帧推理时间仅需约 8 ms。推理完成后,CPU 根据 NPU 输出的坐标和置信度,直接在 HyperRAM 的图像缓存中绘制目标检测框。
FSP 配置
由于TF-Micro需要更高的C++版本,因此Keil MDK还需要设置 *C/C++* 标准为C++14,并取消 MicroLIB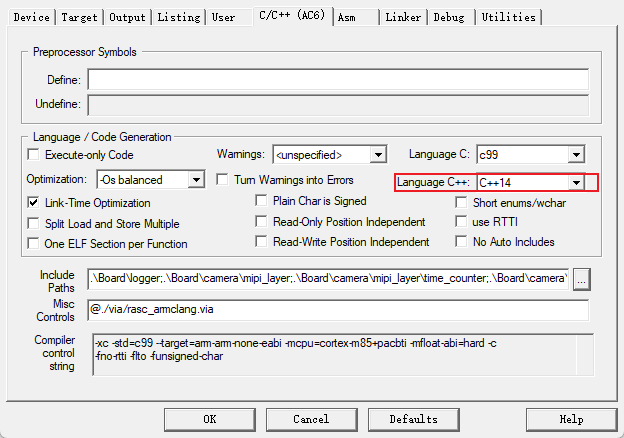
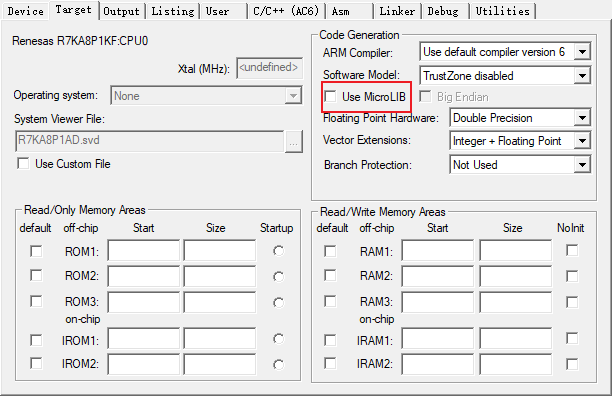
参考RUHMI文档,安装RUHMI Framework
# 1. Clone the repository
git clone https://github.com/renesas/ruhmi-framework-mcu.git
cd ruhmi-framework-mcu
# 2. Create and activate virtual environment
python3.10 -m venv mera-env
source mera-env/bin/activate
# 3. Install dependencies and MERA
pip install --upgrade pip
pip install decorator typing_extensions psutil attrs pybind11 cmake junitparser
pip install ./install/mera-2.5.0+pkg.3577-cp310-cp310-manylinux_2_27_x86_64.whl
coco数据集的建立参考ultralytics/yolo,相应的数据集也可从ultralytics/yolo下载
数据集结构如下
.
├── train
│ ├── 000001.jpg
│ ├── 000001.txt
│ ├── 000002.jpg
│ ├── 000002.txt
│ ├── 000003.jpg
│ └── 000003.txt
└── val
├── 000043.jpg
├── 000043.txt
├── 000057.jpg
├── 000057.txt
├── 000070.jpg
└── 000070.txt
其中xxx.txt描述了标签以及对应的box标注
例如
11 0.344192634561 0.611 0.416430594901 0.262
14 0.509915014164 0.51 0.974504249292 0.972
模型训练与模型转换,参考dog-qiuqiu/Yolo-FastestV2
# 1. Clone Yolo-FastestV2
git clone https://github.com/dog-qiuqiu/Yolo-FastestV2.git
cd Yolo-FastestV2
# 2. Generate anchor based on current dataset
python3 genanchors.py --traintxt ./train.txt
# 3. Train
python3 train.py --data data/coco.data
# 4. Deploy the Model to C
cd ruhmi-framework-mcu/scripts
python mcu_compile.py ../models_int8 ../deploy_output --npu
# 5. Check Model Metrics
python utils/check_model_metrics.py ../deploy_output/ad01_int8_NPU
当前除了命令行转换,还可以直接使用Renesas e2 studio/Renesas AI/Conversion Tool进行转换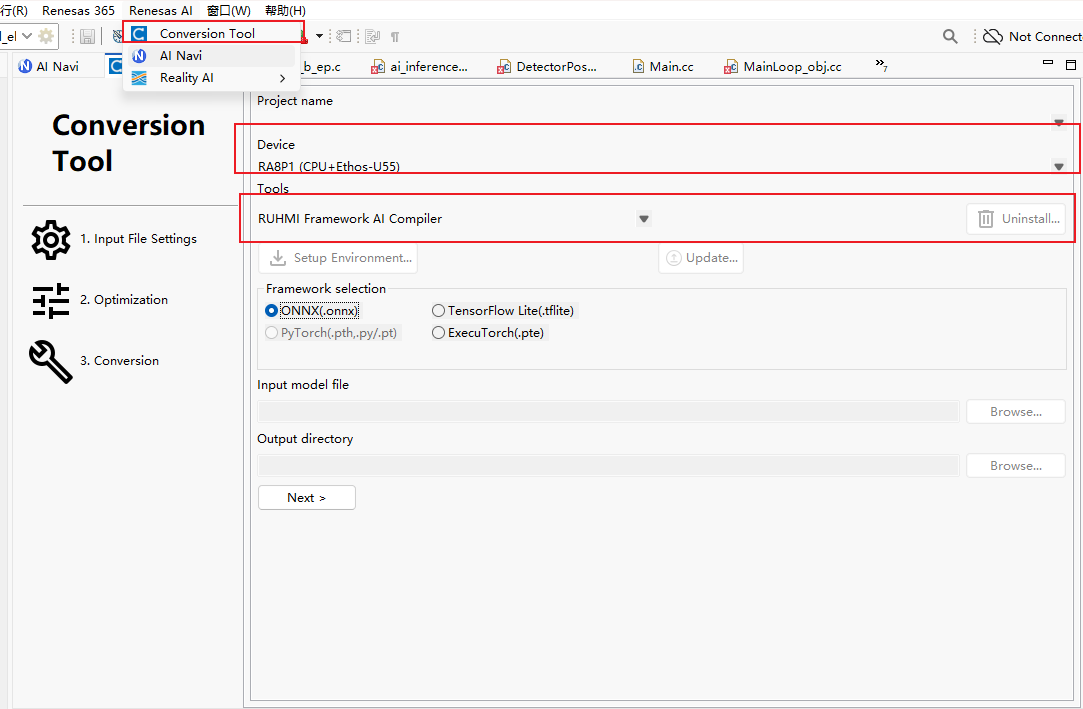
AI Thread实现如下:
#include "async_logger.h"
#include "model.h"
#include "npu_infer_thread.h"
#include "pmu_ethosu.h"
#include "yolo_rtthread.h"
#include <math.h>
#define CAM_WIDTH 320
#define CAM_HEIGHT 240
#define COLOR_RED 0xF800
#define COLOR_GREEN 0x07E0
extern uint8_t camera_capture_image_rgb565[];
extern TX_SEMAPHORE g_ai_start_sem;
extern TX_SEMAPHORE g_ai_done_sem;
int8_t in_i8[INPUT_W * INPUT_H] BSP_PLACE_IN_SECTION(".ospi1_cs0_noinit") BSP_ALIGN_VARIABLE(8);
float out_f1[output1_len] BSP_PLACE_IN_SECTION(".ospi1_cs0_noinit") BSP_ALIGN_VARIABLE(32);
float out_f2[output2_len] BSP_PLACE_IN_SECTION(".ospi1_cs0_noinit") BSP_ALIGN_VARIABLE(32);
void draw_bbox_rgb565(uint8_t *img_buffer, int img_w, int img_h, int x, int y, int w, int h, uint16_t color,
