
卢工爱分享
零基础理解 VLA 原理 3:机器人是如何生成动作的?
前两篇我们讲了 VLA 如何理解图像和语言。到了第三篇,就要进入最关键的一步:机器人如何把理解变成动作。比如机器人收到了指令:把红色方块放进白色碗里。VLM 可以识别红色方块和白色碗,也可以理解“放进去”这个任务关系。但机器人真正执行时,并不需要一句自然语言回答,而是需要一串具体控制量:机械臂末端往哪里移动,夹爪什么时候闭合。这中间缺的,就是action head。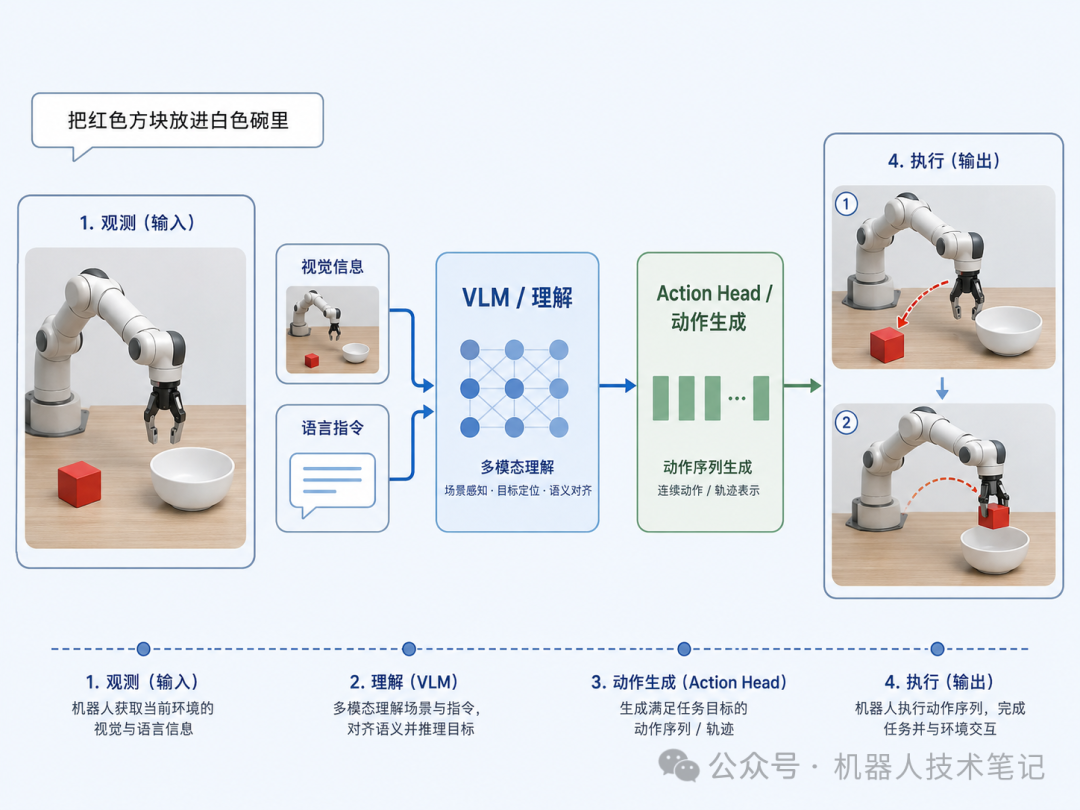 可以把 VLA 模型粗略拆成两部分:前面是理解模块,负责看图像、读语言、理解任务;后面是动作模块,负责把理解结果变成机器人可以执行的动作。这个动作模块,通常就可以叫 action head,也有人叫 action decoder 或 action expert。action head 的作用,就是把视觉和语言理解结果,转换成机器人能够执行的动作表示。
可以把 VLA 模型粗略拆成两部分:前面是理解模块,负责看图像、读语言、理解任务;后面是动作模块,负责把理解结果变成机器人可以执行的动作。这个动作模块,通常就可以叫 action head,也有人叫 action decoder 或 action expert。action head 的作用,就是把视觉和语言理解结果,转换成机器人能够执行的动作表示。
动作到底如何表示?