int line_width);
/* Infer Thread entry function */
void npu_infer_thread_entry(void)
{
int16_t status = FSP_SUCCESS;
status = RM_ETHOSU_Open(&g_rm_ethosu0_ctrl, &g_rm_ethosu0_cfg);
if (status != FSP_SUCCESS)
{
APP_PRINT("** [Infer Thread] Failed to start NPU");
return;
}
while (1)
{
if (tx_semaphore_get(&g_ai_start_sem, TX_WAIT_FOREVER) == TX_SUCCESS)
{
ULONG infer_start_time = tx_time_get();
rgb565_to_gray_resize_192_and_quantization(camera_capture_image_rgb565, CAM_WIDTH, CAM_HEIGHT, in_i8);
memcpy(GetModelInputPtr_serving_default_image_input_0(), in_i8, INPUT_SIZE);
RunModel(false);
int8_t *output1 = GetModelOutputPtr_StatefulPartitionedCall_0_70273(); // 6
int8_t *output2 = GetModelOutputPtr_StatefulPartitionedCall_1_70283(); // 12
dequantize_int8(output1, out_f1, output1_len, scale_out1, zero_point_out1);
dequantize_int8(output2, out_f2, output2_len, scale_out2, zero_point_out2);
int16_t total = 0;
static det_box_t pool[540]; // 6*6*3 + 12*12*3 = 108 + 432 = 540
total += decode_output_layer(out_f1, GRID_SIZE_1, 0, CAM_WIDTH, CAM_HEIGHT, CONF_THRESH, pool + total,
(int16_t)(sizeof(pool) / sizeof(pool[0])) - total);
total += decode_output_layer(out_f2, GRID_SIZE_2, 1, CAM_WIDTH, CAM_HEIGHT, CONF_THRESH, pool + total,
(int16_t)(sizeof(pool) / sizeof(pool[0])) - total);
// nms
int32_t kept = nms_filter(pool, total, NMS_THRESH);
int32_t out_n = MIN(kept, MAX_BOXES); // 拷贝前 kept(不超过 MAX_BOXES)
ULONG infer_end_time = tx_time_get();
ULONG infer_time_ms = (infer_end_time - infer_start_time) * (1000 / TX_TIMER_TICKS_PER_SECOND);
if (out_n > 0 )
{
APP_PRINT("\r\n[AI] NPU Inference Time: %lu ms, detect face: %d\r\n", infer_time_ms, out_n);
}
// draw
for (int i = 0; i < out_n; i++)
{
int x = pool->x1;
int y = pool->y1;
int w = abs(pool->x2 - pool->x1);
int h = abs(pool->y2 - pool->y1);
draw_bbox_rgb565(camera_capture_image_rgb565, 320, 240, x, y, w, h, COLOR_RED, 3);
}
tx_semaphore_put(&g_ai_done_sem);
}
}
}
void draw_bbox_rgb565(uint8_t *img_buffer, int img_w, int img_h, int x, int y, int w, int h, uint16_t color,
int line_width)
{
uint16_t *img = (uint16_t *)img_buffer;
/* clip */
if (x < 0)
{
w += x;
x = 0;
}
if (y < 0)
{
h += y;
y = 0;
}
if (x + w > img_w)
w = img_w - x;
if (y + h > img_h)
h = img_h - y;
if (w <= 0 || h <= 0)
return;
/* 画上下水平线 */
for (int lw = 0; lw < line_width; lw++)
{
if (y + lw < img_h)
{
for (int i = x; i < x + w; i++)
img[(y + lw) * img_w + i] = color;
}
if (y + h - 1 - lw >= 0)
{
for (int i = x; i < x + w; i++)
img[(y + h - 1 - lw) * img_w + i] = color;
}
}
/* 画左右垂直线 */
for (int lw = 0; lw < line_width; lw++)
{
if (x + lw < img_w)
{
for (int j = y; j < y + h; j++)
img[j * img_w + (x + lw)] = color;
}
if (x + w - 1 - lw >= 0)
{
for (int j = y; j < y + h; j++)
img[j * img_w + (x + w - 1 - lw)] = color;
}
}
}
3.4 使用ThreadX NetX 的网络流分发
在完成了相机以及推理后,现在通过网络UDP将图像发送出去,这部分采用了 RA8 的 ESWM 千兆以太网模块(ETH0)。在 FSP 配置中,本项目启用了 r_mac并通过自定义初始化函数rmac_phy_target_rtl8211_initialize完成对 PHY 芯片的寄存器配置。
在操作系统层,使用ThreadX 和 NetX Duo 协议栈(Azure RTOS NetX Duo IP Instance)。应用程序创建一个专用的推流线程,将画好检测框的 RGB 数据切割成适配 MTU 长度的数据块,通过 UDP Socket 持续向局域网内的 PC 上位机发送。
FSP配置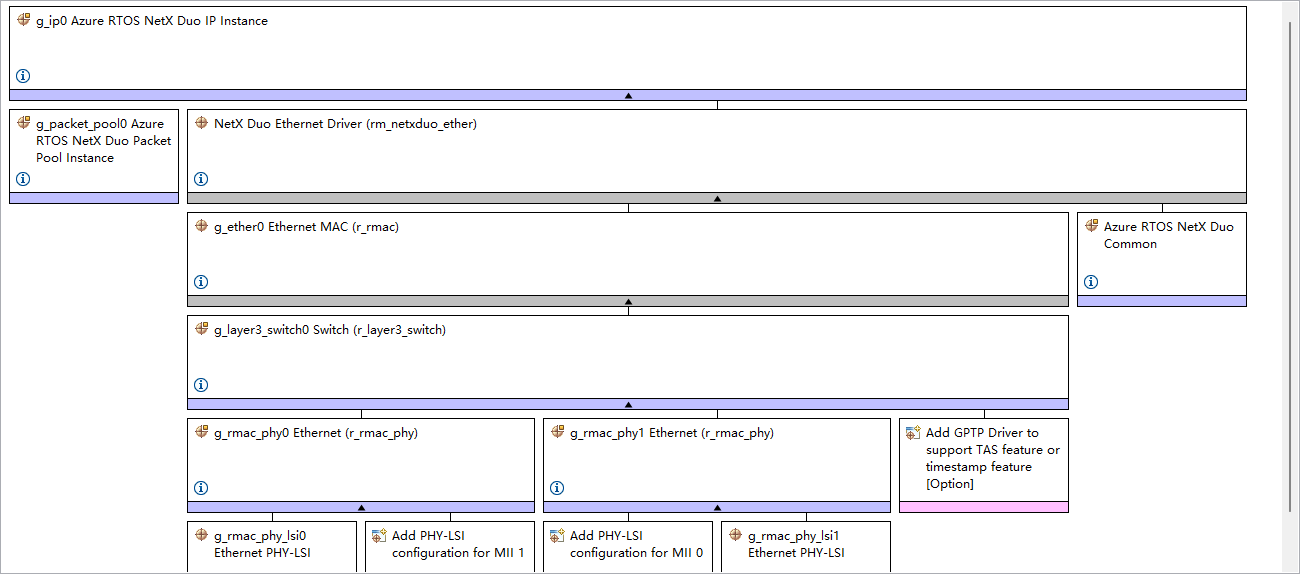
其中Ethernet的配置参考 Titan-Board SDK 文档/驱动篇/Ethernet 示例说明
重点注意PHY-LSI Address,Titan-Board LSI0 Address为2(010),LSI1 Address为1(001)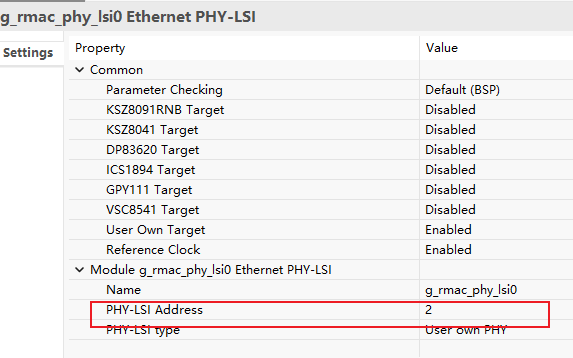
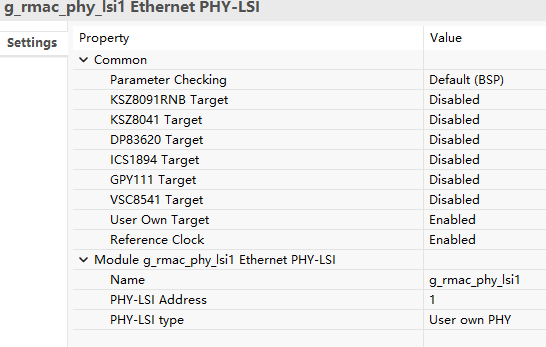
代码实现:
#include "async_logger.h"
#include "net_thread.h"
#include <stdio.h>
// RTL8211
void rmac_phy_target_rtl8211_initialize(rmac_phy_instance_ctrl_t *phydev)
{
#define RTL_8211F_PAGE_SELECT 0x1F
#define RTL_8211F_EEELCR_ADDR 0x11
#define RTL_8211F_LED_PAGE 0xD04
#define RTL_8211F_LCR_ADDR 0x10
uint32_t val1, val2 = 0;
/* switch to led page */
R_RMAC_PHY_Write(phydev, RTL_8211F_PAGE_SELECT, RTL_8211F_LED_PAGE);
/* set led1(green) Link 10/100/1000M, and set led2(yellow) Link 10/100/1000M+Active */
R_RMAC_PHY_Read(phydev, RTL_8211F_LCR_ADDR, &val1);
val1 |= (1 << 5);
val1 |= (1 << 8);
val1 &= (~(1 << 9));
val1 |= (1 << 10);
val1 |= (1 << 11);
R_RMAC_PHY_Write(phydev, RTL_8211F_LCR_ADDR, val1);
/* set led1(green) EEE LED function disabled so it can keep on when linked */
R_RMAC_PHY_Read(phydev, RTL_8211F_EEELCR_ADDR, &val2);
val2 &= (~(1 << 2));
R_RMAC_PHY_Write(phydev, RTL_8211F_EEELCR_ADDR, val2);
/* switch back to page0 */
R_RMAC_PHY_Write(phydev, RTL_8211F_PAGE_SELECT, 0xa42);
}
bool rmac_phy_target_rtl8211_is_support_link_partner_ability(rmac_phy_instance_ctrl_t *p_instance_ctrl,
uint32_t line_speed_duplex)
{
FSP_PARAMETER_NOT_USED(p_instance_ctrl);
FSP_PARAMETER_NOT_USED(line_speed_duplex);
/* This PHY-LSI supports half and full duplex mode. */
return true;
}
void rtl8211_wakeup(void)
{
APP_PRINT("\r\n[net_thread] Network Thread Started! Waking up ETH0 PHY...\r\n");
R_IOPORT_PinWrite(&g_ioport_ctrl, BSP_IO_PORT_08_PIN_13, BSP_IO_LEVEL_LOW);
tx_thread_sleep(5);