设计 action head 之前,首先要定义动作是什么。对一个机械臂来说,动作可以有很多种表示方式。最常见的是末端位姿增量,比如:Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper前三个量表示末端在空间中的平移,后三个量表示姿态变化,最后一个量表示夹爪开合。这样一个 7 维向量,就可以表示机器人下一步该怎么动。也可以直接输出关节空间动作,比如:Δq1, Δq2, Δq3, Δq4, Δq5, Δq6, gripper这种方式更接近底层控制,但跨机器人泛化会更困难。不同机械臂的关节数量、结构和运动范围都可能不同,同一个关节增量在不同机器人上的意义并不一样。还有一种常见做法,是一次输出未来一小段动作,也就是 action chunk:a_t, a_{t+1}, a_{t+2}, ..., a_{t+H}这里的每个 a 都是一帧动作,整段动作表示未来一小段时间内机器人应该如何运动。基于这些定义,action head 的设计有几种不同的思路。
把动作当成 token
大语言模型本来就是预测 token 的。输入一句话,模型预测下一个词;输入一段上下文,模型继续生成后面的内容。那么能不能把机器人动作也离散化,让模型像预测文字一样预测动作?比如原本连续的动作是:Δx = 0.012 Δy = 0.005 Δz = 0.000可以先把每个维度离散成若干区间,再映射成 token:MOVE_X_128 MOVE_Y_096 MOVE_Z_120这样一来,动作就变成了模型可以处理的序列。训练时,模型看到图像、语言指令和历史状态,学习预测下一组动作 token;执行时,再把这些 token 解码回连续控制量。这种方法的好处是统一。语言 token、图像 token、动作 token 可以放在同一个序列建模框架里,比较容易复用 VLM 或大语言模型的训练方式。但它也有问题。机器人动作本来是连续的,离散化之后会损失精度。区间太粗,动作不够细;区间太细,token 数量又会膨胀,学习难度变大。所以,动作 token 化适合做大规模统一建模,但不一定适合所有高精度控制场景。
回归连续动作
另一种更接近传统机器人学习的方法,是让 action head 直接输出连续动作向量。这时,前面的视觉语言模块负责提取任务相关特征,action head 接在后面,输出一个数值向量:图像 + 语言指令 → VLM hidden state → MLP → 连续动作如果动作是 7 维的,action head 最后一层就输出 7 个数。如果要输出未来 10 步动作,就输出 10 × 7 个数。这种设计简单直接,动作空间天然连续,不需要离散化。对于固定机械臂、固定相机、固定工作台这类场景,连续动作回归是一个很容易落地的方案。但它也有局限。机器人动作往往不是单一答案。比如“拿起杯子”,机器人可以从左侧接近,也可以从右侧接近;可以先移动到物体上方再下降,也可以斜着靠近。多种动作路线都可能合理。如果只用简单回归,模型可能学到几种动作的平均值,而这个平均动作反而不一定可执行。这也是很多方法转向生成式动作建模的原因。