R_IOPORT_PinWrite(&g_ioport_ctrl, BSP_IO_PORT_08_PIN_13, BSP_IO_LEVEL_HIGH);
APP_PRINT("\r\n[net_thread] Waiting for PHY Auto-Negotiation (approx 2 seconds)...\r\n");
tx_thread_sleep(200);
}
#define LINK_ENABLE_WAIT_TIME (1000U)
#define NULL_CHAR ('\0')
#define RESET_VALUE (0x00)
#define PC_IP_ADDRESS IP_ADDRESS(192, 168, 5, 117)
#define PC_UDP_PORT 3000
#define CHUNK_PAYLOAD_SIZE 1024
/*UDP*/
NX_UDP_SOCKET g_udp_socket;
static uint32_t g_frame_counter = 0;
static void nx_common_init0(void);
static void packet_pool_init0(void);
static void ip_init0(void);
static void udp_stream_init(void);
void send_jpeg_via_udp(uint8_t *jpeg_data, uint32_t length);
/* Packet pool instance (If this is a Trustzone part, the memory must be placed in Non-secure memory) */
NX_PACKET_POOL g_packet_pool0;
#if (BSP_PERIPHERAL_ESWM_PRESENT)
uint8_t g_packet_pool0_pool_memory[G_PACKET_POOL0_PACKET_NUM *
(G_PACKET_POOL0_PACKET_SIZE + sizeof(NX_PACKET))] BSP_ALIGN_VARIABLE(4);
#else
uint8_t g_packet_pool0_pool_memory[G_PACKET_POOL0_PACKET_NUM *
(G_PACKET_POOL0_PACKET_SIZE + sizeof(NX_PACKET))] BSP_ALIGN_VARIABLE(4)
ETHER_BUFFER_PLACE_IN_SECTION;
#endif
/* IP instance */
NX_IP g_ip0;
/* Stack memory for g_ip0 */
uint8_t g_ip0_stack_memory[G_IP0_TASK_STACK_SIZE] BSP_PLACE_IN_SECTION(".stack.g_ip0")
BSP_ALIGN_VARIABLE(BSP_STACK_ALIGNMENT);
/* ARP cache memory for g_ip0 */
uint8_t g_ip0_arp_cache_memory[G_IP0_ARP_CACHE_SIZE] BSP_ALIGN_VARIABLE(4);
volatile bool g_network_ready = false;
/* Network Thread entry function */
void net_thread_entry(void)
{
rtl8211_wakeup();
/* Initialize the NetX system */
nx_common_init0();
/* Initialize the packet pool */
packet_pool_init0();
/* Create the IP instance */
ip_init0();
/* Initialize UDP Server */
udp_stream_init();
ULONG current_state;
UINT status;
APP_PRINT("\r\n[net_thread] Waiting for Ethernet Link to be UP...\r\n");
do
{
status = nx_ip_status_check(&g_ip0, NX_IP_LINK_ENABLED, ¤t_state, 100);
if (status != NX_SUCCESS)
{
APP_PRINT(".");
}
} while (status != NX_SUCCESS);
APP_PRINT("\r\n[net_thread] Ethernet Link is UP! IP Address Acquired.\r\n");
APP_PRINT("\r\n[net_thread] Probing PC IP (ARP Resolve)...\r\n");
NX_PACKET *probe_packet;
if (nx_packet_allocate(&g_packet_pool0, &probe_packet, NX_UDP_PACKET, 100) == NX_SUCCESS)
{
probe_packet->nx_packet_prepend_ptr[0] = 0x00;
probe_packet->nx_packet_length = 1;
probe_packet->nx_packet_append_ptr = probe_packet->nx_packet_prepend_ptr + 1;
if (nx_udp_socket_send(&g_udp_socket, probe_packet, PC_IP_ADDRESS, PC_UDP_PORT) != NX_SUCCESS)
{
nx_packet_release(probe_packet);
}
}
tx_thread_sleep(500);
APP_PRINT("\r\n[net_thread] Network Ready! Camera streaming allowed.\r\n");
g_network_ready = true;
while (1)
{
ULONG ip_address;
ULONG network_mask;
nx_ip_address_get(&g_ip0, &ip_address, &network_mask);
tx_thread_sleep(2000);
}
}
static void nx_common_init0(void)
{
/* Initialize the NetX system */
nx_system_initialize();
}
static void packet_pool_init0(void)
{
/* Create the packet pool */
UINT status = nx_packet_pool_create(&g_packet_pool0, "g_packet_pool0 Packet Pool", G_PACKET_POOL0_PACKET_SIZE,
&g_packet_pool0_pool_memory[0],
G_PACKET_POOL0_PACKET_NUM * (G_PACKET_POOL0_PACKET_SIZE + sizeof(NX_PACKET)));
if (NX_SUCCESS != status)
{
APP_PRINT("\r\n[net_thread] Error: Packet Pool create failed! 0x%02X\r\n", status);
}
}
static void ip_init0(void)
{
UINT status = NX_SUCCESS;
/* Create the IP instance */
status = nx_ip_create(&g_ip0, "g_ip0 IP Instance", G_IP0_ADDRESS, G_IP0_SUBNET_MASK, &g_packet_pool0,
g_netxduo_ether_0, &g_ip0_stack_memory[0], G_IP0_TASK_STACK_SIZE, G_IP0_TASK_PRIORITY);
if (NX_SUCCESS != status)
{
APP_PRINT("\r\n[net_thread] Error: IP Instance create failed! 0x%02X\r\n", status);
}
/* Enable address resolution protocol (ARP) */
status = nx_arp_enable(&g_ip0, &g_ip0_arp_cache_memory[0], G_IP0_ARP_CACHE_SIZE);
if (NX_SUCCESS != status)
{
APP_PRINT("** [net_thread] Error: ARP Enable failed! 0x%02X\r\n", status);
}
/* Enable UDP */
status = nx_udp_enable(&g_ip0);
if (NX_SUCCESS != status)
{
APP_PRINT("** [net_thread] Error:nx_udp_enable failed! 0x%02X\r\n", status);
}
/* Enable ICMP */
status = nx_icmp_enable(&g_ip0);
if (NX_SUCCESS != status)
{
APP_PRINT("** [net_thread] Error: nx_icmp_enable failed! 0x%02X\r\n", status);
}
/* Wait for the link to be enabled */
ULONG current_state;
APP_PRINT("\r\n[net_thread] Checking Ethernet Link...\r\n");
status = nx_ip_status_check(&g_ip0, NX_IP_LINK_ENABLED, ¤t_state, LINK_ENABLE_WAIT_TIME);
if ((NX_SUCCESS != status) || (NX_IP_LINK_ENABLED != current_state))
{
APP_PRINT("** [net_thread] Error: nx_ip_status_check failed! 0x%02X\r\n", status);
}
APP_PRINT("\r\n[net thread] Ethernet link is up.\r\n");
}
static void udp_stream_init(void)
{
UINT status = NX_SUCCESS;
status = nx_udp_socket_create(&g_ip0, &g_udp_socket, "UDP Stream Socket", NX_IP_NORMAL, NX_FRAGMENT_OKAY, 0x80, 5);