生成一段动作
真实机器人控制里,一个重要经验是:只预测下一步动作,容易抖动;预测未来一段动作,执行会更稳定。这就是 action chunk 的思路。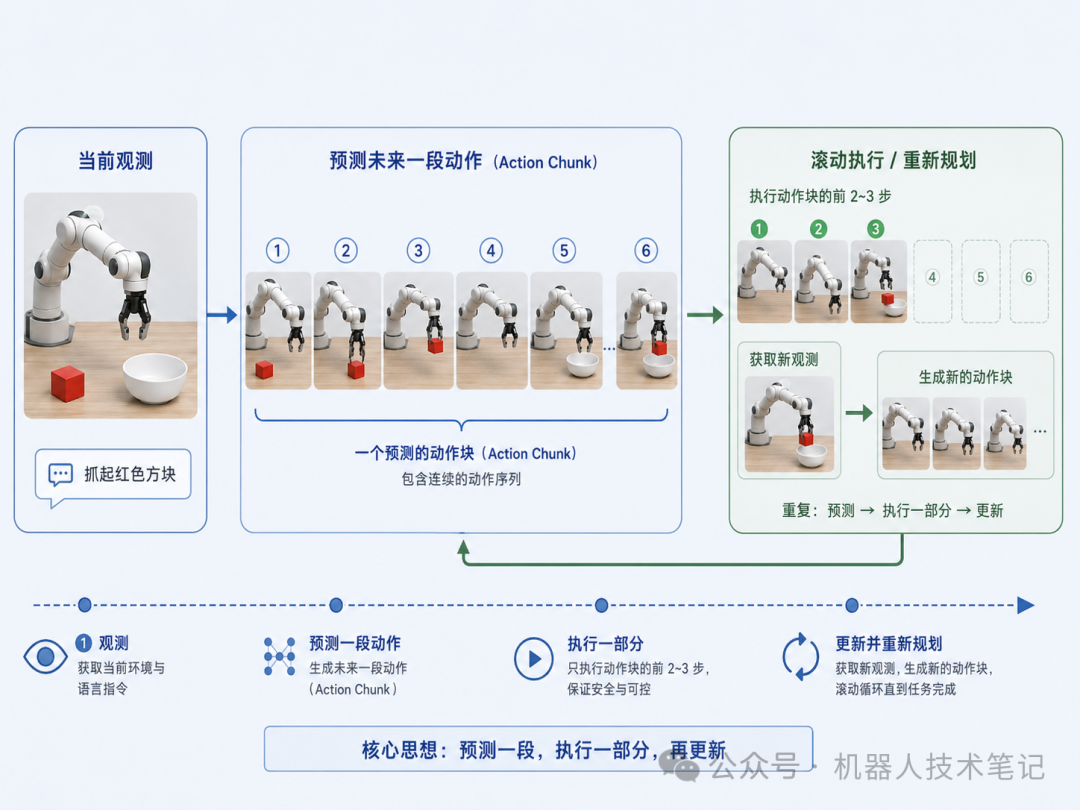 模型不再只输出当前时刻的一个动作:a_t而是输出未来一小段时间的动作序列:a_t, a_{t+1}, a_{t+2}, ..., a_{t+H}比如抓取红色方块时,模型可以一次生成未来 1 秒内的动作趋势:先向目标靠近,再微调高度,再闭合夹爪。不过,机器人通常不会把整段动作一次性执行到底,而是采用滚动更新的方式:先执行前几步,然后重新观察环境,重新生成下一段动作。这有点像滚动规划。模型每次根据当前图像和状态预测未来一小段轨迹,真正执行时只执行开头部分,再根据新状态继续修正。这样做动作更平滑,短期意图更清楚,也更容易在执行过程中纠偏。
模型不再只输出当前时刻的一个动作:a_t而是输出未来一小段时间的动作序列:a_t, a_{t+1}, a_{t+2}, ..., a_{t+H}比如抓取红色方块时,模型可以一次生成未来 1 秒内的动作趋势:先向目标靠近,再微调高度,再闭合夹爪。不过,机器人通常不会把整段动作一次性执行到底,而是采用滚动更新的方式:先执行前几步,然后重新观察环境,重新生成下一段动作。这有点像滚动规划。模型每次根据当前图像和状态预测未来一小段轨迹,真正执行时只执行开头部分,再根据新状态继续修正。这样做动作更平滑,短期意图更清楚,也更容易在执行过程中纠偏。
扩散 / flow matching
如果 action head 只是一个 MLP,它输出的通常是一个确定动作。输入同样的图像和语言,输出基本就是同一个结果。但机器人操作经常存在多种合理解。比如抓一个方块,可以从正面抓,也可以从侧面抓;可以绕开障碍物,也可以直接接近。只输出一个确定结果,有时会限制模型表达能力。扩散模型和 flow matching 的引入,就是为了解决这类问题。可以简单理解为:模型不是直接一步算出动作,而是从一个随机动作序列开始,逐步把它变成一个合理的动作序列。随机动作轨迹 → 逐步修正 → 可执行动作轨迹这个生成过程会受到图像、语言指令和机器人状态的约束。也就是说,动作不是凭空生成的,而是根据当前任务上下文生成的。这类方法的优势是能表达更复杂的动作分布。它不是简单给出一个平均动作,而是可以学习人类示教中多样化的动作模式。对于灵巧操作、双臂协作、接触丰富的任务,这一点尤其重要。
action head 具体要输入什么?
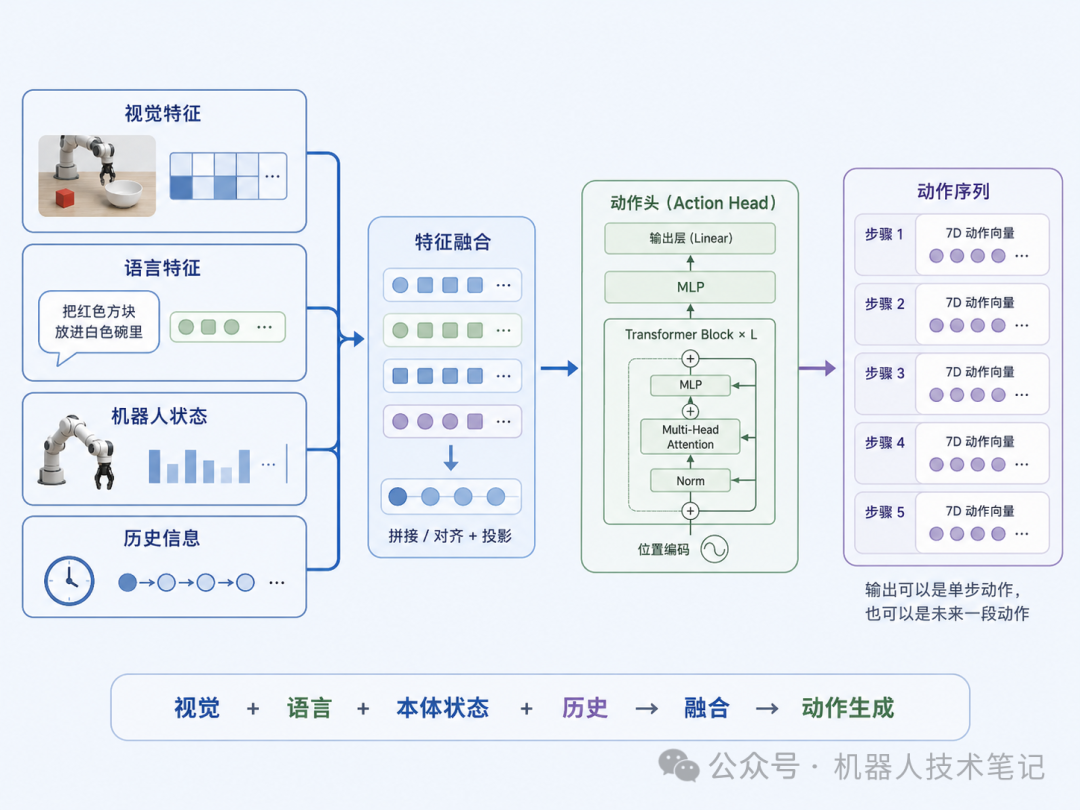
一般来说,至少有四类输入。第一类是视觉特征。机器人需要知道目标物体在哪里,障碍物在哪里,场景发生了什么变化。第二类是语言特征。语言指令决定任务目标。同样是桌面上的方块和碗,“放进碗里”和“推到碗旁边”对应完全不同的动作。第三类是本体状态,也就是 proprioception。包括关节角度、末端位置、夹爪状态、速度等。机器人不仅要知道外部世界,还要知道自己当前在哪里。第四类是历史信息。有些任务只看当前一帧图像并不够。比如夹爪现在闭合了,是已经抓住物体,还是刚准备抓?这需要结合过去几帧状态判断。所以,一个完整的 action head 可以写成:
action_head(
visual_features,
language_features,
robot_state,
history
) → actions
这里的 actions 可以是下一步动作,也可以是一段未来动作;可以是离散 token,也可以是连续向量;可以由 MLP 直接输出,也可以由扩散模型或 flow matching 生成。
设计一个简单的 action head
任务是桌面机械臂抓取。输入是相机图像、语言指令和机器人当前状态。输出是末端执行器未来 10 步动作,每一步包含 7 个维度:Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper一个简化设计可以是:图像 → Vision Encoder语言 → Language Encoder机器人状态 → State Encoder三类特征融合 → Transformer / MLP输出未来 10 步动作 → 10 × 7训练数据来自人类遥操作或脚本生成的示教轨迹。每条数据包括当前图像、语言指令、机器人状态,以及接下来一段时间的真实动作。训练目标就是让模型预测的动作序列尽量接近示教动作。执行时,机器人先观察当前场景,模型生成未来 10 步动作。控制器只执行前几步,然后重新拍图、重新读取状态、重新生成下一段动作。这样就形成了一个闭环过程。也就完成了 action head 的功能。
相关推荐:
文章来源于公众号-机器人技术笔记,仅用于学习分享,如有侵权请私聊删除
版块:
机器人开源工坊
2026/06/05 10:54



全部评论