if (NX_SUCCESS != status)
{
APP_PRINT("** [net_thread] Error: nx_udp_socket_create failed! 0x%02X\r\n", status);
}
status = nx_udp_socket_bind(&g_udp_socket, NX_ANY_PORT, TX_WAIT_FOREVER);
if (NX_SUCCESS != status)
{
APP_PRINT("** [net_thread] Error: nx_udp_socket_bind failed! 0x%02X\r\n", status);
}
}
void send_jpeg_via_udp(uint8_t *jpeg_data, uint32_t length)
{
if (!g_network_ready) return;
g_frame_counter++;
uint16_t total_chunks = (length + CHUNK_PAYLOAD_SIZE - 1) / CHUNK_PAYLOAD_SIZE;
uint16_t chunks_sent = 0;
for (uint16_t chunk_idx = 0; chunk_idx < total_chunks; chunk_idx++)
{
NX_PACKET *packet_ptr;
UINT status = nx_packet_allocate(&g_packet_pool0, &packet_ptr, NX_UDP_PACKET, 50);
if (status != NX_SUCCESS) {
APP_PRINT("\r\\n**[net_thread] Error: nx_packet_allocate failed! 0x%02X\r\n", status);
break;
}
uint32_t offset = chunk_idx * CHUNK_PAYLOAD_SIZE;
uint32_t current_chunk_size = length - offset;
if (current_chunk_size > CHUNK_PAYLOAD_SIZE) current_chunk_size = CHUNK_PAYLOAD_SIZE;
uint8_t *ptr = packet_ptr->nx_packet_prepend_ptr;
ptr[0] = (g_frame_counter >> 24) & 0xFF; ptr[1] = (g_frame_counter >> 16) & 0xFF;
ptr[2] = (g_frame_counter >> 8) & 0xFF; ptr[3] = (g_frame_counter) & 0xFF;
ptr[4] = (total_chunks >> 8) & 0xFF; ptr[5] = (total_chunks) & 0xFF;
ptr[6] = (chunk_idx >> 8) & 0xFF; ptr[7] = (chunk_idx) & 0xFF;
memcpy(ptr + 8, jpeg_data + offset, current_chunk_size);
packet_ptr->nx_packet_length = current_chunk_size + 8;
packet_ptr->nx_packet_append_ptr = packet_ptr->nx_packet_prepend_ptr + packet_ptr->nx_packet_length;
status = nx_udp_socket_send(&g_udp_socket, packet_ptr, PC_IP_ADDRESS, PC_UDP_PORT);
if (status != NX_SUCCESS) {
APP_PRINT("\r\\n**[net_thread] Error: nx_udp_socket_send failed! 0x%02X\r\n", status);
nx_packet_release(packet_ptr);
} else {
chunks_sent++;
}
if ((chunks_sent % 8) == 0) {
tx_thread_sleep(5);
}
}
}四、最终效果
UDP上位机的简单实现
import socket
import struct
import numpy as np
import cv2
import time
# ================= 配置参数 =================
UDP_IP = "0.0.0.0" # 监听所有网卡
UDP_PORT = 3000 # 端口
WIDTH = 320 # 图像宽度
HEIGHT = 240 # 图像高度
BYTES_PER_PIXEL = 2 # RGB565 占用 2 字节
TOTAL_IMAGE_BYTES = WIDTH * HEIGHT * BYTES_PER_PIXEL # 153600 Bytes
# ============================================
def main():
# 创建 UDP Socket 并绑定端口
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.bind((UDP_IP, UDP_PORT))
print(f"[*] 正在监听 UDP 端口 {UDP_PORT},等待 RA8P1 图像数据流...")
print(f"[*] 分辨率: {WIDTH}x{HEIGHT} RGB565")
current_frame_id = -1
frame_buffer = {}
# 用于计算 FPS
fps_start_time = time.time()
fps_frame_count = 0
try:
while True:
data, addr = sock.recvfrom(2048)
# 解析 8 字节自定义帧头
# >IHH 表示:大端序的 uint32 (4字节), uint16 (2字节), uint16 (2字节)
if len(data) < 8:
continue
frame_id, total_chunks, chunk_idx = struct.unpack('>IHH', data[:8])
payload = data[8:]
if frame_id > current_frame_id:
current_frame_id = frame_id
frame_buffer.clear()
elif frame_id < current_frame_id:
continue
frame_buffer[chunk_idx] = payload
if len(frame_buffer) == total_chunks:
full_data = b''.join([frame_buffer[i] for i in range(total_chunks)])
if len(full_data) != TOTAL_IMAGE_BYTES:
print(f"[!] 警告: 帧 {frame_id} 数据长度错误,预期 {TOTAL_IMAGE_BYTES}, 实际 {len(full_data)}")
continue
img_u16 = np.frombuffer(full_data, dtype='<u2')
# 2. 提取 R, G, B 通道 (RGB565: R5, G6, B5)
r5 = (img_u16 >> 11) & 0x1F
g6 = (img_u16 >> 5) & 0x3F
b5 = img_u16 & 0x1F
# 3. 映射到 0-255 的 8-bit 范围
# 例如 5bit最大是31,所以 (r5 * 255) // 31
r8 = ((r5 * 255) // 31).astype(np.uint8)
g8 = ((g6 * 255) // 63).astype(np.uint8)
b8 = ((b5 * 255) // 31).astype(np.uint8)
# 4. OpenCV 使用的是 BGR 通道顺序,所以按照 B, G, R 堆叠
img_bgr = np.dstack((b8, g8, r8))
# 5. 重塑为二维图像矩阵
img_bgr = img_bgr.reshape((HEIGHT, WIDTH, 3))
fps_frame_count += 1
now = time.time()
if now - fps_start_time >= 1.0:
fps = fps_frame_count / (now - fps_start_time)
cv2.putText(img_bgr, f"FPS: {fps:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
fps_start_time = now
fps_frame_count = 0
img_display = cv2.resize(img_bgr, (WIDTH * 2, HEIGHT * 2), interpolation=cv2.INTER_NEAREST)
cv2.imshow("RA8P1 UDP Camera Stream", img_display)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
except KeyboardInterrupt:
print("\n[*] 用户强行终止")
finally:
sock.close()
cv2.destroyAllWindows()
print("[*] 资源已释放")
if __name__ == "__main__":
main()
```连线

串口打印
======================================
Azure RTOS ThreadX is running on RA8P1!
Core Clock: 480 MHz
======================================
[ram_thread] HyperRAM Initialized Successfully!
[ram_thread] HyperRAM Read/Write Test PASS! Data: 0xDEADBEEF
[net_thread] Waiting for PHY Auto-Negotiation (approx 2 seconds)...
[net_thread] Checking Ethernet Link...
[Cam] MIPI Camera Init Success! Starting pipeline...
** [net_thread] Error: nx_ip_status_check failed! 0x43
[net thread] Ethernet link is up.
[net_thread] Waiting for Ethernet Link to be UP...
.....................
[net_thread] Ethernet Link is UP! IP Address Acquired.
[net_thread] Probing PC IP (ARP Resolve)...
[net_thread] Network Ready! Camera streaming allowed.
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
[AI] NPU Inference Time: 8 ms, detect face: 1
检测效果
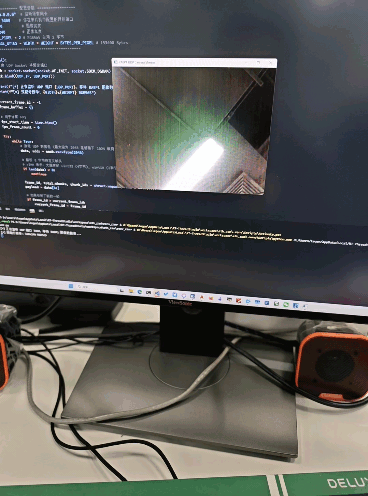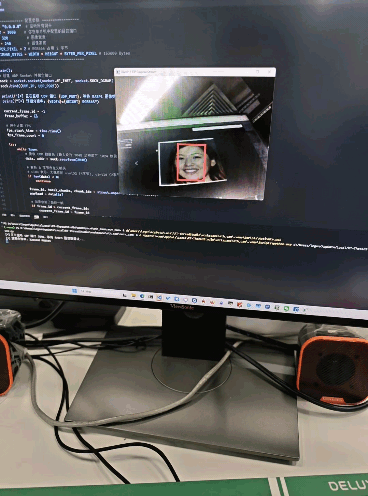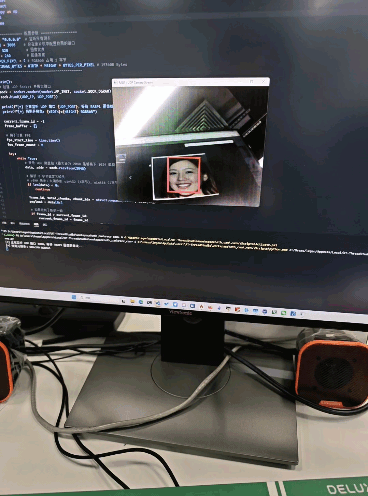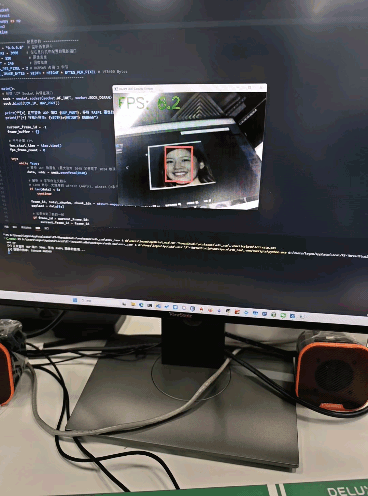
五、一些小问题
正如我们在前期系统调试中所发现并解决的,此类高并发边缘AI应用存在诸多问题:
- 高速时钟信号失真导致网络发送失败 (4003 错误)
现象:底层 PHY 芯片握手成功 (Link UP),但 NetX 无法发出数据,底层 API 频繁返回发送缓冲区满错误。
解决:以太网的 RGMII 接口(TXC/RXC)工作频率高达 125MHz。必须在 FSP 的 `Pins` 配置中,将所有 ETH0 相关引脚的**驱动能力 (Drive Capacity) 强制修改为 H**,以保证方波信号的完整性。 - NPU推理时系统 HardFault或者无法发送数据**
现象:在 NPU 满负荷运行且网络推流时,系统偶发总线错误导致崩溃或者无法发送数据。
解决:NPU 和 MIPI-VIN 的硬件 DMA 在访问内存(SRAM/HyperRAM)时占用了大量内存,导致以太网数据包内存池耗尽,最终引起网络 RX 环形缓冲区溢出。在 FSP 中增加以太网的 Number of RX buffer,增加g_packet_pool0 (NetX Duo Packet Pool)。
此外,如果直接使用Titan-Board SDK + RTThread组合开发,则不可以混用不同版本的FSP,不同版本的FSP可能有不同的链接LD定义,这将会导致程序无法进入RTOS
六、 总结时间
本测评项目成功验证了 RA8P1 (Cortex-M85 + Ethos-U55) 在边缘侧同时处理高带宽外设(MIPI + 千兆网)和重度AI推理任务的非凡实力。结合 FSP 工具的可视化配置与 ThreadX 的硬实时调度,开发者可以极其快速地构建出无屏化的智能 IPC (IP Camera) 产品雏形,敏捷开发。最后折腾之路任重道远,受限于作者的开发水平,力有不逮之处,还请各位多多包涵,多多指教。
版块:
瑞萨电子
2026/03/10 12:32



全部评论